
▫ OpenPose란?
화상에 포함된 여러 인물을 탐지하여 인체 각 부위 위치를 식별하고, 부위를 연결하는 선(링크)를 구하는 기술
'joint_self' : 목 이외 17개 부위의 x, y 좌표와 해당 부위 시인성 정보 포함
'scale_provided' : 주요 인물을 둘러싼 바운딩 박스 높이가 365pixel의 몇 배인지 나타냄
'joint_others' : 화상 내 다른 인물의 부위 정보 저장✔ openpose를 활용한 자세 추정의 흐름 3단계
- 이미지 크기를 368x368 pixel로 변경하고, 색상 정보 표준화
- 오픈포즈 신경망에 전처리 한 이미지 입력.
출력으로 19x368x368(클래스 수 높이 폭) 배열과 38 368 368 배열이 출력됨. 신체 부위 클래스와 PAFs 클래스에 대응하는 배열임. 배열의 채널 수는 신체 부위는 18개 + 기타 총 19채널, PAFs는 19개 링크 x,y방향의 벡터 좌표를 나타내며 38채널이 됨. 배열에 저장되는 값은 각 픽셀이 각 클래스일 신뢰도(확률)에 대응한 값- 신체 부위의 출력 결과에서 각 부위별 좌표를 정하고, PAFs 정보와 함께 링크를 구함. 화상 크기를 다시 되돌림
▪ 데이터 준비
import json
import os
import os.path as osp
import numpy as np
import cv2
from PIL import Image
from matplotlib import cm
import matplotlib.pyplot as plt
%matplotlib inline
import torch.utils.data as data
from pytorch_advanced.pose_estimation.utils.data_augumentation import *# 파일 경로 리스트 작성
def make_datapath_list(rootpath) :
'''학습 및 검증 이미지 데이터와 어노테이션 데이터, 마스크 데이터의 파일 경로 리스트 작성'''
# 어노테이션의 JSON 파일 읽기
json_path = osp.join(rootpath, 'COCO.json')
with open(json_path) as data_file :
data_this = json.load(data_file)
data_json = data_this['root']
# index 저장
num_samples = len(data_json)
train_indexes = []
val_indexes = []
for count in range(num_samples) :
if data_json[count]['isValidation'] != 0 :
val_indexes.append(count)
else :
train_indexes.append(count)
# 이미지 파일 경로 저장
train_img_list = list()
val_img_list = list()
for idx in train_indexes :
img_path = os.path.join(rootpath, data_json[idx]['img_paths'])
train_img_list.append(img_path)
for idx in val_indexes :
img_path = os.path.join(rootpath, data_json[idx]['img_paths'])
val_img_list.append(img_path)
# 마스크 데이터 경로 지정
train_mask_list = []
val_mask_list = []
for idx in train_indexes :
img_idx = data_json[idx]['img_paths'][-16 : -4]
anno_path = './pytorch_advanced/pose_estimation/data/mask/train2014_' + \
img_idx + '.jpg'
train_mask_list.append(anno_path)
for idx in val_indexes :
img_idx = data_json[idx]['img_paths'][-16 : -4]
anno_path = \
'./pytorch_advanced/pose_estimation/data/mask/val2014/mask_COCO_val2014_' +
img_idx + '.jpg'
val_mask_list.append(anno_path)
# 어노테이션 데이터 저장
train_meta_list = list()
val_meta_list = list()
for idx in train_indexes :
train_meta_list.append(data_json[idx])
for idx in val_indexes :
val_meta_list.append(data_json[idx])
return train_img_list, train_mask_list ,\
val_img_list, val_mask_list, train_meta_list, val_meta_list
# 동작 확인
train_img_list, train_mask_list, val_img_list, \
val_mask_list, train_meta_list, val_meta_list = make_datapath_list(
rootpath='./pytorch_advanced/pose_estimation/data/')
val_meta_list[24]# 마스크 데이터 동작 확인
index = 24
# image
img = cv2.imread(val_img_list[index])
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)
plt.show()
# 마스크
mask_miss = cv2.imread(val_mask_list[index])
mask_miss = cv2.cvtColor(mask_miss, cv2.COLOR_BGR2RGB)
plt.imshow(mask_miss)
plt.show()
# 합성
blend_img = cv2.addWeighted(img, 0.4, mask_miss, 0.6, 0)
plt.imshow(blend_img)
plt.show()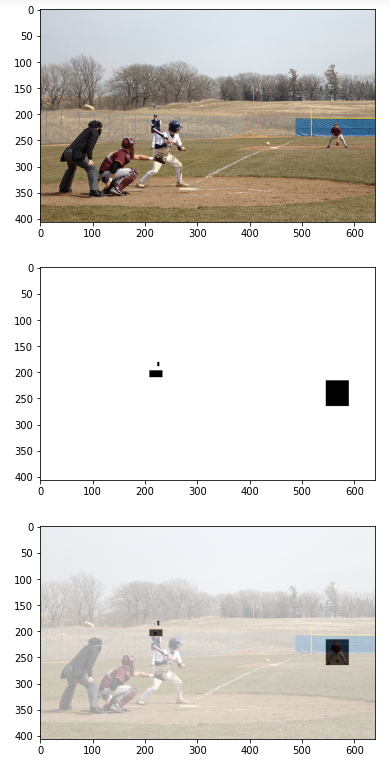
▪ 이미지 전처리 작성
DataTransform
: 화상과 어노테이션 전처리
class DataTransform() :
'''화상과 마스크, 어노테이션의 전처리 클래스
학습, 추론 시 서로 다르게 동작
학습 시에는 데이터 확장 수행'''
def __init__(self) :
self.data_transform = {
'train' : Compose([
get_anno(), # json에서 어노테이션을 사전에 저장
add_neck(), # 어노테이션 데이터 순서 변경 및 목의 어노테이션 데이터 추가
aug_scale(), # 확대 축소
aug_rotate(), # 회전
aug_croppad(), # 자르기
aug_flip(), # 좌우 반전
remove_illegal_joint(), # 화상에서 밀려나온 어노테이션 제거
# Normalize_Tensor() # 색상 정보의 표준화 및 텐서화
no_Normalize_Tensor() # 색상 정보의 표준화 생략
]),
'val' : Compose([
# 검증 생략
])
}
def __call__(self, phase, meta_data, img, mask_miss) :
'''
Parameters
-----------
phase : `train` or `val`
전처리 모드 지정
'''
meta_data, img, mask_miss = self.data_transform[phase] \
(meta_data, img, mask_miss)
return meta_data, img, mask_miss# 동작 확인
# 화상 읽기
index = 24
img = cv2.imread(val_img_list[index])
mask_miss = cv2.imread(val_mask_list[index])
meta_data =val_meta_list[index]
# 화상 전처리
transform = DataTransform()
meta_data ,img, mask_miss = transform('train', meta_data, img, mask_miss)
# 화상 표시
img = img.numpy().transpose((1, 2, 0))
plt.imshow(img)
plt.show()
# 마스크 표시
mask_miss = mask_miss.numpy().transpose((1, 2, 0))
plt.imshow(mask_miss)
plt.show()
# 합성 RGB 정보 갖추기
img = Image.fromarray(np.uint8(img*255))
img = np.asarray(img.convert('RGB'))
mask_miss = Image.fromarray(np.uint8((mask_miss)))
mask_miss = np.asarray(mask_miss.convert('RGB'))
blend_img = cv2.addWeighted(img, 0.4, mask_miss, 0.6, 0)
plt.imshow(blend_img)
plt.show()어노테이션 데이터 작성
: 훈련 데이터 정답 정보로 사용할 어노테이션 데이터 작성
# 이미지 읽기
index = 24
img = cv2.imread(val_img_list[index])
mask_miss = cv2.imread(val_mask_list[index])
meta_data = val_meta_list[index]
# 이미지 전처리
meta_data, img, mask_miss = transform('train', meta_data, img, mask_miss)
img = img.numpy().transpose((1, 2, 0))
mask_miss = mask_miss.numpy().transpose((1, 2, 0))
# 오픈포즈 어노테이션 데이터 생성
heat_mask , heatmaps, paf_mask, pafs = get_ground_truth(meta_data, mask_miss)
# plt.imshow(img)
# plt.show()# 왼쪽 팔꿈치의 히트맵 확인
# 원본 이미지
img = Image.fromarray(np.uint8(img*255))
img = np.asarray(img.convert('RGB'))
# 왼쪽 팔꿈치
heat_map = heatmaps[:, :, 6] # 6은 왼쪽 팔꿈치
heat_map = Image.fromarray(np.uint8(cm.jet(heat_map)*255))
heat_map = np.asarray(heat_map.convert('RGB'))
heat_map = cv2.resize(heat_map, (img.shape[1], img.shape[0]),
interpolation=cv2.INTER_CUBIC)
# 주의 ! 히트맵은 이미지 크기가 1/8 로 되어있어 확대함
# 합성하여 표시
blend_img = cv2.addWeighted(img, 0.5, heat_map, 0.5, 0)
# addWeighted() : brief Calculates the weighted sum of two arrays
plt.imshow(blend_img)
plt.show()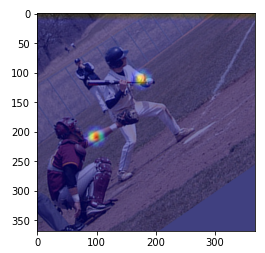
# 왼쪽 손목
heat_map = heatmaps[:, :, 7] # 7 은 왼쪽 손목
heat_map = Image.fromarray(np.uint8(cm.jet(heat_map) * 255))
heat_map = np.asarray(heat_map.convert('RGB'))
heat_map = cv2.resize(heat_map, (img.shape[1], img.shape[0]),
interpolation=cv2.INTER_CUBIC)
# 합성하여 표시
blend_img = cv2.addWeighted(img, 0.5, heat_map, 0.5, 0)
plt.imshow(blend_img)
plt.show()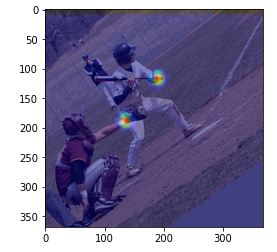
# 왼쪽 팔꿈치와 왼쪽 손목에 PAF 확인
paf = pafs[:, :, 24] # 24는 왼쪽 팔꿈치와 왼쪽 손목을 잇는 x 벡터의 PAF
paf = Image.fromarray(np.uint8((paf)*255))
paf = np.asarray(paf.convert('RGB'))
paf = cv2.resize(paf, (img.shape[1], img.shape[0]), interpolation=cv2.INTER_CUBIC)
# 합성하여 표시
blend_img = cv2.addWeighted(img, 0.3, paf, 0.7, 0)
plt.imshow(blend_img)
plt.show()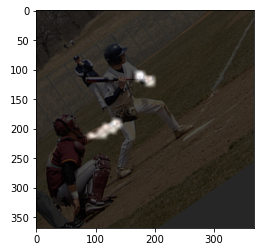
# PAF만 표시
paf = pafs[:, :, 24] # 24는 왼쪽 팔꿈치와 왼쪽 손목을 잇는 x 벡터의 PAF
paf = Image.fromarray(np.uint8((paf)*255))
paf = np.asarray(paf.convert('RGB'))
paf = cv2.resize(paf, (img.shape[1], img.shape[0]), interpolation=cv2.INTER_CUBIC)
plt.imshow(paf)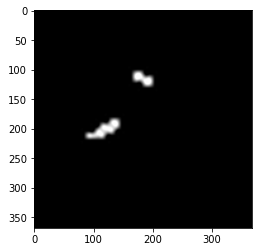
데이터셋 작성
: COCOkeypointDataset
class COCOkeypointsDataset(data.Dataset) :
'''
MSCOCO Cocokeypoints의 데이터셋을 작성하는 클래스. 파이토치 데이터셋 클래스 상속
Attributes
-----------
img_list : 리스트
화상 경로를 저장한 리스트
anno_list : 리스트
어노테이션 경로를 저장한 리스트
phase : `train` or `test`
학습 또는 훈련 설정
transform : object
전처리 클래스의 인스턴스
'''
def __init__(self, img_list, mask_list, meta_list, phase, transform) :
self.img_list = img_list
self.mask_list = mask_list
self.meta_list = meta_list
self.phase = phase
self.transform = transform
def __len__(self) :
'''화상 매수 반환'''
return len(self.img_list)
def __getitem__(self, index) :
img, heatmaps, heat_mask, pafs, paf_mask = self.pull_item(index)
return img, heatmaps, heat_mask, pafs, paf_mask
def pull_item(self, index) :
'''화상의 텐서 형식 데이터, 어노테이션, 마스크 취득'''
# 1. 화상 읽기
image_file_path = self.img_list[index]
img = cv2.imread(image_file_path) # [높이] [폭] [색BGR]
# 2. 마스크와 어노테이션 읽기
mask_miss = cv2.imread(self.mask_list[index])
meta_data = self.meta_list[index]
# 3. 화상 전처리
meta_data, img, mask_miss = self.transform(self.phase, meta_data,
img, mask_miss)
# 4. 정답 어노테이션 데이터 취득
mask_miss_numpy = mask_miss.numpy().transpose((1, 2, 0))
heat_mask, heatmaps, paf_mask, pafs = get_ground_truth(meta_data,
mask_miss_numpy)
# 5. 마스크 데이터는 RGB가 (1, 1, 1) 또는 (0, 0, 0)이므로 차원을 낮춤
# 마스크된 위치는 값이 0, 그렇지 않으면 1
heat_mask = heat_mask[:, :, :, 0]
paf_mask = paf_mask[:, :, :, 0]
# 6. 채널이 맨 끝에 있어 순서 변경
# 예) paf_mask : torch.Size([46, 46, 38])
# --> torch.Size([38, 46, 46])
paf_mask = paf_mask.permute(2, 0, 1)
heat_mask = heat_mask.permute(2, 0, 1)
pafs = pafs.permute(2, 0, 1)
heatmaps = heatmaps.permute(2, 0, 1)
return img, heatmaps, heat_mask, pafs, paf_mask# 동작 확인
train_dataset = COCOkeypointsDataset(val_img_list, val_mask_list,
val_meta_list, phase="train", transform=DataTransform())
val_dataset = COCOkeypointsDataset(val_img_list, val_mask_list,
val_meta_list, phase="val", transform=DataTransform())
# 데이터 꺼내기 예시
item = train_dataset.__getitem__(0)
print(item[0].shape) # img
print(item[1].shape) # heatmaps,
print(item[2].shape) # heat_mask
print(item[3].shape) # pafs
print(item[4].shape) # paf_mask데이터로더 작성
# 데이터 로더
batch_size = 8
train_dataloader = data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_dataloader = data.DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
# 사전형 변수에 정리
dataloaders_dict = {'train' : train_dataloader , 'val' : val_dataloader}
# 동작 확인
batch_iterator = iter(dataloaders_dict['train']) # 반복으로 변환
item = next(batch_iterator) # 첫번째 요소를 꺼낸다
print(item[0].shape) # img
print(item[1].shape) # heatmaps
print(item[2].shape) # heat_mask
print(item[3].shape) # pafs
print(item[4].shape) # paf_mask▪ OpenPose 네트워크 구현
-
총 7개 모듈로 구성
-
Feature: 화상의 특징량 추출VGG-19를 사용하여 출력되는 화상 크기는 1/8이 됨. Feature 모듈의 출력은 128 46 46
-
Stage: 히트맵과 PAFs를 출력 (6개)- stage 1은 Feature 모듈 출력을 2개의 서브 네트워크에 입력(block1_1, block1_2). block1_1은 PAFs를 출력하는 서브 네트워크, 블록 1_2는 히트맵을 출력하는 서브 네트워크. 블록1_1의 출력 텐서 크기는 38 46 46, 블록1_2의 출력 텐서 크기는 19 46 46
- stage 2의 블록 2_1과 2_2에 stage 1의 출력 텐서(185 46 46)를 입력. 2_1과 2_2는 PAFs(38 46 46)와 히트맵(19 46 46)을 출력.
스테이지 6까지 반복 --> 최종 서브 블록 6_1은 PAFs(38 46 46), 6_2는 히트맵(19 46 46)을 출력
import torch
import torch.nn as nn
from torch.nn import init
import torchvision
class OpenPoseNet(nn.Module) :
def __init__(self) :
super(OpenPoseNet, self).__init__()
# Feature 모듈
self.model0 = OpenPose_Feature()
# Stage 모듈
# PAFs 측
self.model1_1 = make_OpenPose_block('block1_1')
self.model2_1 = make_OpenPose_block('block2_1')
self.model3_1 = make_OpenPose_block('block3_1')
self.model4_1 = make_OpenPose_block('block4_1')
self.model5_1 = make_OpenPose_block('block5_1')
self.model6_1 = make_OpenPose_block('block6_1')
# confidence heatmap 측
self.model1_2 = make_OpenPose_block('block1_2')
self.model2_2 = make_OpenPose_block('block2_2')
self.model3_2 = make_OpenPose_block('block3_2')
self.model4_2 = make_OpenPose_block('block4_2')
self.model5_2 = make_OpenPose_block('block5_2')
self.model6_2 = make_OpenPose_block('block6_2')
def forward(self, x) :
''' 순전파 정의 '''
# Feature 모듈
out1 = self.model0(x)
# stage 1
out1_1 = self.model1_1(out1) # PAFs 측
out1_2 = self.model1_2(out1) # confidence heatmap 측
# stage 2
out2 = torch.cat([out1_1, out1_2, out1], 1) # 1차원 채널 결합
out2_1 = self.model2_1(out2)
out2_2 = self.model2_2(out2)
# stage 3
out3 = torch.cat([out2_1, out2_2, out1], 1) # 1차원 채널 결합
out3_1 = self.model3_1(out3)
out3_2 = self.model3_2(out3)
# stage 4
out4 = torch.cat([out3_1, out3_2, out1], 1) # 1차원 채널 결합
out4_1 = self.model4_1(out4)
out4_2 = self.model4_2(out4)
# stage 5
out5 = torch.cat([out4_1, out4_2, out1], 1) # 1차원 채널 결합
out5_1 = self.model5_1(out5)
out5_2 = self.model5_2(out5)
# stage 6
out6 = torch.cat([out5_1, out5_2, out1], 1) # 1차원 채널 결합
out6_1 = self.model6_1(out6)
out6_2 = self.model6_2(out6)
# 손실 계산을 위해 각 스테이지의 결과를 저장
saved_for_loss = []
saved_for_loss.append(out1_1) # PAFs 측
saved_for_loss.append(out1_2) # confidence heatmap 측
saved_for_loss.append(out2_1)
saved_for_loss.append(out2_2)
saved_for_loss.append(out3_1)
saved_for_loss.append(out3_2)
saved_for_loss.append(out4_1)
saved_for_loss.append(out4_2)
saved_for_loss.append(out5_1)
saved_for_loss.append(out5_2)
saved_for_loss.append(out6_1)
saved_for_loss.append(out6_2)
# 최종적 PAFs의 out6_1과 confidence heatmap의 out6_2,
# 손실 계산용으로 각 단계에서 PAFs와 히트맵을 저장한 saved_for_loss를 출력
# out6_1 : torch.Size([minibatch, 38, 46, 46])
# out6_12: torch.Size([minibatch, 19, 46, 46])
# saved_for_loss : [out1_1, out1_2, ..., out6_2]
return (out6_1, out6_2), saved_for_lossFeature 및 Stage 모듈 설명 및 구현
class OpenPose_Feature(nn.Module) :
def __init__(self) :
super(OpenPose_Feature, self).__init__()
# VGG-19 최초 열 개 합성곱 사용
# 처음 실행할 때는 학습된 파라미터를 다운로드하여 실행에 시간이 걸림
vgg19 = torchvision.models.vgg19(pretrained=True)
model = {}
model['block0'] = vgg19.features[:23] # VGG-19 최초 열개의 합성곱 층까지
# 나머지는 새로운 합성곱 층을 두개 준비
model['block0'].add_module('23', torch.nn.Conv2d(512, 256,
kernel_size=3, stride=1, padding=1))
model['block0'].add_module('24', torch.nn.ReLU(inplace=True))
model['block0'].add_module('25', torch.nn.Conv2d(256, 128,
kernel_size=3, stride=1, padding=1))
model['block0'].add_module('26', torch.nn.ReLU(inplace=True))
self.model = model['block0']
def forward(self, x) :
outputs = self.model(x)
return outputs'''
**********************************************
make_OpenPose_block 함수는 다음 네 가지를 실행
**********************************************
(1) 서브 네트워크를 구성하는 유닛 설정인 config 설정
-->사전형 변술 합성곱 층을 리스트로 설정
-->전체 스테이지 및 블록 구성을 준비하여 주어진 인수의
block_name 설정을 사용
(2) config 내용에 맞도록 합성곱 층과 ReLU를 생성하고 리스트
변수 layers에 저장.
(3) 리스트 변수 layers의 유닛 정보를 사용하여 nn.Sequential()
클래스의 네트워크 모델 net을 생성.
(4) 변수 net의 합성곱 층 가중치 초기화
**********************************************
'''
def make_OpenPose_block(block_name) :
'''
구성 변수에서 오픈포즈 stage 모듈의 블록 작성
nn.Module이 아닌 nn.Sequential로 한다'''
# 1. 구성의 사전형 변수 blocks를 작성하여 네트워크 생성
# 모든 패턴의 사전을 준비하여 block_name 인수만 생성
blocks = {}
# stage 1
blocks['block1_1'] = [{'conv5_1_CPM_L1' : [128, 128, 3, 1, 1]},
{'conv5_2_CPM_L1' : [128, 128, 3, 1, 1]},
{'conv5_3_CPM_L1' : [128, 128, 3, 1, 1]},
{'conv5_4_CPM_L1' : [128, 512, 1, 1, 0]},
{'conv5_5_CPM_L1' : [512, 38, 1, 1, 0]}]
blocks['block1_2'] = [{'conv5_1_CPM_L2' : [128, 128, 3, 1, 1]},
{'conv5_2_CPM_L2' : [128, 128, 3, 1, 1]},
{'conv5_3_CPM_L2' : [128, 128, 3, 1, 1]},
{'conv5_4_CPM_L2' : [128, 512, 1, 1, 0]},
{'conv5_5_CPM_L2' : [512, 19, 1, 1, 0]}]
# stage 2 ~ 6 // 반복
for i in range(2, 7) :
blocks['block%d_1'% i] = [
{'Mconv1_stage%d_L1' % i : [185, 128, 7, 1, 3]},
{'Mconv2_stage%d_L1' % i : [128, 128, 7, 1, 3]},
{'Mconv3_stage%d_L1' % i : [128, 128, 7, 1, 3]},
{'Mconv4_stage%d_L1' % i : [128, 128, 7, 1, 3]},
{'Mconv5_stage%d_L1' % i : [128, 128, 7, 1, 3]},
{'Mconv6_stage%d_L1' % i : [128, 128, 1, 1, 0]},
{'Mconv7_stage%d_L1' % i : [128, 38, 1, 1, 0]}]
blocks['block%d_2'% i] = [
{'Mconv1_stage%d_L2' % i : [185, 128, 7, 1, 3]},
{'Mconv2_stage%d_L2' % i : [128, 128, 7, 1, 3]},
{'Mconv3_stage%d_L2' % i : [128, 128, 7, 1, 3]},
{'Mconv4_stage%d_L2' % i : [128, 128, 7, 1, 3]},
{'Mconv5_stage%d_L2' % i : [128, 128, 7, 1, 3]},
{'Mconv6_stage%d_L2' % i : [128, 128, 1, 1, 0]},
{'Mconv7_stage%d_L2' % i : [128, 19, 1, 1, 0]}]
# block name 인수의 구성 사전을 꺼낸다.
cfg_dict = blocks[block_name]
# 구성 내용을 리스트 변수 layers에 저장
layers = []
# 0번째부터 마지막 층까지 작성
for i in range(len(cfg_dict)) :
for k, v in cfg_dict[i].items() :
if 'pool' in k :
layers += [nn.MaxPool2d(kernel_size=v[0], stride=v[1],
padding=v[2])]
else :
conv2d = nn.Conv2d(in_channels=v[0], out_channels=v[1],
kernel_size=v[2], stride=v[3],
padding=v[4])
layers += [conv2d, nn.ReLU(inplace=True)]
# 3. layers를 Sequential로 한다.
# 단, 마지막에 있는 ReLU는 필요 없어 직전 까지 사용
net = nn.Sequential(*layers[:-1])
# 4. 초기화 함수를 설정하여 합성곱층 초기화
def _initialize_weights_norm(self) :
for m in self.modules() :
if isinstance(m, nn.Conv2d) :
init.normal_(m.weight, std=0.01)
if m.bias is not None :
init.constant_(m.bias, 0.0)
net.apply(_initialize_weights_norm)
return net# 동작 확인
# 모델 정의
net = OpenPoseNet()
net.train()
# 더미 데이터 작성
batch_size = 2
dummy_img = torch.rand(batch_size, 3, 368, 368)
# 계산
outputs = net(dummy_img)
print(outputs)▪ 텐서보드X를 이용한 네트워크 시각화
텐서보드 X: 파이토치 데이터나 네트워크 모델을 시각화하는 서드파티 패키지Graph 파일 생성
시각화하려는 네트워크 모델 파일 생성. // 지금까지 작성한 openpose 네트워크 모델의 인스턴스 생성
# 모델 준비
net = OpenPoseNet()
net.train() Tensorboard X의 저장 클래스 호출
from tensorboardX import SummaryWriter
# 2. tbX 폴더에 저장할 writer 준비
# tbX 폴더가 없으면 자동으로 생성
writer = SummaryWriter('./tbX/')
# 3. 네트워크에 넣을 더미 데이터 생성
batch_size = 2
dummy_img = torch.rand(batch_size, 3, 368, 368)
# 4. 오픈포즈의 인스턴스 net에 더미 데이터인 dummy_img를 전달할 때 graph를 writer에 저장
writer.add_graph(net, (dummy_img,))
writer.close()
# 5. 명령 프롬프트를 열고 tbX가 있는 4_pose_estimation 폴더까지 이동
# 다음 명령 실행
# tensorbard --logdir='./tbX/'
# 이후 http://localhost:6006에 접근▪ OpenPose 학습
데이터로더 및 네트워크 작성
# MSCOCO 파일 경로 리스트 작성
train_img_list , train_mask_list, val_img_list ,\
val_mask_list, train_meta_list, val_meta_list = make_datapath_list(rootpath= \
'./pytorch_advanced/pose_estimation/data/')
# 데이터셋 작성
# 데이터 양이 많아 train을 val_list에서 작성
train_dataset = COCOkeypointsDataset(val_img_list, val_mask_list, val_meta_list,
phase='train', transform=DataTransform())
# 간단한 학습을 진행 // 검증 생략
# val_dataset = CocokeypointsDataset(val_img_list, val_mask_list, val_meta_list,
# phase='val', transform=DataTransform())
# 데이터 로더 작성
batch_size = 32
train_dataloader = data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# val_dataloader = data.DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
# 사전 형 변수로 정리
# dataloaders_dict = {'train' : train_dataloader, 'val' : val_dataloader}
dataloaders_dict = {'train' : train_dataloader, 'val' : None}
# OpenPose Net 클래스의 인스턴스 생성
net = OpenPoseNet()손실함수 정의
- 오픈포즈의 손실함수는 회귀 문제에서 일반적으로 사용하는 평균제곱오차함수로 하고,
구현 시에는 F.mse_loss()를 사용함- 자세 어노테이션이 없는 부분은 손실을 계산하지 않음
# 손실함수 설정
class OpenPoseLoss(nn.Module) :
'''오픈포즈의 손실 함수 클래스'''
def __init__(self) :
super(OpenPoseLoss, self).__init__()
def forward(self, saved_for_loss, heatmap_target, heat_mask, \
paf_target, paf_mask) :
'''
손실함수 계산
Parameters
-----------
saved_for_loss : OpenPoseNet 출력 (리스트)
heatmap_target : [num_batch, 19, 46, 46 ]
정답 부위의 어노테이션 정보
heatmap_mask : [num_batch, 19, 46, 46]
히트맵 화상의 마스크
paf_target : [num_batch, 38, 46, 46 ]
정답 PAF의 어노테이션 정보
paf_mask : [num_batch, 38, 46, 46 ]
PAF 화상의 마스크
Returns
------
loss : 텐서
손실 값
'''
total_loss = 0
# 스테이지 마다 계산
for j in range(6) :
# PAFs 및 히트맵에서 마스크된 부분(paf_mask=0) 은 무시
# PAFs
pred1 = saved_for_loss[2 * j] * paf_mask
gt1 = paf_target.float() * paf_mask
# 히트맵
pred2 = saved_for_loss[2 *j +1] * heat_mask
gt2 = heatmap_target.float() * heat_mask
total_loss += F.mse_loss(pred1, gt1, reduction='mean') + \
F.mse_loss(pred2, gt2, reduction='mean')
return total_loss
criterion = OpenPoseLoss()학습 실시
import random
import math
import time
import pandas as pd
import numpy as np
import torch
import torch.utils.data as data
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import time
optimizer = optim.SGD(net.parameters(), lr=1e-2,
momentum=0.9,
weight_decay=0.0001)
# 모델을 학습시키는 함수 작성
def train_model(net, dataloaders_dict, criterion, optimizer, num_epochs) :
# GPU를 사용할 수 있는지 확인
device= torch.device('cuda:0' if torch.cuda.is_available() else "cpu")
print('사용 장치:', device)
# 네트워크를 GPU로
net.to(device)
# 네트워크가 어느정도 고정되면 고속화시킨다
torch.backends.cudnn.benchmark = True
# 화상 매수
num_train_imgs = len(dataloaders_dict['train'].dataset)
batch_size = dataloaders_dict['train'].batch_size
# 반복 카운터 설정
iteration = 1
# 에폭 루프
for epoch in range(num_epochs) :
# 개시 시간 저장
t_epoch_start = time.time()
t_iter_start = time.time()
epoch_train_loss = 0.0 # 에폭 손실 합
epoch_val_loss = 0.0 # 에폭 손실 합
print('-' * 20)
print(f'Epoch {epoch+1}/{num_epochs}')
print('-' * 20)
# 에폭별 훈련 및 검증 루프
for phase in ['train', 'val'] :
if phase == 'train' :
net.train() # 모델을 훈련 모드로
optimizer.zero_grad()
print(' (train) ')
# 검증 생략
else :
continue
# net.eval() # 모델 검증 모드
# print(' (val) ')
# 데이터 로더에서 미니 배치씩 꺼내는 루프
for images, heatmap_target, heat_mask, paf_target, \
paf_mask in dataloaders_dict[phase] :
# 미니 배치 크기가 1이면 배치 정규화에서 오류가 발생하므로 피한다
# if images.size()[0] == 1 :
# continue
# GPU를 사용할 수 있으면 GPU로 데이터를 보낸다.
images = images.to(device)
heatmap_target = heatmap_target.to(device)
heat_mask = heat_mask.to(device)
paf_target = paf_target.to(device)
paf_mask = paf_mask.to(device)
# 옵티마잊더 초기화
optimizer.zero_grad()
# 순전파 계산
with torch.set_grad_enabled(phase == 'train') :
# out6_1, out6_2는 사용하지 않으므로 _ 로 대체
_, saved_for_loss = net(images)
loss = criterion(saved_for_loss, heatmap_target,
heat_mask, paf_target, paf_mask)
del saved_for_loss
# 훈련 시 역전파
if phase == 'train' :
loss.backward()
optimizer.step()
if (iteration % 10 == 0 ) : #10iter에 한 번 손실 표시
t_iter_finish = time.time()
duration = t_iter_finish - t_iter_start
print(f'반복 {iteration} || Loss : \
{loss.item()/batch_size:.4f} || \
10iter : {duration:.4f} sec.')
t_iter_start = time.time()
epoch_tran_loss += loss.item()
iteration += 1
# 에폭의 phase 별 손실과 정답률
t_epoch_finish = time.time()
print('-' * 20)
print(f'Epoch {epoch + 1} || Epoch Train Loss : \
{epoch_train_loss/num_train_imgs:.4f} || Epoch Val Loss : {0:.4f}')
print(f'timer : {t_epoch_finish - t_epoch_start:.4f} sec')
t_epoch_start = time.time()
# 마지막 네트워크 저장
torch.save(net.state_dict(), './pytorch_advanced/pose_estimation/weights/\
openpose_net_' +str(epoch+1) + '.pth')# 학습 및 검증 실행
num_epochs = 2
train_model(net, dataloaders_dict, criterion, optimizer, num_epochs=num_epochs)▪ 오픈포즈 추론
# 학습 및 검증 실행
# 학습된 모델과 이번 장의 모델은 네트워크 계층의 이름이 달라 대응시켜 로드함
# 모델 정의
net = OpenPoseNet()
# 학습된 파라미터를 읽는다
net_weights = torch.load('./pytorch_advanced/pose_estimation/weights/ \
pose_model_scratch.pth',map_location='cpu')
keys = list(net_weights.keys())
weights_load = {}
# 로드한 내용을 책에서 구축한 모델의 파라미터명 net.state_dict().keys()로 복사
for i in range(len(keys)) :
weights_load[list(net.state_dict().keys())[i]] = net_weights[list(keys)[i]]
# 복사한 내용을 모델에 할당
state = net.state_dict()
state.update(weights_load)
net.load_state_dict(state)
print('네트워크 설정 완료. 학습된 가중치를 로드했습니다.')# 야구 화상을 읽어 전처리 실행
test_image = './pytorch_advanced/pose_estimation/data/hit-1407826_640.jpg'
ori_image = cv2.imread(test_image) # B, G, R 순서
# BGR을 RGB로 표시
ori_image = cv2.cvtColor(ori_image, cv2.COLOR_BGR2RGB)
plt.imshow(ori_image)
plt.show()
# 화상 resize
size = (368, 268)
img = cv2.resize(ori_image, size, interpolation=cv2.INTER_CUBIC)
# 화상 전처리
img = img.astype(np.float32) / 255.
# 색상 정보 표준화
color_mean = [0.485, 0.456, 0.406]
color_std = [0.229, 0.224, 0.225]
preprocessed_img = img.copy()[:, :, ::-1] # BGR --> RGB
for i in range(3) :
preprocessed_img[:, :, i] = preprocessed_img[:, :, i] - color_mean[i]
preprocessed_img[:, :, i] = preprocessed_img[:, :, i] / color_std[i]
# (높이, 폭, 색) --> (색, 높이, 폭)
img = preprocessed_img.transpose((2, 0, 1)).astype(np.float32)
# 화상을 텐서로
img = torch.from_numpy(img)
# 미니 배치화 : torch.Size([1, 3, 368, 368])
x = img.unsqueeze(0)# 오픈포즈로 히트맵과 PAFs를 구한다
net.eval()
predicted_outputs, _ = net(x)
# 화상을 텐서에서 넘파이로 변환하여 크기 반환
pafs = predicted_outputs[0][0].detach().numpy().transpose(1, 2, 0)
heatmaps = predicted_outputs[1][0].detach().numpy().transpose(1, 2, 0)
pafs = cv2.resize(pafs, size, interpolation=cv2.INTER_CUBIC)
heatmaps = cv2.resize(heatmaps, size, interpolation=cv2.INTER_CUBIC)
pafs = cv2.resize(pafs, (ori_image.shape[1], ori_image.shape[0]),
interpolation=cv2.INTER_CUBIC)
heatmaps = cv2.resize(heatmaps, (ori_image.shape[1], ori_image.shape[0]), \
interpolation=cv2.INTER_CUBIC)
# 왼쪽 팔꿈치와 왼쪽 손목의 히트맵, 그리고 왼쪽 팔꿈치와 왼쪽 손목을 잇는 PAF의 x 벡터를 시각화
# 왼쪽 팔꿈치
heat_map = heatmaps[:, :, 6] # 6은 왼쪽 팔꿈치
heat_map = Image.fromarray(np.uint8(cm.jet(heat_map)*255))
heat_map = np.asarray(heat_map.convert('RGB'))
# 합성하여 표시
blend_img = cv2.addWeighted(ori_image, 0.5, heat_map, 0.5, 0)
plt.imshow(blend_img)
plt.show()
# 왼쪽 손목
heat_map = heatmaps[:, :, 7] # 7은 왼쪽 손목
heat_map = Image.fromarray(np.uint8(cm.jet(heat_map)*255))
heat_map = np.asarray(heat_map.convert('RGB'))
# 합성하여 표시
blend_img = cv2.addWeighted(ori_image, 0.5, heat_map, 0.5, 0)
plt.imshow(blend_img)
plt.show()
# 왼쪽 팔꿈치와 왼쪽 손목을 잇는 PAF의 x 벡터
paf = pafs[:, : , 24]
paf = Image.fromarray(np.uint8(cm.jet(paf)* 266))
paf = np.asarray(paf.convert('RGB'))
# 합성하여 표시
blend_img = cv2.addWeighted(ori_image, 0.5, paf, 0.5, 0)
plt.imshow(blend_img)
plt.show()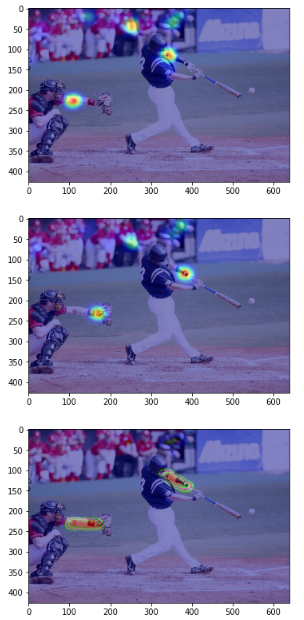
# from utils.decode_pose import decode_pose
_, result_img , _, _ = decode_pose(ori_image, heatmaps, pafs)
# 결과를 화면에 그리기
plt.imshow(ori_image)
plt.show()
plt.imshow(result_img)
plt.show()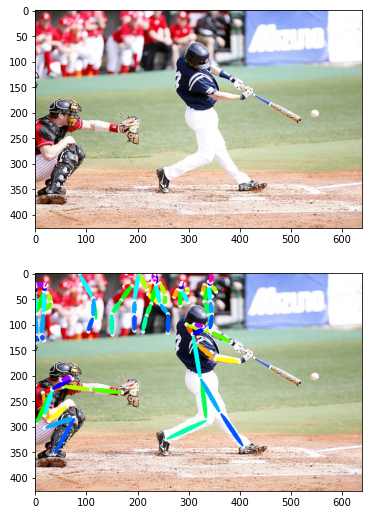

AI에 대체되지 않는 인재가 되자