Today I Learned
오늘은 RecSys 경진대회 정보와 거기서 쓰였던 모델들에 대해 공부해봤다.
RecSys 경진대회
- 추천시스템 분야 특징
-
추천시스템은 도메인에 대한 의존성이 높다.
그렇기 때문에 대회 참가를 통해 다양한 데이터를 보면서 여러 도메인을 경험해보면 좋다. -
추천시스템에 사용되는 데이터들은 대부분 기업 내부정보라 보안상 비공개인 데이터가 많다.
그렇기 때문에 대회를 통해 체험해보는 것이 좋다.
- 대회플랫폼
kaggle, dacon, RecSys Challenge(학회 주최)
sharechat 대회(recsys challenge 2023)
-
adversarial validation
학습데이터와 테스트데이터에 각각 다른 label(0/1)을 부여하고 이를 구분하는 classifier를 학습해 분류 성능이 0.5를 넘으면 학습데이터와 테스트데이터의 분포가 다르다고 판단하는 방법.
(어떤 피처에서 학습과 테스트데이터의 분포가 같아야 의미가 있는거지, 오히려 해당 피처가 학습/테스트 데이터를 가르는 데 도움이 되는 데이터면 학습이 왜곡된다)
즉, 학습데이터와 테스트데이터를 구분할 수 있는 feature를 찾아 제외시키는 방법. -
cardinality(변수에 속한 유니크값) 처리
카테고리형 변수의 카테고리가 너무 많아지면(1만 이상) 따로 전처리가 필요하다
frequency encoding(동일한 피처가 등장한 횟수 사용) or catboost encoding(카테고리별 target 평균 이용) -
cross feature 추가
(feature importance가 높은 변수에 한해) 두 특성을 조합해 새로운 특성을 만드는 방법
두 특성을 곱하거나 교차해서 만든 2차 특성으로 원본 특성들 간의 상호작용을 포착한다.
모델이 알아서 학습하기도 하지만, 이렇게 명시적으로 넣어줘도 된다. -
historical feature 추가
유저의 변하는 성향을 피처로 만들어 반영.
ex. 최근 n일동안 사용자의 광고 카테고리 선호도 -
contrastive learning
두 데이터가 같은 클래스에 속하면 가깝게, 다른 클래스에 속하면 멀어지게 학습하는 방법. -
MMoE 모델
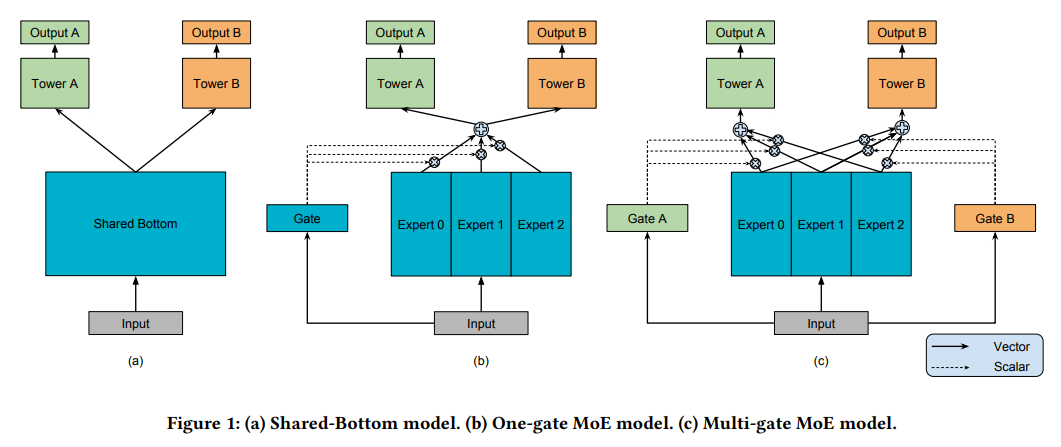
여러 태스크를 동시에 학습하면서 태스크 간의 관계를 명시적으로 모델링하는 방식
여러 개의 Expert Networks로 구성하고, 각 expert는 특정 패턴이나 특성을 학습한다.
각 태스크마다 별도의 게이팅 네트워크 존재하고, 입력에 따라 각 expert의 가중치를 동적으로 결정한다.
