Today I Learned
오늘은 RecBole 라이브러리로 RecVAE 모델을 돌려봤다.
RecBole - RecVAE
RecVAE
암묵적 피드백을 활용한 Top-N 추천을 위해 개발된 VAE 기반의 추천시스템 모델
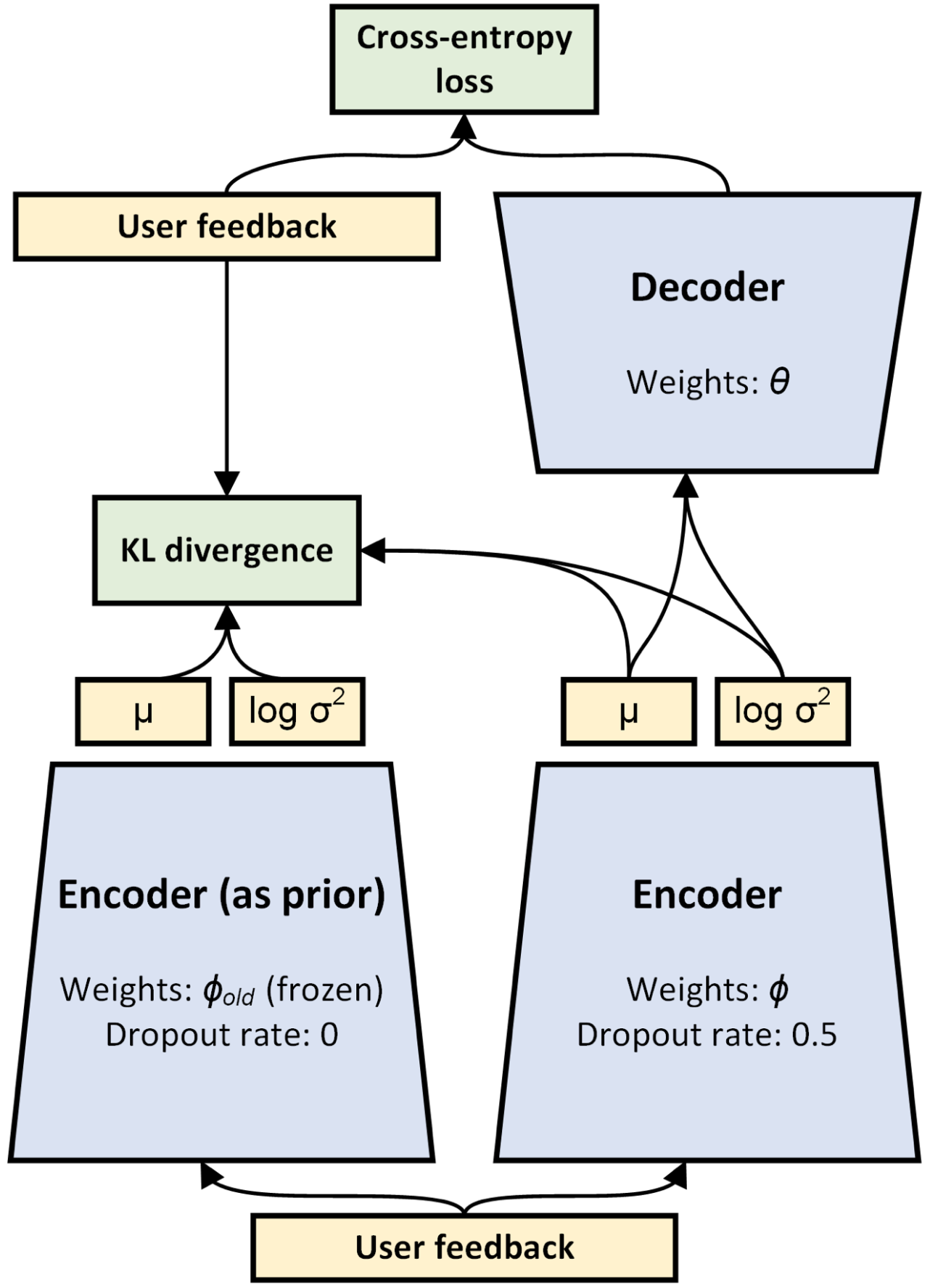 이미지 출처 : RecBole 공식문서
이미지 출처 : RecBole 공식문서
RecVAE: a New Variational Autoencoder for Top-N
Recommendations with Implicit Feedback
-
Mult-VAE를 개선한 모델로, 인코더는 사용자의 아이템 피드백을 사용자 임베딩으로 변환하고, 디코더는 이를 다시 사용자-아이템 피드백으로 복원하는 구조를 가진다.
-
인코더와 디코더의 교차 업데이트 방식의 학습 방법
-
기존 VAE는 인코더 출력과 표준 정규분포 간의 KL divergence를 사용했지만, RecVAE는 인코더 출력과 이전 epoch의 파라미터를 저장한 인코더 간의 KL divergence를 사용한다.
-
주요 하이퍼파라미터
hidden_dimension: 600
latent_dimension: 200
dropout_prob: 0.5
beta: 0.2
gamma: 0.005 -
public score Recall@10 = 0.1347 / valid = 0.1523
RecBole로 구현
- recbole_recvae.yaml
model: RecVAE # 모델 이름
dataset: train_ratings # 데이터셋 이름 (기본 제공 데이터셋 사용)
data_path: ./data/train
field_separator: "\t"
# 기본 필드 설정
USER_ID_FIELD: user_id
ITEM_ID_FIELD: item_id
LABEL_FIELD: label
# 학습 하이퍼파라미터
epochs: 20
learning_rate: 0.001
train_batch_size: 256
embedding_size: 64
# 평가 지표 설정
metrics:
- mrr
- recall
- precision
topk: 10 # Top-K 추천 평가
# RecVAE 특정 파라미터
hidden_dimension: 600
latent_dimension: 200
dropout_prob: 0.3
# 데이터 분할
eval_args:
split: {'RS': [0.8, 0.15, 0.05]}
order: RO # Random Order
# 얼리스타핑 설정
stopping_step: 10 # early stopping 판단 기준
eval_step: 2 # 몇 에폭마다 검증할지 (1이면 매 에폭)
valid_metric: recall@10 # early stopping에 사용할 평가 지표- recbole_recvae.ipynb
from recbole.quick_start import run_recbole, load_data_and_model
parameter_dict = {
'train_neg_sample_args': None, # 암시적 피드백 데이터를 위한 설정
}
run_recbole(config_file_list=['recbole_recvae.yaml'], config_dict=parameter_dict)- inference 단계
# model, dataset 불러오기
model_path = './saved/저장된모델.pth'
config, model, dataset, train_data, valid_data, test_data = load_data_and_model(model_path)
# device 설정
device = config.final_config_dict['device']
# user, item id -> token 변환 array
user_id2token = dataset.field2id_token['user_id']
item_id2token = dataset.field2id_token['item_id']
# user-item sparse matrix
matrix = dataset.inter_matrix(form='csr')
# user id, predict item id 저장 변수
pred_list = None
user_list = None
model.eval()
for data in test_data:
interaction = data[0].to(device)
score = model.full_sort_predict(interaction)
rating_pred = score.cpu().data.numpy().copy()
user_id = interaction['user_id'].cpu().numpy()
# 사용자가 상호작용한 아이템 인덱스를 가져옵니다.
interacted_indices = matrix[user_id].indices
# 상호작용한 아이템의 점수를 0으로 설정합니다.
rating_pred[interacted_indices] = 0
# 상위 10개 아이템 인덱스 추출
ind = np.argpartition(rating_pred, -10)[-10:]
arr_ind = rating_pred[ind]
# 추출된 값들을 내림차순으로 정렬하기 위한 인덱스를 얻음
arr_ind_argsort = np.argsort(arr_ind)[::-1]
# 실제 값들을 정렬된 순서대로 인덱스 배열에 적용
batch_pred_list = ind[arr_ind_argsort]
# 예측값 저장
if pred_list is None:
pred_list = batch_pred_list
# batch_pred_list 길이만큼 user_id를 반복
user_list = np.repeat(user_id, len(batch_pred_list))
else:
pred_list = np.append(pred_list, batch_pred_list, axis=0)
# batch_pred_list 길이만큼 user_id를 반복하여 추가
user_list = np.append(user_list, np.repeat(user_id, len(batch_pred_list)), axis=0)
# 결과를 저장할 빈 리스트 초기화
final_result = []
# user_list와 pred_list에 있는 인덱스를 실제 'resume_seq'와 'recruitment_seq'로 변환
for user, item in zip(user_list, pred_list):
# user_id2token을 사용하여 변환된 사용자 ID를 얻고
# index_to_resume_seq을 사용하여 원래의 'resume_seq'로 변환
original_user_seq = user_id2token[user]
# item_id2token을 사용하여 변환된 아이템 ID를 얻고
# index_to_recruitment_seq을 사용하여 원래의 'recruitment_seq'로 변환
original_item_seq = item_id2token[item]
# 최종 결과에 추가
final_result.append((original_user_seq, original_item_seq))
# 결과를 DataFrame으로 변환하고 CSV 파일로 저장
final_dataframe = pd.DataFrame(final_result, columns=['user', 'item'])
final_dataframe.to_csv('./data/eval/recbole_recvae_1.csv', index=False)
print('Final mapping done and saved to CSV!')
Full-Stack Dev / MLOps