Today I Learned
오늘 공부한 내용은 추천을 위한 시스템 디자인!
System Design for Recommendation
- 일반적으로 추천 결과는 사용자가 key, 추천 아이템들이 정렬된 형태로 value에 저장되어 쓰여진다.
Batch Recommendation
추천 결과를
일정 주기(하루에 한번, 한 시간에 한번 등)에 따라 업데이트 하는 것
-
key-value로 된 추천 결과가 이미 저장되어 있기 때문에 serving 단계에선 단순히 look up만 하면 된다.
-
연산 과정에 문제가 생겨 결과가 오지 않아도 이전에 캐싱된 결과물을 serving에 쓰면 돼서 안정적이다.
-
연산 비용이 적고 효율적이다. 하지만 모든 유저에 대한 추천을 만들어야하는 단점이 있다.
-
추천 결과가 자주 변하지 않는 식료품, 직업 추천 같은게 적합하다.
Real Time Prediction
stream 형태로 들어오는 데이터를 실시간으로 분석해서 추천 결과를 제시하는 것
-
유저의 요청이 올 때 마다 추천을 한다.
-
실시간 추천이기 때문에 latency가 낮아야하고 대규모 트래픽을 감당할 수 있어야 한다.
-
시간에 민감한 context(날씨, 시간)을 사용할 수 있다. -
모든 유저가 아니라 방문하는 유저만 추천 결과를 만들면 된다.
-
쇼핑, 음악, 영상 등 빠르게 변하는 환경에서 사용한다.
Candidate Generation
매번 수백만개의 아이템을 정렬하는 것은 비효율적이다. 그래서 후보군을 추리는 단계와 ranking을 진행하는 2 stage로 나눈다.
-
수백만개의 아이템을 수백개로 줄이는 과정
-
정확도보다 속도를 우선해서 빠르게 후보군을 추려낸다.
-
대표적으로 ANN 방법을 사용한다.
-
4stage로 본다면 Candidate Generation는 Retrieval과 Filtering, Ranking은 Scoring과 Ordering으로 나눌 수 있다.
Industrial System Design
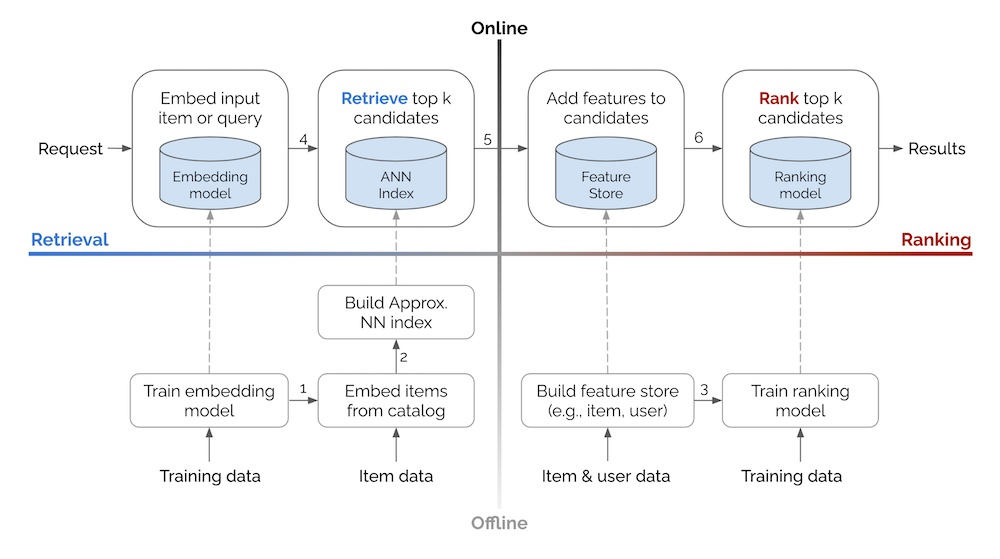
이미지 출처 : Eugene Yan
-
오프라인 환경의 특징
모델 학습, 표현 학습, 랭킹 등의 배치 프로세스 수행
카탈로그 아이템에 대한 임베딩 생성
ANN(Approximate Nearest Neighbors) 인덱스나 지식 그래프 구축
피처 스토어에 아이템과 사용자 데이터 로드 -
온라인 환경의 특징
오프라인에서 생성된 모델, 인덱스, 그래프 등을 활용
입력 아이템이나 검색 쿼리를 임베딩으로 변환
후보 검색과 랭킹을 순차적으로 수행
쿼리 표준화, 토큰화, 맞춤법 검사 등의 전처리 수행 -
Candidate Retrieval
수백만 개의 아이템을 수백 개로 빠르게 축소하는 과정
정확도보다 효율성 중시
주로 임베딩과 ANN을 활용하며, 그래프나 의사결정 트리도 사용 -
Ranking
후보군에 대해 정밀한 점수 계산과 순위 결정
아이템, 사용자 데이터, 문맥 정보 등 다양한 특성 활용
학습-순위화(learning-to-rank) 또는 분류 작업으로 모델링
