DeBERTa: Decoding-enhanced BERT with Disentangled Attention(2020) 논문을 읽고 내용 요약 및 정리
1. Introduction
트랜스포머(Transformer)는 자연어 모델링을 위한 가정 효율적인 신경망 구조가 되어 왔다. 시퀀스에서 텍스트를 처리하는 순환 신경망(RNNs)와 달리, 트랜스포머는 self-attention을 적용하여 입력 텍스트의 모든 단어가 어텐션 가중치(attention weight)를 parallel하게 연산하는데, 이 어텐션 가중치는 각 단어가 서로에게 끼치는 영향력을 측정한다. 따라서 대형 규모 모델 학습에서, RNNs보다 훨씬 더 많은 parallelization을 허용한다. 2018년 이래로, GPT, BERT, RoBERTa, XLNet, UniLM, ELECTRA, T5, ALUM, StructBERT, ERINE과 같은 대규모의 트랜스포머 기반 사전학습 언어모델(PLMs)들이 부흥해 왔다. PLMs는 태스크 명시적인(task-specific) label을 사용하여 파인튜닝되고, 많은 다운스트림 NLP 태스크에서 새로운 SOTA를 달성한다.
본 논문은 2가지 새로운 테크닉(disentangled attention mechanism과 an enhanced mask
decoder)을 활용하여 기존의 SOTA PLMs를 발전시키는 트랜스포머 기반 신경 언어 모델DeBERTa(Decoding-enhanced BERT with disentangled attention)를 새롭게 제시한다.
- Disentangled attention BERT의 입력 레이어의 각 단어가 word embedding과 position embedding의 총합인 단일 벡터를 사용하여 표현된다면, DeBERTa의 각 단어는 content와 position을 각각 인코딩하는 두 개의 벡터를 사용하여 표현되고, 단어간의 어텐션 가중치가 각각 content와 relative position에 기반한
disentangled matrices를 사용하여 연산된다. 이는 한 단어의 어텐션 가중치가 content 뿐만 아니라, relative position에도 의존한다는 견해를 기반으로 한다. 단어 “deep”과 “learning”을 예로 들면, 두 단어가 다른 문장에 있을 때보다 옆에 있을때 두 단어 간 의존성이 더 강력해진다.
- Enhanced mask decoder BERT와 유사하게, DeBERTa는 마스크 언어 모델링(MLM)을 사용하여 사전학습된다. MLM은 빈칸을 채우는 태스크로, 모델이 마스크 토큰의 주변 단어를 사용하여 마스킹 된 단어가 무엇인지 예측하도록 학습된다. DeBERTa는 MLM을 위한 context word의 content와 position 정보를 사용한다. disentangled attention mechanism은 context word에 대한 content와 relative position을 먼저 판별하지만, 대부분 예측에 상당히 중요한 요소인 단어의 absolute position은 먼저 판별하지 않는다. “a new store opened beside the new mall”라는 문장에서 “store”와 “mall”이 마스킹되었다고 가정해보자. 두 단어의 local context는 유사하지만, 문장에서 두 단어의 구문론적(syntactic) 역할이 다르다. (예를 들면, 이 문장에서의 주어는 “store”이지 “mall”이 아니다.) 이러한 구문론적 뉘앙스는 문장의 absolute position에 크게 의존하고, 따라서 언어 모델링 프로세스에서 단어의 absolute position을 고려하는 것이 중요하다. DeBERTa는 모델이 word contents와 position의 aggregated contextual embeddings에 기반한 masked words를 디코딩하는 softmax layer 바로 이전에
absolute word position embedding을 통합한다.
또한, 본 논문은 다운스트림 NLP 태스크를 위해 PLMs를 파인튜닝하는 virtual adversarial training method를 새롭게 제안한다. 이러한 방법론은 모델의 일반화(generalization)를 향상시키는 데 효율적이다.
본 논문은 이러한 테크닉이 사전학습 효율성과 다운스트림 태스크의 성능을 크게 발전시킨다는 것을 comprehensive empirical study를 통해 입증한다.
2. Background
트랜스포머 기반 언어 모델은 트랜스포머 블록 스택으로 구성되어 있다. 각 블록은 완전히 연결된 positional feed-forward network에 뒤따른 multi-head self-attention layer를 포함한다.
표준 self-attention mechanism은 word position 정보를 인코딩하기 위한 natural한 방법이 부족하다. 그러므로, 현존하는 접근법은 positional bias를 각 입력 word embedding에 부가하여, 각 입력 단어 값이 content 및 position에 의존하는 벡터로 표현되도록 한다.
positional bias는 absolute position embedding이나 relatvie positional embedding을 사용하여 시행된다. 본 논문에서 제안한 disentangled attention mechanism은 각 입력 단어를 한 단어의 content와 position을 각각 인코딩하는 2개의 separate vector를 사용하여 표현한다는 점에서 현존하는 모든 접근법과 상이하고, 단어간 어텐션 가중치는 각각 content와 relative position의 disentangled matrices를 사용하여 연산된다.
대규모의 트랜스포머 기반 PLMs는 전형적으로 MLM(masked language model)라고 알려진 self-supervision을 사용하여 objective contextual word representation을 학습하기 위해 대형 텍스트로 사전학습된다.
특히, 시퀀스 가 주어질 때, 해당 시퀀스의 토큰 15%를 임의로 마스킹함으로써 를 손상시키고, 이후 컨디셔닝 된 에서 마스킹 된 토큰 를 예측함으로써 를 재구성하기 위하여 로 파라미터화된 언어 모델을 학습시킨다.
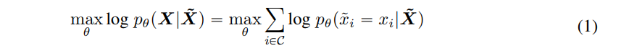
다음 식에서 는 시퀀스에서 마스킹된 토큰 인덱스의 집합이다. BERT의 저자는 10%의 마스킹 된 토큰을 변경하지 않은 상태로 유지하고, 다른 10%는 임의로 선택된 토큰으로 대체하며, 나머지를 [MASK] 토큰으로 대체하는 것을 제안했다.
3. The DeBERTa Architecture
시퀀스 내 포지션 의 토큰은 포지션 의 토큰으로 각각 content와 relative position을 나타내는 2개의 벡터 {}와 {}를 사용하여 표현한다. 토큰 와 간의 cross attention score 연산은 다음과 같이 4개의 컴포넌트로 분해시킬 수 있다.

즉, 단어 쌍의 어텐션 가중치는 content-to-content, content-to-position, position-to-content, position-to-position과 같이 content와 position에 대한 disentangled matrices를 사용하여 4개의 어텐션 스코어의 총합으로 연산될 수 있다는 것이다.
relative position encoding에 대한 현존 접근법은, 어텐션 가중치를 연산할 때 relative position bias를 연산하기 위한 sepearate embedding matrix를 사용한다. 이는 식(2)의 content-to-content 또는 content-to-position term만 사용하여 어텐션 가중치를 연산하는 것과 동등하다. 본 논문에서는 단어 쌍의 어텐션 가중치가 content 뿐만 아니라, content-to-position과 position-to-content term을 모두 사용해야만 fully modeling 될 수 있는 relative position에도 의존하기 때문에, position-to-content term도 중요하다고 주장한다. 본 논문에서는 relative position embedding을 사용하므로, positon-to-position term은 부가적인 정보를 많이 생성하지 않으며 따라서 본 식 (2)에서 제거된다.
single-head attention을 예로 들면, 표준 self-attention 연산은 다음과 같이 형성된다 :
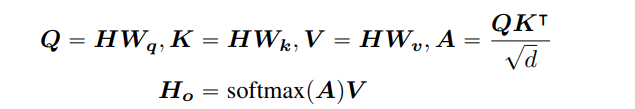
본 식에서 는 input hidden vector, 는 self-attention의 output, ,, 는 projection matrics를, 는 attention matrix를, 은 input sequence의 길이를, 그리고 는 hidden state의 dimension을 나타낸다.
k를 최대 relative distance, 를 토큰 부터 까지의 relative distance로 나타내며, 다음과 같이 정의된다.
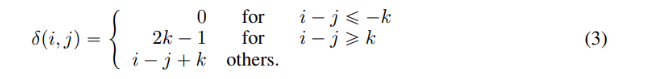
다음 식 (4)와 같이, disentangled self-attention을 relative position bias로 나타낸다. 는 각각 projection matrices projected content vectors이고, 는 모든 레이어에서 공유하는 relative position embedding vectors를 나타내며, 과 은 각각 projection matrices 를 사용하여 생성된 projected relative position vectors이다.
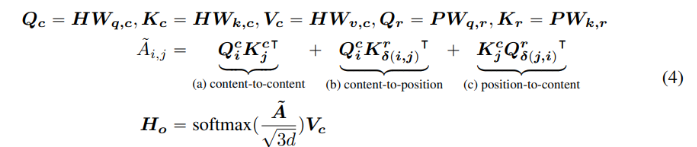
는 attention matrix 의 엘리먼트로, 토큰 ~의 어텐션 스코어를 나타낸다. 는 의 번째 행이다. 는 의 번째 행이다. 는 relative distance 에 대한 의 번째 행이다. 여기서는 보다 를 사용하도록 한다. 이는 주어진 position 에서, position-to-content가 에서 의 쿼리 포지션에 대한 핵심 content의 어텐션 가중치를 연산하기 때문으로, 따라서 relative distance가 이 된다. position-to-content term은 으로 연산된다. content-to-position term 또한 유사한 방법으로 연산된다.
마지막으로, 에 의 scaling factor를 적용한다. 이 factor는 PLM과 같은 대규모 모델학습에서 모델 학습을 안정화하는 데 특히 중요하다.

입력 시퀀스 길이 은 각 토큰에 대한 relative position embedding을 저장하기 위해 의 공간 복잡도(space complexity)를 요구한다. 그러나, content-to-position을 예로 들면, 와 모든 possible relative positions의 embedding이 항상 의 부분집합이기 때문에, 모든 쿼리 어텐션 연산에서 을 재활용할 수 있다는 것을 인지해야 한다.
본 논문의 실험 단계에서 사전학습의 최대 relative distance 를 512로 설정한다. Disentangled attention weight는 Algorithm 1을 사용하여 효율적으로 연산될 수 있다. δ은 식 (3)에 따라 relative position matrix가 된다. 즉, 이다. 각 쿼리에 대해 다양한 relative position embedding matrix를 할당하는 것 대신, line 3-5에서처럼 각 쿼리 벡터 를 로 곱한다. 그리고 나서, line 6-10에서처럼 relative position matrix 를 인덱스로 사용하여 어텐션 가중치를 추출한다. position-to-content 어텐션 스코어 연산을 위해, line 11-13에서와 같이 각 키 벡터 를 로 곱함으로써 , 즉 attention matrix 의 컬럼 벡터를 연산한다. 마지막으로, relative position matrix 를 인덱스로 하여, line 14-18에서와 같이 대응하는 어텐션 스코어를 추출한다. 이러한 방법으로, 메모리를 할당하여 각 쿼리에 대한 relative position embedding을 저장하고, 따라서 의 공간 복잡도를 감소시킬 수 있다(과 을 저장하기 위함)
DeBERTa는 마스킹 단어가 무엇인지 예측하기 위해 마스크 토큰 주변의 단어들을 사용하여 학습하는 MLM(masked language model) 방식으로 사전학습된다. DeBERTa는 MLM에서 context word content와 position information을 사용한다. Disentangled attention 메커니즘은 content words의 content와 relative position을 고려하지만, 예측에 중요한 단어의 absolute position을 고려하지는 않는다.
“a new store opened beside the new mall”라는 문장이 주어지고, “store”와 “mall”이 마스킹된다고 가정해 보자. local text만 사용하는 것(예를 들면, relative position과 surrounding words)은 모델이 이 문장에서 store와 mall을 구분하게 하기에는 부족한데, 두 단어 모두 동일한 relative position에 있는 단어 “new”에 뒤따르기 때문이다. 이러한 한계점을 다루기 위해, 모델은 absolute position을 상대적 위치에 대한 보완적 정보로 고려해야 할 필요가 있다. 예를 들면, 앞의 문장에서 주어는 “store”이고, “mall”이 아니다. 이러한 구문론적 뉘앙스는 문장 내 단어의 절대적 위치에 크게 의존한다.
absolute position을 통합하는 두 가지 방법론이 있다. BERT 모델은 입력 레이어에서 absolute position을 통합한다. DeBERTa에서는 Figure 2와 같이 마스킹된 토큰 예측을 위한 softmax layer 이전, 그리고 모든 트랜스포머 레이어 직후에서 absolute position을 통합한다. 이러한 방식으로, DeBERTa는 모든 트랜스포머 레이어에서 relative positions를 포착하고, 마스킹 된 단어를 디코딩할 때 absolute position만 보완 정보로 사용한다. 그러므로, DeBERTa의 decoding component를 Enhanced Mask Decoder(EMD)라 한다. 경험적 연구에서, 이러한 absolute positions를 통합하는 두 가지 방법론을 비교하고, EMD work를 관측한다. BERT와 같이 absolute position를 일찍 통합하는 것은, 모델이 relative position에 대한 충분한 정보를 학습하는 것을 방해할 것으로 추측된다. 덧붙여, EMD는 사전학습 동안 position과 더불어 다른 유용한 정보들을 도입할 수 있도록 한다. 이러한 사항은 후행 연구로 남겨두려 한다.
4. Scale Invariant Fine-tuning
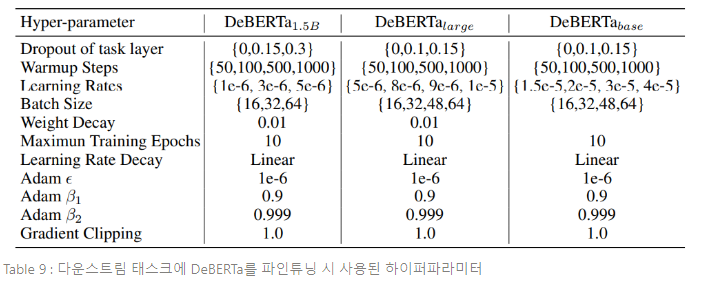
본 섹션은 파인튜닝을 위한 새로운 virtual adversarial 학습 알고리즘이자, Miyato et al.(2018)과 Jian et al.(2020)에서 설명된 알고리즘의 변형인 Scale-invariant-Fine-Tuning(SiFT)을 제시한다.
Virtual adversarial training은 모델의 일반화를 향상시키기 위한 정규화 방법론이다. virtual adverarial training은 입력에 작은 변화(perturbations)를 만듦으로써 생성된 adversarial examples에 모델의 견고함(robustness)를 향상시키며 학습된다. 모델이 정규화되면서 task-specific example이 주어지면, 모델이 해당 example의 adverarial perturbatins를 생성할 때 동일한 output distribution을 생성하게 한다.
NLP 태스크에서, perturbation은 원본 단어 시퀀스가 아닌 word embedding에 적용된다. 그러나, 임베딩 벡터 값의 범위는 각 단어와 모델에 따라 다르다. 이러한 다양성은 수십 억개의 파라미터를 갖는 대형 모델에서는 더 커지고, adversarial training의 불안정성을 야기한다.
Layer Normalization에 영감을 받아, normalized word embedding에 perturbation을 적용함으로써 학습 안전성을 향상시키는 SiFT 알고리즘을 제안한다. DeBERTa를 다운스트림 NLP 태스크에 파인튜닝 할 때, SiFT는 먼저 word embedding vector를 stochastic vector로 normalize하고 나서, normalized embedding vector에 perturbation을 적용한다. normalization은 파인튜닝 모델의 성능을 크게 향상시키며, 더 큰 DeBERTa 모델에서 이러한 향상이 더 뚜렷하다.
5. Experiment
본 섹션은 다양한 NLU 태스크에 대한 DeBERTa 적용 결과를 보고한다.
- performance on LARGE MODELS
Radford et al.(2019)의 BPE vocabulary를 사용한 것을 제외하면, BERT의 설정에 따라 large model을 사전학습한다. 데이터 사전학습에서, Wikipedia(12GB), BookCorpus(6GB), OPENWEBTEXT(Reddit, 38GB), STORIES(CommonCrawl subset,31GB)을 사용한다. 중복 데이터 제거 후 총 데이터 크기는 약 78GB정도이다. 사전학습 데이터셋에 대한 자세한 설명은 부록 A.2에 언급되어 있다.
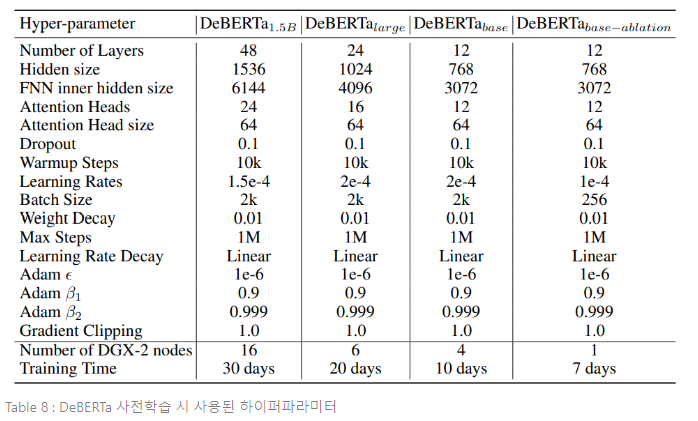
모델 학습은 6 DGX-2 machines로 진행되었으며, 단일 모델은 2k batch size와 1m steps로 약 20일간 학습되었다. 세부적인 하이퍼파라미터 설정은 부록 A에 언급되어 있다.
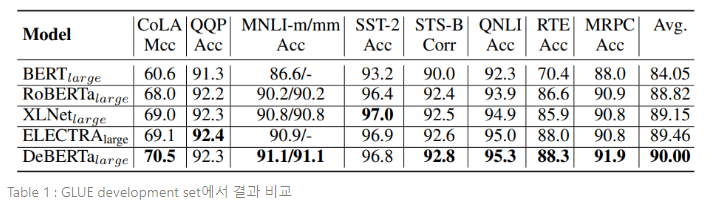
Table 1에서는 GLUE의 8개 NLU 태스크에 대하여 DeBERTa와 유사한 구조인(즉, hidden size가 1024인 24개 레이어로 구성된) BERT, RoBERTa, XLNet, ELECTRA를 포함한 트랜스포머 기반 PLMs의 결과를 비교한다. RoBERTa, XLNET, ELECTRA가 160GB의 학습 데이터로 사전학습 되는 반면, DeBERTa는 78GB의 학습 데이터로 학습된다. RoBERTa와 XLNet은 500k steps동안, 각 step에서 8k samples로 사전학습 되어, 총 40억개의 training sample을 사용한다. DeBERTa는 1m steps동안 각 step에서 2k samples로 사전학습 되어, RoBERTa나 XLNet의 약 반 정도 되는 20억개의 training sample을 사용한다. Table 1은 DeBERTa가 BERT와 RoBERTa에 비해, 모든 태스크에서 꾸준히 좋은 성능을 보인다는 것을 입증한다. 한편, DeBERTa는 8개 태스크 중 6개 태스크에서 XLNet의 성능을 능가한다. 특히, MRPC(XLNet의 1.1%, RoBERTa의 1.0%), RTE(XLNet의 2.4%, RoBERTa의 1.7%), CoLA(XLNet의 1.5%, RoBERTa의 2.5%)가 중대한 차이를 보인다. DeBERTa는 평균 GLUE score에서 다른 SOTA PLMs, 즉 와 모델까지 능가한다.
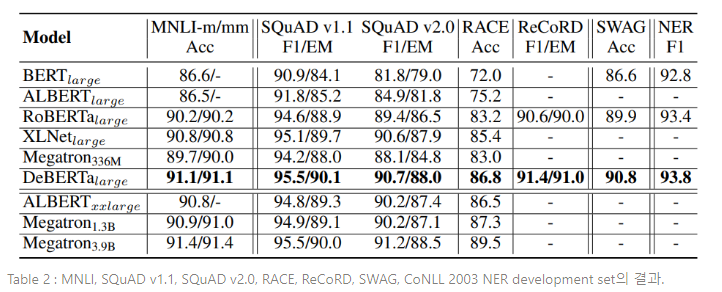
GLUE와 더불어, NLU benchmark 3가지 카테고리로 DeBERTa를 평가한다 : (1) Question Answering : SQuAD v1.1, SQuAD v2.0, RACE, ReCoRD, SWAG (2) Natural Language Inference : MLNI, (3) NER : CoNLL-2003. 비교를 위해, , , , 를 포함시킨다. Table 2에 그 결과가 요약되어 있다. 유사한 모델 크기의 SOTA PLMs를 비교했을 때, (BERT, RoBERTa, XLNet, , ), DeBERTa는 모든 7개 태스크에서 가장 우월한 성능을 보인다. RACE benchmark를 예로 들면, DeBERTa는 XLNet을 +1.4%만큼 크게 능가한다(86.8% vs 85.4%). 가 DeBERTa보다 3배 큰 모델임에도 불구하고, DeBERTa는 4개의 benchmark 중 3개에서 를 능가한다.
- performance on BASE MODELS
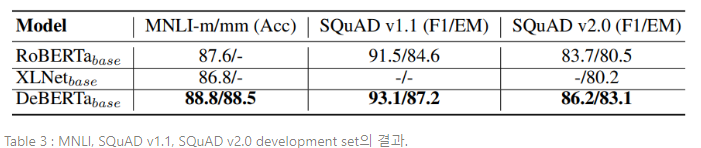
베이스 모델 사전학습 설정은 대형 모델과 유사하다. 베이스 모델 구조는 BERT 베이스 모델 구조를 따른다. 즉, L=12, H=768, A=12이다. 모델 학습은 64V100 GPUs를 탑재한 4DGX-2를 사용하여 진행되었다. 배치 사이즈는 2048로, 1m steps의 사전학습을 끝마치는 데 10일이 소요되었다. DeBERTa는 78GB의 데이터셋을 사용하여 학습되었고, 160GB의 데이터셋으로 학습된 RoBERTa, XLNet과 비교한다. 베이스 모델의 결과는 Table 3에 요약되어 있다. 모든 3개의 태스크에서, DeBERTa는 RoBERTa와 XLNet을 큰 차이로 능가한다.
6. Conclusion
본 논문은 2가지 새로운 기술을 사용하여, BERT와 RoBERTa 모델의 성능을 향상시키는 새로운 모델 구조 DeBERTa(Decoding-enhanced BERT with disentangled attention)를 제시한다.
첫 번째 기술은 disentangled attention 메커니즘으로, 각 단어가 각각 content와 position을 인코딩하는 두 개의 벡터로 표현되며, 단어 간 어텐션 가중치(attention weight)가 각 content와 relative positions의 disentangled matrices를 사용하여 연산되는 것이다.
두 번째 기술은 enhanced attention 메커니즘으로, 모델 사전 학습에서 마스킹 된 토큰 예측을 위해 decoding layer의 absolute position을 통합하는 것이다. 더불어, 파인튜닝 단계에서 새로운 virtual adversarial training method가 다운스트림 태스크에 대한 모델 일반화 성능을 향상시키기 위해 사용된다.
본 논문은 포괄적인 경험적 연구를 통해, 이러한 기술들이 모델의 사전학습 효율성과 다운스트림 태스크 성능을 크게 향상시킨다는 것을 입증한다. 15개의 파라미터로 구성된 DeBERTa 모델은, macro-average score에서 최초로 superGLUE benchmark의 human performance를 능가한다.
Appendix