지난번 포스팅에 이어서 양방향 LSTM, GRU 모델로 주가를 예측해 보려고 한다.
그런데 파이토치를 곁들인....
이번 주가예측은 레퍼런스 교재의 스타벅스 주가 데이터를 사용한다. 예측 진행 방식(전처리 등)은 pytorch 시리즈의 LSTM, GRU 진행방식과 동일하다.
양방향 RNN 구조
양방향 RNN은 하나의 출력값을 예측하는 데 메모리 셀 2개를 사용한다. 첫 번째 메모리 셀은 이전 시점 은닉 상태(forward states)를 전달받아 현재 은닉 상태를 계산한다. 두 번째 메모리 셀은 다음 시점의 은닉 상태(backward states)를 전달받아 현재의 은닉 상태를 계산한다. 그리고 이 두 개의 값을 모두 출력층에서 출력 값 예측에 사용한다.
bi-directional LSTM
import os
import time
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
from torch.autograd import Variable
from tqdm import tqdm_notebook
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')data = pd.read_csv('../080289-main/chap07/data/SBUX.csv')
data.dtypesdata['Date'] = pd.to_datetime(data['Date'])
data.set_index('Date', inplace=True)data['Volume'] = data['Volume'].astype(float)
X=data.iloc[:,:-1]
y=data.iloc[:,5:6]
print(X)
print(y)from sklearn.preprocessing import StandardScaler, MinMaxScaler
ms = MinMaxScaler()
ss = StandardScaler()
X_ss = ss.fit_transform(X)
y_ms = ms.fit_transform(y)
X_train = X_ss[:200, :]
X_test = X_ss[200:, :]
y_train = y_ms[:200, :]
y_test = y_ms[200:, :]
print("Training Shape", X_train.shape, y_train.shape)
print("Testing Shape", X_test.shape, y_test.shape) X_train_tensors = Variable(torch.Tensor(X_train))
X_test_tensors = Variable(torch.Tensor(X_test))
y_train_tensors = Variable(torch.Tensor(y_train))
y_test_tensors = Variable(torch.Tensor(y_test))
X_train_tensors_f = torch.reshape(X_train_tensors, (X_train_tensors.shape[0], 1, X_train_tensors.shape[1]))
X_test_tensors_f = torch.reshape(X_test_tensors, (X_test_tensors.shape[0], 1, X_test_tensors.shape[1]))
print("Training Shape", X_train_tensors_f.shape, y_train_tensors.shape)
print("Testing Shape", X_test_tensors_f.shape, y_test_tensors.shape) class biLSTM(nn.Module):
def __init__(self, num_classes, input_size, hidden_size, num_layers, seq_length):
super(biLSTM, self).__init__()
self.num_classes = num_classes
self.num_layers = num_layers
self.input_size = input_size
self.hidden_size = hidden_size
self.seq_length = seq_length
self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size,
num_layers=num_layers, bidirectional=True, batch_first=True)
self.fc = nn.Linear(hidden_size*2, num_classes)
self.relu = nn.ReLU()
def forward(self,x):
h_0 = Variable(torch.zeros(self.num_layers*2, x.size(0), self.hidden_size))
c_0 = Variable(torch.zeros(self.num_layers*2, x.size(0), self.hidden_size))
out, _ = self.lstm(x, (h_0, c_0))
out = self.fc(out[:, -1, :])
out = self.relu(out)
return out모델 네트워크 정의 시,
bidirectional=True옵션을 사용하면 양방향 LSTM을 사용할 수 있다.
bi-directional LSTM의 차이점(LSTM과 비교)은 입력 데이터가 전방향, 역방향 학습에 모두 전달되며 그 결과도 모두 출력에 반영된다는 것이다.
즉, 한 번 학습하는 데 두 개의 계층이 필요하기 때문에 LSTM과 다르게 은닉 상태, 셀 상태에 2를 곱하고 마지막 출력층에도 2를 곱해야 한다. (num_layers*2)
num_epochs = 1000
learning_rate = 0.0001
input_size = 5
hidden_size = 2
num_layers = 1
num_classes = 1
model = biLSTM(num_classes, input_size, hidden_size, num_layers, X_train_tensors_f.shape[1])
criterion = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) for epoch in range(num_epochs):
outputs = model.forward(X_train_tensors_f)
optimizer.zero_grad()
loss = criterion(outputs, y_train_tensors)
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print("Epoch: %d, loss: %1.5f" % (epoch, loss.item())) df_x_ss = ss.transform(data.iloc[:, :-1])
df_y_ms = ms.transform(data.iloc[:, -1:])
df_x_ss = Variable(torch.Tensor(df_x_ss))
df_y_ms = Variable(torch.Tensor(df_y_ms))
df_x_ss = torch.reshape(df_x_ss, (df_x_ss.shape[0], 1, df_x_ss.shape[1])) train_predict = model(df_x_ss)
predicted = train_predict.data.numpy()
label_y = df_y_ms.data.numpy()
predicted = ms.inverse_transform(predicted)
label_y = ms.inverse_transform(label_y)
plt.figure(figsize=(10,6))
plt.axvline(x=200, c='r', linestyle='--')
plt.plot(label_y, label='Actual Data')
plt.plot(predicted, label='Predicted Data')
plt.title('Time-Series Prediction')
plt.legend()
plt.show() 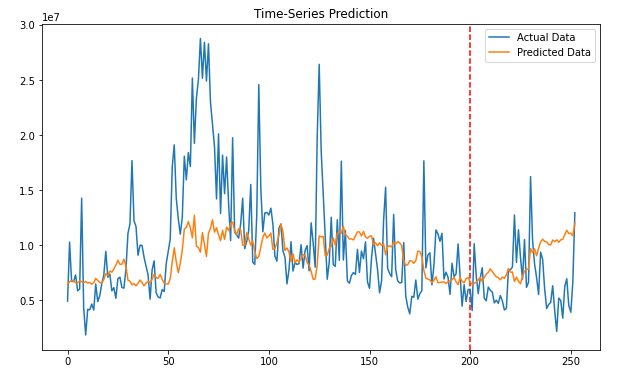
예측 결과를 출력해보면 단일 LSTM보다 괜찮은 예측 결과를 내는 것을 볼 수 있다.
bi-directional GRU
앞 데이터 전처리 과정은 동일하니 생략하고 모델 빌드부터 시작해 보겠다. (biLSTM class 생성 전까지 과정을 되풀이 하면 된다.)
class biGRU(nn.Module) :
def __init__(self, num_classes, input_size, hidden_size, num_layers, seq_length) :
super(biGRU, self).__init__()
self.num_classes = num_classes
self.num_layers = num_layers
self.input_size = input_size
self.hidden_size = hidden_size
self.seq_length = seq_length
self.gru = nn.GRU(input_size=input_size,hidden_size=hidden_size,
num_layers=num_layers, bidirectional=True, batch_first=True) #
self.fc = nn.Linear(hidden_size*2, num_classes) # bidirectional=True, h*2
self.relu = nn.ReLU()
def forward(self, x) :
h_0 = Variable(torch.zeros(self.num_layers * 2, x.size(0), self.hidden_size))
out, _ = self.gru(x, (h_0))
out = self.fc(out[:, -1:, :])
out = self.relu(out)
return out참고 교재에 bi-GRU를 빌드하는 과정은 나와 있지 않아서 bi-LSTM 빌드 과정을 참고하여 빌드했는데,
bi-LSTM과 마찬가지로 gru에bidirectional=True옵션을 부여하고, 은닉 상태와 출력층에 2를 곱했다.
num_epochs = 1000
learning_rate = 0.0001
input_size=5
hidden_size=2
num_layers=1
num_classes=1
model=biGRU(num_classes,input_size,hidden_size,num_layers,X_train_tensors_f.shape[1])
criterion = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)for epoch in range(num_epochs):
outputs = model.forward(X_train_tensors_f)
optimizer.zero_grad()
loss = criterion(outputs, y_train_tensors)
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print("Epoch: %d, loss: %1.5f" % (epoch, loss.item())) 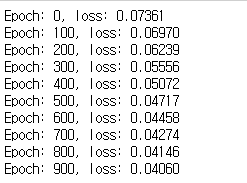
학습 과정도 GRU와 같다.
df_x_ss = ss.transform(data.iloc[:, :-1])
df_y_ms = ms.transform(data.iloc[:, -1:])
df_x_ss = Variable(torch.Tensor(df_x_ss))
df_y_ms = Variable(torch.Tensor(df_y_ms))
df_x_ss = torch.reshape(df_x_ss, (df_x_ss.shape[0], 1, df_x_ss.shape[1]))
train_predict = model(df_x_ss)
predicted = train_predict.data.numpy()
label_y = df_y_ms.data.numpy()
predicted = np.reshape(predicted,(253, 1))
predicted = ms.inverse_transform(predicted)
label_y = ms.inverse_transform(label_y)
plt.figure(figsize=(10,6))
plt.axvline(x=200, c='r', linestyle='--')
plt.plot(label_y, label='Actual Data')
plt.plot(predicted, label='Predicted Data')
plt.title('Time-Series Prediction')
plt.legend()
plt.show() 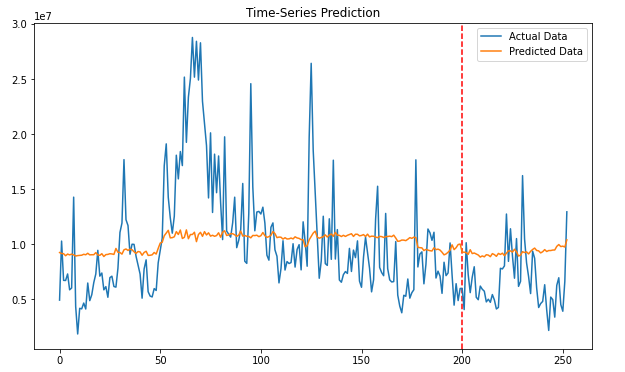
Loss 추이를 봤을 때나 그래프를 보면, 단일 GRU 모델보다 좋은 결과는 아닌 것 같다. 하지만 예제에서 데이터를 랜덤으로 불러와서 실행 시마다 예측 결과가 달라지긴 한다. 여기서는 예제를 따르긴 했지만.. 시계열에서 데이터 랜덤 로드는 좋지 않은 방법 같다.
📚 reference
- (길벗) 딥러닝 파이토치 교과서 / 서지영 지음
- github
