Today I Learned
오늘은 모델을 서빙하는 패턴에 대해 공부했다.
Product Serving
ML Model Serving. 모델의 예측 결과를 클라이언트에게 제공하는 과정
 이미지 출처 : analyticsvidhya
이미지 출처 : analyticsvidhya
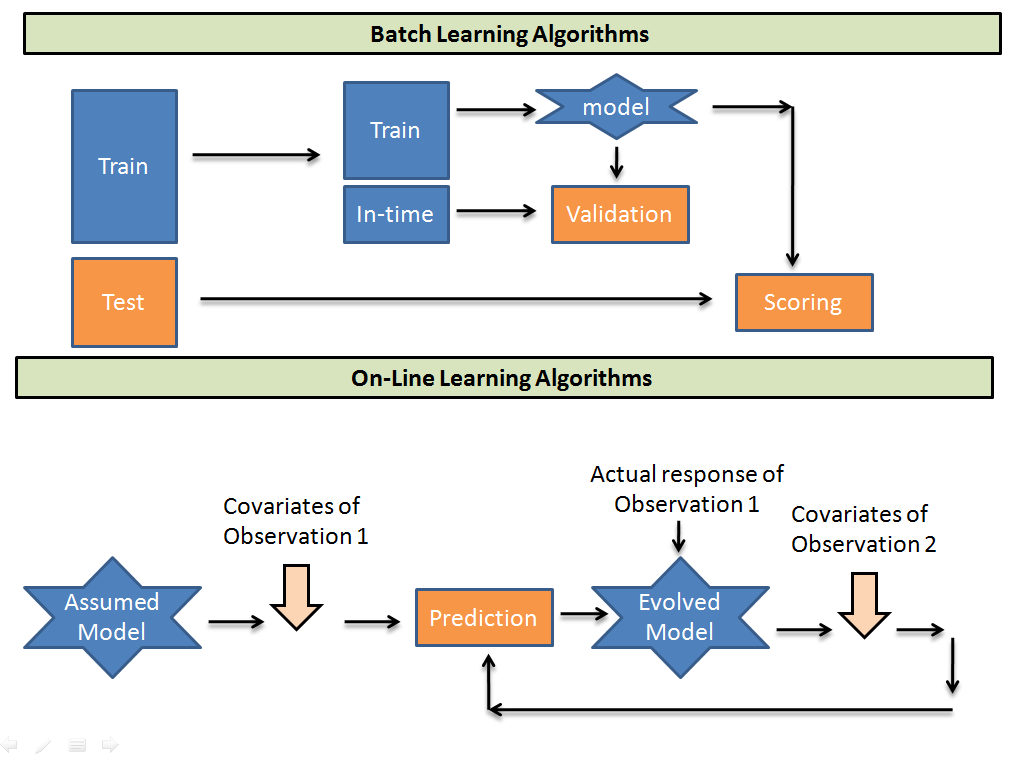
Batch Serving
정해진 주기로 대량의 데이터를 묶어 한번에 처리
-
일정 주기로 생성되는 예측 결과를 DB에 저장해서 서빙에 활용
-
비용 효율적인 방식
-
새로운 데이터에 대한 즉각적인 대응이 어렵고, 지연된 결과만 제공 가능함
-
실시간 응답이 중요하지 않거나, 모델의 예측에 시간이 걸릴 때
-
인력이 적은경우 인프라가 갖춰져 있으면 배치가 더 효율적이다.
-
RDB, 데이터 웨어하우스와 같은 형태로 데이터가 저장된다.
Online Serving
실시간으로 요청에 대한 예측값을 생성하고 반환
-
웹 API 형태로 모델을 래핑해서 서비스 제공
-
빠른 프로토타이핑이 가능하고, REST 기반 백엔드와 잘 통합됨
-
GPU가 필요한 경우 호스팅 비용이 높고, 항상 온라인을 유지해야 해서 비용이 많이 소모된다.
-
실시간 응답이 중요하거나 데이터가 동적으로 계속 변할 때 온라인이 더 효율적이다.
-
API 서버나 실시간 처리에 대한 경험이 필요하기 때문에 배치보다 인력이 더 요구된다.
-
요철이 오면 같이 예측 데이터를 제공한다. API나 메세지 식으로 전달된다.
Serving Pattern
-
머신러닝은 그 특수성(Data, Model)으로 인해 별도의 디자인 패턴이 존재한다.
-
모델이 존재하는 예측 서버와 서비스가 동작하는 서비스 서버가 나눠질 수 있다.
-
Batch 패턴 하나와 Online 패턴 3가지를 정리해보려 한다.
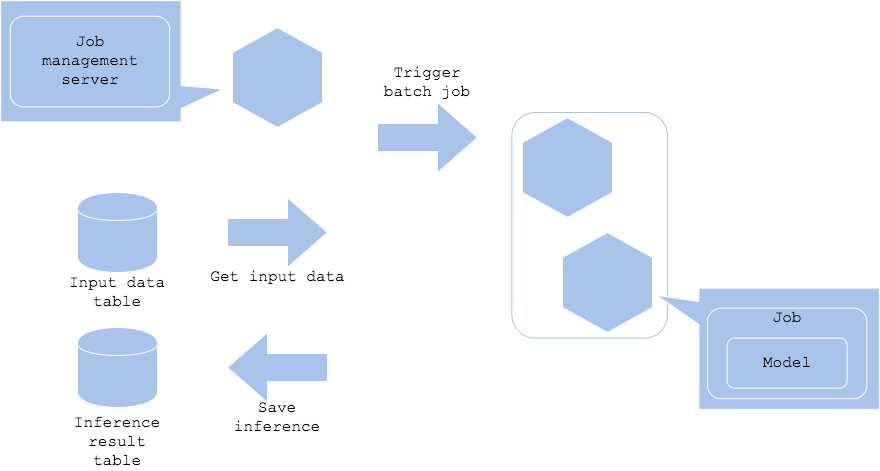
1. Batch Pattern
 이미지 출처 : mercari
이미지 출처 : mercari
-
주기적으로 input data를 모델에 넣어 예측 output을 생성해 결과를 DB에 저장.
-
저장된 결과를 서비스 서버가 DB에 주기적으로 접근해 추천 결과를 노출
-
Job Management Server
Apache Airflow를 주로 사용해서 특정 시간에 주기적으로 Batch job을 실행한다. -
API 서버 없이 스케쥴러 역할의 Job Management Server만 있으면 된다.
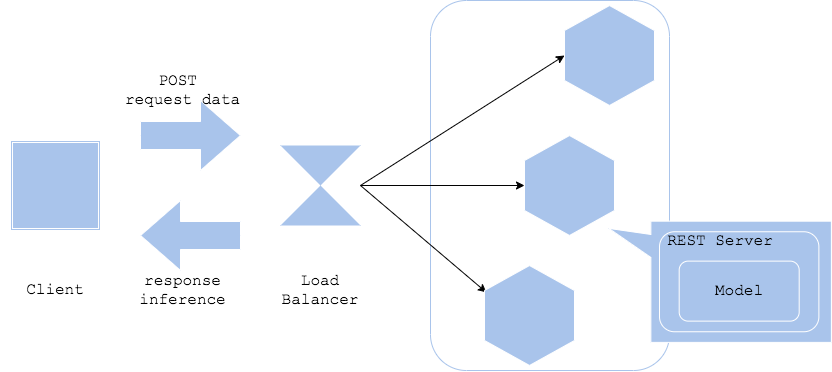
2. Web Single Pattern
 이미지 출처 : mercari
이미지 출처 : mercari
-
API 서버 코드에 모델을 포함시켜서 배포해서 Request가 들어오면 Response로 예측 결과를 반환. 서비스 서버가 이 예측 서버에 요청하는 식으로 진행된다.
-
FastAPI, Flask 등으로 단일 REST API 서버를 개발 후 배포하는 방식으로 진행된다.
-
API 서버가 실행될 때 모델을 로드해서 항상 모델이 켜져있고, 전처리 과정까지 이 서버가 할 수 있다.
-
Request에 데이터를 함께 담아서 요청을 보낸다.
-
하나의 API 서버에서 진행되기 때문에 아키텍처가 단순하고 간단하지만, 구성요소가 바뀌면 전체가 바뀌어야한다. 그래서 online 예측의 가장 기본형태로 웹싱글 패턴으로 시작해 다른 패턴으로 진행하기도 한다.
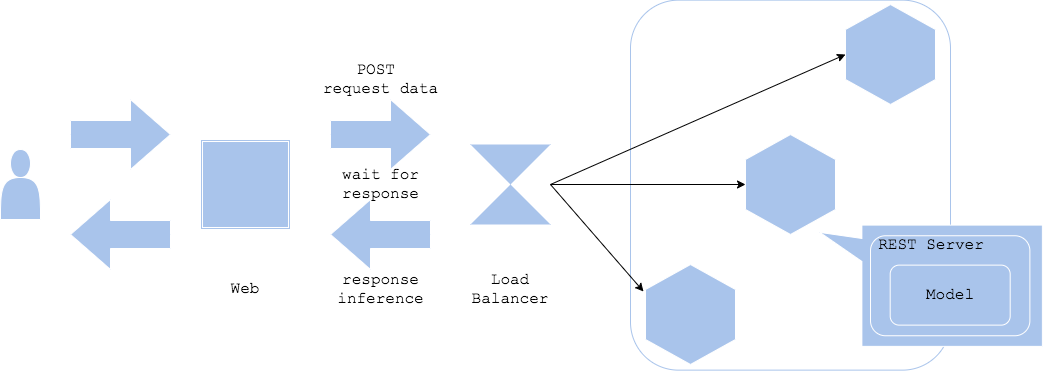
Synchronous Pattern
 이미지 출처 : mercari
이미지 출처 : mercari
-
Synchronous : 동기식. 하나의 작업이 끝날 때까지 다른 작업을 하지 않고 기다리는 방식.
-
web single 패턴을 동기적으로 서빙. 대부분의 REST API 서버는 동기적으로 서빙한다.
-
예측이 완료될 때까지 프로세스가 다른 작업을 안하기 때문에 단순하다.
그렇기 때문에 병목현상이 발생하고 사용자가 몰리면 응답 시간이 지연될 수 있다. -
예측 결과에 따라 클라이언트의 로직이 즉각적으로 달라져야하면 동기적으로 진행할 수 밖에 없다. 보통 예측결과를 기다려 달라고 뜨면 동기식으로 작동한다고 보면 된다.
Asynchronous Pattern
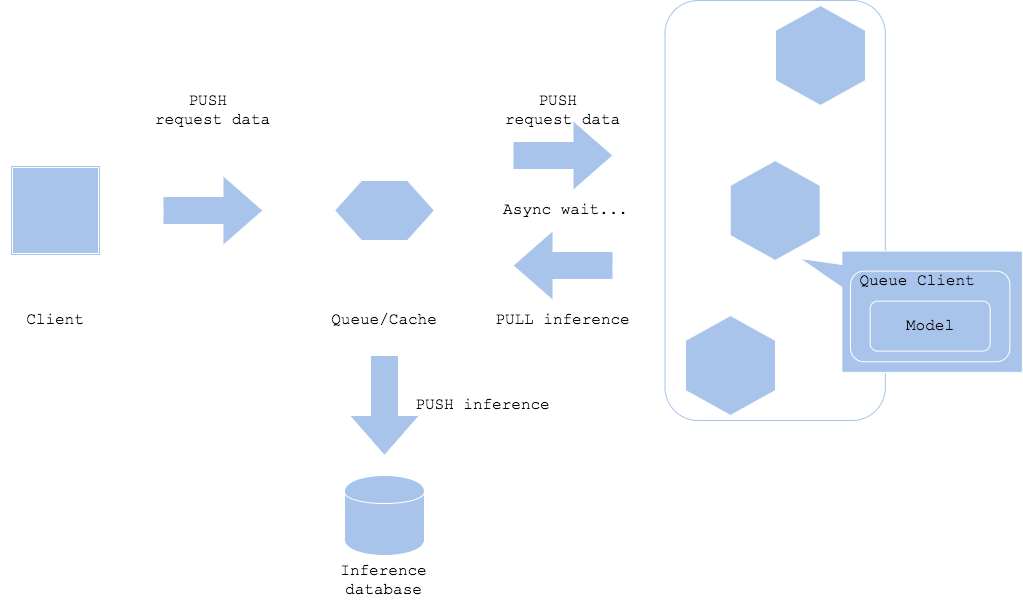 이미지 출처 : mercari
이미지 출처 : mercari
-
Asynchronous : 비동기식. 하나의 작업을 시작하고 결과를 기다리는 동안 다른 작업을 하는 방식. 완료가 되면 시스템이 결과를 알려준다. ex) 음식점의 진동벨
-
클라이언트와 예측을 분리할 수 있고, 클라이언트가 예측 대기 시간을 기다릴 필요가 없다.(당장 결과를 못받아도 최종적으로는 받는다)
-
클라이언트와 예측서버 사이에 Kafka 같은 메세지 큐를 넣는다. 요청과 예측결과가 메시지 큐에 저장되어 순서대로 서빙된다.
-
메시지 큐 시스템을 만드는 과정이 복잡하고, 완전한 실시간 예측이라고 보기 어려운 단점이 있다.
Anti Serving Pattern
권장되지 않는 서빙 패턴
-
Online Bigsize Pattern
Online 패턴에 예측이 오래걸리는 big size의 모델을 사용하는 경우
서버 실행과 서빙이 느려지므로 모델은 반드시 모델을 경량화하는 작업이 필요하다.
배치로 변경하거나 캐시서버를 따로 둬서 과거 동일한 예측을 대체하거나 전처리를 분리하는 대안이있다. -
All-in-one Pattern
여러 모델의 여러 예측을 하나의 서버에서 다 실행하는 경우
다 같은 라이브러리 버전 및 환경을 써야하고, 일부에 장애가 발생하면 전체 시스템이 마비된다.(SPOF) 모델 별로 서버를 분리하는 것이 대안.
