Today I Learned
오늘은 LLM과 결합한 RecSys를 알아보았다.
Recent RecSys with LLM
-
Large Language Model
큰 규모의 고품질 텍스트 데이터를 기반으로 사전학습된 초대형 딥러닝 모델
수십억개 이상의 매개변수를 포함하는 거대한 신경망 구조를 가진다.
큰 모델 하나로 다양한 task를 수행해서 컨텐츠를 생성하는 생성형 AI -
기존 RecSys의 한계
도메인별로 환경이 달라 일반적인 추천모델이 없다.
그리고 전이 학습(transfer)이 사실상 어렵다.
추천에 대한 설명력이 부족하다. -
최근엔 위의 단점을 LLM의 결합으로 해결하고자 하는 연구가 많아지고 있다.
-
LLM 결합의 장점
feature engineering을 생략할 수 있고, cold start문제를 잘 다룰 수 있다.
전이 학습도 가능하고, 추천 성능과 다양성 향상에 기여할 수 있다. -
단점
LLM만으로는 personalization이 어렵고, hallucination 이슈가 있어 신뢰도가 떨어진다.
그리고 대부분이 아이템간 semantic 유사도에 근거해 collaborative signal을 포착하지 못한다.
LLM + RecSys 결합 방식
-
LLM 임베딩 + RecSys
LLM을 feature extractor로 활용해 유저 아이템 임베딩 학습 후 recsys의 input으로 사용 -
LLM 토큰 + RecSys
위와 비슷하지만 유저와 아이템 임베딩이 아니라 LLM이 출력한 토큰(단어)를 추출해 추가적인 처리를 거쳐 recsys의 input으로 사용 -
LLM 자체를 RecSys로 활용
LLM이 직접 추천 결과를 생성
DLLM4Rec
Discriminative LLM4Rec.
사전학습된 LLM으로 유저와 아이템 임베딩을 추출해 이를 input으로 기존 recsys 사용
-
fine-tuning 학습 방식 (UniSRec)
일반적인 LLM을 추천 task에 맞는 데이터와 loss 맞게 세팅하기 위해
모델 파라미터와 downstream task 학습을 위한 추가 파라미터 튜닝 -
prompt-tuning 학습 방식 (Prompt4NR)
추천 task를 LLM 사전학습 task로 재구성해 추가 loss 없이 학습
추천 프롬프트를 LLM 학습 task 형식으로 구성해 모델 파라미터만 튜닝한다.
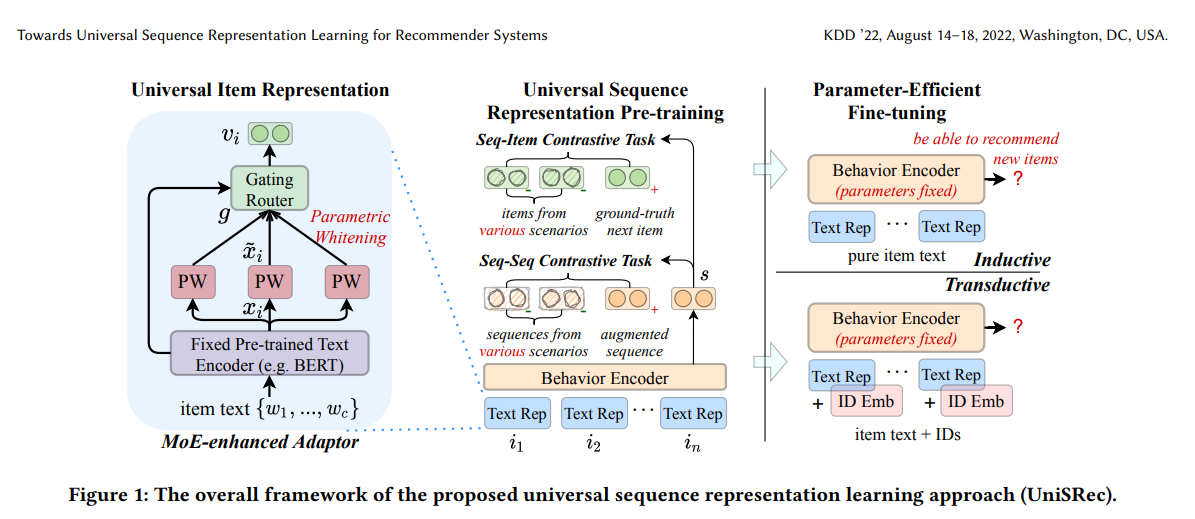
UniSRec
 이미지 출처 : 논문
이미지 출처 : 논문
-
추천 시스템을 위한 범용 시퀀스 표현 학습 방법. 아이템을 구성하는 텍스트를 활용해 전이 가능한 universal item representation을 학습한다.
-
각 아이템 i는 텍스트 시퀀스 로 구성된다.
-
유저는 도메인마다(영화, 책, 옷 등) 각각 아이템 시퀀스를 가진다.
userid, itemid는 따로 만들지 않고모든걸 text로 표현한다. -
Universal Item Representation
여러 도메인의 아이템을 하나의 semantic space에서 표현하는 아이템 임베딩
사전학습된 언어 모델을 통해 아이템 텍스트 인코딩 후 임베딩을 추천 task에 적합하도록 semantic transformation(선형 변환)을 거치고, MoE 기법을 이용해 합쳐 universal 하게 쓸 수 있는 아이템 임베딩으로 생성 -
Universal Sequence Representation
여러 도메인의 아이템시퀀스들을 하나의 semantic space에서 표현하는 Self-attention 기반의 아이템 시퀀스 (유저) 임베딩
Transformer의 인코더로 아이템 시퀀스 임베딩을 만든 후, Sequence-item 대조 학습(같은 시퀀스 끼리 가깝게)을 거치고, Sequence-sequence 대조 학습(같은 도메인의 시퀀스는 가깝게)을 거쳐 아이템 시퀀스 임베딩을 생성 -
아이템별로 여러 개의 whitening embedding을 학습하고 이를 adaptive하게 합침으로써 더 유연하게 universal 임베딩을 만든다.
-
새로운 도메인에 대해 추가학습할 때 전체를 하지 않고, 추가된 학습 파라미터 일부만 fine-tuning해도 된다는 장점이 있다.
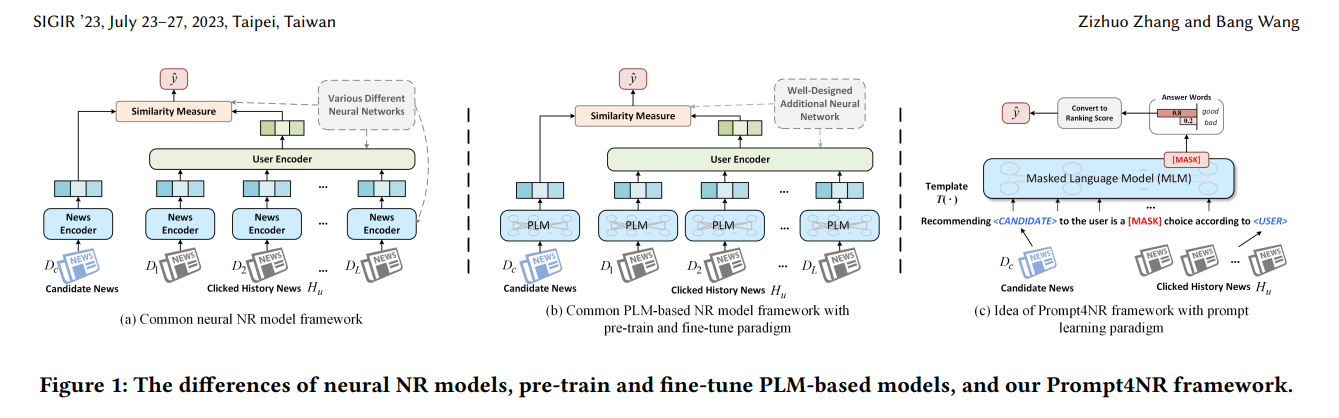
Prompt4NR
 이미지 출처 : 논문
이미지 출처 : 논문
-
뉴스 추천(NR)에 LLM을 사용한 연구
-
뉴스 데이터를 텍스트로 표현해 사전학습된 언어 모델(PLM)을 활용하여 뉴스 표현을 인코딩
-
이산(discrete), 연속(continuous), 하이브리드(hybrid)로 구성된 프롬프트 템플릿을 사용해 여러 프롬프트 템플릿의 예측을 통합하는 앙상블 방식 적용
-
추가 파라미터 필요 없이, 기존 LLM 학습 loss를 사용해 기존 파라미터만 튜닝하는 장점이 있다.
GLLM4Rec
Generative LLM4Rec
LLM이 직접 추천 결과를 생성하는 방식
-
Non-tuning 패러다임 (ChatGPTRec)
사전학습된 LLM이 이미 추천역량이 있다고 보고 파라미터 튜닝 없이 prompting만으로 추천 -
Tuning 패러다임 (P5)
추천 task에 맞게 파라미터를 튜닝해 더 좋은 추천 성능을 이끌어내는 방법
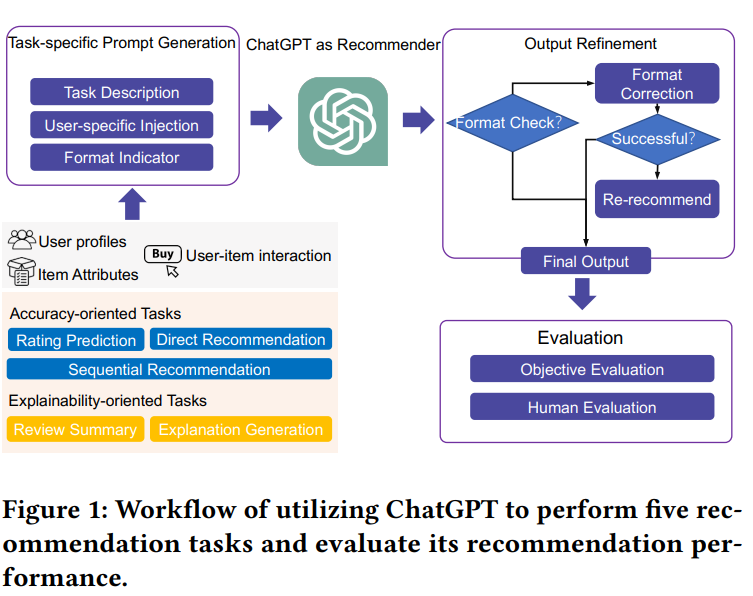
ChatGPTRec
 이미지 출처 : 논문
이미지 출처 : 논문
-
ChatGPT를 범용 추천 모델로 활용할 때 다양한 추천 시나리오에서의 성능을 평가한 실험적 연구
-
평점 예측, 순차적(sequential) 추천, (후보군을 주고)직접 추천, 설명 생성, 리뷰 요약의 5가지 task를 평가함
-
추천 task를 NLP task로 변환하고, 유저-아이템 상호작용 history를 few-shot으로 만들거나 zero-shot으로 프롬프팅. 결과물이 완벽하게 포맷에 맞게는 안나와서 후처리가 필요하다.
-
평점 예측은 soso. 순차와 직접추천은 recsys대비 현저히 낮은 수준.
설명 생성과 리뷰 요약은 인간 평가에서 높은 점수를 획득했다. -
item 본질적인 관계보다는 title의 semantic similarity에 의거해서 추천해주는 수준에 그쳤다.
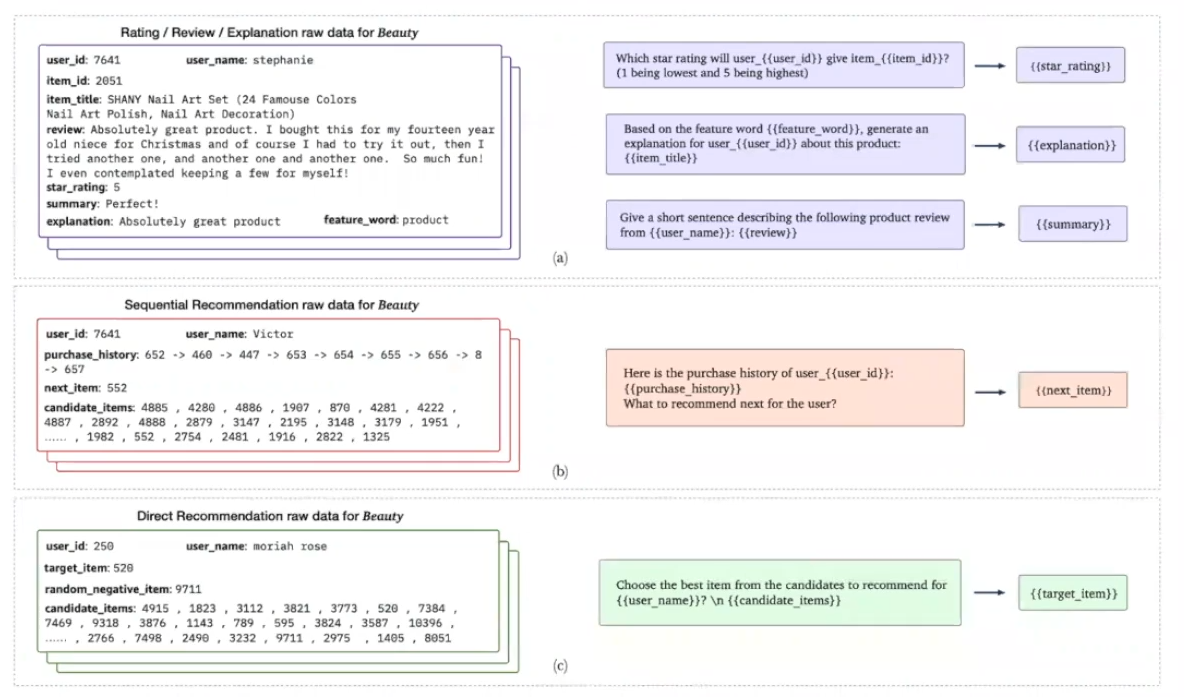
P5
 이미지 출처 : 논문
이미지 출처 : 논문
-
여러 추천 task를 자연어 task로 통햅해 fine-tuning 없이 프롬프트 기반의 사전학습으로 하나의 모델로 여러 추천 task를 풀 수 있는 P5 모델을 제시.
-
모든 추천 관련 데이터를 자연어 시퀀스로 변환하여 처리해, 단일 데이터 형식, 단일 모델, 단일 손실 함수를 사용하여 다양한 추천 작업 수행
-
ChatGPTRec과 같이 5개의 태스크로 테스트.
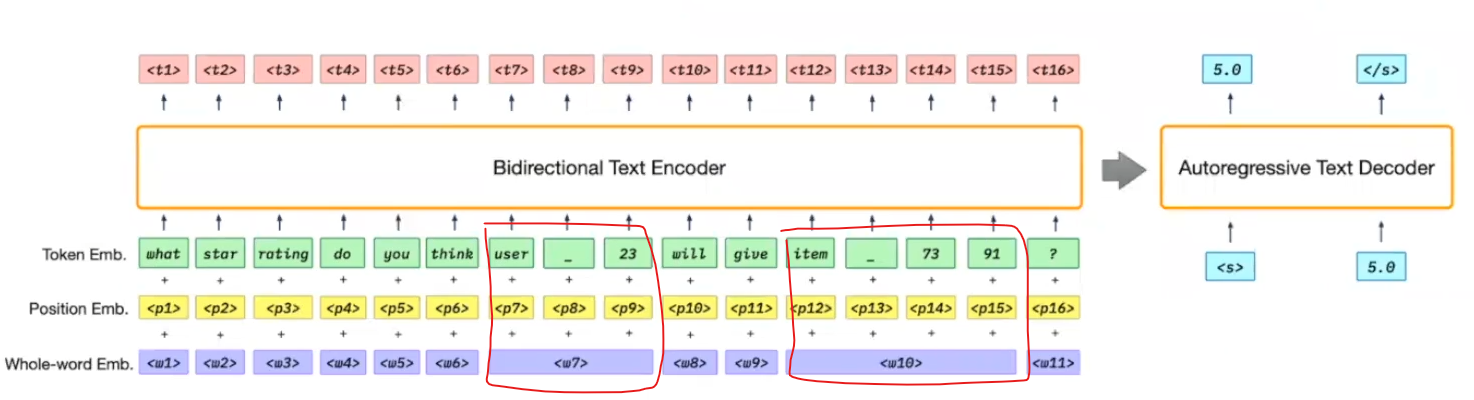 이미지 출처 : 논문
이미지 출처 : 논문
-
userid와 itemid가 따로따로 인식되지 않게 하나의 word 임베딩으로 묶음
-
평점예측은 MF 수준정도까진 나오고, sequential과 직접 추천도 기존 모델 정도로 성능이 꽤 잘나온다.
-
zero-shot으로 도메인 전이도 성능이 꽤 나온다.
ex) toy쪽 추천만 한 유저에게 추가 설명없이 beauty쪽 추천 가능
