
Embedding
embedding(임베딩)은 사람이 사용하는 언어(자연어)를 컴퓨터가 이해할 수 있는 언어(숫자) 형태인 vector(벡터)로 변환한 결과 혹은 일련 과정을 의미한다.
임베딩의 역할은 (1) 단어 및 문장 간 관련성 계산과 (2) 의미적/문법적 정보 함축이다.
임베딩은 방법에 따라 희소 표현 기반 임베딩, 횟수 기반 임베딩, 예측 기반 임베딩, 횟수/예측 기반 임베딩으로 분류할 수 있다.
1. 희소 표현 기반 임베딩
희소 표현(sparse representation) 기반 임베딩은 대부분 값이 0으로 채워진 경우로, 대표적으로 one-hot encoding이 있다.
One-hot Encoding
one-hot encoding이란, 주어진 텍스트를 vector로 변호나해 주는 것이다. 즉, N개의 단어를 각 N차원의 벡터로 표현하는 방식으로, 단어가 포함된 위치에 1을, 나머지에 0을 채운다.
그러나, 이러한 인코딩 방식에는 큰 단점이 있다.
첫째, one-hot vector들은 하나의 요소만 1값을 갖고 나머지는 모두 0인 sparse vector를 갖는다. 이 때, 두 단어에 대한 vector의 inner product(내적)을 구해 보면, 0값을 갖게 되어 직교(orthogonal)를 이룬다. 즉, 단어끼리 관계성이 없는 독립적인 관계가 된다.
둘째, 차원의 저주(curse of dimensionality) 문제가 발생한다. corpus의 수 만큼 차원이 증가하기 때문이다.
2. 횟수 기반 임베딩
횟수 기반 임베딩은 단어의 출현 빈도를 고려하여 임베딩하는 방법이다. 대표젹으로 CounterVector와 TF-IDF가 있다.
Counter Vector
Counter Vector는 문서 집합에서 단어를 토큰으로 생성하고, 각 단어의 출현 빈도수를 이용하여 인코딩해서 벡터를 만드는 방법이다. 즉, 토크나이징과 벡터화가 동시에 가능한 방법이다.
Counter Vector는 sklearn의CountVectorizer()에서 구현이 가능하다.
- 예제 코드
from sklearn.feature_extraction.text import CountVectorizer
corpus = ["When I'm away from you, I miss your touch (ooh)",
"You're the reason I believe in love",
"It's been difficult for me to trust (ooh)",
"And I'm afraid that I'ma fuck it up",
"Ain't no way that I can leave you stranded",
"'Cause you ain't never left me empty-handed",
"And you know that I know that I can't live without you"]
vectorizer = CountVectorizer()
vectorizer.fit(corpus)
vectorizer.vocabulary_
TF-IDF
TF-IDF는 정보 검색론(Information Retrival)에서 가중치를 구할 때 사용되는 알고리즘이다.
TF(Term Frequency)(단어 빈도)는 문서 내 특정 단어가 출현한 빈도를 뜻한다.
혹은,
*t는 term(단어), d는 document(문서 한개)
DF(Document Freuency)(문서 빈도)는 한 단어가 전체 문서에서 얼마나 공통적으로 많이 등장하는지 나타내는 값이다. 즉, 특정 단어가 나타난 문서 개수이다.
특정 단어 t가 모든 문서에 등장하는 일반적인 단어(a, the 등)라면 TF-IDF 가중치를 낮추어야 한다. 따라서 DF 값이 클수록 TF-IDF 가중치 값을 낮추기 위해 DF 값에 역수를 취하는데, 이 값이
IDF(Inverse Document Frequency)(역문서 빈도)이다. 역수를 취하면 전체 문서 개수가 많아질수록 IDF 값도 커지므로, IDF에는 로그를 취한다.
이 때 전체 문서에 특정 단어가 0이라면 분모가 0이 되는 상황이 발생한다. 이를 방지하기 위해 분모에 1을 더해 주는 것을
스무딩(smoothing)이라 한다.
- 예제 코드
# TF-IDF 적용하기
from sklearn.feature_extraction.text import TfidfVectorizer
doc = ['I love Choonsik', 'who love cats?', 'Choonsik is a cat', 'Cats are so lovely']
tfidf_vectorizer = TfidfVectorizer(min_df=1)
tfidf_matrix = tfidf_vectorizer.fit_transform(doc)
doc_dist = (tfidf_matrix * tfidf_matrix.T)
print(f'유사도 행렬 {doc_dist.get_shape()[0]} x {doc_dist.get_shape()[1]}:')
print(doc_dist.toarray())
특정 문서 내 단어의 출현 빈도가 높거나, 전체 문서에서 특정 단어가 포함된 문서가 적을수록 TF-IDF 값이 높다. 따라서, 이 값을 활용하면 문서에 나타나는 흔한 단어(a, the 등)를 걸러 내거나 특정 단어의 중요도를 찾을 수 있다.
3. 예측 기반 임베딩
예측 기반 임베딩은 신경망 구조 혹은 모델을 이용하여 특정 문맥에서 어떤 단어가 나올지 예측하면서 단어를 벡터로 만드는 방식이다.
Word2Vec
Word2Vec(워드투벡터)는 신경망 알고리즘으로, 주어진 텍스트에서 텍스트의 각 단어마다 하나씩 일련의 벡터를 출력한다.
Word2Vec의 출력 벡터가 2차원 그래프에 표시될 때, 의미론적으로 유사한 단어의 벡터는 서로 가깝게 표현된다. 이 때 “서로 가깝다”는 의미는 코사인 유사도를 이용하여 단어 간 거리를 측정한 결과로 나타나는 관계성을 의미한다. 즉, Word2Vec를 이용하면 특정 단어 동의어를 찾을 수 있다.
Word2Vec은 다음과 같은 과정으로 수행된다.
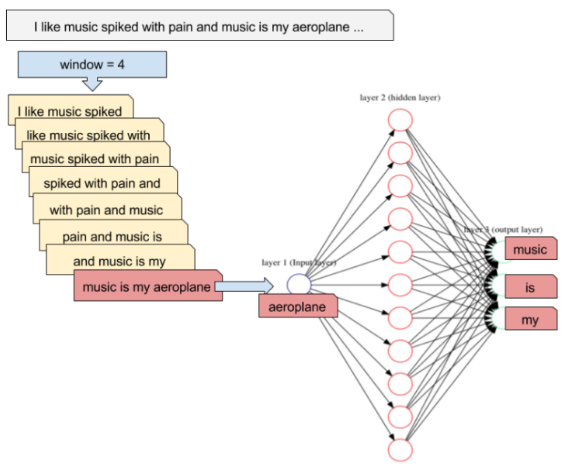
1) 텍스트를 일정 크기 윈도우(window)로 분할하여 신경망 입력으로 사용한다.
2) 분할된 텍스트를 한 쌍의 word와 context로 네트워크에 공급한다.
3) 네트워크 은닉층에는 각 단어에 대한 가중치를 포함한다.
- 예제 코드
- 코퍼스 토큰화 적용
from nltk.tokenize import sent_tokenize, word_tokenize
import warnings
warnings.filterwarnings('ignore')
import gensim
from gensim.models import Word2Vec
sample = open('../080289-main/chap10/data/peter.txt', 'r', encoding='utf-8')
s = sample.read()
f = s.replace('\n', ' ')
data = []
for i in sent_tokenize(f) :
temp = []
for j in word_tokenize(i) :
temp.append(j.lower())
data.append(temp)
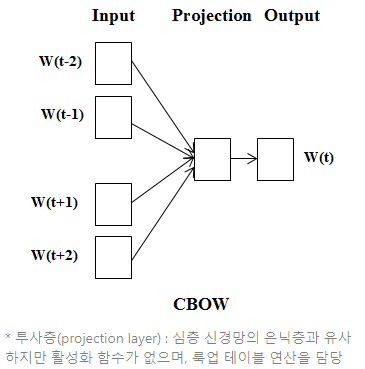
CBOW(Continuous Bag Of Words)
CBOW는 단어를 여러 개 나열한 후 관련 단어를 추정하는 방식이다. 문장에서 등장하는 n개의 단어 열에서 다음으로 등장할 단어를 예측한다.
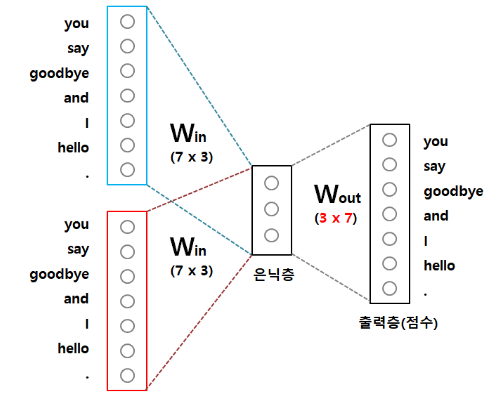
CBOW는 그림과 같은 신경망 구조를 갖고, 각 문맥 단어를 은닉층으로부터 투사하는 가중치 행렬은 모든 단어에서 공통으로 사용된다.
CBOW 신경망에서 크기가 인 은닉층을 가지고 있을 때, 은닉층 크기 은 입력 텍스트를 임베딩한 벡터 크기이다. 입력층과 은닉층 사이 가중치 는 행렬이며, 은닉층에서 출력층 사이 가중치 는 행렬이다. 여기서 는 단어 집합 크기를 의미한다.
- 예제 코드
- CBOW 적용 후 단어 유사도 확인
# 데이터셋에 CBOW 적용
model = gensim.models.Word2Vec(data, min_count=1,
size=100, window=5, sg=0)
# min_count : 단어 최소 빈도수 제한, size : 임베딩 벡터 차원,
# window : 컨텍스트 윈도우 크기, sg : 0(CBOW,default), 1(skip-gram)
print('[CBOW]Cosine similarity :', model.wv.similarity('leaving', 'went'))
print('[CBOW]Cosine similarity :', model.wv.similarity('dinner', 'party'))
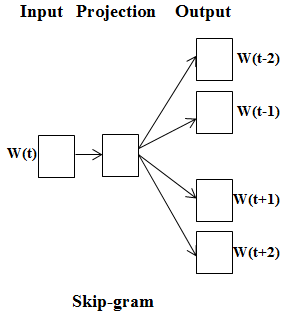
Skip-gram
skip-gram 방식은 CBOW 방식과 반대로 특정 단어에서 문맥이 될 수 있는 단어를 예측한다. 즉, 중심 단어에서 주변 단어를 예측하는 방식을 사용한다. 보통 입력 단어 주변의 개를 문맥으로 보고 예측 모형을 만들며, 이 값을 윈도우 크기라 한다.
- 예제 코드
- Skip-gram 적용 후 단어 유사도 확인
# 데이터셋에 skip-gram 적용
model = gensim.models.Word2Vec(data, min_count=1,
size=100,window=5,sg=1)
print('[skip-gram]Cosine similarity :', model.wv.similarity('leaving', 'went'))
print('[skip-gram]Cosine similarity :', model.wv.similarity('dinner', 'party'))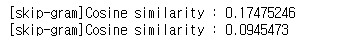
FastText
Word2Vec 단점을 보완하고자 페이스북에서 개발한 임베딩 알고리즘이다. 기존 Word2Vec의 워드 임베딩 방식은 분산 표현(distributed representation)을 이용해 단어의 분산 분포가 유사한 단어에 비슷한 벡터 값을 할당하여 표현한다. 따라서 Word2Vec은 사전에 없는 단어에 대한 벡터 값은 얻을 수 없다. 또한, 자주 사용되지 않는 단어에 대한 학습이 불안정하다.
FastText는 이러한 단점을 보완하고자 개발된
word representation방법을 사용한다. FastText는 노이즈에 강하며, 새로운 단어에 대해 형태적 유사성을 고려한 벡터값을 얻기 때문에 많이 사용되는 알고리즘이다.
- 사전에 없는 단어에 벡터 값을 부여하는 방법
주어진 문서의 각 단어를
n-gram으로 표현한다. 이 때 n의 설정에 따라 단어 분리 수준이 결정된다. 예를 들어 n=3이면 “This is Deep Learning Book” 문장을 “This is Deep”, “is Deep Learning”, “Deep Learning Book”으로 분리한 후 임베딩한다.FastText는 인공 신경망을 이용하여 학습이 완료된 후 데이터셋의 모든 단어를 각 n-gram에 대해 임베딩한다. 따라서 사전에 없는 단어가 등장하면 n-gram으로 분리된 부분 단어와 유사도를 계산하여 의미를 유추할 수 있다.
- 자주 사용되지 않는 단어에 학습 안정성을 확보하는 방법
Word2Vec은 단어의 출현 빈도가 적으면 임베딩의 정확도가 낮다는 단점이 있다. 참고할 수 있는 경우의 수가 적기 때문에 상대적으로 정확도가 낮아 임베딩되지 않는다. 그러나 FastText은 등장 빈도수가 적더라도 n-gram으로 임베딩하기 때문에 참고할 수 있는 경우의 수가 많다. 따라서 상대적으로 자주 사용되지 않는 단어도 정확도가 높다.
- 예제 코드
- FastText로 단어 유사도 구하기
from gensim.test.utils import common_texts
from gensim.models import FastText
model = FastText('../080289-main/chap10/data/peter.txt',
size=4, window=3, min_count=1, iter=10)
sim_score = model.wv.similarity('leaving', 'went')
print(sim_score)
sim_score = model.wv.similarity('dinner','party')
print(sim_score)
- 사전 훈련된 FastText 모델 사용하기
# pre-trained fastText
from __future__ import print_function
from gensim.models import KeyedVectors
model_kr = KeyedVectors.load_word2vec_format('./wiki.ko.vec')
find_similar_to = '노력'
for similar_word in model_kr.similar_by_word(find_similar_to) :
print(f'Word : {similar_word[0]}, Similarity : {similar_word[1]:.2f}')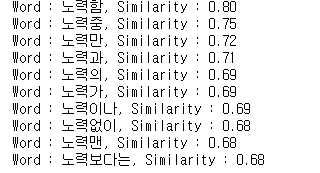
# positive / negative
similarities = model_kr.most_similar(positive=['동물', '육식'], negative=['사람'])
print(similarities)
4. 횟수/예측 기반 임베딩
횟수 기반, 예측 기반 임베딩의 단점을 보완하기 위한 임베딩 기법이다. 대표적으로 GloVe가 있다.
GloVe
Glove(글로브)는 횟수 기반의 LSA(latent semantic Analysis, 잠재 의미 분석)와 예측 기반의 Word2Vec 단점을 보완하기 위한 모델이다. Glove는 그 이름에서 유추할 수 있듯 단어에 대한 글로벌 동시 발생 확률(global co-occurrence statistics) 정보를 포함하는 단어 임베딩 방법이다. 즉, 단어에 대한 통계 정보와 skip-gram을 합친 방식이라고 할 수 있다.
- 예제 코드
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('ggplot')
from sklearn.decomposition import PCA
from gensim.test.utils import datapath, get_tmpfile
from gensim.models import KeyedVectors
from gensim.scripts.glove2word2vec import glove2word2vec
glove_file = datapath('D:\\python\\self_study\\pyTorch\\NLP\\glove.6B\\glove.6B.100d.txt')
word2vec_glove_file = get_tmpfile('glove.6B.100d.txt')
glove2word2vec(glove_file, word2vec_glove_file)# 유사한 단어 리스트 반환
model = KeyedVectors.load_word2vec_format(word2vec_glove_file)
model.most_similar('bill')
model.most_similar(negative=['simple']) # 관련 없는 단어
model.most_similar(positive=['forest', 'tree'], negative=['city'])
model.doesnt_match(['true', 'sincere', 'honest', 'conscience', 'lie']) # 리스트 중 유사도 가장 낮은단어 반환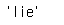
📚 reference
- (길벗) 딥러닝 파이토치 교과서 / 서지영 지음
- github
