ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS(2020) 논문을 읽고 내용 요약 및 정리를 담았다.
1. Introduction
현재 SOTA language representation 학습 방법론은 오토 인코더(auto-encoder)를 denoising하는 방식을 학습하는 방식이다. 이러한 방법론은 라벨링 되지 않은(unlabeled) 입력 시퀀스(통상적으로 15%)의 작은 subset을 선택하고, 이러한 토큰을 마스킹하거나(BERT처럼) 이러한 토큰의 어텐션(attention)을 마스킹하고(XLNet처럼), 그리고 나서 원본 입력을 되찾기 위한 신경망을 학습시킨다. 이러한 MLM(masked language model) 방법론이 bidirectional representation을 학습함으로써, 통상적 언어 모델의 사전학습 방식보다 효율적이긴 하지만, 신경망이 각 example마다 15% 토큰에서만 학습하게 되면서 이러한 접근법은 상당한 연산 비용을 발생시킨다.
이에 대한 대안책으로, replaced token detection , 모델이 종합적으로 생성된 가짜(plausible) 토큰 replacement로부터 실제 입력 토큰을 판별하는 방법을 학습하는 사전학습 태스크를 제안한다. 마스킹 작업 대신, 본 방법론은 일부 토큰을 확률 분포(proposal distribution)에서 추출된 샘플로 대체함으로써 입력 값을 변형시키는 것인데, 이는 전형적인 small MLM의 출력이 된다. BERT의 신경망이 사전학습 과정에서는 인공 [MASK] 토큰을 목격하지만, 다운스트림 태스크에서 파인튜닝 될 때는 인공 토큰을 목격하지 못하는 부조화(XLNet에서는 해당되지 않음)의 문제를 이러한 변형 절차가 해결한다. 그리고, 본 방법론은 모든 토큰이 원본인지 replacement인지 예측하는 판별(discriminator)신경망을 학습한다. MLM은 이 신경망을 변형된 토큰의 원본을 예측하는 생성(generator)로 학습한다. 우리는 판별 태스크(discirminative task)의 핵심 이점은 모델이 small masked-out subset 대신 모든(all) 입력 토큰에서 학습하여 연산을 더 효율적으로 만드는 것이다. 본 접근법은 GAN 모델의 판별 모델 학습을 연상시키지만, GANs를 텍스트에 적용하는 것이 어려우므로, 변형 토큰을 생성하는 생성 몯렝르 최대 우도법으로 학습시킨다는 점에서 우리의 방법론은 적대적(adversarial)이지 않다.
본 논문은 이러한 접근법을 Efficiently Learning an Encoder that Classifies Token Replacements Accurately(token replacement를 정확하게 분류하는 인코더의 효율적 학습), ELECTRA라고 일컫는다.
가장 최신의 사전학습 방법론은 효율적이 되기 위해서 대용량 연산을 필요로 하며, 비용과 접근성 면에서 우려를 발생시킨다. 더 많은 사전학습 연산은 대부분 더 좋은 다운스트림 태스크의 정확도를 산출하기 때문에, 절대적인 성능 뿐만 아니라 연산 효율성이 사전학습 방법론에서 중요한 고려사항이 되어야 한다. 이러한 관점에서 본 논문은 ELECTRA 모델을 다양한 크기로 학습하고, 다운스트림 성능 대비 연산의 필요조건을 평가한다. 실험은 GLUE benchmark와 SQuAD QA benchmark에서 수행되었다. ELECTRA 모델은 같은 모델 크기, 데이터, 연산에서 BERT와 XLNet과 같은 MLM 기반 방법론의 성능을 크게 능가한다. (Figure 1 참조) ELECTRA의 접근법은 대규모 모델에서도 잘 작동한다.
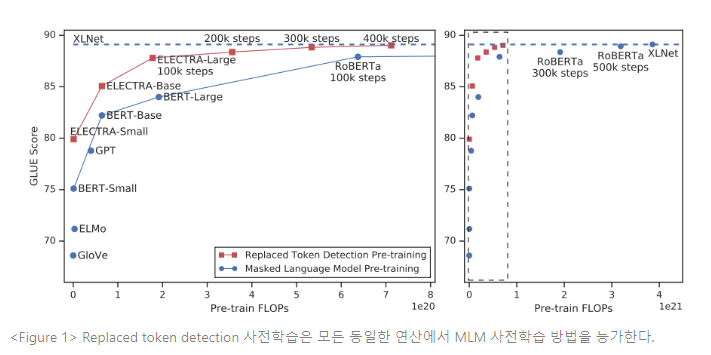
이러한 결과는 실제 데이터를 challenging negative sample과 구분하는 판별 태스크(discriminative task)가 언어 표현 학습(language representation learning)의 현존하는 생성(generative) 접근법보다 연산 및 파라미터적으로 더 효율적임을 입증한다.
2. Method
먼저 우리는 replaced token detection 사전학습 태스크에 대해 설명한다. 다음 Figure 2는 그 개요이다. 이러한 방법론에 대한 몇가지 모델링적 개선사항은 섹션 3.2에서 제시한다.
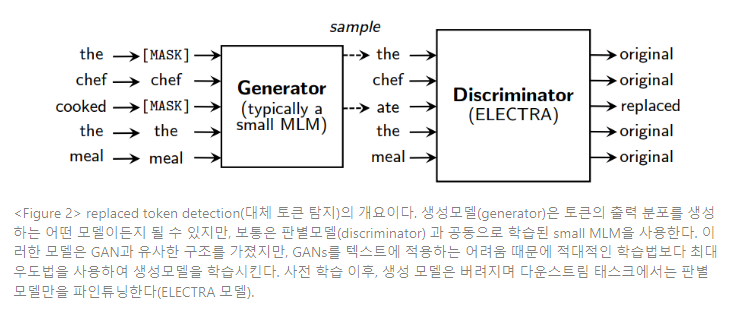
우리의 접근법은 생성모델 G, 판별모델 D라는 2개의 신경망을 학습한다. 각 신경망은 최초 입력 토큰에서 contextualized vector representations인 로 사상시키는 인코더(예로, 트랜스포머 신경망)로 구성된다. 주어진 포지션 , (본 접근법에서는 인 포지션만)에서 생성모델은 소프트맥스 레이어로 특정 토큰 를 생성할 확률을 산출한다.
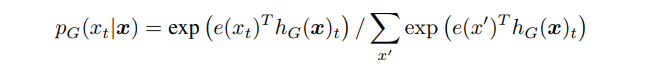
본 식에서 는 토큰 임베딩을 나타낸다. 주어진 포지션 에서 판별 모델은 가 “실제(real)”인지 예측한다. 즉, 토큰 가 생성모델 분포에서 온 게 아닌 실데이터에서 왔는지 시그모이드 출력 레이어로 판별하는 것이다.
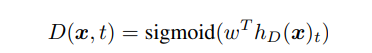
생성 모델은 MLM을 수행하기 위해 학습된다. 입력 이 주어지면, MLM은 먼저 를 마스킹하기 위해 랜덤 포지션 세트(set)를 선택한다(1~n 사이 정수값). 선택된 포지션의 토큰들은 [MASK] 토큰으로 대체된다 : 이를 라 표현한다. 생성 모델은 다음으로 마스킹 된 토큰의 원래 형태를 예측하기 위해 학습된다. 판별 모델은 데이터에서 생성 모델 샘플에 의해 대체된 토큰을 구분하기 위해 학습된다. 즉, 마스킹된 토큰을 생성 모델 샘플로 대체함으로써 변형된 를 생성하고, 의 어떤 토큰이 원본 입력 x와 일치하는지 예측하는 판별 모델을 학습시킨다. 공식적으로, 모델 입력은 다음에 따라 구성된다.
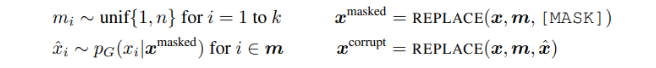
그리고 손실 함수는 다음과 같이 구성된다.

이러한 방법론은 GAN의 학습 objective와 유사하지만, 몇가지 핵심적인 차이가 존재한다.
첫째, 생성 모델이 올바른 토큰을 생성하게 되면 그 토큰은 “가짜(fake)”가 아닌 “진짜(real)”로 간주된다.
둘째, 생성 모델이 판별 모델을 속이기 위해 적대적(adversarially)으로 학습되지 않고 최대우도법으로 학습된다. 이러한 학습법을 선택한 이유는 생성 모델을 샘플링하여 역전파(back-propagate)하는 것이 불가능하여, 적대적으로 학습시키는 것이 어렵기 때문이다.
셋째, 입력 생성모델에 통상적인 GAN과 같은 노이즈 벡터를 제공하지 않는다.
다음 식은 로우 텍스트(raw text)의 대형 코퍼스 에 대한 결합 손실을 최소화한다.
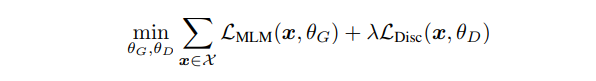
손실 기대값의 근사치는 단일 샘플로 구한다. 판별 모델의 손실은 생성 모델로 역전파하지 않는다(실제로 샘플링 스텝 때문에 역전파 할 수 없다). 생성 모델은 버리고, 판별 모델을 다운스트림 태스크에 파인튜닝한다.
3. Experiments
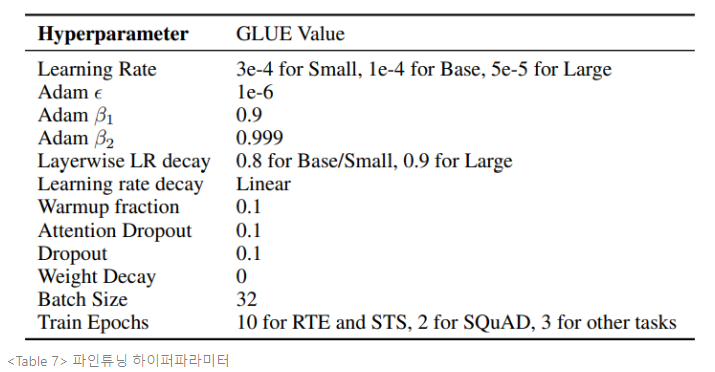
GLUE benchmark와 SQuAD dataset에 대한 평가를 수행한다. STS에서는 스피어만 상관계수(spearman correlation), CoLA에서는 매튜 상관계수(Matthews correlation), 다른 GLUE 태스크에는 정확도를 사용한다. SQuAD 1.1과 2.0에서는 EM(Exact-Match)와 F1-score를 사용한다.
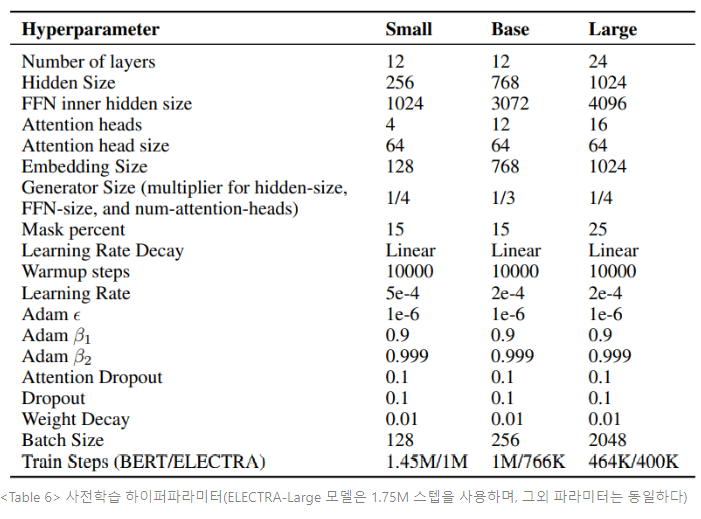
대부분의 실험에서 ELECTRA는 BERT와 동일한 데이터를 학습하는데, 데이터는 Wikipedia와 BookCorpus에서 추출한 3.3억개 토큰으로 구성된다. 그러나 Large Model에서는 XLNet에서 사용된 데이터로 사전학습한다. XLNet은 ClueWeb, CommonCrwal, Gigaword에서 추출한 데이터를 포함하여 BERT 데이터셋을 33억개 토큰으로 확장한 것이다. 모델 구조와 하이퍼파라미터는 대부분 BERT와 동일하다.
본 논문은 모델에 몇가지 확장(extension)을 제안하고 평가하여 방법론을 발전시킨다. 달리 언급이 없는 한, 본 실험은 BERT-Base와 동일한 모델 크기 및 학습 데이터를 사용한다.
- 가중치 공유(Weight Sharing)
생성 모델과 판별 모델 간 가중치 공유를 통해 사전학습 효율성을 향상시키는 방식이다. 생성 모델과 판별 모델이 동일한 크기이면, 모든 트랜스포머 가중치가 동등해질 수 있다. 그러나, 생성 모델과 판별 모델의 임베딩(토큰 임베딩과 포지셔널 임베딩 모두 포함)만을 공유할수 있기 때문에, 작은 생성 모델을 갖는 것이 더 효율적이라는 것을 발견한다. 이러한 경우 임베딩을 판별 모델의 은닉 상태 크기로 사용한다. 생성 모델의 “입력” 과 “출력” 토큰 임베딩은 BERT에서와 같이 항상 동결된다.
생성 모델이 판별 모델과 동일한 크기일 때, 가중치 동결 전략을 비교한다. 모델을 500k 스텝 동안 학습시킬 때, 가중치 동결을 사용하지 않은 경우 GLUE score는 83.6이고, 토큰 임베딩에 가중치 동결을 사용한 경우 84.3이며, 모든 가중치를 동결시키면 84.4가 된다. MLM이 representation 학습에 특히 효과적이기 때문에, ELECRA는 동결 토큰 임베딩으로 혜택을 본다. 판별 모델이 입력에 존재하거나 생성 모델에 의해 샘플된 토큰만을 업데이트 할 수 있는 반면, 생성 모델의 vocabulary에 대한 소프트맥스는 모든 토큰 임베딩을 빽빽하게 업데이트한다.
반면, 모든 인코더의 가중치를 동결하는 것은 생성 모델과 판별 모델이 동일한 크기가 되도록 강제하는 큰 단점이 있으나, 이는 크게 성능을 향상시키지 못한다. 이러한 발견을 기반으로, 본 논문의 이후 실험에는 동결 임베딩(tied embeddings)이 사용된다.
- 더 작은 생성모델(Smaller Generators)
생성 모델과 판별 모델이 동일한 크기면, ELECTRA를 학습하는 것이 MLM만 학습하는 것보다 스텝 2배수만큼 많은 연산이 소요된다. 따라서 더 작은 생성 모델을 사용하도록 제안한다. 특히, 다른 하이퍼파라미터는 그대로 두고 레이어 크기를 줄여 모델을 더 작게 만든다. 또한, 아주 단순한 “유니그램(unigram)” 생성 모델을 사용하는 것을 탐구한다. Figure 3을 보면, 생성 모델이 판별 모델의 1/4 ~ 1/2 크기일 때 가장 잘 작동한다는 것을 알 수 있다.
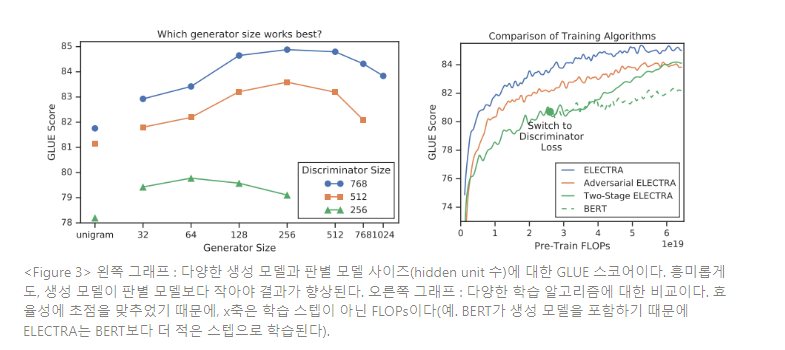
이는 너무 강력한 생성 모델을 사용하면 판별 모델에 지나치게 도전적인 태스크를 제시하여, 판별 모델의 효율적인 학습을 방해하기 때문으로 추측된다. 본 논문의 이후 실험에서는 주어진 판별 모델 크기에 대한 최적 생성 모델 크기를 사용한다.
- 학습 알고리즘(Training Algorithms)
마지막으로 ELECTRA의 다른 학습 알고리즘을 탐구하는데, 이러한 알고리즘이 더 좋은 결과를 산출하는 것은 아니다. 제안한 학습 objective는 생성 모델과 판별 모델을 공동 학습하는 것이다. 다음 2단계의 학습절차로 실험한다. :
- n스텝 동안 으로만 학습한다
- 판별 모델의 가중치를 생성 모델의 가중치로 초기화한다. 그리고 판별 모델을 로 n스텝 동안 학습시키며, 생성 모델 가중치는 동결시킨 채 유지한다.
이 절차에서 가중치 초기화를 하려면 생성 모델과 판별 모델이 동일한 크기가 되어야 한다는 것을 주목해야 한다. 가중치 초기화가 없으면 판별 모델은 다수 클래스 이상을 학습하는 것을 완전히 실패할 수 있는데, 이러한 실패는 생성 모델이 판별 모델보다 훨씬 앞서 학습을 시작했기 때문이다.
반면 공동 학습은 판별 모델이 자연적으로 생성 모델이 어디서 시작되는지에 대한 커리큘럼을 제공하는데, 이는 처음엔 약하지만 학습을 거치며 발전된다. 또한 생성 모델에서 샘플링된 별개의 작용(discrete operation)을 수용(accommodate)하는 방법을 학습하기 위해 강화학습 방식을 사용하여, GAN과 같이 생성 모델을 적대적으로 학습시키는 방안을 탐구했다. 실험에 대한 세부사항은 부록 F에 첨부되어 있다.
결과는 Figure 3의 오른쪽 그래프에서 볼 수 있다. 2단계의 학습을 거치는 동안, 다운스트림 태스크 성능은 생성 모델에서 판별 모델로 변환된 이후 크게 향상되지만, 공동 학습법을 넘어서지 못하고 종료된다. 이러한 학습 방법이 BERT보다는 뛰어난 성능을 내지만, 적대적 학습(adversarial training)은 최대 우도 학습법보다 성능이 떨어짐을 발견한다. 이후 분석은 이러한 성능 차이는 적대적 학습의 2가지 문제 때문에 발생함을 시사한다.
첫째, 적대적 생성 모델은 MLM보다 단순 성능이 떨어진다. 이 모델은 MLE 학습에서 58%의 정확도를 내는데, MLM 방식은 65%의 정확도를 낸다. 낮은 정확도의 주된 원인은 생성 텍스트의 행동 공간(action space)이 클 때 강화학습 샘플 효율성이 좋지 않기 때문이라고 추측된다.
둘째, 대조 학습 생성 모델은 대부분 확률 질량이 단일 토큰일 때, 낮은 엔트로피 출력 분포를 생산하고, 이는 생성 모델 샘플의 다양성이 높지 않다는 것을 뜻한다. 이러한 두가지 문제는 선행 연구에서 GANs 모델을 텍스트에 적용할 때 관측되었던 것이다.
본 연구의 목표는 사전학습 효율성을 향상시키는 것이기 때문에, 단일 GPU로도 빠르게 학습될 수 있는 작은 모델을 고안한다. BERT-Base의 하이퍼파라미터로 시작하여, 시퀀스 길이를 줄이고(52→128), 배치 사이즈를 줄이고(256→128), 모델의 은닉 차원 크기를 줄이고(768→256), 더 작은 토큰 임베딩을 사용한다(768→128). BERT-Small을 1.5M 스텝동안 학습시켜, 1M 스텝동안 학습된 ELECTRA-Small 모델과 동일한 training FLOPs를 사용한다. BERT에 덧붙여, 언어 모델링에 기반한 2개의 덜 자원 집약적인(resource-intensive) 사전학습 모델 방법론(ELMo, GPT)을 비교하려 한다. 또한 기본 크기(base-sized) ELECTRA 모델과 BERT-Base 비교 결과를 제시한다.
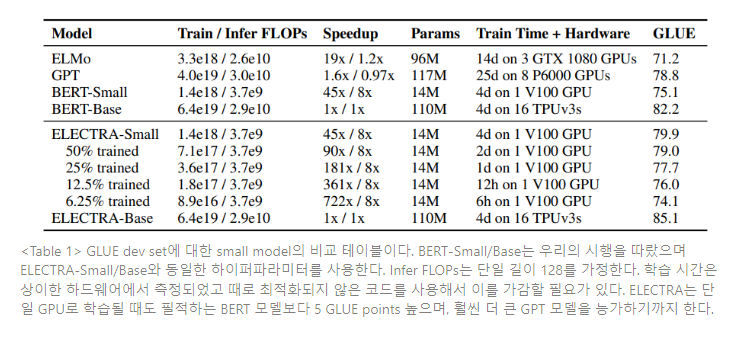
Table 1을 보면 ELECTRA-Small은 주어진 크기에서 상당히 우수한 성능을 내고, 더 많은 연산과 파라미터를 사용한 다른 방법론보다 더 높은 GLUE 스코어를 달성한다. 결과는 ELECTRA-Base 모델이 강력함을 입증한다. 비교적 적은 연산으로 강력한 성능을 내는 ELECTRA 모델이 NLP 분야 사전학습 모델을 발전시키고 적용하는 데 접근성을 높일 것으로 기대한다.
대형 사전학습 트랜스포머 모델에서 replaced token detection 사전학습 태스크의 효율성을 측정하기 위해, 대형 ELECTRA 모델을 학습시킨다. ELECTRA-Large 모델은 BERT-Large와 동일한 크기이지만, 더 오래 학습된다. 특히, 400k 스텝 동안 하나의 모델을 학습시키고(ELECTRA-400K, RoBERTa의 사전학습 연산의 대략 1/4정도 된다), 다른 하나의 모델은 1.75M 스텝 동안 학습시킨다(ELECTRA-1.75M, RoBERTa와 거의 유사한 연산량). 배치 사이즈는 2048로 하고, XLNet의 사전학습 데이터를 사용한다. 베이스라인 모델로서 BERT-Large 모델에 동일한 파라미터를 사용하고 ELECTRA-400K와 동일한 학습 시간을 사용하여 학습시킨다. GLUE dev set 결과는 Table 2에 명시되어 있다.
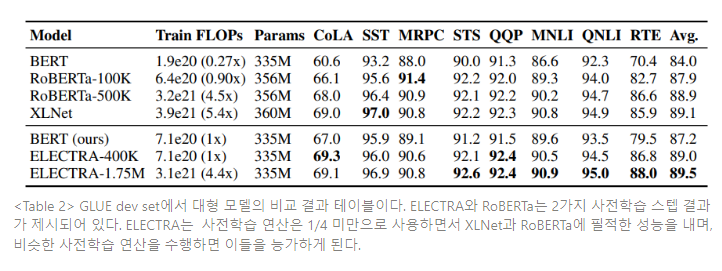
ELECTRA-400K 는 RoBERTa와 XLNet에 필적한 성능을 낸다. 그러나 ELECTRA-400K를 학습시키는 데 필요한 연산량은 RoBERTa와 XLNet 학습 연산량의 1/4만 소요된다. 이는 ELECTRA의 샘플 효율성이 대규모 모델에서도 유지됨을 입증한다. ELETRA를 더 오래 학습시킨 모델(ELECTRA-1.75)은 여전히 더 적은 사전 학습 연산량을 요하면서도, 대부분의 GLUE 태스크 스코어를 능가하는 결과를 낸다.
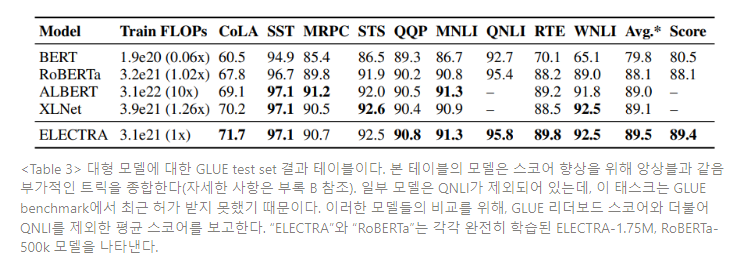
ELECTRA가 어떻게 효율적으로 작동하는지 이해하기 위해, BERT와 ELECTRA 간 사전학습 objectives를 비교해 본다.
- ELECTRA 15% : 판별 모델 손실이 입력에서 마스킹된 토큰의 15%에서만 얻어진다는 것을 제외하면 ELECTRA와 동일하다. 즉, 판별 모델의 손실 의 합 범위가 1 to n에서 로 변경된다.
- Replace MLM : 마스킹 된 토큰을 [MASK]로 대체하는 대신, 생성 모델의 토큰으로 대체하는 것을 제외하면 MLM과 동일하다. ELECTRA가 사전학습 동안 모델을 [MASK]토큰에 노출시키고 파인튜닝에는 노출하지 않는 차이를 해결하여 얻는 이점의 정도를 시험한다.
- All-Tokens MLM : Replace MLM에서와 마찬가지로, 마스킹 된 토큰은 생성 모델 샘플로 대체된다 . 덧붙여, 모델은 마스킹 된 토큰 뿐만 아니라, 모든 입력 토큰을 예측한다. 시그모이드 층을 사용하는 각 토큰에 대한 확률 D를 출력하는 copy mechanism으로 이 모델을 학습시켜 결과를 향상시킨다. 모델의 출력 분포는 D 가중치를 입력 토큰에 두고, 1-D를 MLM 소프트맥스 출력과 곱한다. 근본적으로 이 모델은 BERT와 ELECTRA 모델의 결합이다. 생성 모델의 대체(replacement)없이, 모델은 vocabulary에서 [MASK] 토큰을 예측하고 다른 토큰에 입력을 복사하도록 학습된다.

Table 5의 실험 결과를 참조하면, ELECTRA가 모든(all) 입력 토큰에 걸쳐 정의된 손실을 갖음으로써 큰 이익을 얻는다는 것을 알 수 있다. ELECTRA 15%는 ELECTRA에 비해 성능이 크게 저하된다. BERT의 성능은 [MASK] 토큰에 대한 사전학습과 파인튜닝의 부조화로 인해 손상되고, 따라서 Replace MLM이 BERT보다 좀 더 높은 성능을 낸다는 것을 알 수 있다. 또한 All-Tokens MLM, 즉 subset 대신 모든 토큰에 대한 예측 생성 모델이 BERT와 ELECTRA 간 차이를 크게 좁힌다는 것을 알 수 있다. 이러한 결과는 ELECTRA의 모든 토큰으로 학습하는 것이 성능 향상에 가장 크게 기인하고, 사전학습과 파인튜닝의 부조화 경감이 성능 향상에 약간 기인한다는 것을 시사한다.
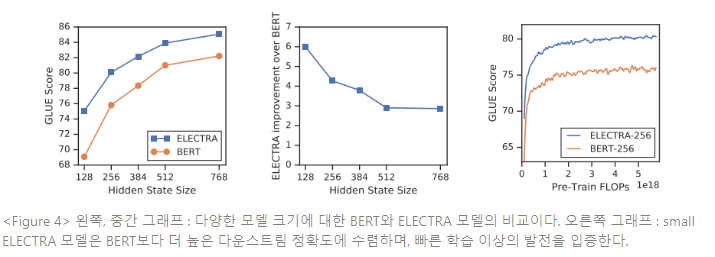
All-Tokens MLM 대비 ELECTRA의 성능 향상은 ELECTRA의 이점이 빠른 학습보다 많음을 시사한다. 다양한 모델 크기에서 BERT와 ELECTRA를 비교하여, 이에 대해 더 깊게 연구한다(Figure 4 왼쪽 그래프 참조). ELECTRA의 장점은 모델 크기가 작아질수록 더 커짐을 발견한다. 작은 모델은 수렴할 때까지 완전히 학습되고(Figure 4 오른쪽 그래프 참조), ELECTRA 모델은 BERT가 완전히 학습되었을 때보다 높은 다운스트림 정확도를 얻는다. ELECTRA는 BERT보다 파라미터 효율적인데, ELECTRA는 각 포지션에서 가능한 토큰에 대한 모든 분포를 모델링할 필요가 없기 때문이다. 그러나 ELECTRA의 파라미터 효율성을 완전히 설명하기 위해서는 더 많은 분석이 필요하다.
4. Related Work
- NLP의 자가지도 사전학습(Self-Supervised Pre-training for NLP)
자가지도 학습은 word representation, 최근에는 언어 모델링과 같은 objectives지만 contextual representation을 학습하기 위해 사용되어 왔다. BERT는 대형 트랜스포머를 MLM 태스크에서 사전학습한다. 대형 트랜스포머를 MLM 태스크에서 사전학습하는 BERT 모델에 대한 확장이 많이 연구되어 왔다. 예를 들면, MASS와 UniLM은 자기회귀 생성(auto-regressive generative) 학습 objective를 더하여 BERT를 일반화 태스크에 확장한다. ERNIE와 SpanBERT는 향상된 span representation을 위해 연속적 토큰 시퀀스를 마스킹한다. 이러한 아이디어는 ELECTRA 모델에 상호 보완적이 될 수 있다. ELECTRA 생성 모델을 자기회귀로 만들고 replaced span detection 태스크를 추가하면 흥미로운 결과가 나올 것이다. 입력 토큰을 마스킹하는 대신, XLNet은 어텐션 가중치를 마스킹하여 입력 시퀀스가 임의의 순서로 자동회귀적으로 생성된다. 그러나 이러한 방법론은 BERT와 동일하게 비효율성의 문제를 겪는데, XLNet은 입력 토큰의 15%만 생성하기 때문이다. ELECTRA 모델과 같이, XLNet은 [MASK] 토큰을 요구하지 않음으로써 BERT의 사전학습과 파인튜닝 간 차이를 경감할 수 있다. XLNet이 사전학습 동안 2개의 어텐션 “스트림(stream)”을 사용하지만 파인튜닝에서는 하나의 어텐션 스트림을 사용하므로, XLNet의 차이 경감은 명확하진 않다. 최근 TinyBERT, MobileBERT와 같은 모델은 BERT가 효율적으로 작은 모델로 추출될 수 있다는 것을 입증한다. 본 논문은 추론 속도보다 사전학습 속도에 더 집중하여, ELECTRA-Small을 학습시킨다.
- 생성적 적대 신경망(Generative Adversarial Networks)
GANs는 고품질의 합성 데이터를 생성하는 데 효율적이다. Radford et al.(2016)은 다운스트림 태스크에서 GAN의 판별 모델을 사용하는 것을 제안했고, 이는 본 논문의 방법론과 유사하다. GANs는 텍스트 데이터에 적용되어 왔는데, 표준 최대우도 학습법에 비해 뒤떨어져 있다. 본 논문의 방법론에서는 적대적 학습법을 사용하진 않지만, 생성 모델이 부분적으로 입력에서 지워진 토큰을 채우기 때문에 생성 모델을 학습시키는 MaskGAN을 연상시킨다.
- 적대적 학습(Contrastive Learning)
적대적 학습 방법론은 대략 관측된 데이터 포인트를 허구의 네거티브 샘플로부터 구분하는 것이다. 이러한 방법론은 텍스트, 이미지, 비디오를 비롯한 많은 모덜리티에 적용되어 왔다. 일반적인 접근법은 연관된 데이터 포인트가 유사한 지점의 임베딩 공간을 학습하거나 네거티브 샘플에 대해 실제 데이터 포인트의 순위를 매기는 모델을 학습하는 것이다. ELECTRA는 부분적으로 Noise-Contrastive Estimation(NCE)와 연관되어 있는데, 이러한 모델도 실제와 가짜 데이터 포인트를 구분하기 위해 이진 분류를 학습한다.
가장 오래된 NLP 사전학습 방법론 중 하나인 Word2Vec 또한 적대적 학습 방법을 사용한다. 실제로, ELECTRA는 대규모로 확장된 CBOW(Continuous Bag of Words)와 네거티브 샘플링 버전으로 간주된다. CBOW 또한 주변 문맥이 주어질 때 입력 토큰을 예측하고, 입력 토큰이 실제 데이터에서 오는지 확률분포에서 오는지를 분류하는 이진 분류로 학습 태스크를 전환한다. 그러나, CBOW는 트랜스포머 보다는 bag-of-vector 인코더를 사용하고, 학습된 생성 모델 대신 유니그램(unigram) 토큰 빈도수에서 얻어진 단순 확률분포를 사용한다.
Word2Vec, CBOW
Word2Vec
단어 벡터간 유의미한 유사도를 반영할 수 있도록 단어의 의미를 수치화하는 방법이다.
1) 희소 표현(sparse representation)
원-핫 인코딩을 통해 얻은 원-핫 벡터는 표현하고자 하는 단어의 인덱스만 1이고, 나머지 인덱스는 전부 0으로 표현되는 벡터 표현 방법이다. 이와 같이 벡터나 행렬 값이 대부분 0으로 표현되는 방법을
희소 표현(sparse representation)이라 한다.이러한 표현 방법은 각 단어 벡터간 유의미한 유사성을 표현할 수 없다는 단점이 있어, 대안으로 단어의 의미를 다차원적으로 공간에 벡터화하는 방법을 사용하는데, 이러한 표현을
분산 표현(distributed representation)이라 한다. 그리고 분산 표현을 이용하여 단어간 의미적 유사성을 벡터화하는 작업을 워드 임베딩이라 부르며, 이렇게 표현된 벡터를임베딩 벡터(embedding vector)라 한다.2) 분산 표현(distributed representation)
분포 가설(distributional hypothesis) 가정 하에 만들어진 표현 방법입니다. 이 가정은 “비슷한 문맥에서 등장하는 단어는 비슷한 의미를 가진다”는 가정이다.
희소 표현이 고차원에 각 차원이 분리된 표현 방법이라면, 분산 표현은 저차원에 단어의 의미를 여러 차원에다 분산하여 표현한다. 이러한 표현 방법을 사용하면 단어 벡터간 유의미한 유사도를 계산할 수 있다. 이를 위한 대표적인 학습 방법이 Word2Vec이다.
3) CBOW(continuous bag of words)
Word2Vec 학습 방식에는 CBOW와 skip-gram 2가지 방식이 있다.
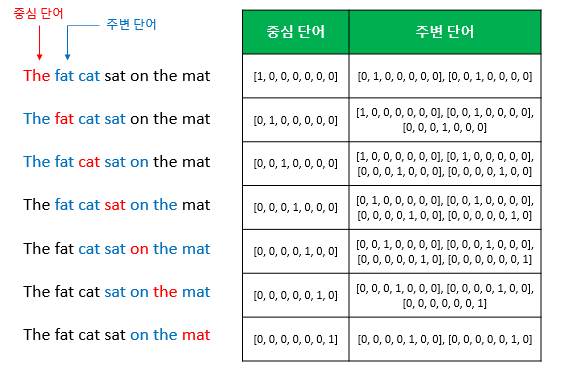
CBOW는 주변 단어들을 입력으로 중간 단어를 예측하는 방법이다. 반대로,skip-gram은 중간 단어들을 입력으로 주변 단어를 예측하는 방법이다.e.g. “The fat cat sat on the mat”다음과 같은 예문이 있을 때, [’The’, ‘fat’, ‘cat’, ‘on’, ‘the’, ‘mat’]에서 sat을 예측하는 것은 CBOW의 일이다. 이때 예측해야 하는 단어 sat을 중심 단어(center word)라 하고, 예측에 사용되는 단어를 주변 단어(context word)라 한다.
중심 단어를 예측하기 위해서는 앞, 뒤로 몇 개의 단어를 볼 지 결정해야 하는데, 이 범위를
윈도우(window)라 한다. 예를 들어, 윈도우 크기가 2이고 예측하고자 하는 중심 단어가 sat이라 하면, 앞의 두 단어인 fat과 cat, 뒤의 두 단어 on과 the를 입력으로 사용한다. 윈도우 크기가 n이라 하면, 실제 중심 단어를 예측하기 위해 참고하는 주변 단어 개수는 2n개가 된다.윈도우 크기가 정해지면, 윈도우를 옆으로 움직여 주변 단어와 중심 단어의 선택을 변경해가며 학습을 위한 데이터셋을 만드는데, 이 방법을
슬라이딩 윈도우(sliding window)라 한다.
위 그림은 윈도우 크기가 2일때, 슬라이딩 윈도우가 어떤 식으로 이루어지면서 데이터 셋을 생성하는지 보여준다. Word2Vec에서 입력은 모두 원핫 벡터가 되어야 하므로, 우측 그림은 중심 단어와 주변 단어의 선택에 따라 어떻게 원핫 벡터가 되는지 보여준다. 이는 CBOW를 위한 전체 데이터셋과 같다.CBOW의 인공 신경망은
입력층(input layer),투사층(projection layer),출력층(output layer)로 구성되어 있다. 입력층의 입력에는 사용자가 정한 윈도우 크기 범위 안에 있는 주변 단어의 원핫벡터가 들어가고, 출력층은 예측하고자 하는 중간 단어의 원핫벡터가 레이블로 필요하다. 투사층은 룩업 테이블이라는 연산을 담당하는 층이다.
CBOW의 투사층 크기 M은 임베딩하고 난 벡터의 차원이다. 위 그림에서 M=5이므로 CBOW를 수행한 후 얻는 각 단어의 임베딩 벡터 차원은 5가 된다. 입력층과 투사층 사이 가중치 W는 VM 행렬이며, 투사층에서 출력층 사이의 가중치 W’는 MV 행렬이다. 여기서 V는 단어 집합의 크기를 의미한다. 여기서 두 행렬은 동일한 행렬의 전치(transpose)가 아닌 서로 다른 행렬이다. 인공 신경망 훈련 전에 이 가중치 행렬 W와 W’는 랜덤 값을 가진다. CBOW는 주변 단어로 중심 단어를 더 정확히 맞추기 위해 계속해서 이 W와 W’를 학습해가는 구조이다.(참고) 위키독스 https://wikidocs.net/book/2155

5. Conclusion
본 논문은 language representation의 학습을 위해 새로운 자가지도 태스크 replaced token detection을 제안해 왔다. 논문의 핵심 견해는 입력 토큰을 작은 생성 신경망에 의해 생성된 고품질의 네거티브 샘플과 구분하도록 텍스트 인코더를 학습하는 것이다. 이러한 사전학습 objectives는 MLM에 비해 효율적인 연산 방법이며 다운스트림 태스크에서 더 좋은 성능을 낸다. 이러한 모델은 상대적으로 적은 양의 연산으로도 잘 작동하는데, 이러한 결과가 사전학습 텍스트 인코더를 개발하고 적용하는 접근법을 더 쉽게 만들 것으로 기대된다.
Appendix