Today I Learned
24년의 마지막날.. 열심히 했지만 후회는 많다..
내년도 화이팅 해보자!!
Distributed Training
병렬 컴퓨팅. 딥러닝 모델의 학습 시간을 단축하기 위한 필수적인 기술인 분산 학습 기술
- 여러 GPU(or device)에 데이터나 모델을 분할해 병렬적으로 훈련하는 기법
Data Parallelism
데이터 병렬화. 동일한 모델을 여러 GPU에 복제하고 GPU별로 각각 다른 데이터로 학습
-
분할된 데이터로 동시에 학습하니
학습시간이 절감된다. -
모든 GPU에 모델을 복제해야하기 때문에 메모리 효율성은 떨어진다.
과정
-
Initialization(초기화)
모든 GPU에 모델을 복제하고, 데이터셋을 minibatch 단위로 나눠서 할당
마스터노드(0번 GPU)가 데이터와 모델 weight를 다른 GPU에 할당한다. -
Forward Pass
각 GPU는 할당받은 데이터에 대해 연산을 병렬적으로 수행 -
Backward Pass
각 GPU에서 독립적으로 계산된 gradient를 하나의 최종 gradient로 합침(평균)
마스터 노드가 병합과 모델의 parameter 업데이트 수행
-
DDP(Distributed Data Parallelism)
마스터 노드에게 병목이 생기는 문제를 해결하기 위해 마스터 노드 자체를 없에고 업데이트에 필요한 값은 서로 공유해 진행. AllReduce 연산으로 모든 GPU가 동시에 업데이트를 한다.
통신쪽의 오버헤드가 일반적인 DP에 비해 적고, 모델 복제가 초기화단계에서 한번만 진행되는 장점이있다. -
PyTorch
torch.nn.DataParallel: 간단하지만 성능이 제한적
torch.nn.parallel.DistributedDataParallel: 더 효율적이고 확장성이 높음
Model Parallelism
모델 병렬화. 대규모 딥러닝 모델을 여러 GPU에 분산하여 학습하는 방법
-
주로 단일 GPU의 메모리로 처리하기 어려운 큰 모델을 다룰 때 사용
평균 GPU 메모리 사용량은 최적화 된다. -
GPU간 통신이 필요하기 때문에 여기서 오버헤드가 발생하고, 모델을 여러 부분으로 나누고 관리하는 것이 기술적으로 복잡하다.
 이미지 출처 : huseinzol05
이미지 출처 : huseinzol05
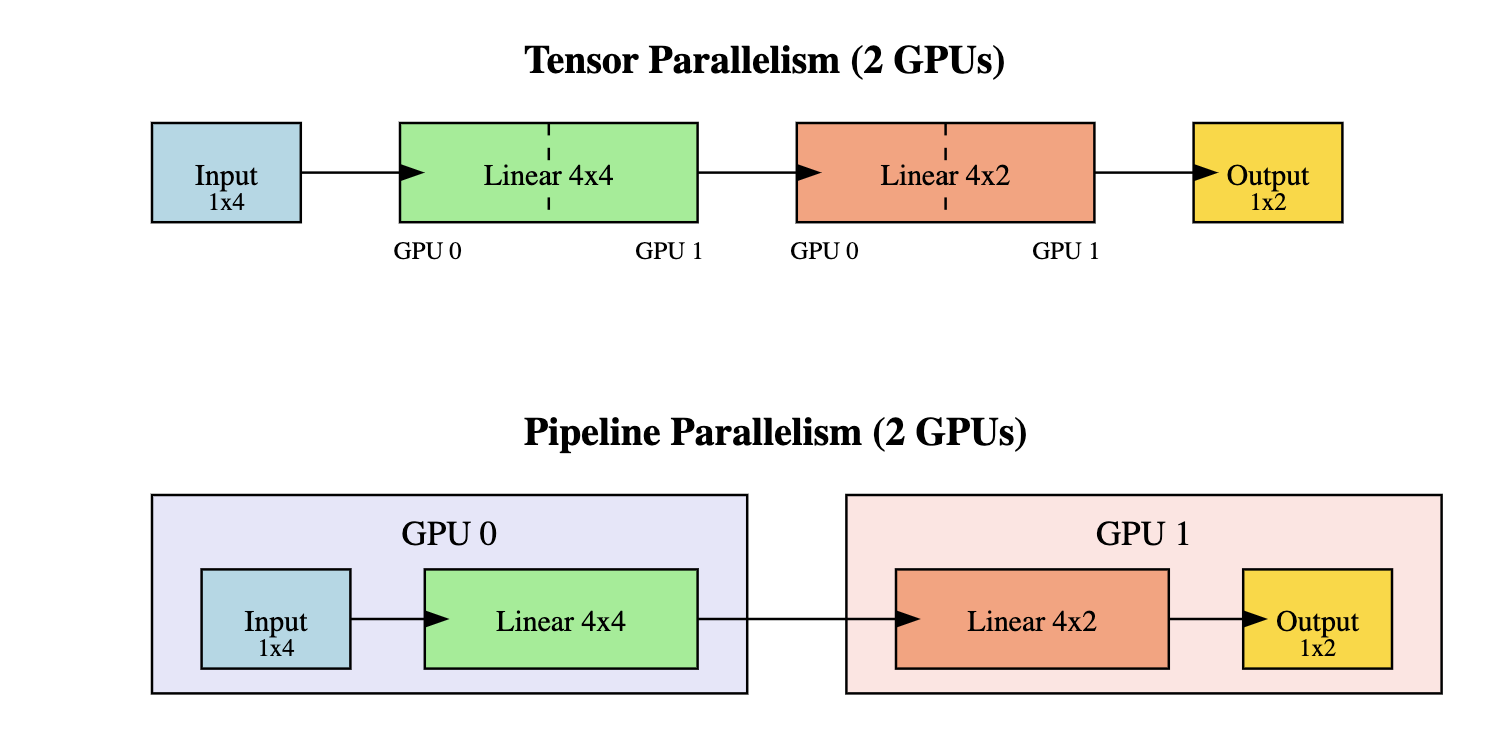
Tensor Parallelism
-
Weight Matrix를 여러 GPU에 분할하여 병렬 연산 수행
-
각 GPU에서 병렬로 연산을 수행한 후 결과를 concatenate
-
행렬 연산을 분산 처리하여 학습 시간 단축 가능하지만 구현이 복잡하다.
-
나누는 방향에 따라 column-wise, row-wise로 나뉜다.
Pipeline Parallelism
-
모델의 layer(층)를 여러 GPU에 순차적으로 분할
-
각 GPU는 이전 GPU의 결과를 받아 다음 layer 연산 수행하기때문에 이전 GPU의 연산이 끝나지 않으면 유휴시간이 발생하는데 이를 pipline bubble이라 한다.
-
유휴시간을 줄이기 위해 batch 사이즈를 더 줄이는 micro batch를 사용한다.
배치 수가 늘면 오버헤드가 늘고, 배치수가 너무 적으면 효율성이 떨어진다. -
forward가 다 끝나야 backward를 하는 동기화 방식과 forward와 backward를 번갈아 하는 비동기 방식이 있다.
-
순차적 처리로 인해 학습 시간 단축 효과는 제한적.
