reading papers
1.Transformer 논문 리뷰

Attention is All you Need(2017) 논문을 읽고 내용 요약 및 정리
2.BERT 논문 리뷰

BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(2018)
3.RoBERTa 논문 리뷰

RoBERTa: A Robustly Optimized BERT Pretraining Approach(2019) 논문을 읽고 내용 요약 및 정리
4.ELECTRA 논문 리뷰
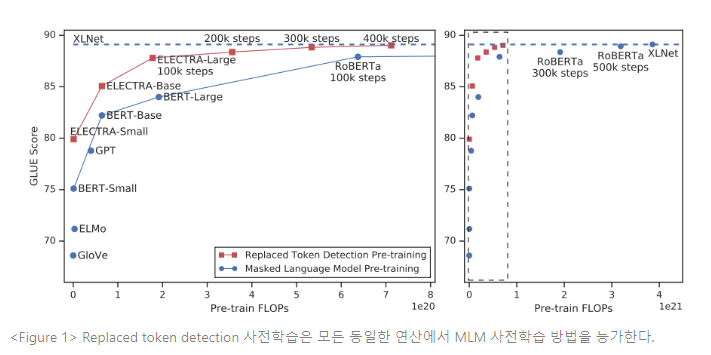
ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THANGENERATORS(2020) 논문을 읽고 내용 요약 및 정리
5.XLNet 논문 리뷰
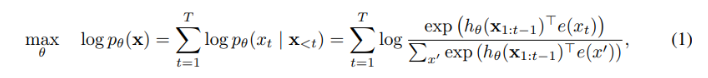
XLNet: Generalized Autoregressive Pretraining for Language Understanding(2019) 논문을 읽고 내용 요약 및 정리
6.DeBERTa 논문 리뷰
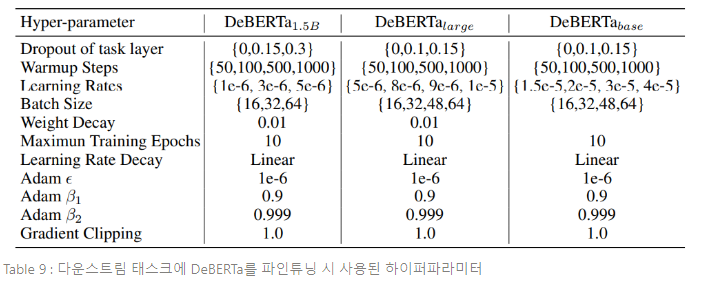
DeBERTa: Decoding-enhanced BERT with Disentangled Attention(2020) 논문을 읽고 내용 요약 및 정리
7.Transformer 기반 최신 NLP 모델 비교

지금까지 스터디한 모델들에 대해서 간단하게 정리, 비교해보고자 한다.
8.ELMo 논문 리뷰

Deep contextualized word representations(2018) 논문을 읽고 내용 요약 및 정리
9.GPT-3 논문 리뷰

Language Models are Few-Shot Learners(2020) 논문을 읽고 내용 요약 및 정리
10.개체명 인식 논문 리뷰
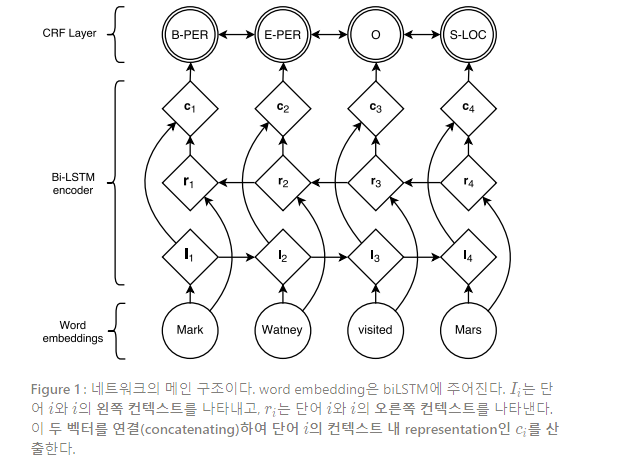
Neural Architectures for Named Entity Recognition(2016) 논문을 읽고 내용 요약 및 정리
11.SBERT(SentenceBERT) 논문 리뷰
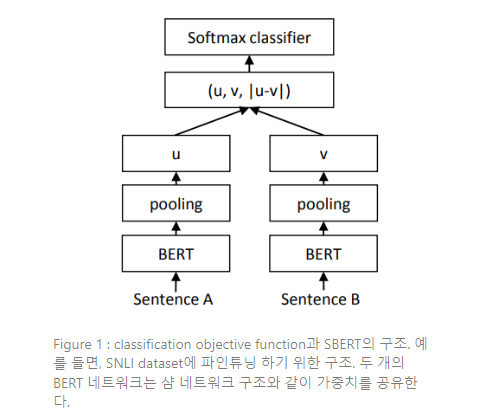
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks(2019) 논문을 읽고 내용 요약 및 정리
12.BART 논문 리뷰

BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension(2019) 논문을 읽고 내용 요약 및 정리
13.Vision Transformer(ViT) 논문 리뷰
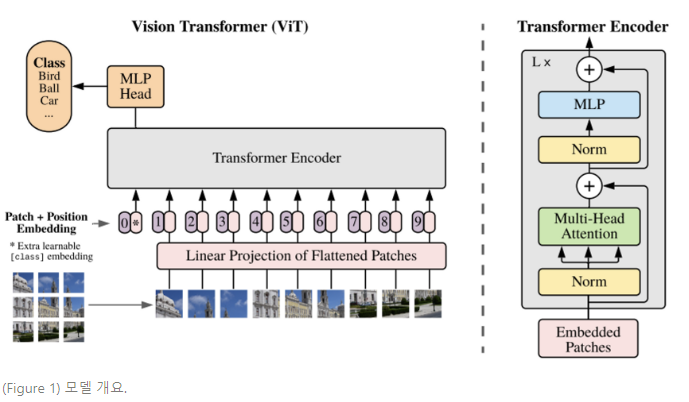
ViT(비전 트랜스포머) 논문 읽기
14.LLMs 전성시대! (Meta) LLaMA, (Stanford) Alpaca 알아보기

LLaMA와 Alpaca 읽어보기
15.T5(Text-to-Text Transfer Transformer) 논문 리뷰
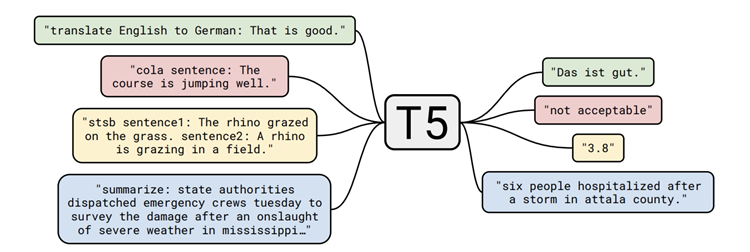
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer(2019) 읽어보기
16.You Look Only Once : Unified, Real-Time Object Detection (YOLO) 논문 리뷰
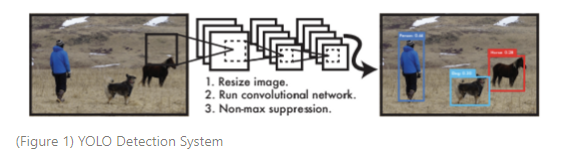
You Look Only Once : Unified, Real-Time Object Detection(2016) Paper Review
17.YOLOv2(2017) 논문 리뷰

YOLO9000 : Better, Faster, Stronger (YOLOv2) 논문 읽기
18.YOLOv9 논문 리뷰

YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information (2024, arxiv) 읽어보기
19.A Survey of Transformers (2021) 논문 스터디 - (1)

A Survey of Transformers (2021) 논문 스터디 - (1)
20.BLIP (2022) 논문 리뷰
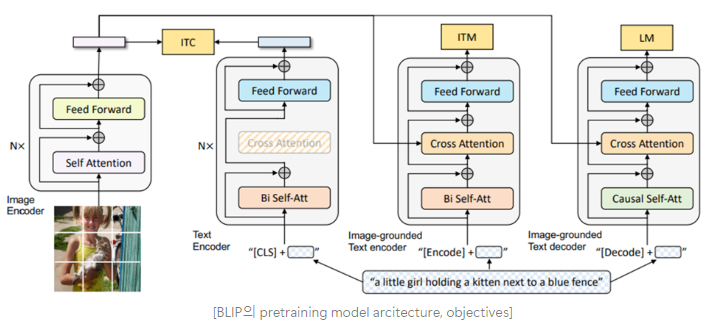
BLIP : Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation (2022, arXiv) paper review
21.LLM-Planner(2023, ICCV) 논문 리뷰

LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models (ICCV 2023) 논문 읽기
22.요즘 핫한 DeepSeek-R1 훔쳐보기

요즘 기술 발전 속도 따라가기 버거운 사람의 DeepSeek-R1 technical report review
23.Qwen 2.5 technical report

읽고 써보는 Qwen 2.5 테크니컬 리포트 리뷰 🫠
24.SayCan (CoRL, 2022) 논문 리뷰

SayCan 읽으라고? 너 누군데?
25.DETR (DEtection Transformer) 논문 리뷰 - (1)

DETR (End-to-End Object Detection with Transformer, ECCV 2020) 논문 리뷰
26.DETR (DEtection Transformer) 논문 리뷰 - (2)

DETR (End-to-End Object Detection with Transformer, ECCV 2020) 논문 리뷰
27.[day-1 논문 핥기] Qwen3 technical report

(DAY 1) Qwen3 technical report review
28.[day-2 논문 핥기] Segment Anything (SAM) paper

(DAY 2) Segment Anything (SAM) paper review
29.[day-3 논문 핥기] GroundingDINO paper

(DAY 3) GroundingDINO paper review
30.[day-4 논문 핥기] RT-1(Robotics Transformer) paper

(DAY 4) RT-1 paper review
31.Qwen3-Next: Towards Ultimate Training & Inference Efficiency

Qwen3-Next post review
32.[day-5 논문 핥기] Retrieval-Augmented Generation (RAG) for Knowledge-Intensive NLP Tasks

(DAY 5) RAG(Retrieval Augmented Generation) paper review
33.[day-6 논문 핥기] LORA: Low-Rank Adaptation of Large Language Models

(DAY 6) LoRA: Low-Rank Adaptation of Large Language Models paper review
34.JiT (Just Image Transformers) 논문 리뷰
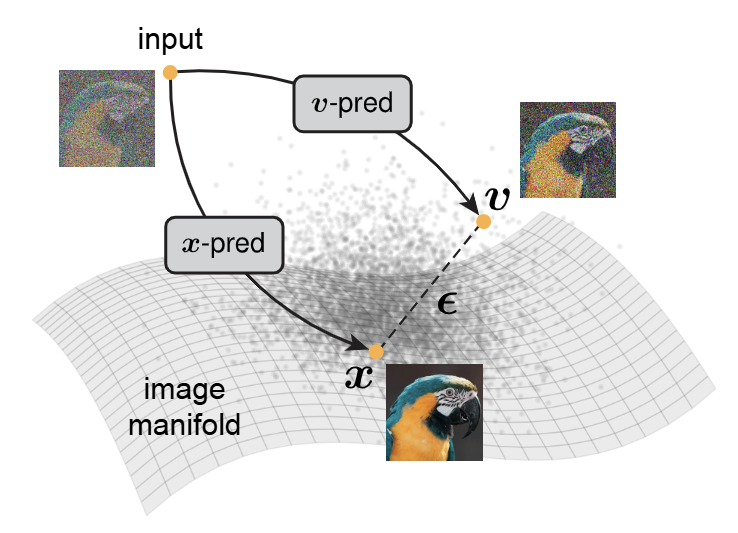
Back to Basics: Let Denoising Generative Models Denoise (2025), JiT 논문 읽기
35.OpenVLA : An Open-Source Vision-Language-Action Model 논문 리뷰

OpenVLA : An Open-Source Vision-Language-Action Model (2024) 논문 읽기
36.π0 : A Vision-Language-Action Flow Model for General Robot Control
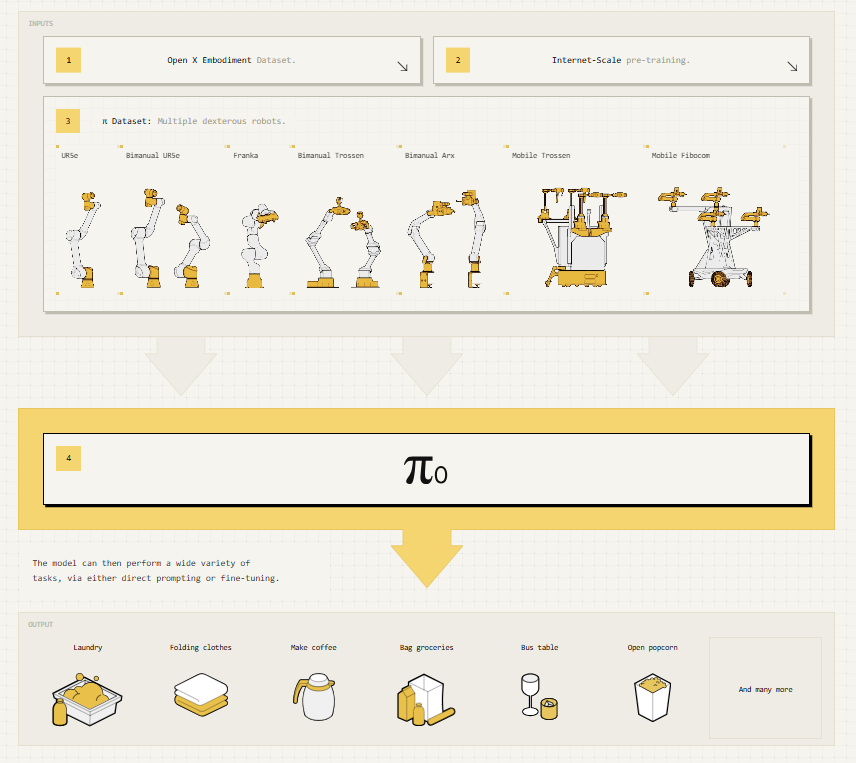
π_0 : A Vision-Language-Action Flow Model for General Robot Control (2024) 읽어보기
37.SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
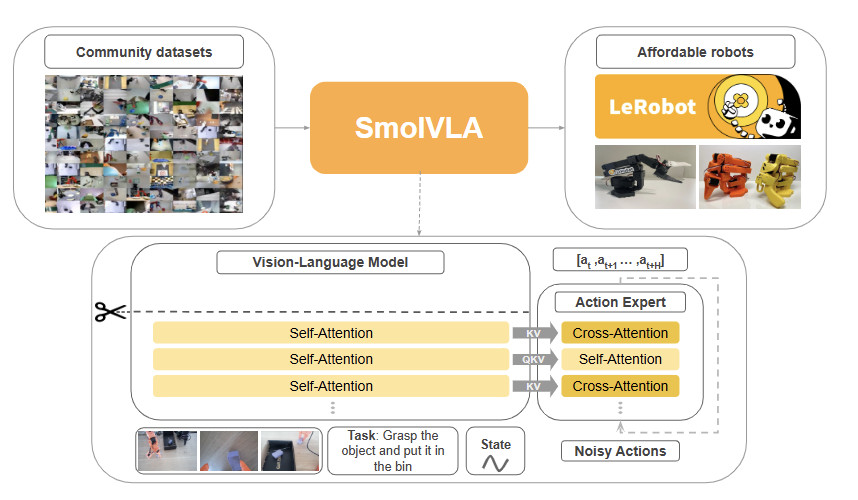
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics (2025) 논문 내용 정리
38.ACT : Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware (2023)
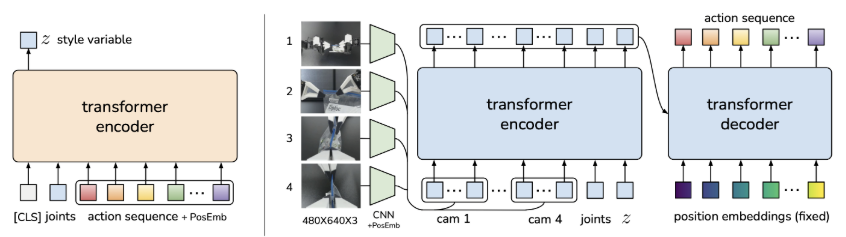
ACT : Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware (RSS 2023) 논문 읽기
39.CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models (2025)
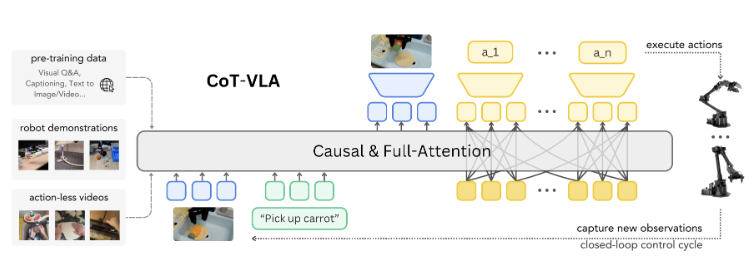
CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models (CVPR 2025)의 논문 내용 정리
40.DAgger : A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning (2011)

A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning (DAgger) paper review
41.PPO: Proximal Policy Optimization Algorithms (2017)

PPO (Proximal Policy Optimization) paper review