LSTM(Long Short Term Memory)
📖 LSTM
RNN의 기울기 소멸 문제를 극복하기 위해, LSTM과 GRU와 같은 RNN 확장 방식이 많이 사용된다.
- LSTM 순전파
기울기 소멸 문제 해결을 위해 망각 게이트, 입력 게이트, 출력 게이트라는 새로운 요소를 은닉층의 각 뉴런에 추가한다.
- 망각 게이트(forget gate)
망각 게이트는 과거 정보를 어느정도 기억할 지 결정한다. 과거 정보와 현재 데이터를 입력받아 시그모이드를 취한 후, 그 값을 과거 정보에 곱해 준다. 따라서 시그모이드 출력이 0이면 과거 정보를 버리고, 1이면 과거 정보를 온전히 보존한다. 망각 게이트 수식은 다음과 같다.
- 입력 게이트(input gate)
입력 게이트는 현재 정보를 기억한다. 과거 정보와 현제 데이터를 입력받아 시그모이드와 하이퍼볼릭 탄젠트 함수를 기반으로 현 정보에 대한 보존량을 결정한다. 즉, 현 메모리에 새로운 정보를 반영할지 결정하는 역할을 한다. 계산 값이 1이면 입력 가 들어올 수 있도록 허용(open)하고, 계산 값이 0이면 차단한다. 이를 수식으로 정리하면 다음과 같다.
- 셀(cell)
각 단계에 대한 은닉 노드(hidden node)를메모리 셀이라 한다. 총합을 사용하여 셀 값을 반영하며, 이로써 기울기 소멸 문제가 해결된다. 망각 게이트와 입력 게이트의 이전단계 셀 정보를 계산하여 현재 단계 셀 상태를 업데이트한다. 다음은 셀에 대한 수식이다.
- 출력 게이트(output gate)
출력 게이트는 과거 정보와 현 데이터를 사용하여 뉴런의 출력을 결정한다. 이전 은닉 상태와 t번째 입력을 고려해 다음 은닉 상태를 계산한다. 그리고 LSTM에서는 이 은닉 상태가 그 시점에서의 출력이 된다. 출력 게이트는 갱신된 메모리의 출력 값을 제어하는 역할을 한다. 계산한 값이 1이면 의미 있는 결과로 최종 출력하고, 계산한 값이 0이면 해당 연산 출력을 하지 않는다. 이것을 수식으로 정리하면 다음과 같다.
- LSTM 역전파
셀을 통해 역전파를 수행하기 때문에,중단 없는 기울기(uninterrupted gradient flow)라고도 한다. 최종 오차는 모든 노드에 전파되는데, 이 때 셀을 통해 중단 없이 전파된다.
📟 구현
class LSTM(nn.Module):
def __init__(self, num_classes, input_size, hidden_size, num_layers, seq_length):
super(LSTM, self).__init__()
self.num_classes = num_classes # 클래스
self.num_layers = num_layers # LSTM 계층 개수
self.input_size = input_size # 입력 크기(컬럼 개수)
self.hidden_size = hidden_size # 은닉층의 뉴런 개수
self.seq_length = seq_length # 시퀀스 길이
self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size,
num_layers=num_layers, batch_first=True) # lstm 계층
self.fc_1 = nn.Linear(hidden_size, 128) # 완전연결층
self.fc = nn.Linear(128, num_classes) # 출력층
self.relu = nn.ReLU()
def forward(self,x):
h_0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size)) # 은닉상태 초기화
c_0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size)) # 셀 상태 초기화
output, (hn, cn) = self.lstm(x, (h_0, c_0)) # lstm 계층에 은닉 상태와 셀 상태 적용
hn = hn.view(-1, self.hidden_size) # 완전연결층 적용을 위해 데이터 형태를 1차원으로 조정
out = self.relu(hn)
out = self.fc_1(out)
out = self.relu(out)
out = self.fc(out)
return outGRU(Gate Recurrent Unit)
📖 GRU
GRU(게이트 순환 신경망)는 게이트 메커니즘이 적용된 RNN framework의 한 종류이며, LSTM보다 간단한 구조이다. LSTM에서 사용하는 망각 게이트와 입력 게이트를 하나로 합친 것이며, 별도의 업데이트 게이트로 구성되어 있다.
하나의 게이트 컨트롤러(gate controller)가 망각 게이트와 입력 게이트를 모두 제어한다. 게이트 컨트롤러가 1을 출력하면 망각 게이트가 열리고 입력 게이트는 닫히며, 반대로 0을 출력하면 망각 게이트가 닫히고 입력 게이트는 열린다. 즉, 이전 기억이 저장될 때마다 단계별 입력이 삭제된다.
GRU는 출력 게이트가 없어 전체 상태 벡터가 매 단계마다 출력되며, 이전 상태 어느 부분이 출력될 지 제어하는 새로운 게이트 컨트롤러가 별도 존재한다.
- 망각 게이트(reset gate)
망각 게이트는 과거 정보를 적당히 초기화(reset)시키려는 목적으로 시그모이드 함수를 출력으로 이용하여 (0, 1)값을 이전 은닉층에 곱한다. 이전 시점의 은닉층 값에 현 시점의 정보에 대한 가중치를 곱한 것으로 수식은 다음과 같다.
- 업데이트 게이트(update gate)
업데이트 게이트는 과거와 현 정보의 최신화 비율을 결정하는 역할을 한다. 시그모이드로 출력된 결과()는 현시점의 정보량을 결정하고 1에서 뺀 값()을 직전 시점 은닉층 정보와 곱한다. 이를 수식으로 나타내면 다음과 같다.
- 후보군(candidate)
후보군은 현 시점 정보에 대한 후보군을 계산한다. 과거 은닉층 정보를 그대로 이용하지 않고, 망각 게이트의 결과를 이용하여 후보군을 계산한다.
- 은닉층 계산
업데이트 게이트 결과와 후보군 결과를 결합하여 현 시점의 은닉층을 계산한다. 시그모이드 함수 결과는 현 시점에서 결과에 대한 정보량을 결정하고, 1-시그모이드 함수의 결과는 과거의 정보량을 결정한다. 이를 수식으로 나타내면 다음과 같다.
📟 구현
class GRU(nn.Module) :
def __init__(self, num_classes, input_size, hidden_size, num_layers, seq_length) :
super(GRU, self).__init__()
self.num_classes = num_classes
self.num_layers = num_layers
self.input_size = input_size
self.hidden_size = hidden_size
self.seq_length = seq_length
self.gru = nn.GRU(input_size=input_size,hidden_size=hidden_size,
num_layers=num_layers,batch_first=True)
self.fc_1 = nn.Linear(hidden_size, 128)
self.fc = nn.Linear(128, num_classes)
self.relu = nn.ReLU()
def forward(self, x) :
h_0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size))
output, (hn) = self.gru(x, (h_0))
hn = hn.view(-1, self.hidden_size)
out = self.relu(hn)
out = self.fc_1(out)
out = self.relu(out)
out = self.fc(out)
return out📉 주가 예측
분석 대상 : 2022년 1월 1일 ~ 5월 31일 까지의 삼성 주가(종가)
분석 방법 : pytorch에서 LSTM, GRU 모델 적용
import torch
import torch.nn
import torchvision.transforms as transforms
import torchvision.datasets
from torch.autograd import Variable
from torch.nn import Parameter
import torch.nn as nn
from torch import Tensor
import torch.nn.functional as F
from torch.utils.data import DataLoader
import math
import matplotlib.pyplot as plt
from datetime import datetime
import seaborn as sns
plt.style.use('seaborn-whitegrid')
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
cuda = True if torch.cuda.is_available() else False
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
torch.manual_seed(125)
if torch.cuda.is_available() :
torch.cuda.manual_seed_all(125)import yfinance as yf
df = yf.download('005930.KS',
start='2022-01-01',
end='2022-05-31') # 005930 : 삼성전자 주가
df.head()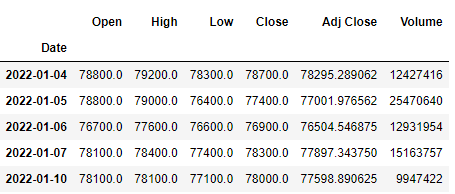
yfinance에서 분석 대상 데이터를 다운받는다.
# data check
fig = df['Close'].plot()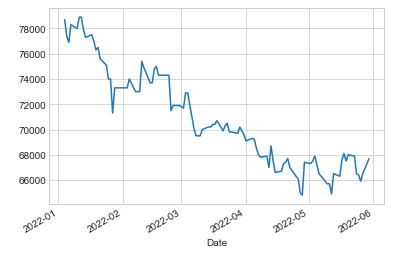
그래프를 그려 종가 추세를 확인해 본다.
X = df.drop('Close', axis=1) # X, y 분리
y = df[['Close']]X, y값을 분리한다.
from sklearn.preprocessing import StandardScaler, MinMaxScaler
ms = MinMaxScaler() # 0 ~ 1
ss = StandardScaler() # 평균 0, 분산 1
X_ss = ss.fit_transform(X)
y_ms = ms.fit_transform(y)
X_train = X_ss[:79, :]
X_test = X_ss[79:, :]
y_train = y_ms[:79, :]
y_test = y_ms[79:, :]
print('Training Shape :', X_train.shape, y_train.shape)
print('Testing Shape :', X_test.shape, y_test.shape)데이터를 정규화한 후 학습, 평가 데이터로 분리한다.
# 데이터셋 형태 및 크기 조정
X_train_tensors = Variable(torch.Tensor(X_train))
X_test_tensors = Variable(torch.Tensor(X_test))
y_train_tensors = Variable(torch.Tensor(y_train))
y_test_tensors = Variable(torch.Tensor(y_test))
X_train_tensors_f = torch.reshape(X_train_tensors,
(X_train_tensors.shape[0], 1, X_train_tensors.shape[1]))
X_test_tensors_f = torch.reshape(X_test_tensors,
(X_test_tensors.shape[0], 1, X_test_tensors.shape[1]))
print('Training Shape :', X_train.shape, y_train.shape)
print('Testing Shape :', X_test.shape, y_test.shape)데이터셋 형태를 tensor 형식으로 변경한다.
1. LSTM model result
class LSTM(nn.Module):
def __init__(self, num_classes, input_size, hidden_size, num_layers, seq_length):
super(LSTM, self).__init__()
self.num_classes = num_classes # 클래스
self.num_layers = num_layers # LSTM 계층 개수
self.input_size = input_size # 입력 크기(컬럼 개수)
self.hidden_size = hidden_size # 은닉층의 뉴런 개수
self.seq_length = seq_length # 시퀀스 길이
self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size,
num_layers=num_layers, batch_first=True) # lstm 계층
self.fc_1 = nn.Linear(hidden_size, 128) # 완전연결층
self.fc = nn.Linear(128, num_classes) # 출력층
self.relu = nn.ReLU()
def forward(self,x):
h_0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size)) # 은닉상태 초기화
c_0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size)) # 셀 상태 초기화
output, (hn, cn) = self.lstm(x, (h_0, c_0)) # lstm 계층에 은닉 상태와 셀 상태 적용
hn = hn.view(-1, self.hidden_size) # 완전연결층 적용을 위해 데이터 형태를 1차원으로 조정
out = self.relu(hn)
out = self.fc_1(out)
out = self.relu(out)
out = self.fc(out)
return out모델을 정의한다.
num_epochs = 1000
lr = 0.0001
input_size=4 # 칼럼 개수
hidden_size=2 # 은닉층 유닛 개수
num_layers=1 # LSTM 계층 개수
num_classes=1 # 클래스 개수
model = LSTM(num_classes, input_size, hidden_size, num_layers, X_train_tensors_f.shape[1])
criterion = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)하이퍼파라미터를 정의한다.
for epoch in range(num_epochs) :
outputs = model.forward(X_train_tensors_f) # 전방향 학습
optimizer.zero_grad()
loss = criterion(outputs, y_train_tensors) # 오차 계싼
loss.backward() # 기울기 계산
optimizer.step() # 오차 업데이트
if epoch % 100 == 0 :
print(f'Epoch : {epoch}, loss : {loss.item():1.5f}')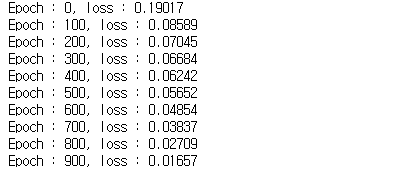
모델 학습을 진행한다.
df_x_ss = ss.transform(X)
df_y_ms = ms.transform(y)
df_x_ss = Variable(torch.Tensor(df_x_ss))
df_y_ms = Variable(torch.Tensor(df_y_ms))
df_x_ss = torch.reshape(df_x_ss, (df_x_ss.shape[0], 1, df_x_ss.shape[1]))결과 출력을 위해 데이터를 변형한다.
train_predict = model(df_x_ss)
predicted = train_predict.data.numpy()
label_y = df_y_ms.data.numpy()
predicted = ms.inverse_transform(predicted)
label_y = ms.inverse_transform(label_y)
plt.figure(figsize=(10, 6))
plt.axvline(x=datetime(2022,5,1), c='r', linestyle='--')
df['pred'] = predicted
plt.plot(df['Close'], label='Actual Data')
plt.plot(df['pred'], label='Predicted Data')
plt.title('Time-series Prediction')
plt.legend()
plt.show()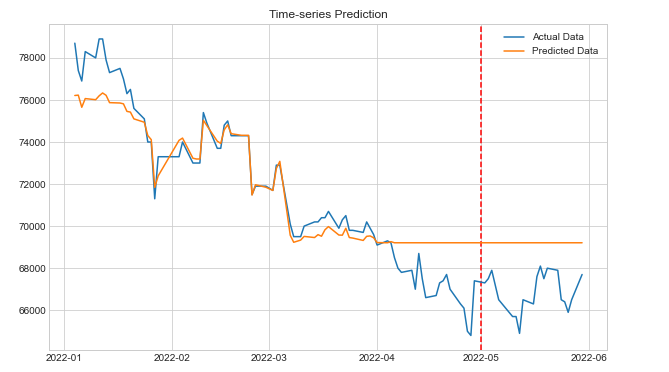
예측 결과를 출력한다.
2. GRU model result
class GRU(nn.Module) :
def __init__(self, num_classes, input_size, hidden_size, num_layers, seq_length) :
super(GRU, self).__init__()
self.num_classes = num_classes
self.num_layers = num_layers
self.input_size = input_size
self.hidden_size = hidden_size
self.seq_length = seq_length
self.gru = nn.GRU(input_size=input_size,hidden_size=hidden_size,
num_layers=num_layers,batch_first=True)
self.fc_1 = nn.Linear(hidden_size, 128)
self.fc = nn.Linear(128, num_classes)
self.relu = nn.ReLU()
def forward(self, x) :
h_0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size))
output, (hn) = self.gru(x, (h_0))
hn = hn.view(-1, self.hidden_size)
out = self.relu(hn)
out = self.fc_1(out)
out = self.relu(out)
out = self.fc(out)
return out모델을 정의한다.
num_epochs = 1000
learning_rate = 0.0001
input_size=4
hidden_size=2
num_layers=1
num_classes=1
model=GRU(num_classes,input_size,hidden_size,num_layers,X_train_tensors_f.shape[1])
criterion = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)하이퍼파라미터를 정의한다.
for epoch in range(num_epochs) :
outputs = model.forward(X_train_tensors_f)
optimizer.zero_grad()
loss = criterion(outputs, y_train_tensors)
loss.backward()
optimizer.step()
if epoch % 100 == 0 :
print(f'Epoch : {epoch}, loss : {loss.item():1.5f}')
모델 학습을 진행한다.
df_x_ss = ss.transform(X)
df_y_ms = ms.transform(y)
df_x_ss = Variable(torch.Tensor(df_x_ss))
df_y_ms = Variable(torch.Tensor(df_y_ms))
df_x_ss = torch.reshape(df_x_ss, (df_x_ss.shape[0], 1, df_x_ss.shape[1]))결과 출력을 위해 데이터를 변형한다.
train_predict = model(df_x_ss)
predicted = train_predict.data.numpy()
label_y = df_y_ms.data.numpy()
predicted = ms.inverse_transform(predicted)
label_y = ms.inverse_transform(label_y)
plt.figure(figsize=(10, 6))
plt.axvline(x=datetime(2022,5,1), c='r', linestyle='--')
df['pred'] = predicted
plt.plot(df['Close'], label='Actual Data')
plt.plot(df['pred'], label='Predicted Data')
plt.title('Time-series Prediction')
plt.legend()
plt.show()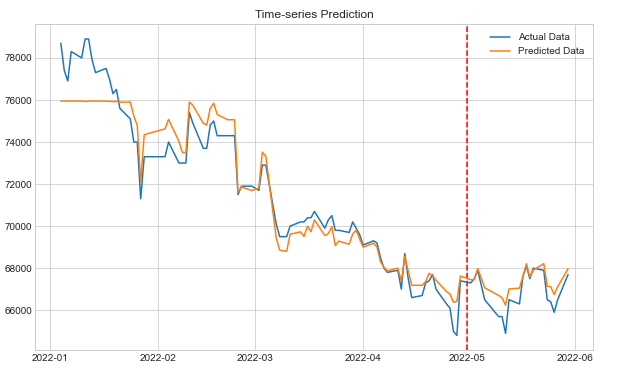
예측 결과를 출력한다.
LSTM과 GRU의 예측 결과를 비교해 보면, GRU의 예측 결과가 훨씬 좋은 것을 알 수 있다. 다음에는 양방향 LSTM 모델도 적용해 보려고 한다.

안녕하세요, 관련 내용을 아주 잘보았습니다!! 다름이 아니라 질문을 드리고싶어서요!!
위의 LSTM, GRU코드 구현 부분은 직접 구현하신건가요 아니면 이미 내포되어있는걸 쓰신건가요???