
Deep contextualized word representations(2018) 논문을 읽고 내용 요약 및 정리
1. Introduction
사전학습 된 word representation은 많은 NLU 모델의 핵심 요소이다. 그러나 질 좋은 representation을 학습 하는 것은 어려운데, (1) 단어 사용(syntax, semantics)의 복합적인 특성과 (2)단어 사용이 언어 문맥에서 어떻게 다른지를 이상적으로 모델링(다의성 모델링)해야 하기 때문이다. 본 논문은 이러한 2가지 챌린지를 다루고, 현존하는 모델로 쉽게 통합되며, 모든 NLU 문제에서 SOTA 성능을 크게 향상시키는 deep contextualized word representation을 소개한다.
본 논문에서는 대형 텍스트 코퍼스에서 한 쌍의 언어 모델(LM) objective로 학습된 양방향 LSTM에서 얻은 벡터를 사용한다. 따라서, 이를 ELMo(Embeddings from Language Model)라고 부른다. Contextualized word vectors를 학습하는 이전 접근법과 달리, ELMo는 biLM의 모든 내부 레이어에 대하여 기능하기 때문에, deep하다고 볼 수 있다. 구체적으로 말하면, 각 앤드 태스크를 위해 각 입력 단어 위에 쌓은 벡터의 선형 결합을 학습하고, 이는 top LSTM layer만 사용하는 것보다 성능을 크게 향상시킨다.
이러한 내부 상태(states)의 결합은 아주 풍부한 word representation이 가능하게 한다. high-level LSTM 상태가 문맥 의존적인(context-dependent) 단어의 의미 측면을 포착하는 반면(예를 들면, 단어 의미 중의성 해소 태스크를 잘 수행하기 위한 변형 없이 사용될 수 있다.), low-level 상태는 구문론의 측면에서 모델링한다(예를 들면 품사 태깅에 사용될 수 있다.). 이러한 시그널을 동시에 모두 노출하는 것은, 학습된 모델이 각 앤드 태스크에 가장 유용한 반지도(semi-supervision) 학습 유형을 선택할 수 있도록 하기 때문에, 상당한 이득이 된다.
ELMo representation이 실제로 굉장히 잘 작용한다는 것은, 다양한 연구를 통해 입증된다. 먼저, 본 논문에서는 ELMo가 text entailment, question answering, sentiment analysis를 포함한 6개의 NLU 문제를 해결하기 위한 현존 모델에 쉽게 덧붙여질 수 있다는 것을 입증한다. ELMo representation을 덧붙이는 것만으로도, 모든 경우의 오차를 20%까지 감소시키며, SOTA 성능을 크게 향상시킬 수 있다. ELMo는 신경망 기계 번역 인코더(neural machine translation encoder)를 사용하여 contextualized representation을 연산하는 CoVe(McCann et al., 2017)의 성능을 능가한다.
결과적으로, ELMo와 CoVe에 대한 분석은 deep representation이 LSTM의 top layer에서만 얻어낸 representation보다 뛰어나다는 것을 입증한다.
2. Related Work
이전에 제안된 방법론은 서브워드 정보로 워드 벡터를 풍부하게 하거나, 각 단어 의미에 대한 벡터를 분리하여 학습하는 방식으로 전통적인 워드 벡터의 결점을 극복한다. 본 논문의 접근법 또한 문자 단위 컨볼루션(character convolution)을 사용하여 서브워드 유닛으로 혜택을 보며, 사전 정의된 의미 클래스를 예측하기 위해, 명시적인 학습 없이도 다중 의미(multi-sense) 정보를 균일하게 다운스트림 태스크로 통합한다.
또다른 최근 연구도 문맥 의존적인 representation 학습에 초점을 맞추고 있다. Context2Vec은 양방향 장단기 메모리(bidirectional Long Short Term Memory)를 사용하여 pivot word를 둘러싼 문맥을 인코딩한다. 문맥적 임베딩을 학습하는 다른 접근법에는 pivot word 자체를 포함하는 representation이 있고, 이러한 접근법은 지도학습된 신경망 기계 번역(MT) 시스템 혹은 비지도 언어 모델의 인코더로 연산된다. 이러한 접근법들은 모두 대형 데이터셋에서 혜택을 보지만, MT 접근법은 병렬 코퍼스 크기 때문에 제한된다. 본 논문은 단일 언어 데이터의 접근을 충분히 활용하고, 약 30M개의 문장이 포함된 코퍼스에서 biLM을 학습한다. 또한, 이러한 접근법을 deep contextual representation에 일반화하고, 광범위한 NLP 태스크에 걸쳐 이러한 접근법이 잘 작용함을 입증한다.
선행 연구 또한 deep biRNNs의 여러 레이어가 다양한 유형의 정보를 인코딩한다는 것을 입증해 왔다. 예를 들면, 멀티 태스크 구문론적 지도학습(예를 들면 품사 태깅)를 low-level deep LSTM에 도입하는 것이 dependency parsing이나 CCG super tagging과 같은 high-level 태스크의 전반적인 성능을 향상시킬 수 있다. RNN 기반 encoder-ecoder 기계 번역 시스템에서는 2-layer LSTM encoder의 첫 레이어에서 학습된 representation이 2번째 레이어보다 품사 태깅 예측에 더 뛰어나다는 것을 입증했다. 결국, 단어 문맥을 인코딩하는 top LSTM layer가 단어 의미 표현을 학습한다는 것이 입증되었다. 본 논문은 이와 유사한 시근러이 ELMo representation에서 변형된 LM objective로 도출되며, 이러한 다양한 반지도학습 유형이 섞여진 다운스트림 태스크를 위한 모델을 학습시키는 데 매우 효율적임을 입증한다.
Dai and Le(2015)와 Ramachandran et al.(2017)은 언어모델과 시퀀스 오토인코더(sequence
autoencoder)를 사용하여 encoder-decoder 쌍을 사전학습시키고, 태스크 명시적인 지도학습에 파인튜닝한다. 이와 대조적으로, 본 논문에서는 biLM을 라벨링되지 않은 데이터에 사전학습 시킨 후 가중치를 수정하고 부가적인 태스크 명시적 모델 성능에 더함으로써, 다운스트림 학습 데이터 크기가 더 작은 지도학습 모델에 영향을 주는 경우, 크고 풍부하며 보편적인 biLM representation을 활용할 수 있도록 한다.
3. ELMo : Embeddings from Language Models
ELMo word representations는 전체 입력 문장에 기능한다. 이러한 word representation은 내부 네트워크 상태의 선형 함수로 character convolutions를 갖는 2개의 biLMs layer 위에서 연산된다. 이러한 구조는 biLM이 반지도 학습을 가능하게 하며, 대규모로 사전학습되고 현존하는 신경망 NLP 구조의 범위로 쉽게 통합될 수 있다.
개의 토큰 시퀀스()가 주어졌을 때, 순방향 언어 모델은 주어진 히스토리()에서 토큰 의 확률을 모델링함으로써 시퀀스 확률을 연산한다.
최신 SOTA 신경망 언어 모델은 문맥에 독립적인 token representation 를 연산(토큰 임베딩이나 문자 CNN을 통해)한 다음, 이것을 순방향 LSTM의 layer를 통과시킨다. 각 포지션 에서, 각 LSTM layer는 일 때 context-dependent representation 을 출력한다. top layer LSTM의 출력 은 소프트맥스 레이어와 함께 다음 토큰 을 예측하는 데 사용된다.
역방향 LM은 순방향 LM과 유사한데, 시퀀스를 역방향으로 통과하면서 future context가 주어졌을 때 이전 토큰을 예측한다는 점이 다르다.
이는 layer 의 각 역방향 LSTM layer 과 함께 deep model이 주어진 ()의 에 대한 representation 을 생성하며, 순방향 LM과 유사한 방식으로 시행될 수 있다.
biLM은 순방향 LM과 역방향 LM을 결합한다. 다음 공식은 순방향과 역방향의 로그 우도(log likelihood)를 공통으로 최대화한다.
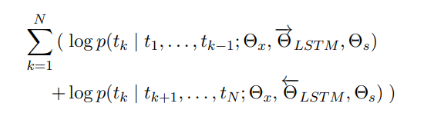
본 식에서 token representation 과 소프트맥스 레이어 를 위해 순방향과 역방향의 파라미터를 묶고, 그 동안 각 방향의 LSTMs의 개별 파라미터를 유지한다. 전반적으로, 이러한 공식은 Peters et al.(2017)의 접근법과 유사한데, 완전히 독립적인 파라미터를 사용하는 것 대신에, 각 방향 간 가중치를 일부 공유한다는 점이 다르다.
ELMo는 biLM에서 intermediate layer representation의 태스크 명시적인 결합이다. 각 토큰 에서 -layer biLM은 representation 집합을 연산한다.
{ }
{}
다음 식에서 각 biLSTM layer에 대한 은 token layer이고, 이다.
다운스트림 모델에 포함하기 위해, ELMo는 의 모든 레이어를 단일 벡터(single vector) 로 만든다. 가장 단순한 경우는, ELMo가 TagLM(Peters et al., 2017)이나 CoVe(McCann et al., 2017)에서와 같이 top layer 만을 선택하는 것이다. 좀 더 일반적으로는, 모든 biLM layer의 태스크 명시적인 가중치를 연산한다 :
(1)
(1)에서 는 소프트맥스로 정규화된 가중치이고, 스칼라 파라미터 는 태스크 모델이 전체 ELMo 벡터를 스케일링 할 수 있도록 한다. 는 최적화 프로세스를 돕기 위한 practical importance이다. 각 biLM layer의 활성화를 고려하는 것에는 다양한 distribution이 있는데, 어떤 경우에는 가중치를 부여하기 전에 각 biLM layer에 레이어 정규화(layer normalization)을 적용하는 데 도움이 된다.
사전학습 된 biLM과 목표한 NLP 태스크를 위한 지도학습 구조가 주어지면, biLM을 사용하여 태스크 모델을 사용하는 것은 단순한 프로세스이다. 본 논문에서는 단순히 biLM을 시행하고 각 단어에 대한 모든 layer representation을 기록하고, 그리고 나면 다음 설명과 같이 앤드 태스크 모델이 이러한 representation의 선형 결합을 학습하도록 한다.
먼저, biLM 없이 지도학습된 모델의 lowest layers를 고려한다. 대부분의 지도학습된 NLP 모델은 lowest layers에서 공통의 구조를 공유하기 때문에, ELMo를 일관되고 통합된 방식으로 추가할 수 있게 한다. 토큰의 시퀀스()가 주어졌을 때, 사전학습된 워드 임베딩과 선택적 character-based representations를 사용하는 각 토큰의 위치(token position)를 위한 문맥에 독립적인(context-independent) token representation 를 형성하는 것이 표준이다. 그리고 나서, 모델은 문맥에 민감한(context-sensitive) representation 를 형성하는데, 일반적으로 양방향 RNNs, CNNs 또는 feed-forward 네트워크를 사용한다.
ELMo를 지도 학습 모델에 추가하기 위해서는, 먼저 biLM의 가중치를 동결하고 ELMo 벡터 를 와 연결(concatenate)한 다음 ELMo의 향상된 표현(representation) 을 태스크 RNN으로 넘긴다. 일부 태스크(예를 들면, SNLI, SQuAD)에서는, 또 다른 출력 명시적인 선형 가중치의 집합을 도입하고 를 로 대체하여 태스크 RNN의 출력에 ELMo를 포함시킴으로써, 더 큰 성능 향상을 관측한다. 지도학습 모델의 나머지 부분이 변경되지 않은 채로 남아있기 때문에, 이러한 추가(additions)가 더 복합적인 신경망 모델의 문맥 내에서 발생할 수 있다. 예를 들면, 섹션 4의 SNLI 실험이나 대용어 해소(coreference resolution) 실험을 참고하면 된다.
마지막으로, 본 논문에서는 적절한 양의 드롭아웃을 ELMo에 추가하는 것, 그리고 일부 경우에는 를 손실에 추가함으로써 ELMo의 가중치를 규제**하는 것이 beneficial하다는 것을 발견했다. 이는 ELMo 가중치의 귀납적인 편향(inductive bias)이 모든 biLM layers의 평균에 근사하도록 강제한다.
본 논문에서 사전학습된 biLMs는 Jozefowicz et al. (2016)과 Kim et al. (2015)의 구조와 유사
하지만, 양방향의 공동 학습을 지원하기 위해 변형되었고, LSTM 레이어 간 잔차 연결(residual
connection)을 더한다. Peters et al. (2017)에서 순방향만 사용한(forward-only) LM에
biLM을 사용하고 대규모로 학습시키는 것의 중요성을 강조함에 따라, 본 연구에서 대규모 biLMs
에 집중한다.
순전히(purely) 문자 기반(character-based)의 input representation을 유지하면서, 전반적인 언어 모델의 퍼플렉서티(perplexity)와 모델 크기, 다운스트림 태스크에 대한 연산적인 요구사항(computational requirements)의 균형을 잡기 위해, Jozefowicz et al.(2016)의 단일 최적 모델 CNN-BIG-LSTM에서 모든 임베딩과 은닉 차원을 이등분한다. 최종 모델은 4096개의 유닛과 512차원 투영(dimension projection), 첫번째에서 두번째 layer의 잔차 연결(residual connection)으로 구성된 의 biLSTM layer를 사용한다. 문맥에 민감하지 않은(context insensitive) type representation은 2048 문자의 n-gram 컨볼루션 필터(convolutional filters)를 사용한다. 결과적으로, biLM은 순수한 문자 입력 때문에, 학습 세트 외의 representations를 포함한 각 입력 토큰에 대한 3개의 representation layers를 제공한다. 반면, 전형적인 워드 임베딩 방법론은 고정된 vocabulary에서 토큰에 대한 1개의 representation layer만을 제공한다.
4. Evaluation
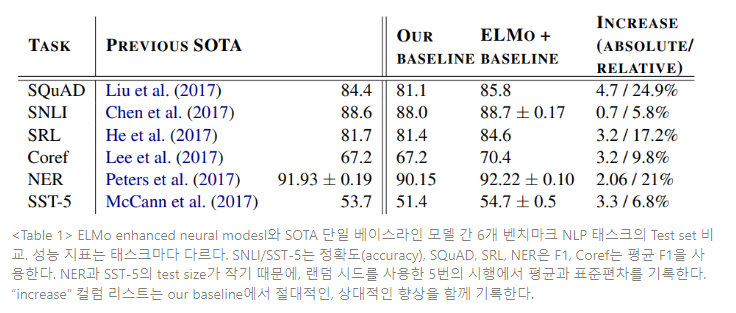
Table 1 은 6 개의 NLP 벤치마크 태스크에 대한 ELMo 의 성능을 보여준다. 고려된 모든 태스크에서,
ELMo 를 추가하는 것만으로, 강력한 베이스 모델의 상대적 오차를 6~20%정도까지 감소시키며
새로운 SOTA 기록을 세운다. 이는 다양한 모델 구조와 언어 이해 태스크에 걸쳐 상당히 보편적인
결과이다.
5. Analysis
본 섹션은 논문의 주장을 입증하고 ELMo representation의 흥미로운 양상을 자세히 설명하기 위한 ablation analysis를 제시한다.
biLM을 결합하는 식 (1)에는 많은 대안이 있다. contextual representation에 대한 선행 연구에서는 biLM이나 MT encoder의 last layer만을 사용했다. 규제 파라미터인 람다()를 선택하는 것 또한 매우 중요한데, =1과 같은 큰 값은 레이어에 대한 단순 평균 수준까지 가중치 함수를 효과적으로 감소시키는 반면, $\lambda$=0.001`과 같은 작은 값은 다양한 레이어 가중치를 허용하기 때문이다.

Table 2는 SQuAD, SNLI, SRL에서 이러한 대안을 비교한다. 모든 레이어의 representation을 포함하는 것이 마지막 레이어만 사용하는 것보다 전반적인 성능을 향상시키고, 마지막 레이어의 contextual representation을 포함시키는 것이 베이스라인 모델의 성능을 향상시킨다 (Baseline < Last < ALL).
예를 들면 SQuAD의 경우, 마지막 biLM layer만 사용하는 것이 베이스라인 모델보다 F1을 3.9%만큼 향상시킨다. 마지막 레이어만 사용하기보다, 모든 biLM layer를 평균하는 것이 “Last Only”보다 F1을 0.3%만큼 추가로 향상시키고, 태스크 모델이 개별 레이어의 가중치를 학습하게 되면(=0.001) F1을 0.2%만큼 추가로 향상시킨다. ELMo를 사용하는 경우 대부분 작은 람다 값이 선호되는데, 더 작은 훈련 세트를 가진 NER과 같은 태스크의 결과는 람다 값에 민감하지 않다.
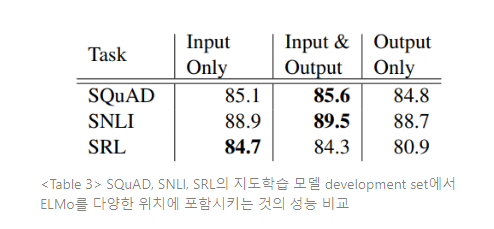
본 논문에서 모든 태스크 구조는 워드 임베딩을 biRNN의 lowest layer의 입력으로만 포함한다. 그러나, 태스크 명시적인 구조에서 ELMo를 biRNN 출력에 포함시키는 것이 일부 태스크의 전반적인 결과를 향상시킬 수 있다는 것을 발견한다. Table 3에서와 같이, ELMo를 SNLI와 SQuAD의 입출력에 모두 포함시키는 것이 입력 레이어만 적용한것 보다 성능을 향상시켰는데, SRL의 경우(명시되지 않았으나 coreference resolution도) 입력 레이어에만 ELMo를 포함시키는 것이 가장 성능이 좋다. 이러한 결과는 어떻게 해석해야 할까? SNLI와 SQuAD 구조는 모두 biRNN 이후 어텐션 구조를 사용하기 때문에, 이 레이어에 ELMo를 도입함으로써 모델이 biLM의 내부 representation에 직접적으로 집중하도록 하기 때문이다. 그러나 SRL의 경우에는 태스크 명시적인 context representation이 biLM representation보다 더 중요하기 때문이다.
ELMo를 추가하는 것만으로도 워드 벡터에 대한 태스크 성능을 향상시킬 수 있기 때문에, biLM의 contextual representation은 워드 벡터에서 포착되지 않는, NSP 태스크에 일반적으로 유용한 정보를 인코딩해야 한다. biLM은 문맥을 활용하여, 단어의 의미가 모호하지 않도록 해야 한다.

“play”라는 다의적인 단어를 생각해 보자. Table 4의 상단에는 GloVe 벡터를 사용하여 “play”의 nearest neighbors를 리스팅한다. 이러한 단어들은 여러 품사에 걸쳐 있지만, “play”의 스포츠와 관련된 의미가 연결되어 있다. 반면, Table의 하단 2열은 SemCor dataset의 원천 문장에서 “play”에 대한 biLM의 context representation을 사용하여, 가장 가까운 문장을 보여준다. 이러한 경우, biLM은 원천 문장에서 품사와 단어의 의미를 모두 명확하게(disambiguate) 할 수 있다.
biLM으로 인코딩 된 정보를 분리하기 위해, representations는 fine-grained WSD(Word Sense disambiguation, 단어 의미 명확화) 태스크와 품사 태깅(POS Tagging) 태스크를 직접적으로 예측하는 데 사용된다. 이러한 접근법으로 CoVe 뿐만 아니라 각 개별 레이어와 비교하는 것이 가능해진다.
- Word Sense disambiguation(WSD)
문장이 주어지면, Melamud et al. (2016)와 유사하게 단순한 1-nearest neighbor 접근법을 사용하여 단어 의미를 예측하기 위해 biLM representation을 사용할 수 있다. 이러한 접근법을 수행하기 위해서 먼저 학습 코퍼스인 SemCor 3.0의 모든 단어 representation을 연산하는 데 biLM을 사용하고, 각 의미에 대한 평균적인 representation을 취한다. 검증 시에는 다시 biLM을 사용하여 주어진 target word의 representation을 연산하고, 훈련 세트에서 가장 가까운 의미(nearest neighbor sense)를 취하여, 훈련 동안 관측되지 않은 단어의 원형(lemmas)을 위해 WordNet의 처음 의미(first sense)로 돌아간다.
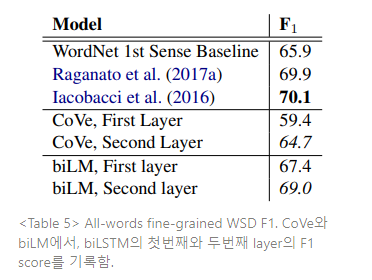
Table 5는 Raganato et al. (2017b) 의 평가 프레임워크를 사용하며, Raganato et al. (2017a)의
4가지 테스트 세트와 동일한 세트에 걸쳐 WSD 결과를 비교한다. 전반적으로 biLM의 top layer representation은 F1이 69.0으로, first layer보다 WSD에 뛰어나다. CoVe biLSTM layers는 biLM과 유사한 패턴을 따르는데(첫 레이어에 비해 두 번째 레이어가 전반적으로 더 높은 성능을 가짐), biLM이 CoVe의 biLSTM 성능을 능가한다.
- POS Tagging
biLM이 basic syntax를 포착하는지 탐구하기 위해, Wall Street Journal portion of the Penn Treebank (PTB)로 품사 태깅을 예측하는 선형 분류기의 입력으로 context representation을 사용한다. WSD와는 상이하게, first biLM layer를 사용한 정확도가 top layer를 사용한것 보다 높다. CoVe 품사 태깅 정확도는 biLM의 품사 태깅과 유사한 패턴을 따르고, WSD와 같이 biLM은 CoVe인코더보다 더 높은 정확도를 얻는다.
- Implications for supervised tasks
종합하면, 이러한 실험은 biLM의 layer들이 다양한 정보를 나타낸다는 것을 입증하고, 모든 biLM layer를 포함하는 것이 다운스트림 태스크에 최고 성능을 내기 위해 중요하다는 것을 설명한다. 덧붙여, biLM representations는 CoVe보다 WSD와 품사 태깅에 trasnferable하고, 이는 ELMo가 왜 CoVe보다 다운스트림 태스크 성능이 뛰어난지 설명하는 데 도움이 된다.
ELMo를 모델에 추가하는 것은 SOTA 성능에 도달하기 위한 업데이트 파라미터의 숫자와 전반적인 훈련 세트 크기 측면에서 표본 효율을 크게 증가시킨다. 예를 들면, SRL 모델은 ELMo 없이 486 에포크의 훈련을 거친 후 최대 F1 수치에 도달한다. ELMo를 추가한 후, 모델은 에포크 10에서 베이스라인 최대치를 능가하며, 동일 수준 성능에 도달하는 데 필요한 업데이트 숫자를 98% 감소시킨다.
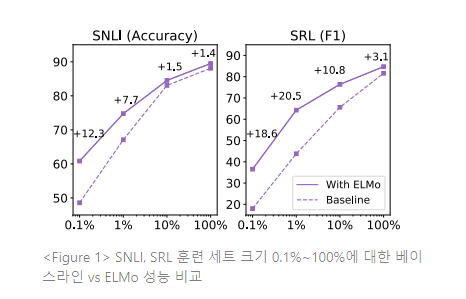
덧붙여, ELMo-enhanced models는 ELMo가 없는 모델보다 더 작은 훈련 세트를 더 효율적으로 사용한다. Figure 1은 ELMo 유무에 따른 베이스라인 모델의 성능을 전체 훈련 세트의 0.1%~100%에서 비교한다. ELMo를 사용한 모델의 성능 향상은 더 작은 훈련 세트에서 가장 크며, 일정 수준 성능까지 도달하는 훈련 데이터의 양을 크게 감소시킨다. SRL의 경우, 훈련 세트의 1%를 사용한 EMLo 모델이 훈련 세트 10%를 사용한 베이스라인 모델과 동일한 F1을 갖는다.
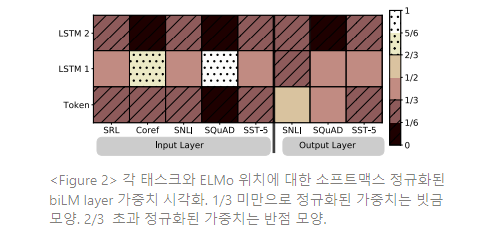
Figure 2는 소프트맥스로 정규화하여 학습된 레이어 가중치를 시각화한다. 입력 레이어에서, 태스크 모델은 first biLSTM layer를 선호한다. 대용어(coreference)와 SQuAD에서 first biLSTM layer가 크게 선호되나, 다른 태스크에서는 덜 선호된다. 출력 레이어 가중치는 lower layer를 약간 더 선호하며, 비교적으로 균형잡혀 있다.
ELMo representation은 biLM의 biLSTM layer에서 포착된 문맥 정보와 더불어 fully character-based context에 민감하지 않은 type layer 의 서브워드 정보도 포함한다. 서브워드 정보 대비 문맥적 정보의 상대적인 기여도를 분석하기 위해, GloVe 벡터를 biLM과 biLSTM layer 없이 biLM character-based layer로 교체하는 ablation을 수행한다.
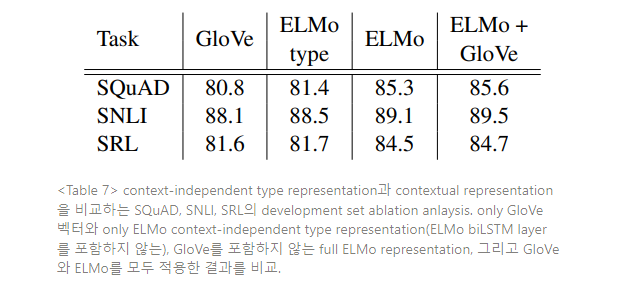
Table 7을 보면 GloVe 벡터를 biLM character layer로 대체하는 것이 모든 태스크에서 약간씩 성능을 향상시킴을 알 수 있다(SQuAD에서 F1 80.8→81.4로 향상시킴). 그러나 full ELMo model과 비교하면 전반적인 향상도는 작다. 여기서, 다운스트림 태스크에 대한 성능 향상은 대부분 서브워드 정보가 아닌, 문맥 정보에 기인한 것으로 결론지을 수 있다.
또한, ELMo 모델에 GloVe를 추가하는 것이 일반적으로 ELMo만 사용한 모델보다 미미하게(marginal) 성능을 향상시킨다(예를 들면, SRL에서 f1이 84.5→84.7로 0.2% 향상).
6. Conclusion
본 논문은 biLM에서 고품질의 deep context-dependent representation을 학습하는 일반적인 접근법에 대해 소개하고, ELMo를 다양한 NLP 태스크에 적용할 때 큰 성능 향상이 있음을 입증했다. Ablation과 다양한 실험을 통해, biLM layer가 효율적으로 문맥 내의 단어(words-in-context)에 대한 구문론적, 의미론적 정보를 인코딩하고, 모든 레이어를 사용하는 것이 전반적인 태스크 성능을 향상시킨다는 것을 입증했다.
