Today I Learned
오늘은 부캠 휴일이지만 진도를 나갔다!
LoRA
Low-Rank Adaptation
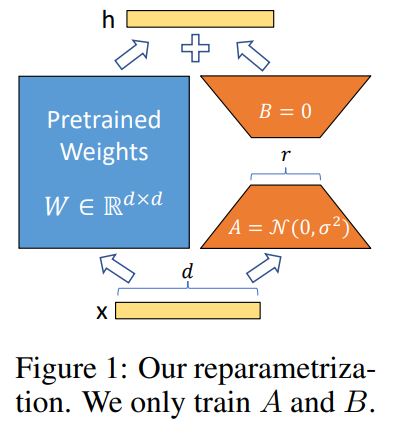 이미지 출처 : LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS (2021)
이미지 출처 : LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS (2021)
-
기존 모델의 가중치는 고정(frozen)한 상태에서 트랜스포머의 각 층에 랭크 분해 행렬을 병렬적으로 위치시켜 추론의 지연이 발생하지 않는다.
cf. 기존 apapter 방식은 기존 파라미터와 직렬구조. -
비선형함수도 쓰지 않고, bias 파라미터는 학습하지 않기 때문에 특히 추론 속도에서 효율적이다.
Adapter vs LoRA
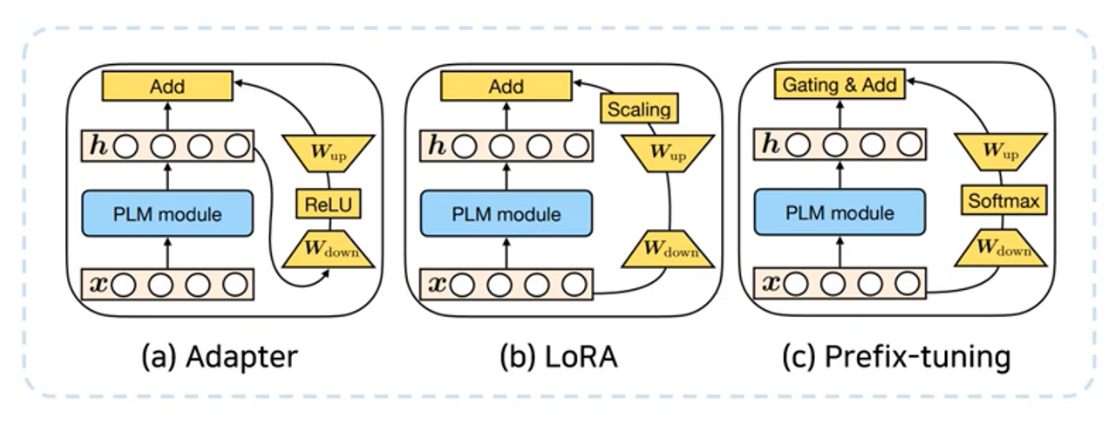 이미지 출처 : mari970
이미지 출처 : mari970
-
Adapter
직렬(sequential) 방식 연산, 추가 비선형 함수, weight과 bias 둘 다 학습
-
LoRA
병렬(parallel) 방식 연산, 비선형 x, weight만 학습. 따라서 연산 지연 거의 x
Advanced PEFT
AdapterFusion
모듈화된 Adapter를 결합해 전환 없이 모델이 task를 선택해 빠르게 수행할 수 있는 기술
-
1단계 : 지식 추출
각 작업별로 어댑터가 파라미터를 학습해 작업별 정보를 캡슐화 -
2단계 : 지식 결합
첫 번째 단계에서 학습된 여러 어댑터들을 결합
각 어댑터들을 병렬적으로 결합해 한번에 연산하도록하고, 그 과정을 가중합 형태로 진행한다. -
지식결합 과정 상세
사용자의 입력에 따라 가장 적합한 Adapter의 가중치를 측정하는 Attention 모듈만 재학습한다. 이미 학습된 Adapter 및 모델의 파라미터는 고정한다.
이 과정을 통해 학습된 Attention 모듈은 입력에 따라 각 Adapter의 중요도나 적합성을 측정하는 역할을 하고, 이를 통해 어떤 Adapter가 현재 사용자의 입력에 가장 적합한지를 판단하여 가중치를 계산한다
QLoRa
Quantization + LoRA
-
LoRA는 원래 BF16을 사용하는데 이를 4비트 NormalFloat (NF4)를 사용하는 방식
-
이중 양자화(Double Quantization): 양자화 상수를 다시 양자화하여 메모리 사용량을 추가로 감소
-
16비트는 양자화로 4비트로 압축되고, 양자화 상수 0.5비트가 남는데 이걸 0.127비트까지 압축해 최종적으로 16비트 -> 4.127비트까지 압축
