Today I Learned
오늘 배운 내용은 Stable Diffusion 모델!
Stable Diffusion
텍스트나 이미지를 입력하면 고품질의 실사 이미지를 생성할 수 있는 생성형 AI 모델
-
참고 블로그 : pitas
-
LDM(Latent Diffusion Model)에서 일부 구조 개선된 모델
-
Latent Diffusion
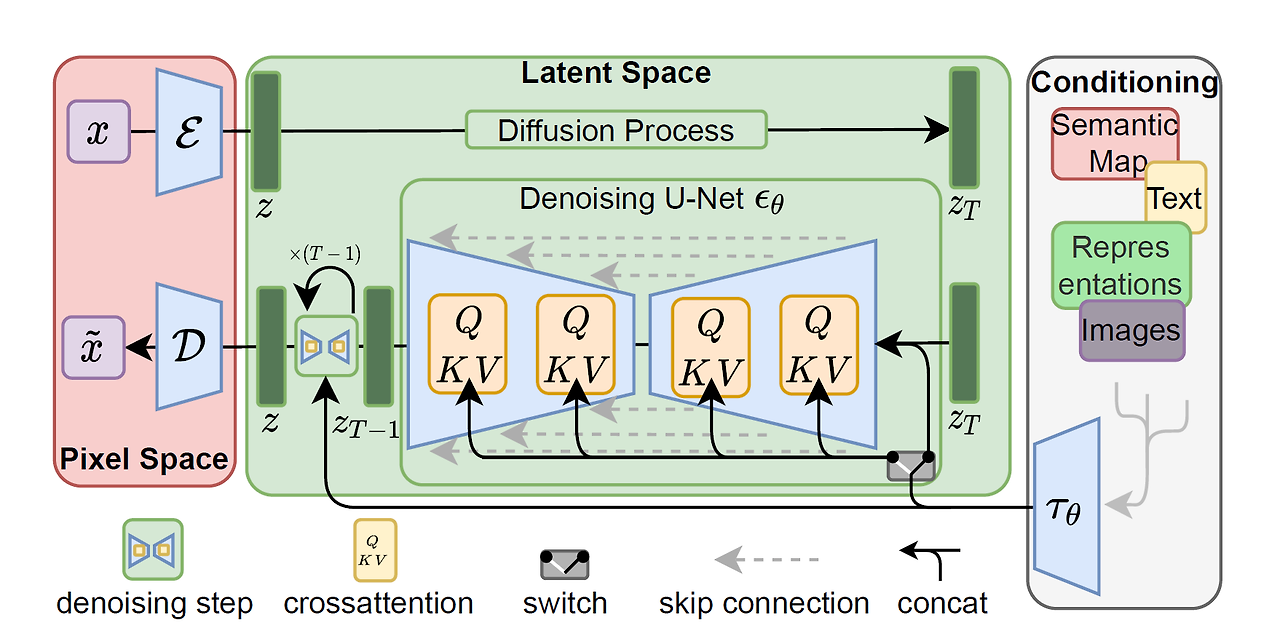 이미지 출처 : 논문
이미지 출처 : 논문
고품질 이미지 생성을 위한 AI 모델
고해상도 데이터를 오토인코더를 사용해 압축된 저차원 잠재공간으로 매핑한다.
압축된 공간에서 diffusion 모델을 훈련해 적은 컴퓨팅 요구사항으로도 고품질 이미지 합성이 가능하다. 인코딩-확산-역확산-디코딩 과정을 거친다. -
특징
오픈소스 - 코드와 모델이 공개되어있다
다양한 활용 - 이미지 생성뿐만 아니라 비디오와 애니메이션도 제작 가능
대량의 데이터, 많은 GPU, 오랜 학습 시간, 큰 모델(9억이상 파라미터)이 필요하다 -
Autoencoder
SD는 이미지가 아니라 인코더로 저차원 매핑된 잠재변수(latent)를 사용해 빠른 학습 및 생성이 가능하다. -
text encoder
text input을 임베딩 형태로 바꾸기 위해 인코더로 BERT 대신 CKIP Text Encoder를 사용한다.
77개 토큰으로 맞춰 최종 토큰 임베딩 사이즈는 [B, 77, 768]의 사이즈를 가진다.
한 토큰당 768차원의 임베딩 벡터
-
Image Information Creator
U-net : Noise Prediction 담당
Noise Scheduler : Noise 주입 정도를 결정 -
학습
noisy latent, token embeddings, time step을 input으로 받아서 가해진 noise를 예측한다.
실제 노이즈와 예측된 노이즈의 차이를 통해 모델이 학습된다. -
inference
가우시안 노이즈에서 시작해 token embeddings를 input으로 받아 u-net으로 noise prediction을 진행한다. 이를 반복해 노이즈를 계속 제거해 최종 latent를 오토인코더의 decoder를 통해 이미지로 변환한다.
Stable Diffusion 2
2022년 11월에 기존 V1을 업그레이드해 출시된 모델
-
해상도 향상
512x512 및 768x768 해상도에서의 이미지 생성을 기본으로 지원하며, 이미지의 품질과 디테일이 크게 개선 -
노이즈 처리 개선
v-objective(v-prediction, v-diffusion)를 활용한 새로운 학습 방식을 도입하여 이미지 생성의 안정성이 향상 -
OpenCLIP을 새로운 텍스트 인코더로 도입
-
text 외에도 depth로 생성이 가능한 Depth2img 도입
Stable Diffusion XL
2023sus 7월에 출시된 차세대 image generation model
-
훨씬 현실적인 이미지 생성 가능
-
향상된 해상도
기본 1024x1024 해상도를 지원하여 이전 버전(512x512)보다 더 큰 이미지를 생성할 수 있다. -
2.6B의 파라미터를 가진 대규모 모델로, 이전 버전의 9.8억 개 대비 7배 이상 증가
-
이중 텍스트 인코더
OpenCLIP ViT-bigG와 CLIP ViT-L을 함께 사용하여 더 정확한 텍스트-이미지 매핑을 제공 -
Refiner 모델
Base 모델과 Refiner 모델의 2단계 구조를 통해 이미지 품질을 더욱 향상 -
이후 SDXL Turbo도 출시
Evaluation
이미지 생성의 평가 방법
- Inception Score
- 생성된 이미지의 fidelity(질, 특정 클래스를 명확히 표현하는가)와 diversity(다양성, 다양한 클래스가 생성되는가)를 동시에 측정
- Inception v3 모델을 이용해 생성된 이미지를 분류한다.
- 생성된 이미지의 likelihood 분포를 이용해서 scoring을 한다. 높을수록 좋다.
- label 분포와 marginal 분포의 KL divergence로 scoring을 한다.
- FID Score
- pretrained image classification model을 활용해 추출한 벡터간의 거리를 score로 활용
- 거리는 프레쳇 거리로 측정한다. 두 곡선의 유사도를 측정하는 지표다.
- 거리가 가까우면 실제 이미지와 비슷한거니, 점수가 낮을수록 좋다.
- CLIP Score
- 이미지와 caption간의 상관관계를 평가하는 지표
- caption으로부터 clip을 이용해 생성된 임베딩과 이미지로부터 CLIP을 이용해 생성된 임베딩간의 코사인 유사도를 측정한다.
- 점수가 높을수록 좋다.
