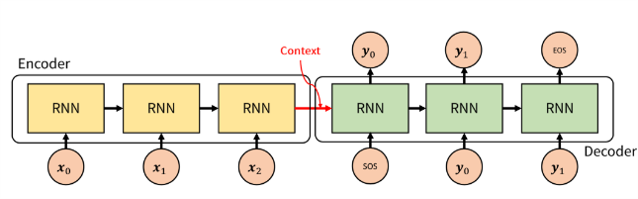
seq2seq
seq2seq(sequence to sequence)는 입력 시퀀스(input sequence)에 대한 출력 시퀀스(output sequence)를 만들기 위한 모델이다. seq2seq는 번역에 초점을 둔 모델로, 입력 시퀀스 과 의미가 동일한 출력 시퀀스 을 만드는 것이며, , 간 관계는 중요하지 않다. 그리고 각 시퀀스의 길이도 다를 수 있다.
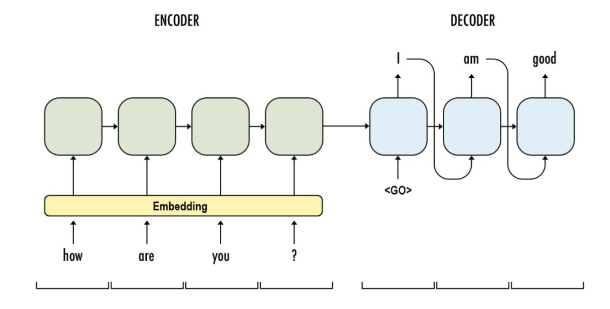
seq2seq 구현하기
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
import pandas as pd
import os
import re
import random
device =torch.device('cuda' if torch.cuda.is_available() else 'cpu')SOS_token = 0
EOS_token = 1
MAX_LENGTH = 20
class Lang:
def __init__(self):
self.word2index = {}
self.word2count = {}
self.index2word = {0: "SOS", 1: "EOS"}
# SOS - 문장의 시작, EOS - 문장의 끝
self.n_words = 2 # sos, eos 카운트
def addSentence(self, sentence): # 문장을 단어 단위로 분리, 컨테이너에 추가
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1
# 데이터 정규화
def normalizeString(df, lang) :
sentence = df[lang].str.lower() # 소문자 전환
sentence = sentence.str.replace('[^A-Za-z\s]+', ' ')
sentence = sentence.str.normalize('NFD') # 유니코드 정규화
sentence = sentence.str.encode('ascii', errors='ignore').str.decode('utf-8')
return sentence
def read_sentence(df, lang1, lang2) :
sentence1 = normalizeString(df, lang1) # 데이터셋 1번째 열
sentence2 = normalizeString(df, lang2)
return sentence1, sentence2
def read_file(loc, lang1, lang2) :
df = pd.read_csv(loc, delimiter='\t', header=None, names=[lang1, lang2])
return df
def process_data(lang1, lang2) :
df = read_file('../080289-main/chap10/data/%s-%s.txt'%(lang1, lang2), lang1, lang2) # load data
sentence1, sentence2 = read_sentence(df, lang1, lang2)
input_lang = Lang()
output_lang = Lang()
pairs = []
for i in range(len(df)):
if len(sentence1[i].split(' ')) < MAX_LENGTH and len(sentence2[i].split(' ')) < MAX_LENGTH:
full = [sentence1[i], sentence2[i]] # 1, 2열 합쳐서 저장
input_lang.addSentence(sentence1[i]) # input으로 영어 사용
output_lang.addSentence(sentence2[i]) # output으로 프랑스어 사용
pairs.append(full) # 입, 출력 합쳐서 사용
return input_lang, output_lang, pairs데이터를 불러와 정규화한다.
# Tensor로 변환
def indexesFromSentence(lang, sentence): # 문장 분리 및 인덱스 반환
return [lang.word2index[word] for word in sentence.split(' ')]
def tensorFromSentence(lang, sentence): # 문장 끝에 토큰 추가
indexes = indexesFromSentence(lang, sentence)
indexes.append(EOS_token)
return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1)
def tensorsFromPair(input_lang, output_lang, pair): # 입출력문장 텐서로 변환
input_tensor = tensorFromSentence(input_lang, pair[0])
target_tensor = tensorFromSentence(output_lang, pair[1])
return (input_tensor, target_tensor)불러온 데이터를 텐서로 변환한다.
# 인코더 네트워크
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, embbed_dim, num_layers):
super(Encoder, self).__init__()
self.input_dim = input_dim # 인코더 입력층
self.embbed_dim = embbed_dim # 인코더 임베딩 계층
self.hidden_dim = hidden_dim # 인코더 은닉층(이전 은닉층)
self.num_layers = num_layers # GRU 계층 개수
self.embedding = nn.Embedding(input_dim, self.embbed_dim) # 임베딩 계층 초기화
self.gru = nn.GRU(self.embbed_dim, self.hidden_dim, num_layers=self.num_layers)
# 임베딩 차원, 은닉층 차원, gru 계층 개수를 이용하여 gru 계층 초기화
def forward(self, src):
embedded = self.embedding(src).view(1,1,-1) # 임베딩
outputs, hidden = self.gru(embedded) # 임베딩 결과를 GRU 모델에 적용
return outputs, hidden인코더 네트워크를 정의한다.
# 디코더 네트워크
class Decoder(nn.Module):
def __init__(self, output_dim, hidden_dim, embbed_dim, num_layers):
super(Decoder, self).__init__()
self.embbed_dim = embbed_dim
self.hidden_dim = hidden_dim
self.output_dim = output_dim
self.num_layers = num_layers
self.embedding = nn.Embedding(output_dim, self.embbed_dim) # 임베딩 초기화
self.gru = nn.GRU(self.embbed_dim, self.hidden_dim, num_layers=self.num_layers) # gru 초기화
self.out = nn.Linear(self.hidden_dim, output_dim) # 선형 계층 초기화
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
input = input.view(1, -1)
embedded = F.relu(self.embedding(input))
output, hidden = self.gru(embedded, hidden)
prediction = self.softmax(self.out(output[0]))
return prediction, hidden 디코더 네트워크를 정의한다. logSoftmax는 소프트맥스와 log 함수의 결합으로, 소프트맥스 활성화 함수에서 발생할 수 있는 기울기 소멸 문제를 방지하기 위해 만들어진 활성화 함수이다.
# Seq2seq 네트워크
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device, MAX_LENGTH=MAX_LENGTH):
super().__init__()
# 인코더와 디코더 초기화
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, input_lang, output_lang, teacher_forcing_ratio=0.5):
input_length = input_lang.size(0) # 입력 문장 길이(문장 단어수)
batch_size = output_lang.shape[1]
target_length = output_lang.shape[0]
vocab_size = self.decoder.output_dim
outputs = torch.zeros(target_length, batch_size, vocab_size).to(self.device)
for i in range(input_length):
# 문장의 모든 단어 인코딩
encoder_output, encoder_hidden = self.encoder(input_lang[i])
# 인코더 은닉층 -> 디코더 은닉층
decoder_hidden = encoder_hidden.to(device)
# 예측 단어 앞에 SOS token 추가
decoder_input = torch.tensor([SOS_token], device=device)
for t in range(target_length):
# 현재 단어에서 출력단어 예측
decoder_output, decoder_hidden = self.decoder(decoder_input, decoder_hidden)
outputs[t] = decoder_output
teacher_force = random.random() < teacher_forcing_ratio
topv, topi = decoder_output.topk(1)
# teacher force 활성화하면 모표를 다음 입력으로 사용
input = (output_lang[t] if teacher_force else topi)
# teacher force 활성화하지 않으면 자체 예측 값을 다음 입력으로 사용
if (teacher_force == False and input.item() == EOS_token) :
break
return outputs
# teacher_force : seq2seq에서 많이 사용되는 기법. 번역(예측)하려는 목표 단어를 디코더의 다음 입력으로 넣어줌Seq2Seq 네트워크를 정의한다.
teacher_force는 seq2seq 모델에서 많이 사용되는 기법으로, 번역(예측)하려는 목표 단어를 디코더의 다음 입력으로 넣어 주는 기법이다.
티쳐 포스를 사용하면 학습 초기 안정적인 훈련이 가능하며, 기울기를 계산할 때 빠른 수렴이 가능하다는 장점이 있지만, 네트워크가 불안정해질 수 있다.
# 모델의 오차 계산 함수 정의
teacher_forcing_ratio = 0.5
def Model(model, input_tensor, target_tensor, model_optimizer, criterion):
model_optimizer.zero_grad()
input_length = input_tensor.size(0)
loss = 0
epoch_loss = 0
output = model(input_tensor, target_tensor)
num_iter = output.size(0)
for ot in range(num_iter):
loss += criterion(output[ot], target_tensor[ot])
loss.backward()
model_optimizer.step()
epoch_loss = loss.item() / num_iter
return epoch_loss# 모델 훈련함수 정의
def trainModel(model, input_lang, output_lang, pairs, num_iteration=20000):
model.train()
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.NLLLoss()
total_loss_iterations = 0
training_pairs = [tensorsFromPair(input_lang, output_lang, random.choice(pairs))
for i in range(num_iteration)]
for iter in range(1, num_iteration+1):
training_pair = training_pairs[iter - 1]
input_tensor = training_pair[0]
target_tensor = training_pair[1]
loss = Model(model, input_tensor, target_tensor, optimizer, criterion)
total_loss_iterations += loss
if iter % 5000 == 0:
average_loss= total_loss_iterations / 5000
total_loss_iterations = 0
print('%d %.4f' % (iter, average_loss))
torch.save(model.state_dict(), './mytraining.pt')
return model모델 훈련 함수와 옵티마이저, 손실 함수를 정의한다.
# 모델 평가
def evaluate(model, input_lang, output_lang, sentences, max_length=MAX_LENGTH):
with torch.no_grad():
input_tensor = tensorFromSentence(input_lang, sentences[0])
output_tensor = tensorFromSentence(output_lang, sentences[1])
decoded_words = []
output = model(input_tensor, output_tensor)
for ot in range(output.size(0)):
topv, topi = output[ot].topk(1)
if topi[0].item() == EOS_token:
decoded_words.append('<EOS>')
break
else:
decoded_words.append(output_lang.index2word[topi[0].item()])
return decoded_words
def evaluateRandomly(model, input_lang, output_lang, pairs, n=10):
for i in range(n):
pair = random.choice(pairs)
print('input {}'.format(pair[0]))
print('output {}'.format(pair[1]))
output_words = evaluate(model, input_lang, output_lang, pair)
output_sentence = ' '.join(output_words)
print('predicted {}'.format(output_sentence))모델 평가함수를 정의한다.
lang1 = 'eng'
lang2 = 'fra'
input_lang, output_lang, pairs = process_data(lang1, lang2)
randomize = random.choice(pairs)
print('random sentence {}'.format(randomize))
input_size = input_lang.n_words
output_size = output_lang.n_words
print('Input : {} Output : {}'.format(input_size, output_size))
embed_size = 256
hidden_size = 512
num_layers = 1
num_iteration = 75000
encoder = Encoder(input_size, hidden_size, embed_size, num_layers)
decoder = Decoder(output_size, hidden_size, embed_size, num_layers)
model = Seq2Seq(encoder, decoder, device).to(device)
print(encoder)
print(decoder)
model = trainModel(model, input_lang, output_lang, pairs, num_iteration)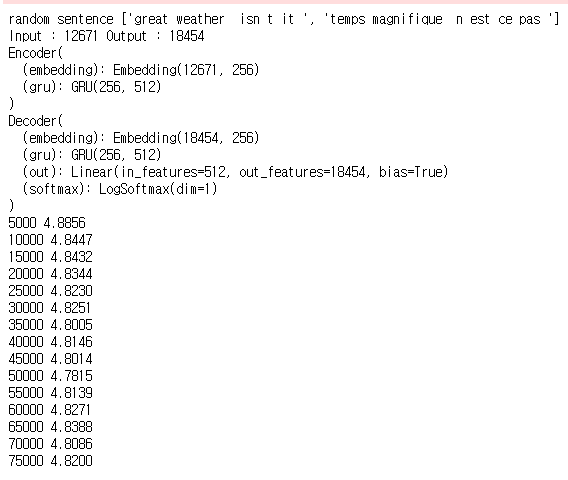
모델을 훈련시킨다.
evaluateRandomly(model, input_lang, output_lang, pairs)
랜덤 예측 결과를 출력해 보자.
seq2seq는 이렇게 인코더와 디코더 네트워크를 사용한다. 그러나, 일반적인 seq2seq 모델은 입력 문장이 긴 시퀀스이면 정확한 처리가 어렵다. 인코더에서 사용하는 RNN의 마지막 은닉 상태만 디코더로 전달되기 때문이다. 이에 따라 정보의 손실이 발생하고, RNN의 기울기 소멸 문제가 발생할 수 있다는 한계점이 있다. 이를 극복하기 위해 등장한 것이 바로 attention mechanism(어텐션 메커니즘)이다.
이어진 포스팅에서는 어텐션 메커니즘을 적용하여 어텐션 디코더 모델을 훈련시켜 보겠다.
📚 reference
- (길벗) 딥러닝 파이토치 교과서 / 서지영 지음
- github
