
| 항목 | 내용 |
|---|---|
| 제목 | Proximal Policy Optimization Algorithms |
| 저자 | John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, Oleg Klimov |
| 소속 | OpenAI |
| 발표 | 2017 (arXiv) |
| 분야 | 강화학습 (Policy Gradient Optimization) |
Main Idea
문제: 기존 강화학습 방법론의 결함
2017년 당시 딥러닝 기반 강화학습의 주요 알고리즘들은 각기 다른 방향에서 막혀 있었다.
-
DQN(Deep Q-learning)은 이산 행동 공간에 특화된 구조상, 로봇 제어처럼 연속적이고 고차원적인 행동 공간에 적용하기 어렵다.
-
Vanilla policy gradient(A2C/A3C)는 구현이 단순하지만, 수집한 데이터로 딱 한 번만 gradient 업데이트를 수행한다는 구조적 한계 때문에 샘플 효율이 낮다. 같은 데이터로 여러 번 업데이트를 시도하면 정책이 붕괴(policy collapse)한다.
-
TRPO(Trust Region Policy Optimization)는 이 안정성 문제를 이론적으로 해결했다. policy update 시
KL divergence를 명시적 제약(constraint)으로 두어 monotonic improvement를 보장한다.그러나 이 제약을 만족시키기 위해 2차 최적화(conjugate gradient + Fisher-vector product + line search)가 필요하고, 구현 복잡도가 수백 줄에 달하며, dropout이나 파라미터 공유 아키텍처와 구조적으로 호환되지 않는다.
PPO의 출발점은 명확하다: TRPO가 주는 안정성을, 1차 최적화(Adam)만으로 달성할 수 있는가?
해결: Clipped Surrogate Objective
이 질문에 대한 답이 논문 전체의 핵심이다. 먼저 확률 비율을 정의한다:
은 현재 정책과 이전 정책이 동일함을 의미한다. TRPO가 최대화하는 CPI objective는:
이를 KL 제약 없이 그대로 최대화하면 가 폭발적으로 커지며 정책이 과도하게 변한다. PPO는 제약 대신 클리핑(clipping)으로 이를 방지한다:
이 식에서 이 핵심 설계 결정이다. 단순히 를 클리핑한 값을 쓰는 것과 달리, 클리핑된 값과 클리핑되지 않은 값 중 더 비관적인(pessimistic) 값을 선택한다. 이 동작을 경우의 수로 분해하면 설계 의도가 명확해진다:
| 조건 | 범위 | 선택 | 효과 |
|---|---|---|---|
| (좋은 행동), | 정상 | unclipped | 정상 학습 |
| , | 과도 증가 | clipped | gradient 차단 |
| (나쁜 행동), | 정상 | unclipped | 정상 학습 |
| , | 과도 감소 | clipped | gradient 차단 |
결과적으로 objective가 개선되는 방향으로 가 범위를 벗어나면 이득을 무시하고, 악화되는 방향에서는 끝까지 페널티를 부과하는 단방향 보수주의(one-sided conservatism)가 구현된다.
이것이 단순 클리핑인 와 다른 이유도 여기서 드러난다. 단순 클리핑은 이고 인 상황, 즉 나쁜 행동의 확률이 과도하게 높아지는 경우에도 gradient를 차단해버려 나쁜 방향으로의 이탈을 방치한다. 을 사용하면 이 경우 unclipped 값이 더 작으므로 페널티가 온전히 전달된다.
머신러닝 관점에서 은 파라미터 공간 대신 정책 확률 비율 공간에서의 암묵적 근위(proximal) 정규화로 해석할 수 있다. 정규화가 파라미터 변화를 제한하듯, clipping은 policy 자체의 변화를 제한하며 — TRPO의 명시적 KL 제약과 기능적으로 유사하되 훨씬 단순한 형태를 취한다.
1. Introduction
딥러닝 기반 강화학습은 2017년 당시 세 가지 주류 접근법이 경쟁하고 있었다.
Deep Q-Network 계열은 이산 행동 공간에 특화되어 연속 제어에 적용하기 어려웠고, vanilla policy gradient(A3C/A2C)는 동일한 데이터를 단 한 번의 업데이트에만 사용할 수 있어 샘플 효율이 낮았다.
TRPO는 이론적으로 가장 탄탄했지만—단조적 성능 향상을 보장하는 constraint 최적화—conjugate gradient와 Fisher-vector product 계산을 요구하는 2차 최적화 특성상 구현 복잡도가 높고, dropout이나 파라미터 공유 아키텍처와 호환되지 않았다.
PPO의 출발점은 단순한 질문이다: TRPO가 제공하는 안정성을 1차 최적화만으로 달성할 수 있는가? 논문의 답은 “확률 비율을 클리핑하면 된다”이다.
이 아이디어는 구현 관점에서는 loss 함수 한 줄을 바꾸는 수준이지만, 그 효과는 TRPO에 필적하거나 능가한다.
PPO가 주장하는 바는 세 가지로 요약된다.
첫째, clipped surrogate objective를 통해 과도한 정책 업데이트를 방지한다.
둘째, 동일한 rollout 데이터로 여러 에폭 동안 SGD 업데이트를 수행하여 샘플 효율을 높인다.
셋째, 아키텍처 제약이 없어(단순한 구조, 범용성) 다양한 실험 설정에 그대로 적용 가능하다.
2. Background: Policy Optimization
2.1 Policy Gradient Methods
Policy gradient의 기본 목표는 기대 누적 보상 를 최대화하는 것이다. Policy gradient 정리에 따라 gradient는:
여기서 는 어드밴티지 추정값으로, 행동 가 기준선(value function)보다 얼마나 좋은지를 나타낸다. 이 gradient를 사용하는 objective를 명시적으로 쓰면:
vanilla policy gradient의 핵심 제약은 동일한 샘플로 한 번만 업데이트해야 한다는 것이다. 같은 데이터를 여러 번 사용하면 와 샘플을 생성한 사이의 괴리가 커져 gradient 추정이 편향되고 정책이 붕괴(policy collapse)할 수 있다.
2.2 Trust Region Methods
TRPO는 이 문제를 constraint 최적화로 해결한다. 핵심 아이디어는 CPI(Conservative Policy Iteration) objective인 를 KL divergence constraint 하에 최대화하는 것이다.
확률 비율("지금 정책이 예전 정책보다 이 행동을 얼마나 더/덜 선택하냐" ) 를 도입하면, 는:
에서 이 되므로 는 와 동일한 gradient를 갖는다. TRPO는 이를:
로 최적화한다. 이 constraint는 정책이 너무 크게 변하지 못하도록 보장하며, Kakade & Langford(2002)의 이론에 의해 의 단조 향상이 보장된다. 그러나 constraint를 만족하면서 최적화하려면 conjugate gradient로 natural gradient를 계산하고, line search로 step size를 결정해야 한다—이는 2차 최적화에 해당하며, 구현 복잡도가 극적으로 높아진다.
또한 패널티 계수 를 최적 효율로 튜닝하는것이 어렵다. (동일한 훈련 과정에서도 초반에는 값을 크기, 후반부에는 작게 조정해야 최적 효율이 나옴)
3. Clipped Surrogate Objective
PPO의 핵심 기여는 TRPO의 KL constraint를 클리핑으로 대체하는 것이다:
이 식을 제대로 이해하려면 경우의 수를 분해해야 한다:
| 조건 | 범위 | 선택 | 해석 |
|---|---|---|---|
| , | 정상 | (unclipped) | 정상 gradient 흐름 |
| , | 과도 증가 | (clipped) | gradient 차단 |
| , | 정상 | (unclipped) | 정상 gradient 흐름 |
| , | 과도 감소 | (clipped) | gradient 차단 |
을 취하는 설계 결정이 핵심이다.
인 경우, 이면 이므로 min이 clipped 값을 선택하고 gradient가 0이 된다.
반대로 이면 이므로 min이 unclipped 값을 선택하여 페널티가 그대로 흐른다.
이 메커니즘이 구현하는 것은 단방향 보수주의다: objective가 좋아지는 방향으로 가 범위를 벗어나면 그 이득을 무시하고, 나빠지는 방향으로 벗어나면 끝까지 페널티를 준다.
을 사용하지 않고 만 썼다고 가정하면, (결과가 나쁜 행동), 인 상황에서 나쁜 방향으로의 과도한 움직임을 허용한다. 값이 상한선인 으로 잘리면서 목적 함수 값이 상수로 고정되어 버리기 때문이다.
즉, 평탄 구간 gradient가 0이 되고 기울기가 차단되어 결과적으로 모델이 나쁜 방향으로 과도하게 움직이는 것을 그대로 허용하고 방치하게 된다.
머신러닝 관점에서 은 함수 공간에서의 암묵적 정규화로 해석할 수 있다. 일반적인 딥러닝에서 정규화가 가중치 파라미터가 비정상적으로 커지는 것을 억제하듯, PPO의 클리핑 메커니즘은 이전 정책과 현재 정책 간의 '확률 비율()' 변화를 제한한다.
이전 세대의 TRPO 알고리즘이 정책 붕괴를 막기 위해 무거운 연산량을 동원하여 명시적인 KL 제약을 외부에 억지로 걸어야 했던 것과 대조적이다. PPO는 목적 함수 수식 자체에 min과 clip의 조합을 통해 이 강력한 제약과 방어 기제를 내재화한 것이다.
Figure 1은 단일 타임스텝에서 의 형태를 시각화한다: A > 0 (좋은 행동), A < 0 (나쁜 행동):
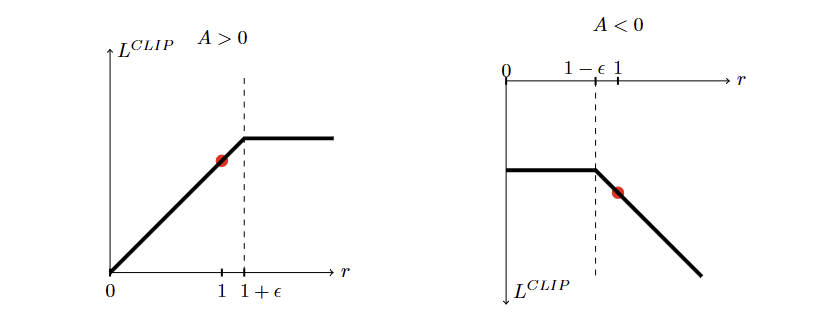
(점선 원)은 업데이트 전 초기 상태를 나타내며, 클리핑 구간을 벗어나는 영역에서 objective가 평탄해진다.
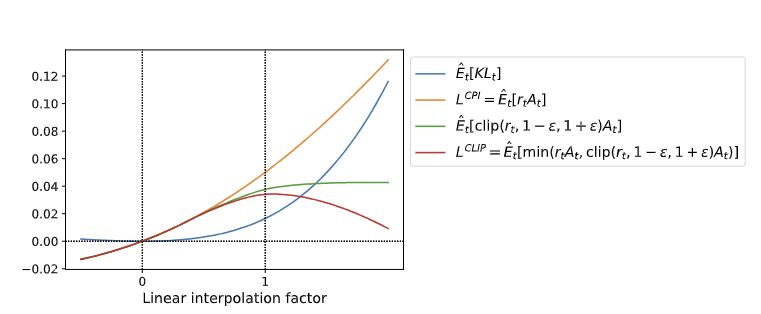
Figure 2는 실제 Hopper-v1의 첫 번째 업데이트에서 에서 새로운 방향으로의 선형 보간 경로를 따라 각 objective를 비교한다.
는 단조 증가하지만 은 policy가 너무 멀어지면 감소하기 시작하는 lower bound를 형성한다—이 의 pessimistic lower bound임이 직관적으로 확인된다.
4. Adaptive KL Penalty Coefficient
PPO가 제시하는 두 번째 변형은 KL divergence를 penalty로 사용하되 계수 를 자동으로 조정하는 방식이다:
각 업데이트 후, 실제 KL 를 측정하여 를 갱신한다:
1.5와 2라는 숫자는 완전한 heuristic이며, 논문 자체도 알고리즘이 이에 민감하지 않다고 인정한다. 지수적 조정( 또는 )을 택한 이유는 의 초기값과 무관하게 빠르게 수렴하기 위해서다—PID 제어기의 적분항(I)과 구조적으로 유사하다.
그러나 이 방식은 근본적인 약점을 가진다. 한 번의 업데이트 이터레이션 내에서는 가 고정된 채로 미니배치 SGD가 진행된다. KL이 이미 목표를 초과해도 가 즉각 반응하지 않는다.
반면 clipping은 매 gradient step마다 자동으로 보호 작용을 한다—이것이 실험에서 Adaptive KL이 Clipping에 뒤지는 주요 원인으로 추정된다.
5. Algorithm
PPO 알고리즘은 다음의 세 가지 항을 동시에 최적화하는 단일 목적 함수를 사용한다.
각 항의 역할 및 세부 정의
- : 정책 개선(Policy Improvement)을 담당. 범위 내에서 클리핑을 적용하여 파괴적인 업데이트 방지
- : 가치 함수(Value Function) 학습을 위한 평균 제곱 오차(Squared-error Loss)
- 여기서 는 시간차 타겟(TD Target)의 변형으로, 보통 로 정의됨.
즉, 실제 얻은 보상 기반의 총합(실제 Return 추정값)을 향해 가치 함수가 수렴하도록 학습시킴.
- : 엔트로피 보너스(Entropy Bonus). 정책의 확률 분포가 너무 일찍 하나로 굳어지는 것을 막고, 다양한 행동을 시도하도록 탐험(Exploration)을 장려.
과 는 각 항의 영향력을 조절하는 가중치(Coefficient)다. Policy와 value function이 파라미터를 공유하는 경우 이 중요해진다—두 loss의 스케일이 다르면 학습이 불안정해지기 때문이다.
-
관측치(Observation)를 처리하는 공통 백본(Shared Backbone) 위에 정책 헤드(Actor)와 가치 헤드(Critic)가 동시에 존재하는 경우, 하나의 가중치 로 두 손실을 동시에 최적화해야 한다.
-
이때 은 확률 비율이므로 보통 의 매우 작은 스케일을 가지지만, 는 환경 보상에 따라 수십에서 수백 스케일로 커질 수 있다.
-
수치(보통 0.5)로 스케일을 강제로 조정하지 않으면 가치 함수의 거대한 기울기(Gradient)가 전체 신경망 학습을 지배해 버려 정책 학습이 붕괴된다.
PPO 알고리즘의 전체 흐름(Algorithm 1)은 다음과 같다:

Step 1: 데이터 수집 (Inner For Loop)
- 명의 액터가 환경과 병렬로 상호작용하며, 각각 타임스텝 동안 현재 정책 로 롤아웃(Rollout)을 수행
- (총 데이터 수집)각 타임스텝마다 일반화된 어드밴티지 추정(Generalized Advantage Estimation, GAE)을 통해 어드밴티지 를 계산
Step 2: 대리 목적 함수 최적화 (Surrogate Optimization)
- 수집한 개의 데이터 전체를 미니배치(Minibatch) 크기 (보통 64 또는 256)으로 나누어 그래디언트 업데이트를 수행.
- 이 과정을 에포크(Epochs)만큼 반복함. TRPO는 수집한 데이터를 한 번만 쓰고 버려 샘플 효율(Sample Efficiency)이 극도로 나빴지만, PPO는 클리핑이 정책 변화를 방어해 주므로 같은 데이터를 번 안전하게 재사용 가능. (단, 가 너무 크면 클리핑 효과가 무력화될 수 있다.)
Step 3: 정책 동기화 (Policy Update)
- 번의 반복 학습이 완료되면, 이전 정책 를 새롭게 최적화된 정책 로 교체하고, 이 새로운 정책으로 다시 Step 1의 데이터 수집 시작.
기존 표준 정책 경사 Vanilla Policy Gradient 방식과의 가장 큰 차별점은 한 번 수집한 데이터를 epoch동안 버리지 않고 재사용한다는 것이다.
이때 개의 병렬 액터가 각기 다른 탐험 궤적 을 동시에 수집하여 미니배치에 섞어 넣는다.
epoch동안 미니배치 학습이 반복되면서 업데이트할 가중치 는 계속 변한다. 하지만 목적 함수 수식 의 분모에 있는 는 이터레이션 시작 시점의 낡은 가중치로 고정되어 있다.
결국 후반부 에포크로 갈수록 비교 기준점()이 너무 옛날 모델이 되어 심각한 편향이 발생한다.
이때 PPO의 클리핑 Clipping 메커니즘이 진가를 발휘한다. 두 정책 간의 확률 비율이 허용 범위를 벗어나지 못하게 잘라냄으로써, 이 낡은 기준점으로 인해 발생하는 편향이 무한정 증폭되는 것을 막아주는 이중 방어선 역할을 수행한다.
어드밴티지 계산에 쓰이는 GAE 파라미터 는 모델의 성능 평가 방식을 조율한다.
- : 바로 다음 스텝의 보상만 보는 1-step TD. 평가는 안정적이나 Variance 이 낮음, 시야가 좁아 편향이 높다(근시안적 평가).
- : 에피소드 끝까지 실제 받은 보상을 다 더하는 Monte Carlo 리턴. 시야가 넓어 편향은 낮으나, 운에 따른 노이즈가 심해 분산이 높다.
본 논문은 를 채택하여 두 극단 사이의 최적의 균형을 잡는다.
어드밴티지 의 1회 계산 및 재사용은 연산 효율을 극대화하는 핵심 포인트다. GAE로 정교하게 계산된 값은 매 에포크마다 새롭게 계산하는 것이 아니다.
이터레이션 초기에 정책으로 롤아웃 Rollout 을 수행할 때 딱 한 번만 계산해 두고, 이후 에포크의 반복 학습 내내 고정된 상수로 재사용한다.
6. Experiments
6.1 Comparison of Surrogate Objectives
Section 3과 4에서 제안한 objective 변형들을 직접 비교한다. MuJoCo 7개 연속 제어 환경(HalfCheetah, Hopper, InvertedDoublePendulum, InvertedPendulum, Reacher, Swimmer, Walker2d)에서 각 알고리즘을 3개 랜덤 시드로 1M 타임스텝 학습하여 총 21회 실행의 결과를 정규화한다.
정규화 방식: 각 환경에서 랜덤 정책의 점수를 0, 해당 실험의 최고 점수를 1로 shift/scale한 후 21개 실행을 평균낸다. 이 정규화는 HalfCheetah처럼 보상 절대값이 큰 환경이 결과를 지배하는 것을 방지한다.
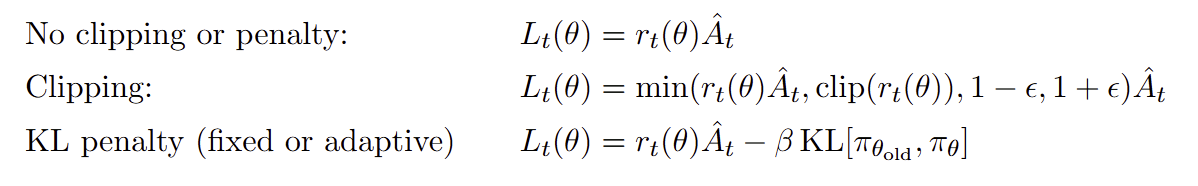

No clipping이 -0.39라는 최악의 점수를 기록한 이유는 HalfCheetah에서 정책이 붕괴했기 때문이다—랜덤 정책보다도 나쁜 성능으로 평균을 극단적으로 끌어내렸다. 이것이 같은 데이터로 여러 번 unconstrained 업데이트를 하면 어떤 일이 생기는지를 실증적으로 보여준다.
Clipping에서 가 최고(0.82)이며, 이 작으면(0.1) 업데이트가 지나치게 보수적이어서 학습이 느리고, 크면(0.3) 안정성을 잃는다. Adaptive KL은 Fixed KL보다 전반적으로 우수하지만 Clipping에는 미치지 못한다—앞서 설명한 이터레이션 내 고정 문제가 원인으로 추정된다.
6.2 Comparison to Other Algorithms in the Continuous Domain
동일한 MuJoCo 7개 환경에서 6개 알고리즘을 1M 타임스텝 동안 비교한다: A2C, A2C+Trust Region, CEM(Cross-Entropy Method), PPO(Clip), Vanilla PG(Adaptive KL), TRPO.
전반적 결과: PPO는 “거의 모든” 환경에서 1위 또는 그에 준하는 성능을 보인다.
주목할 만한 환경별 관찰:
- Walker2d: PPO가 3000+ 달성, 다른 방법들을 압도적으로 능가
- HalfCheetah: PPO가 초기 학습 속도 최고, 최종 성능도 우수
- Hopper: PPO > TRPO, A2C는 낮은 성능대에 머뭄
- Swimmer: Vanilla PG Adaptive가 의외로 경쟁력 있음—환경 특성에 따른 예외
비교의 공정성에 관해 한 가지 언급이 필요하다. CEM은 파라미터가 없는 진화적 방법으로 DNN과 결합 시 스케일링 문제가 있어 낮은 성능이 예상 가능하다.
더 의미 있는 비교는 PPO vs TRPO로, 둘이 유사하거나 PPO가 우세한 성능을 내면서 구현 복잡도는 PPO가 훨씬 낮다—이것이 PPO의 실용적 가치를 가장 잘 드러내는 비교다.
6.3 Showcase in the Continuous Domain: Humanoid Running and Steering
고차원 연속 제어의 대규모 실험으로 세 가지 Roboschool 과제에서 PPO를 단독으로 학습한다:
- RoboschoolHumanoid: 50M 스텝, ~3500 보상으로 안정적 수렴
- RoboschoolHumanoidFlagrun: 100M 스텝, ~2000 달성 (목표 위치가 주기적으로 무작위 변경)
- RoboschoolHumanoidFlagrunHarder: 100M 스텝, ~2500 달성 (큐브에 맞은 후 쓰러진 상태에서 일어나야 함)
이 섹션의 한계는 다른 알고리즘과의 비교 없이 PPO 단독 결과만 제시한다는 점이다. 섹션 제목 “showcase”가 시사하듯, 정량적 우위 증명보다는 PPO가 장기간 대규모 고차원 문제에서도 안정적으로 학습 가능함을 질적으로 보여주는 것이 목적이다.

Figure 5의 프레임 시퀀스는 로봇이 목표 방향으로 달리다가 목표 위치 변경 후 방향을 전환하는 자연스러운 locomotion 행동이 창발했음을 시각적으로 확인한다.
이 실험과 병행하여 Heess et al.(2017)이 PPO의 Adaptive KL variant를 독립적으로 사용하여 유사한 humanoid 제어 결과를 얻었다고 논문은 언급한다.
6.4 Comparison to Other Algorithms on the Atari Domain
Atari 49개 게임에서 A2C, ACER, PPO를 각 3개 시드로 40M 프레임(= 10M timesteps) 학습한다. 비교 기준은 두 가지다: 전체 학습 기간의 평균 보상(빠른 학습 능력)과 마지막 100 에피소드의 평균 보상(최종 성능).
Table 2 — 49개 게임 “승리” 횟수

두 기준의 결과가 역전되는 것이 흥미롭다. PPO는 초기 학습 속도에서 압도적으로 우세(30승)하지만, 최종 성능에서는 ACER에 뒤진다(19승 vs 28승).
이 역전의 구조적 원인은 ACER의 experience replay에 있다:
ACER는 과거 데이터를 off-policy correction과 함께 재사용하므로 같은 프레임 수에서 더 많은 학습이 누적된다.
PPO는 on-policy 알고리즘으로 각 이터레이션의 NT 샘플을 K 에폭 후 버리기 때문에, 학습 후반부로 갈수록 누적 샘플 활용 효율에서 뒤처진다.
PPO가 압도적인 게임들(Enduro, Kangaroo, 원문 Table 6 참조)의 공통점은 exploration보다 안정적인 정책 실행이 중요한 경우다.
PPO의 entropy bonus가 이 게임들에서 효과적으로 작용했을 가능성이 있다. MontezumaRevenge에서 PPO가 42점을 기록한 것은 셋 중 유일하게 0을 넘은 것이지만, 이 게임의 최고 기록은 수천 점이므로 실질적 의미는 제한적이다.
40M 프레임이라는 실험 범위에 관해서도 주의가 필요하다. Atari에서 인간 수준 성능에는 보통 수억 프레임이 필요하다. PPO의 초기 학습 속도 이점이 더 긴 학습에서도 유지되는지는 이 실험만으로 알 수 없다.
7. Conclusion
논문은 PPO를 세 가지 측면에서 정리한다.
-
달성한 것: TRPO가 constraint 최적화로 달성한 안정적 업데이트를, clipped surrogate objective라는 단순한 1차 최적화 기법으로 재현했다. 동일 데이터의 다중 에폭 재사용을 안전하게 가능하게 하여 샘플 효율을 높였다.
-
실증적 우위: MuJoCo 7개 환경과 Atari 49개 게임을 포함한 총 59개 이상의 태스크에서 A2C, TRPO 등 기존 방법들 대비 경쟁력 있는 성능을 일관되게 보였다.
-
남겨진 것: 논문 스스로도 인정하듯, clipping이 policy improvement를 보장한다는 이론적 증명은 없다.
TRPO의 단조 향상 보장과 달리 PPO는 “경험적으로” 작동한다. 또한 K 에폭, T horizon, N 액터 수 등 하이퍼파라미터의 선택이 환경마다 달라 새 환경에 적용할 때의 가이드가 부족하다.
실용적 관점에서 PPO의 가장 큰 의의는 “좋은 알고리즘이 반드시 복잡할 필요는 없다”는 것을 보여준 데 있다.
이 단순성이 이후 PPO가 RLHF(InstructGPT, ChatGPT)의 표준 알고리즘으로 채택된 배경이다.
Appendix
A. Hyperparameters
세 가지 도메인에 사용된 하이퍼파라미터를 정리한다:
| 파라미터 | MuJoCo | Roboschool | Atari |
|---|---|---|---|
| Horizon | 2048 | 512 | 128 |
| # epochs | 10 | 15 | 3 |
| Minibatch size | 64 | 4096 | 256 (32×8) |
| Discount | 0.99 | 0.99 | 0.99 |
| GAE | 0.95 | 0.95 | 0.95 |
| Adam stepsize | adaptive | ||
| Clipping | 0.2 | — | |
| # actors | — | 32~128 | 8 |
Atari에서 는 학습 진행에 따라 으로 선형 감소(annealing)된다. 즉 stepsize와 clipping 범위가 동시에 줄어들어 학습 후반에 점점 더 보수적인 업데이트를 수행한다—이는 fine-tuning 효과를 낸다. 이 annealing이 Atari 결과에 얼마나 기여했는지 ablation이 없다는 점은 이 실험 설계의 주요 누락이다.
도메인 간 의 차이(MuJoCo 10, Atari 3)도 주목할 만하다. Atari에서 으로 제한한 것은 연속 행동 공간보다 이산 Atari에서 다중 에폭 업데이트가 정책을 더 빠르게 불안정하게 만들기 때문으로 추정된다.
MuJoCo에서는 의 긴 horizon으로 충분한 데이터를 확보하고 10 에폭을 사용하는 반면, Atari는 의 짧은 horizon으로 빠르게 rollout하고 에폭을 제한한다.
B. Performance on More Atari Games
Appendix B는 49개 게임 전체의 개별 점수를 제시한다(Table 6). 마지막 100 에피소드 기준으로 일부 주목할 수치를 정리한다:
게임마다 우위 알고리즘이 달라 패턴을 단순화하기 어렵다. 전반적으로 ACER는 장기 학습에서 높은 최댓값에 도달하는 게임이 많고, PPO는 일관되게 A2C를 능가하면서 상당수 게임에서 ACER와 경쟁한다.
Figure 6의 학습 곡선은 3개 시드의 분산이 게임마다 매우 다름을 보여주며, 일부 게임에서는 시드 간 차이가 알고리즘 간 차이보다 크다—이는 단순 “승리 횟수” 집계의 통계적 취약점이다.
