
Attention is All you Need(2017) 논문을 읽고 내용 요약 및 정리를 담았다.
1. Introduction
순환 신경망 구조(RNN)와 장단기 메모리(LSTM)은 인풋과 아웃풋 시퀀스의 심볼 위치를 연산에 고려한다. 순환 신경망 모델은 연산 시간동안 스텝과 위치를 나란히 하며, 이전 은닉 상태 ht-1 의 함수이자 포지션 t의 인풋으로 은닉 상태 시퀀스 ht를 생성한다. 이러한 생성은 시퀀스 특성이 학습 예제 내에서 병렬화를 불가능하게 하는데, 메모리 제한이 학습시 배치 처리를 제한하기 때문에 시퀀스 길이가 더 길때 치명적이다. 최신 연구에서 factorization trick과 conditional computation을 통해 컴퓨팅 효율을 향상시키긴 했으나, 근본적인 시퀀스적 연산의 한계가 남아있다.
어텐션 메커니즘(Attention mechanisms)은 인풋과 아웃풋 거리에 관계없이 의존성(dependencies)을 모델링 할 수 있도록 하여, 다양한 분야에서 시퀀스 모델링과 변환 모델을 사용하게 하는 필수 요소이다. 본 연구에서는 순환 대신 인풋과 아웃풋의 전역적 의존성을 이끌어내기 위해 어텐션 메커니즘에 전적으로 의존하는 Transformer라는 모델 구조를 제안한다.
2. Background
시퀀셜 연산을 줄이려는 목표는 ByteNet과 ConvS2S라는 모델로 Extended Neural GPU의 토대를 마련하는데, 두가지 모델 모두 컨볼루션 신경망을 기반으로 하고, 인풋과 아웃풋 포지션에서 병렬로 hidden representation을 연산을 연산한다. 두개의 인풋, 또는 아웃풋 포지션에서 신호를 연결할 때 필요한 연산 수는 포지션 간 거리에 따라 ConvS2S에서 선형적으로, ByteNet에서 대수적으로 증가한다. 이러한 연산량 증가가 멀리 떨어진 포지션 간의 의존성을 학습하는 것을 더 어렵게 만든다. Transformer에서는 이러한 연산을 어텐션 가중치 포지션을 평균냄으로써 상수의 연산으로 감소시킨다.
Self-Attention은 시퀀스의 representation을 연산하기 위해 단일 시퀀스의 다른 포지션을 연관짓는 어텐션 메커니즘이다. Transformer는 이러한 self-attention에 전적으로 의존하고, RNN이나 컨볼루션 구조를 사용하지 않는 최초의 변환 모델이다.
3. Model Architecture
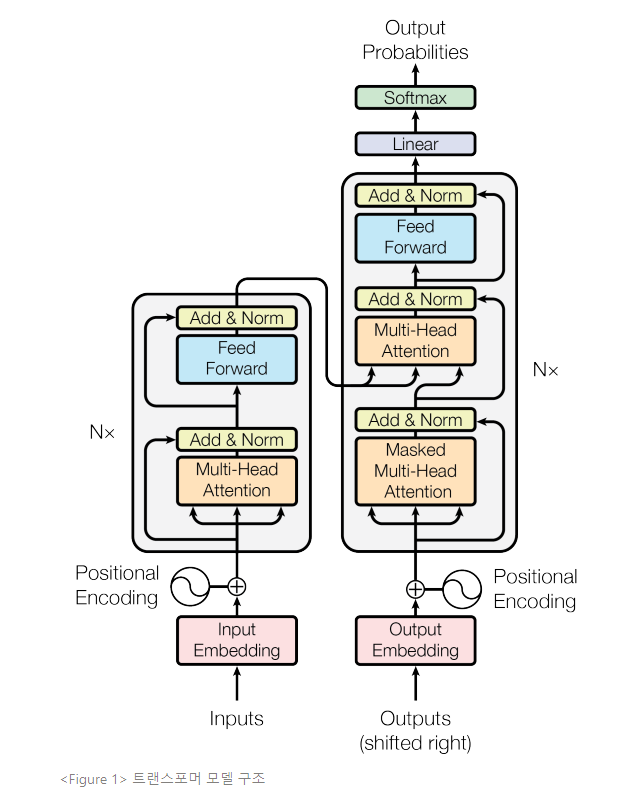
가장 유능한 시퀀스 변환 모델은 인코더-디코더의 구조이다. 이 구조에서 인코더는 심볼 representation의 인풋 시퀀스(x1, x2, ..., xn)를 연속적인 representation 시퀀스 z(z1, z2, ..., zn)로 사상(mapping)한다. 디코더는 z가 주어지면 심볼 아웃풋 시퀀스(y1, y2, ..., ym)를 한번에 한 엘리먼트씩 생성한다. 모델은 각 스텝에서 다음 심볼을 생성할 때 이전에 생성한 심볼을 부가적인 인풋으로 소모하며 자동 회귀한다.
트랜스포머는 Figure 1에서 제시된 것과 같이, 인코더와 디코더 양측에서 완전히 연결된 레이어를 사용하며, 위에 서술한 전반적인 인코더-디코더 구조를 따른다.
-
Encoder는 N=6 layer의 스택으로 구성된다. 각각의 레이어는 서브 레이어 2개를 소유한다. 하나의 레이어는멀티헤드 셀프 어텐션 메커니즘(multi-head self-attention mechanism)이고, 다른 하나는 단순한position-wise feed-forward네트워크이다. 두개의 각 서브 레이어 주변에는 레이어 정규화에 수반된 잔차 연결(residual connection)을 이용한다. 여기서 각 서브 레이어의 아웃풋이 LayerNorm(x + Sublayer(x))이 되는데, Sublayer(x)는 서브 레이어 자체에서 시행된 함수이다. 이러한 잔차 연결을 촉진하기 위해, 모델의 임베딩 레이어와 모든 서브 레이어가 차원 dmodel = 512의 아웃풋을 생성한다. -
Decoder도 동일한 N=6 layer의 스택으로 구성된다. 디코더는 각 인코더 레이어에 있는 서브 레이어에 더하여 3번째 서브 레이어를 삽입하는데, 이 레이어는 인코더 스택의 아웃풋에 멀티 헤드 어텐션을 수행한다. 인코더와 유사하게, 레이어 정규화에 수반된 잔차 연결을 각 서브 레이어에 사용한다. 또한, 디코더 스택의 셀프 어텐션 서브 레이어가 차후 포지션에 관여하지 못하도록 변경한다. 이러한 작업은 아웃풋 임베딩이 한 포지션에 의해 상쇄된다는 것과 결부되어, 포지션 i에 대한 예측이 i보다 작은 포지션에 있는 알려진 아웃풋에만 의존할 수 있도록 보장한다. -
Attention
어텐션 함수는 쿼리(query), 키(key), 밸류(value), 아웃풋이 모두 벡터인 공간에서 쿼리와 키-밸류 쌍 매핑으로 설명할 수 있다. 아웃풋은 가중치가 부여된 밸류 합으로 연산되는데, 여기서 각 밸류에 할당된 가중치는 상응하는 키 값과 쿼리 호환성 함수에 의해 연산된다.
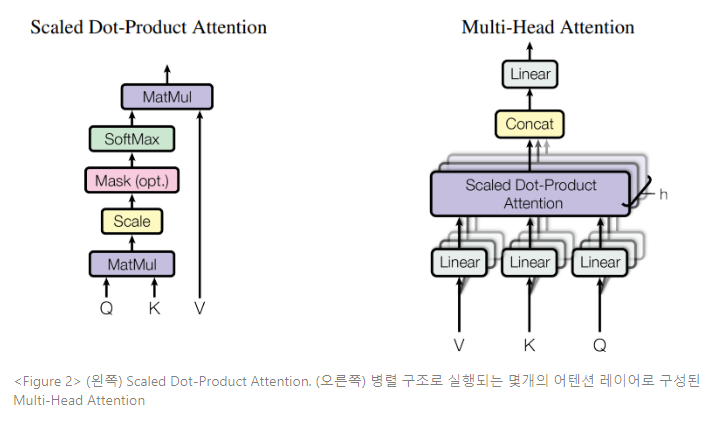
- Scaled dot-product attention
Figure 2와 같은 특정 어텐션은 Scaled Dot-Product Attention이라 명한다. 인풋은 차원 dk의 쿼리와 키, 차원 dv의 밸류로 구성되어 있다. 우리는 쿼리와 모든 키의 내적을 연산한 다음 각각을 √dk로 나누고, 밸류에 대한 가중치를 얻기 위해 소프트맥스 함수를 적용한다.
실제로 어텐션 함수는 쿼리 셋에서 동시다발적으로 연산되어, 행렬 Q로 결합된다. 키와 밸류도 행렬 K와 V로 결합된다. 우리는 아웃풋 행렬을 다음 식과 같이 연산한다.
가장 널리 사용되는 두 가지 어텐션 함수는 additive attention과 dot product(multiplicative) attention이다. dot product attention은 scaling factor인 1/√dk를 제외하면, 논문의 알고리즘과 동일하다. additive attention은 feed-forward 네트워크를 단일 은닉층과 사용하여 호환성 함수를 연산한다. 두 어텐션 함수가 이론적 복합성 면에서는 유사하지만, dot-product attention은 상당히 최적화된 행렬 곱 코드를 사용하여 시행될 수 있기 때문에, 훨씬 더 빠르고 공간적으로도 효율적이다.
dk 밸류가 작으면 두 메커니즘은 유사하게 작동하는데, additive attention은 더 큰 값의 dk를 스케일링하지 않고 dot product attention을 능가한다. 더 큰 값의 dk에서는 소프트맥수 함수를 극도로 작은 기울기가 있는 구역으로 삽입하며 dot products의 규모가 커지는 것을 의심한다. 이러한 영향에 대응하기 위해 우리는 dot products를 1/√dk로 스케일링한다.
Additive Attention
쿼리 벡터와 키 벡터의 조합으로 어텐션 값을 얻을 때 단일 hidden layer를 가진
feed-forward 네트워크를 이용한다. 쿼리 벡터(q)와 키 벡터(k)가 같은 차원을 가질 필요가
없으며, 차원 크기와 관계없이 좋은 성능을 보인다는 장점이 있다.Dot-product Attention
dot-product attention은 qTk를 기반으로 어텐션 가중치를 구하는 방법이다.
additive attention과는 달리 hidden layer를 곱하는 과정이 추가되지 않아 연산 속도와
공간 측면에서 효율적이다. 그러나 반드시 q와 k의 차원이 같아야 한다는 제약이 있으며,
차원이 클 때 학습에 방해가 된다는 단점이 있다.(참고) attention 설명
- multi-head attention
단일 어텐션 함수를 dmodel 차원의 키, 밸류, 쿼리로 수행하는 것 대신, 키, 밸류, 쿼리를 h번 동안 각 dk, dk와 dv에 학습된 다양한 선형 프로젝션(projection)과 선형으로 프로젝트하는 것이 유익함을 발견한다. 이렇게 프로젝트된 각각의 키, 밸류, 쿼리 버전에서 dv 차원의 아웃풋 밸류를 산출하며, 어텐션 함수를 병렬로 수행한다. 이러한 버전은 다시 연결(concatenate)되고 다시 한번 프로젝트되어 Figure 2와 같은 최종 밸류를 산출한다.
멀티 헤드 어텐션은 모델이 여러 위치의 여러 representation subspace의 정보에 공동으로 관리할 수 있도록 한다. 단일 어텐션 헤드로 평균화하는 것은 다음 식을 불가하게 한다.

본 연구는 h=8 병렬 어텐션 레이어 또는 헤드를 사용한다. 각 어텐션 레이어나 헤드에서 dk=dv=dmodel/h=64가 사용된다. 각 헤드에서 축소된 차원 때문에, 총 연산 비용은 최고 차원의 단일 헤드 어텐션 비용과 유사하다.
트랜스포머는 3가지의 방식으로 멀티 헤드 어텐션을 사용한다
- “인코더-디코더 어텐션”레이어에서 쿼리는 이전 디코더 레이어의 결과이고, 메모리 키와 밸류는 인코더 아웃풋의 결과가 된다. 이는 디코더의 모든 포지션이 인풋 시퀀스의 모든 포지션에 관여할 수 있도록 한다. 이는 seq2seq 모델의 전형적 인코더-디코더 어텐션 메커니즘을 모방한다.
- 인코더는 셀프 어텐션 레이어를 포함한다. 셀프 어텐션 레이어의 모든 키, 밸류, 쿼리는 동일한 장소에서 생성되는데, 이러한 경우 인코더에서 이전 레이어 아웃풋이 생성 장소가 된다. 각 인코더의 포지션은 인코더의 이전 레이어에 있는 모든 포지션에 관여할 수 있다.
- 이와 유사하게, 디코더의 셀프 어텐션 레이어는 디코더의 각 포지션이 해당 포지션을 포함해 모든 디코더 포지션에 관여할 수 있도록 한다. 자동 회귀 속성을 보존하기 위해서, 왼쪽의 정보 흐름을 막아야 할 필요가 있다. 허용되지 않는 커넥션에 대응하는 소프트맥스 인풋의 모든 밸류를 마스킹 함으로써 scaled dot-product attention 내부에 이를 시행한다.
- Position-wise Feed-Forward Networks
어텐션 서브 레이어에 덧붙여, 인코더와 디코더 각 레이어는 완전히 연결된 feed-forward network이며, 이는 각 포지션에 개별적으로 동등히 적용된다. 이 네트워크는 두 개의 선형 변환과 중간에 ReLU 활성화 함수로 구성되어 있다.
서
선형 변환이 여러 포지션에 동일하게 적용되지만, 레이어마다 다른 파라미터를 사용한다. 인풋과 아웃풋의 차원 수는 dmodel=512이고, 내부 레이어 차원 수는 dff=2048이다.
- feed-forward network(FFN)
순방향 신경망(feed-forward neural network)으로, 다층 퍼셉트론(MLP)과 같이 오직 입력층에서 출력층으로 연산이 전개되는 신경망을 피드 포워드 신경망이라고 함.
이와 대조하여 순환 신경망(RNN)은 출력층으로도 은닉층의 출력값을 보내지만, 동시에
은닉층의 출력값이 다시 은닉층의 입력으로 사용됨.타 시퀀스 변환 모델과 유사하게, 트랜스포머는 인풋 토큰과 아웃풋 토큰을 dmodel 차원의 벡터로 변경하기 위해 학습된 임베딩을 사용한다. 또한 디코더 아웃풋을 다음 토큰 확률 예측으로 변환하기 위해, 제너럴하게 학습된 임베딩을 사용한다. 트랜스포머에서는 두개의 임베딩 레이어와 사전 소프트맥스 선형 변환 사이의 동일한 가중치 행렬을 공유한다. 임베딩 레이어에서 이러한 가중치를 √dmodel에 곱한다.
- Positional Encoding
트랜스포머는 순환이나 컨볼루션 신경망을 포함하지 않기 때문에, 모델이 시퀀스 순서를 활용하도록 하기 위해 시퀀스에서 연관된 토큰이나 절대적 토큰 위치에 대한 정보를 주입해야 한다. 최종적으로, 트랜스포머는 인코더와 디코더 스택의 하단에서 포지셔널 임베딩(positional embedding)을 인풋 임베딩으로 추가한다. 포지셔널 임베딩은 dmodel과 동일한 임베딩 차원을 갖으므로, 둘은 합산될 수 있다. 학습 및 고정된 포지셔널 임베딩에는 많은 선택지가 있다.
본 연구에서 트랜스포머는 사인과 코사인 함수를 다양한 빈도수에 사용한다.
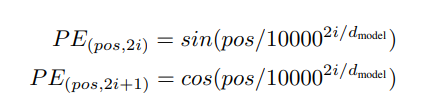
위의 식에서 pos는 포지션, i가 차원이다. 각 포지셔널 임베딩의 차원은 사인곡선(sinusoid)에 상응한다. 파장은 2π에서 10,000 * 2π의 등비수열(geometric progression)을 형성한다. 트랜스포머에 이 함수를 적용한 것은, 이 함수가 연관 포지션을 통해 관여하는 법을 더 쉽게 학습할 수 있게 한다고 가정했기 때문인데, PEpos+k는 특정한 고정 오프셋 k를 위해 PEpos의 선형 함수로서 표현될 수 있다.
학습된 포지셔널 임베딩 seq2seq를 대신해서 사용하여 실험했을 때, 두 버전이 거의 동일한 결과를 산출했다. 트랜스포머는 사은곡선 버전을 선택했는데, 사인 곡선은 모델이 학습 때 마주했던 시퀀스보다 더 긴 시퀀스를 추론할 수 있도록 하기 때문이다.
4. Why Self-Attention
셀프 어텐션 레이어와 심볼 representation에서 하나의 변수 길이 시퀀스(x1, x2,...,xn)를 또 다른 동일한 길이 시퀀스(z1,z2,...,zn)에 시퀀스 변형 인코더와 디코더에 있는 은닉층과 같은 xi , zi ∈ Rd와 사상하는 데 통용되는 순환 및 컨볼루션 레이어를 다양한 측면에서 비교한다. 셀프 어텐션 사용 동기부여에 있어 3가지의 필요사항을 고려한다.
- 각 레이어마다의 총 연산 복잡성(computational complexity)
- 병렬화 될 수 있는 연산의 양(최소한으로 필요한 시퀀셜 연산의 양으로 측정)
- 네트워크 장거리 의존성 간의 거리

Table 1과 같이, 셀프 어텐션 레이어는 연속적으로 수행된 작업의 상수로 모든 포지션을 연결하는 반면, 순환 레이어는 O(n)의 연속적 작업이 필요하다. 연산 복잡성 관점에서 보면 시퀀스 길이 n이 representation의 차원수 d보다 작을 때, 셀프 어텐션 레이어가 순환 레이어보다 빠르다. 아주 장문의 시퀀스를 포함한 태스크의 연산 성능을 향상시키기 위해, 셀프 어텐션은 각각의 아웃풋 포지션을 중심으로 둘러싼 인풋 시퀀스의 r 크기 이웃만을 고려하도록 제한될 수 있다. 이러한 제한은 최대 구간 길이를 O(n/r)로 증가시킬 수 있다.
커널 넓이 k<n인 단일 컨볼루션 레이어는 모든 인풋과 아웃풋 포지션 쌍을 연결하진 않는다. 모든 연결을 하기 위해서 연속된 커널의 경우 O(n/k)의 컨볼루션 레이어 층, 또는 팽창한 컨볼루션일 경우 O(logk(n))을 필요로 하고, 네트워크 특정 포지션 사이 가장 긴 구간의 길이를 증가시킨다. 컨볼루션 레이어는 일반적으로 k 요인에 의해 순환 레이어보다 더 많은 연산 비용이 든다. 그러나 분리가 가능한 컨볼루션은 복잡성을 O(knd+n*d2)로 크게 감소시킨다. 심지어 k=n일때도, 분리가능한 컨볼루션의 복잡성은 트랜스포머 모델에서 사용하는 셀프 어텐션 레이어와 point-wise feed-forward 레이어의 결합과 동등하다.
- Big O(빅오) 표기법?
빅오(점근적 표기법)는 알고리즘 효율성을 테스트하기 위한 표기법으로, 알고리즘의 시간 복잡도를 O(f(n))으로 나타낸다.
(참고) Big O 표기법의 종류
셀프 어텐션의 또 다른 이점은 더 해석하기 용이한 모델을 산출한다는 것이다. 독립적인 어텐션 헤드는 다양한 태스크를 수행할 수 있도록 명확하게 학습하며, 다수의 어텐션에서도 문장의 구문론, 의미론적 구조와 연관된 작용을 하는 것으로 보인다.
5. Training
트랜스포머 모델은 450만개 문장 쌍으로 구성된 표준 WMT 2014 영어-독일어 번역 데이터셋으로 학습되었다. 문장은 약 37,000개 토큰이 포함된 byte-pair 인코딩으로 인코딩되었다. 영어-프랑스어 번역에서는 3600만개 문장으로 구성되어 더 큰 데이터셋인 WMT 2014 영어-프랑스어 데이터셋을 사용했고 32,000 word-piece 단어로 토큰을 분리한다. 문장 쌍은 대략 시퀀스 길이로 배치되었다. 각 학습 배치는 대략 25,000개 원천 토큰과 25,000개 표적 토큰의 문장쌍을 포함한다.
트랜스포머 모델은 8 NVIDIA P100 GPU로 학습되었다. 본 논문의 베이스 모델에서 각 학습 스텝은 0.4초정도 소요되었고, 대형 모델에서는 각 스텝당 1.0초 정도 소요되었다. 대형 모델은 300,000개 스텝(3.5일)동안 학습되었다.
트랜스포머는 Adam 최적화 함수를 β1 = 0.9, β2 = 0.98 and e = 10−9로 사용했다. 학습률은 다음 공식에 따라 학습과정을 거치며 다르게 설정되었다.
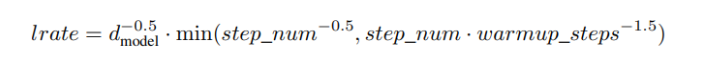
이 식은 학습률을 최초 warmup_step의 학습 스텝을 위해 선형적으로 증가시키고, 이후 스텝 수의 역제곱근에 비례하여 감소시키는 것에 대한 식이다. 트랜스포머는 warmup_steps를 4,000으로 사용했다.
트랜스포머 학습에 사용되는 규제는 다음과 같다.
- Residual Dropout(잔차 드롭아웃) : 각 서브 레이어의 아웃풋이 서브 레이어의 인풋에 삽입되어 정규화되기 이전에 드롭아웃을 적용한다. 또한, 인코더와 디코더 스택에서 모두 임베딩과 포지셔널의 합에 드롭아웃을 적용한다. 베이스 모델에는 Pdrop=0.1을 적용한다.
- Label Smoothing(라벨 평활화) : 학습이 진행되는 동안 els=0.1로 라벨 평활화를 적용한다. 이는 펄플렉시티(perplexity)를 손상시켜 모델이 더 불확실해지기도 하지만, 정확도와 BLEU 스코어를 향상시킨다.
- perplexity
언어 모델을 평가하기 위한 평가지표로, 보통 PPL이라고 표기한다. 영어 뜻은 ‘헷갈리는’ 이라는 의미를 가져, ppl은 ‘헷갈리는 정도’로 통하게 된다. 따라서 ppl이 낮을수록 언어 모델의 성능이 좋다는 것을 의미한다. ppl은 모델 내에서 자신의 성능을 수치화하여 결과를 내놓기 때문에, 정확도는 조금 떨어지더라도 테스트에 대해 빠르게 계산할 수 있는 간단한 평가 방법이다.
(참조) 펄플렉서티(ppl)란
- BLEU(Bilingual Evaluation Understudy)
기계 번역 성능 측정에 사용되는 지표로, 측정 기준은 n-gram에 기반한다. BLEU는 유니그램 정밀도(Unigram Precision)를 사용하여 측정하는데, 생성된 문장과 실제 번역 문장을 비교하여 번역 문장에 등장한 생성 문장 단어의 합을 생성 문장 길이로 나눈 식이다. 언어에 구애받지 않고 사용할 수 있으며, 계산 속도가 빠른 이점을 가진다.
그러나 이러한 계산식은 중복 단어 생성 문장을 계산하면 제대로 된 평가를 하지 못한다는 한계점이 있다.( The the the the the the → the boy went to the supermarket 인 경우 유니그램 정밀도가 1이 됨)
이러한 한계점을 극복하기 위해, 중복 제거 보정을 사용한다. 유니그램이 하나의 번역문에서 최대 몇 번 등장했는지를 카운트하는데, 이 카운트가 기존 단순 카운트 값보다 작은 경우에는 이 값을 최종 카운트 값으로 대체한다. 이러한 카운트를 사용해서 분자를 계산한 정밀도를 보정된 유니그림 정밀도(Modified Unigram Precision)라고 한다.
(참조) BLEU 스코어란
6. Results
대형 트랜스포머 모델(Transformer(big))은 WMT 2014 영어-독일어 번역 태스크에서 28.4 BLEU 스코어로 새로운 SOTA를 달성한다. WMT 2014 영어-프랑스어 번역 태스크에서는 41.0 BLEU 스코어로, 기존 SOTA 모델의 학습 비용을 1/4만큼 감소시키고 가장 최고 성능으로 배포된 단일 모델을 능가한다. 영어-프랑스어 번역을 위해 학습된 대형 트랜스포머 모델은 dropout을 0.3대신 0.1로 사용했다.
베이스 모델은 10분 간격으로 수행한 마지막 5개 체크포인트를 평균해서 얻은 단일 모델을 사용한다. 대형 모델은 마지막 20개 체크포인트를 평균한다. 모델은 빔 크기 4로 길이 패널티 a=0.6의 빔 서치를 사용한다. 이러한 하이퍼파라미터는 dev set에서 실험 후에 선택되었다. 추론시에 최대 아웃풋 길이는 인풋 길이+50으로 설정했으나, 가능하면 빠르게 종료하도록 했다.
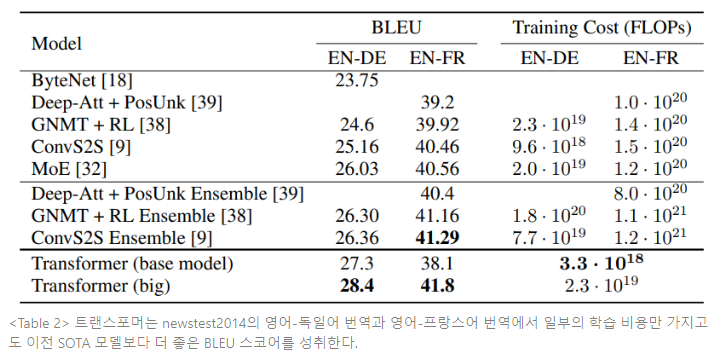
Table 2는 모델의 결과를 요약하고 번역의 질과 학습 비용을 다른 모델들의 구조와 비교한다.
트랜스포머의 구성요소들의 중요성을 평가하기 위해, dev set인 newstest2013으로 영어-독일어 번역의 성능 변화를 측정하며, 베이스 모델을 다양한 방법으로 베리에이션 했다. 체크포인트 평균 대신 이전 섹션에서 설명한 것과 같이 빔 서치 방식을 사용했다. 실험 결과는 Table 3에 명시된다.
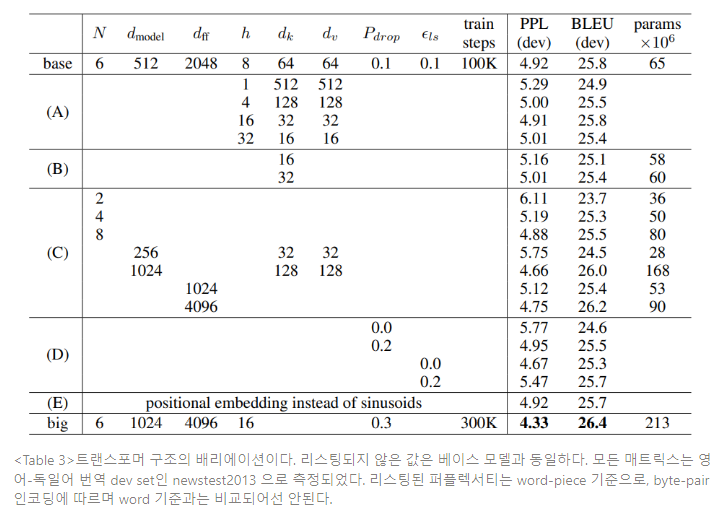
(A)에서 연산 상수양은 유지하면서 어텐션 헤드의 숫자와 어텐션 키, 밸류의 차원을 다양하게 했다. 단일 헤드 어텐션이 최적 세팅에서 0.9 BLEU 스코어만큼 뒤떨어진 반면, 너무 많은 헤드수도 성능이 떨어진다. (B)에서 어텐션 키 크기 dk를 줄이는 것이 모델의 성능을 손상시키는 것을 확인한다. 이는 호환성을 고려하기 쉽지 않고, dot-product보다 더 정교한 호환성 함수가 좋을 거라는 것을 시사한다. (C), (D) 에서 예측한 바와 같이 더 큰 모델이 성능이 좋고, 오버피팅을 피하기에 드롭아웃이 크게 도움된다는 것을 확인한다. (E)에서 사인곡선의 포지셔널 인코딩을 학습된 포지셔널 임베딩으로 교체하고, 베이스 모델과 거의 동일한 결과를 관측한다.
트랜스포머가 다른 태스크를 일반화할 수 있는지 평가하기 위해, 영어의 constituency parsing(구문분석)으로 실험을 진행했다.
약 40k의 학습 문장이 있는 Penn Treebank의 Wall Street Journal(WSJ) portion에서 4개 레이어 트랜스포머를 dmodel=1024로 학습시켰다. 또한 약 17m의 문장이 있는 BerkleyParser corpora를 사용하여 준지도 학습 설정으로 학습시켰다. 16k 토큰은 WSJ only설정에서 사용됐고, 32k 토큰은 준지도 학습 설정에 사용됐다.
어텐션과 잔차, 드롭아웃, 학습률과 빔 크기 등 영어-독일어 베이스 번역 모델에서 바뀌지 않은 채로 유지된 파라미터들을 선택하기 위한 실험을 수행했다(섹션 5.4). 추론을 하는 동안 최대 아웃풋 길이를 인풋 길이 + 300으로 증가시켰다. WSJ only와 준지도 학습 모두 빔 크기를 21, a=0.3으로 사용했다.
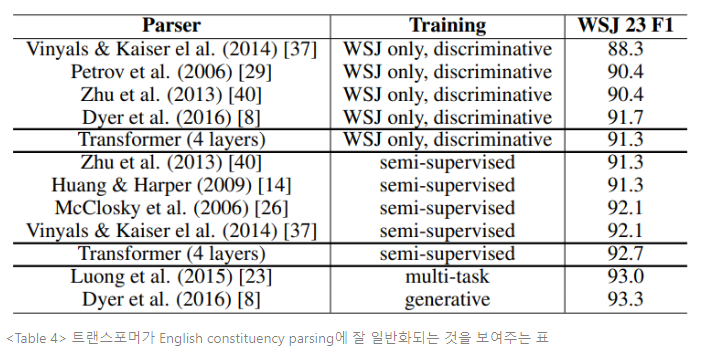
Table 4의 결과는 태스크 명시적 튜닝이 부족함에도 불구하고, 트랜스포머는 RNN Grammar를 제외한 모든 모델보다 좋은 결과를 산출하며, 놀라울 정도로 잘 작용한다. RNN seq2seq 모델과 대조되게, 트랜스포머는 40k 문장의 학습 세트인 only WSJ에서만 학습해도 Berkely-Parser에서 뛰어난 성능을 보인다.
7. Conclusion
본 연구는 멀티헤드 셀프 어텐션을 사용하는 인코더-디코더 구조에서 가장 흔히 사용되는 순환 레이어를 대치하고, 전적으로 어텐션에만 의존한 최초의 시퀀스 변환 모델인 트랜스포머를 제시한다.
번역 태스크에서 트랜스포머는 순환 레이어나 컨볼루션 레이어를 기반으로 한 구조보다 훨씬 빠르게 학습된다. WMT 2014 영어-독일어 번역과 WMT 2014 영어-프랑스어 번역 태스크에서 트랜스포머는 새로운 SOTA를 성취했다. 최고 모델 성능은 이전에 배포된 앙상블 모델도 능가한다.
