참조: https://www.youtube.com/watch?v=aj3vw_KDmxc&t=29
참조: https://velog.io/@turtle601/%EB%B6%84%ED%95%A0%EC%A0%95%EB%B3%B5
분할 정복(Divide and Conquer)이란
어떤 문제를 유사한 형태를 가지는 더 작은 크기의 서브 문제들로 나눈 후 이들을 재귀적으로 같은 방식으로 해결한 뒤 각 서브 문제들을 해결한 결과를 활용하여 원래 문제를 해결하는 방식
보통 merge sort, quick sort, binary search 등에 자주 사용된다.
분할 정복 과정
- divide: 문제를 작은 크기의 서브 문제들로 나눈다.
- conquer: 서브 문제들을 동일하게 재귀적인 방식으로 해결한다. 만약 더 이상 나눌 수 없다면 직접 해결한다.
-combine: 서브 문제들의 솔루션을 합쳐서 원래 문제의 솔루션을 만든다.
분할 정복 예시
관련 예시로 병합 정렬이 있는데, 자세한 사항은 들어가서 확인하자.
- 병합 정렬
과정
1. 정렬할 데이터 집합의 크기가 0 또는 1이면 이미 정렬된 것으로 보고, 그렇지 않으면
2. 데이터 집합을 중간 인덱스 기준으로 나눈다.
3. 원래 같은 집합에서 나뉘어져 나온 데이터 집합 둘을 병합하여 하나의 데이터 집합으로 만든다. 단, 병합할 때 데이터 집합의 원소는 순서에 맞춰 정렬한다.
4. 데이터 집합이 다시 하나가 될 때까지 3을 반복한다.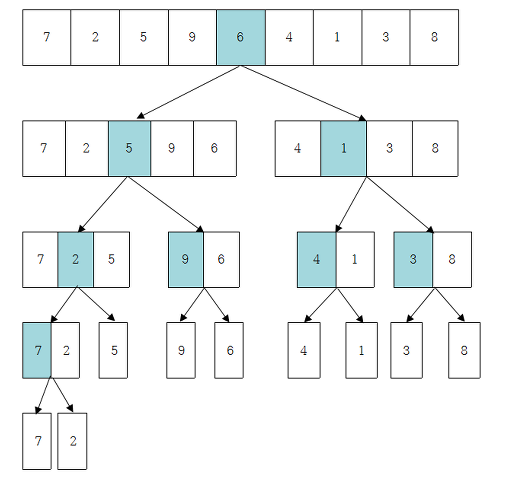
- 해당 그림처럼 1번 2번 과정을 반복한 후
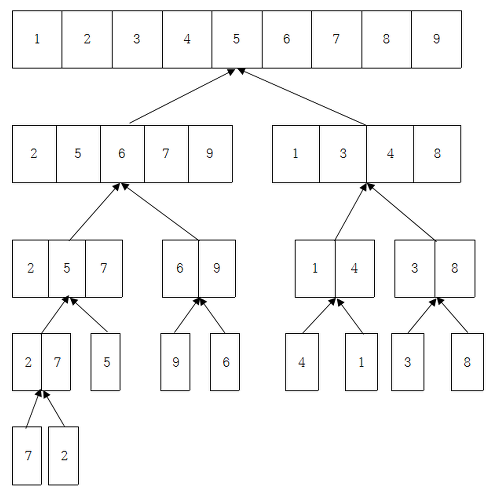
- 해당 그림처럼 3~4번 과정을 반복하여 정렬하는 방법이다.
