서론
위코드 11기 웹 크롤링의 두 번째 과제에 대해 발표를 준비하게된 겸해서 블로그에 정리까지 하기로 했다. 과제는 스타벅스 코리아 음료페이지에서 음료의 이름과 그 이미지 URL을 csv 파일에 담는 것이다. Hello World 수준이니 너무 기대는... 하하.. 그럼 시작해보자!
Web Crawling?
웹 크롤링이란 웹 상에서 존재하는 컨텐츠를 수집하는 일이다. 그럼 우리가 수집할 수 있는 컨텐츠는 무엇일까? 답은 간단하다. HTML/CSS 이다. 우리는 HTML을 파싱하기 위해 BeautifulSoup4 라는 라이브러리를 사용하고 브라우저를 조작하여 원하는 데이터를 얻기위해 Selenium이란 라이브러리를 사용할 것이다.
설치
아래에는 미니콘다(아나콘다)가 설치되어 있다고 가정한다. 그리고 필요한 것들을 설치하기 위해 아래의 코드를 실행한다.
conda install beautifulsoup4
conda install selenium셀레니움은 사용할 브라우저의 웹드라이버를 필요로한다. 이곳에서 크롬 웹드라이버를 다운받고 실행시킨다. 다운받을 때 주의할 점은 본인의 크롬 버전과 웹 드라이버의 크롬 버전이 일치해야한다는 점이다!
무엇을 크롤링하는가?
스타벅스 코리아 음료에서 음료의 이름과 그 이미지 URL을 가져오고 싶다. 그럼 개발자 도구를 열고 원하는 엘리먼트를 찾아보자!
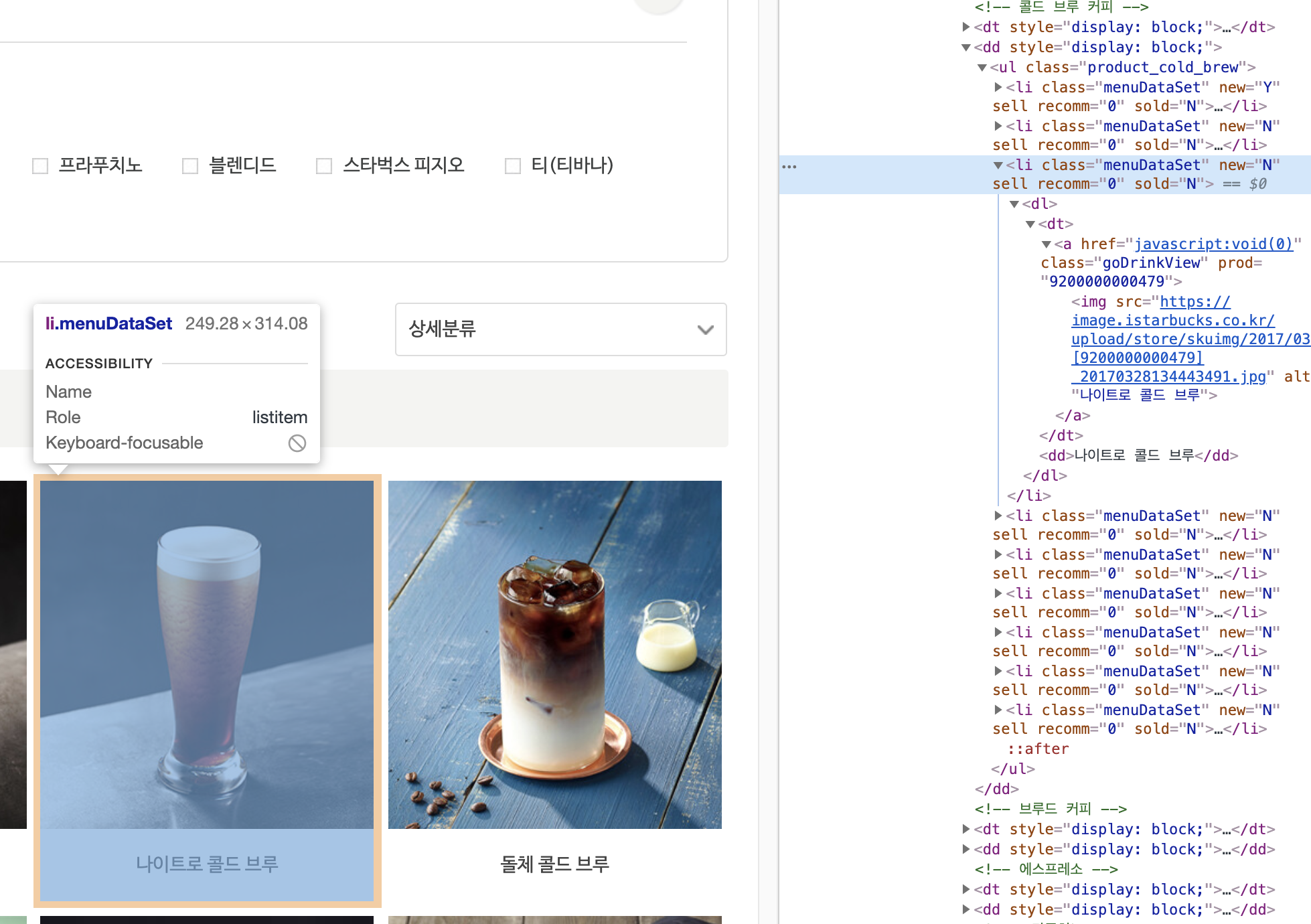
우리는 class가 menuDataSet인 <li> 태그를 찾으면 된다는 것을 알게 되었다. 그리고 그 주위를 잘 살펴보길 바란다! 그럼 코딩을 해보도록 하자!
import
필요한 모듈을 import 해준다.
from bs4 import BeautifulSoup # html parsing
from selenium import webdriver # to manipulate browser
import csv # csv 파일 조작
import re # 정규표현식 사용
# import time 필요하면 사용!
csv 파일 열기
csv 파일에 저장을 해야하는 파일 열기에 대해 보도록하자.
"""
csv 파일 열기
"""
filename = "starbucks_crawling.csv"
csv_open = open(
filename, 'w+', encoding='utf-8')
csv_writer = csv.writer(csv_open)starbucks_crawling.csv 파일을 쓰기모드로 열어서 writer를 얻었다.
크롬으로 원하는 페이지 접속하기
셀레니움의 크롬 웹 드라이버를 이용하여 파이썬 코드로 스타벅스 페이지에 접속이 가능하다.
url = "https://www.starbucks.co.kr/menu/drink_list.do"
"""
크롬 브라우저를 통해 url로 접속한다.
"""
browser = webdriver.Chrome()
browser.get(url)driver.implicitly_wait(5)
지금까지 코드를 실행시킨다면 웹 드라이버가 크롬 창에 url을 넣어서 띄워줄 것이다. 다음에 해야할 일이 파싱을 하는 것인데 창을 띄워주자마자 파싱을하면 이미지와 관련된 요청-응답 시간보다 빨리 코드가 실행되어서 이미지의 url을 찾지 못하는 경우가 있다. 그래서 잠시 기다려주는 코드를 사용한다.
"""
브라우저에서 이미지를 모두 불러오게 하기위해
프로세스를 충분히 쉬어준다.
"""
# time.sleep(10) # 얘도 가능
browser.implicitly_wait(5)
"""
html 소스를 불러온다.
"""
html = browser.page_source마지막 코드는 통신이 끝나기를 기다리며 충분히 쉬어준 후 결과가 반영된 페이지 소스를 가져오는 것 이다.
파싱하기
뷰티풀수프를 사용하여 HTML 파싱을 한다. 우리는 class가 menuDataSet인 <li> 태그를 찾으면 된다는 것을 알고있다. 뷰티풀수프의 findAll 메서드를 사용하여 모든 음료 메뉴 엘리먼트를 가져온다. 그리고 루프를 돌며 <img> 태그를 찾고 그 속성인 src와 alt 속성을 가져온다. alt에는 음료의 이름이 들어 있고, src 속성에는 이미지의 URL이 들어있다. 그것들을 튜플로 묶어 파일에 저장한다.
"""
BeautifulSoup HTML 파서를 불러온다.
"""
bs = BeautifulSoup(html, 'html.parser')
"""
메뉴 정보를 찾아서 이미지 url과 음료 이름을
csv 파일에 저장한다.
"""
drinks_wrapper = bs.findAll(
"li", {"class": re.compile("menuDataSet")})
for row in drinks_wrapper:
img_tag = row.find("img")
img_url = img_tag['src']
title = img_tag['alt']
csv_writer.writerow((title, img_url))리소스 해제하기
파일을 열었으면 닫아주듯이, 웹 드라이버도 실행시키면 종료시켜 주어야한다. close()와 quit()이 있는데, 전자는 브라우저 창만 닫아주고, 후자는 완전히 종료시켜준다.
"""
csv 파일과 웹드라이버를 종료한다.
"""
csv_open.close()
browser.quit()실행 및 결과
실행을 하면 자동으로 브라우저 창이 나오면서 파싱을 하기 시작할 것이다. 그리고 파싱과 파일에 저장이 모두 종료되면 브라우저가 종료될 것 이다. 그리고 결과를 확인하자!
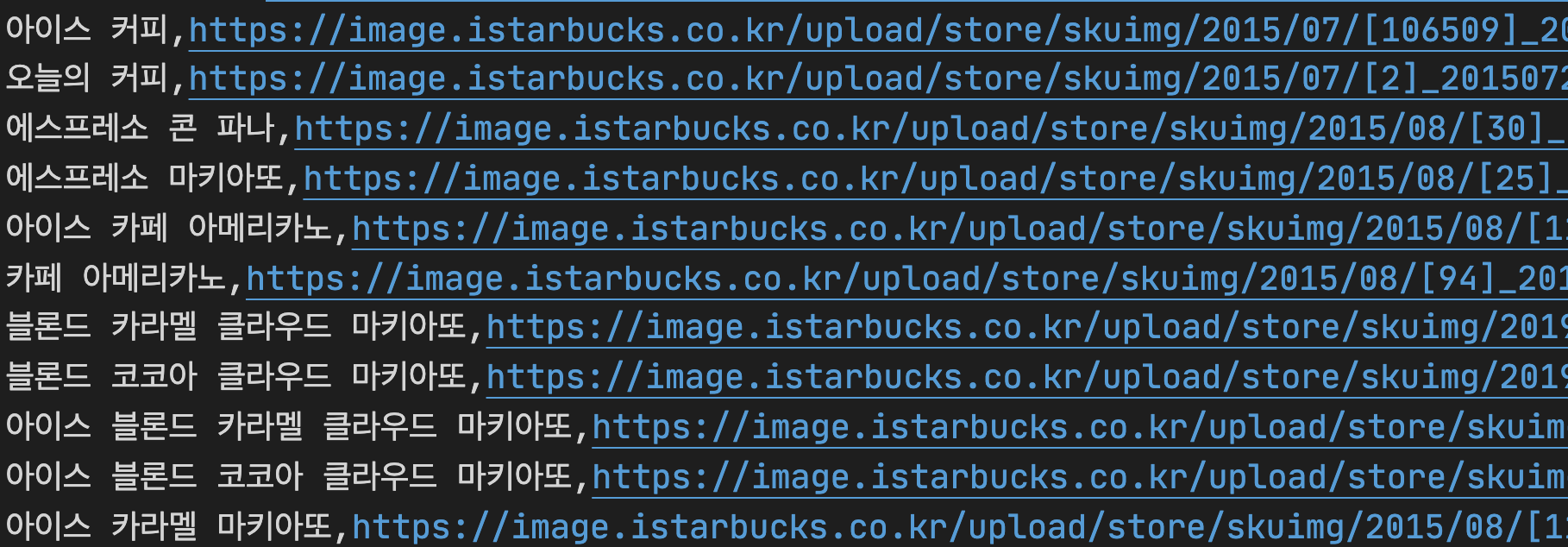
위에는 starbucks_crawling.csv 파일의 내용이다. 음료의 이름과 이미지 URL이 적절하게 들어온 것을 알 수 있다.
결론
일단 느낀점은 커피 이름이 어려워서 주문도 못할 것 같다 ㅋㅋㅋㅋㅋㅋ 🤣. 넝담넝담~ 두 가지 과제를 수행하면서 적당히 어려웠고 적당히 재미있었다. 웹 크롤링에 대해 깊게 알아보고 싶다는 생각이 들어서 관련 책을 하나 장만해볼까 고민이다. 하핫, 다음 세션이 기다려진다 :) !
