Today I Learned
프로젝트 절반지점에서 데이터셋을 변경하게 되었다.
그 이유에 대해서 정리해보고자 한다.
Dataset 변경 이유
기존 데이터셋의 문제
-
기존 anime dataset은 크롤링해온 데이터라서
rating 데이터에 timestamp가 없다. -
데이터셋 선정 당시 side information이 다양해서 이 데이터셋을 선정했으나, 막상 eda단계에서 확인해보니 너무 결측치가 많아(6~70%) 유저쪽 정보는 활용하기 어려워 장점이 많이 사라졌다.
-
그리고 rating에 timestamp가 없으면 단순히 sequential 모델을 못 쓰니까 static한 방식으로 접근하면 되겠다고 어느정도는 naive하게 생각했었다.
-
하지만 rating에 timestamp도 없고, 심지어 순서도 없다면 발생하는 큰 문제가 있었다.
rating에 순서가 없으면 발생하는 문제
-
우선 sequential을 못쓰니 train에 user_id가 없으면 추론하지 못하는 모델들이 많아 train-test 분리 시 user의 rating을 분리해야만 했다.
-
train-test 분리에서 순서가 없으니 흔히들 쓰는 leave-one-out이나 시간에 따라서 분할하는 것이 불가능했다. 그래서 가능한 방법으로 8:2같은 비율에 따라 분리하거나, 유저 당 10개라는 고정식 분리 방법이 있었다.
고정식 분리의 결함
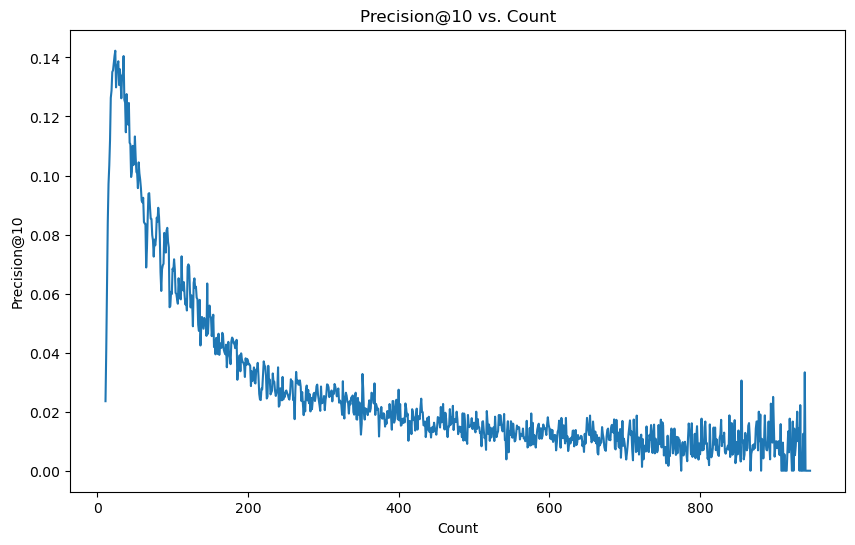
- 위의 그래프는 고정식(유저당 10개) 분리일 때의 유저당 rating 수에 따른 평가지표 그래프다. 참고로 precision과 recall이 분자와 분모가 다 같아져서 동일하게 나온다. 여기서 볼 수 있듯이 극초반을 제외하면 대체적으로 warm한 user일수록 더 추론을 하기 힘든 상황이 발생한다.
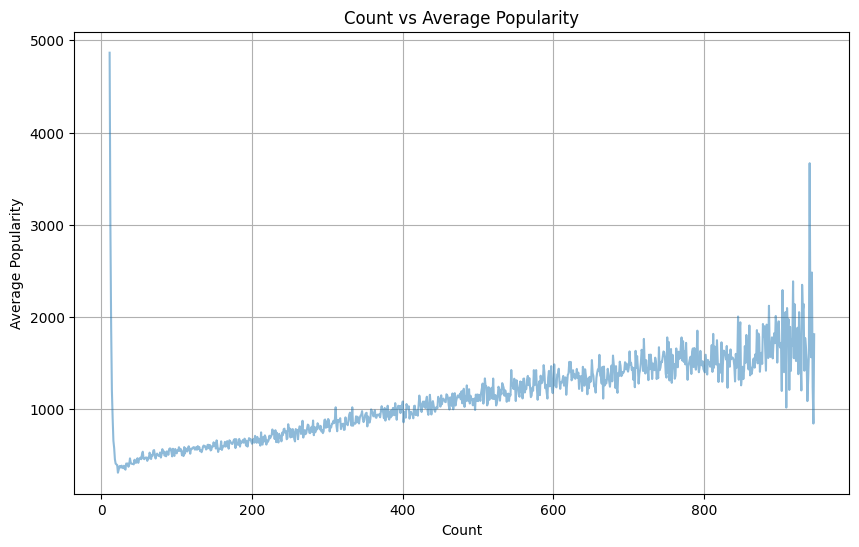
-
유저당 test 셋(정답지)의 인기도를 보면 일반적으로 인기있는 애니메이션을 먼저 시청하는 경향들이 있기 때문에 warm한 유저일수록 인기 없는 애니메이션을 맞춰야하는 문제가 발생해 난이도가 상승한다. 한마디로 인기있는건 이미 다 본 유저는 맞추기 힘들다고 추론했다.
-
그리고 비율적으로만 봐도 30개 본 유저의 10개와 800개 본 유저의 10개가 같지 않다. 800개 본 유저는 10개를 어떤걸 sampling해서 test로 쓰냐에 따라 결과가 확 바뀐다.
비율식 분리의 결함
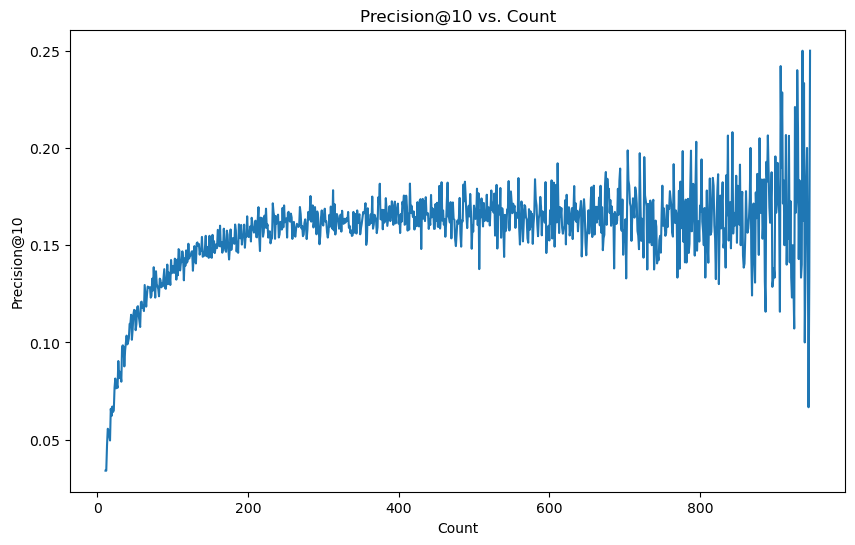
- 비율식으로 test셋을 나누면 precision에서는 위와 같이 흔히들 cold start에서 알고있는 상황이 나온다.
하지만 이 방법이 옳을까? colduser는 정답지 자체가 적기때문에 맞히는게 힘들어서 precision에서 더 과장되게 지표가 안좋아 보일 수 있다.
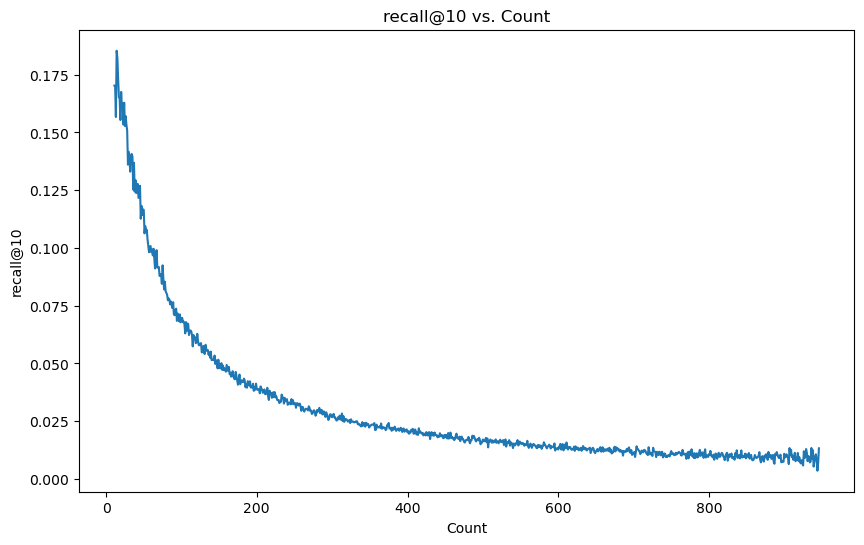
-
하지만 recall을 보면 상황이 달라지는데, warm해질수록 분모가 늘어나 지표가 떨어지는 현상이 발생한다. 이는 정답지 자체가 적기 때문에 하나만 맞춰도 recall값이 매우 커져서 난이도가 쉬워지기 때문이다.
-
즉, 유저별로 정답지(test 데이터의 수)가 달라지기 때문에 신뢰도가 달라져서 비율식 방법도 믿을 수 없다.
따라서 비율, 고정 어떤 방법이든 test 셋을 만들어 cold start 문제를 확인하는 데 어려움이 발생했고, leave-one-out 같은 방식을 사용할 수 없기 때문에 데이터셋을 변경하게 되었다.
-
바꾼 데이터셋은 MovieLens 20m
leave-one-out 같은 online test 시나리오를 흉내낼 수 있는 방법을 사용해 nDCG로 추론해보려 한다. -
이번 일을 계기로 rating에서 timestamp와 순서의 중요성을 뼈저리게 배웠다..
