백준
1.[C++]백준 16562번 : 친구비

문제출처풀이코드return sx = Find(s,sx); 을 통해 랭크가 길어지지 않게끔 설계하였다.Union에서는 cost비교를 하여 가장 적은 cost를 root에 달았다.for문을 통해 그룹내 최소 비용을 구하여 계산하였다.
2.[C++]백준 31477번: 양갈래 구하기
문제출처풀이방법DFS사용하였다. 시작 노드인 1에 인접한 모든 노드를 DFS로 탐색한다. edge의 개수가 1인 node를 만나면 연결된 edge의 가중치를 return한다. 이때 edge의 개수가 1이 아닌 직전 node에선 edge의 개수가 1인 노드로부터의 모든
3.[C++]백준 2056번: 작업
풀이위상정렬을 통해 문제를 해결하였다. time vector에는 input으로 주어지는 고정시간이 들어가고 ttime vector에는 해당 작업에 선제 되는 작업들 중 가장 오래 걸린 작업의 시간을 넣는다. indice값이 0이 되면 선제 작업이 모두 끝났으므로 해당
4.[C++]백준 11085번: 군사 이동

문제출처 >풀이 대충보면 다익스트라 최단경로 문제 같지만 이 문제는 거리 비용의 최소를 구하는 문제가 아니다. 이 문제는 두 지점이 연결이 되었을 때, 두 지점 사이 너비의 최소가 최대가 되게끔 하는게 핵심이다. >두가지 포인트가 있다. 두 지점 사이 너비의
5.[C++]백준 13164번: 행복 유치원
문제출처풀이이 알고리즘을 생각만 해내면 구현까지는 쉽지만 생각해내기까지의 시간이 오래걸렸다. 확률과 통계의 중복조합을 떠올려 생각해냈다.핵심은K-1개의 가림막이 필요하다.그 가림막을 기준으로 조가 나누어진다.결국은 비용의 합이 중요한 것이다.(1-3이 같은 조라면 (1
6.[C++]백준 1365번: 꼬인 전깃줄
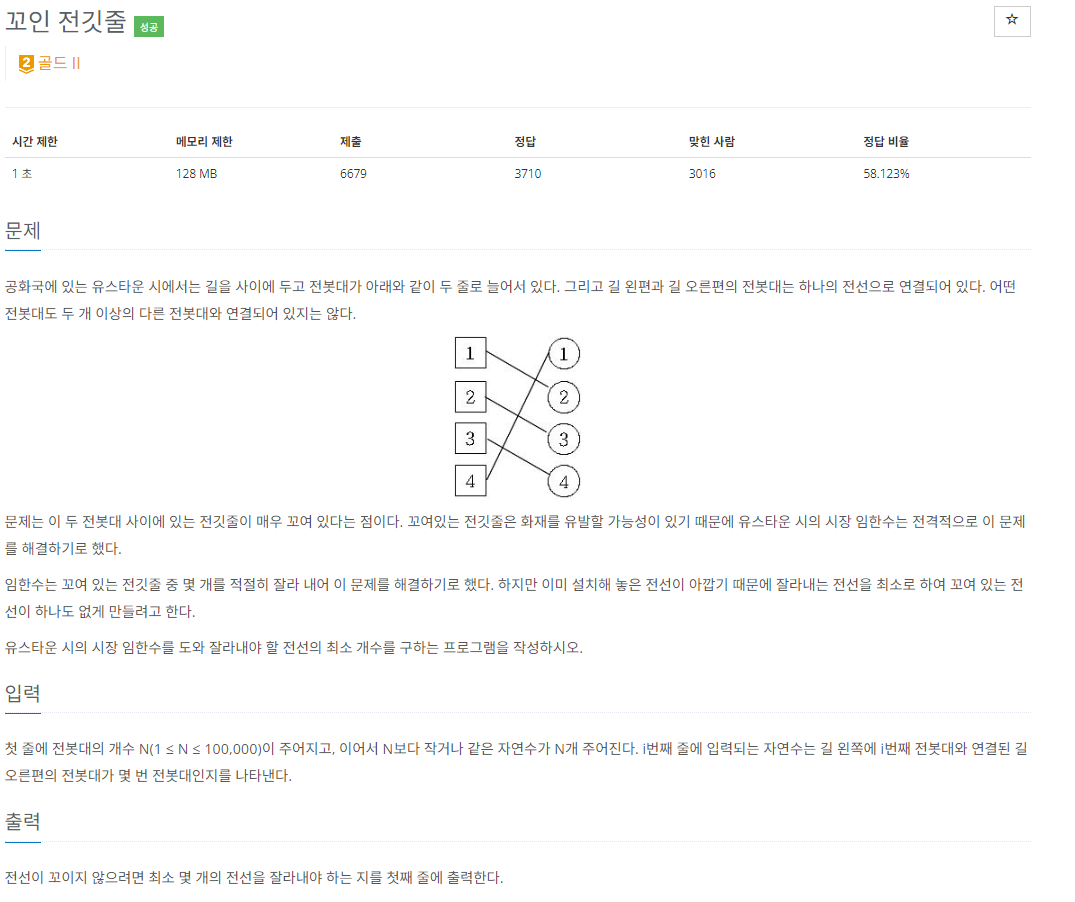
출처풀이문제를 보면 바로 DP 가장 긴 증가하는 수열이 떠오른다. 하지만 시간 제한은 1초이고 N의 최댓값은 100,000이기에 N^2시간복잡도를 가지고 있는 DP를 사용할 수 없다.이 문제에서 중요한 점은 가장 긴 증가하는 수열의 개수만 알면 된다는 것이다.res배열
7.[C++]백준 11000번: 강의실 배정
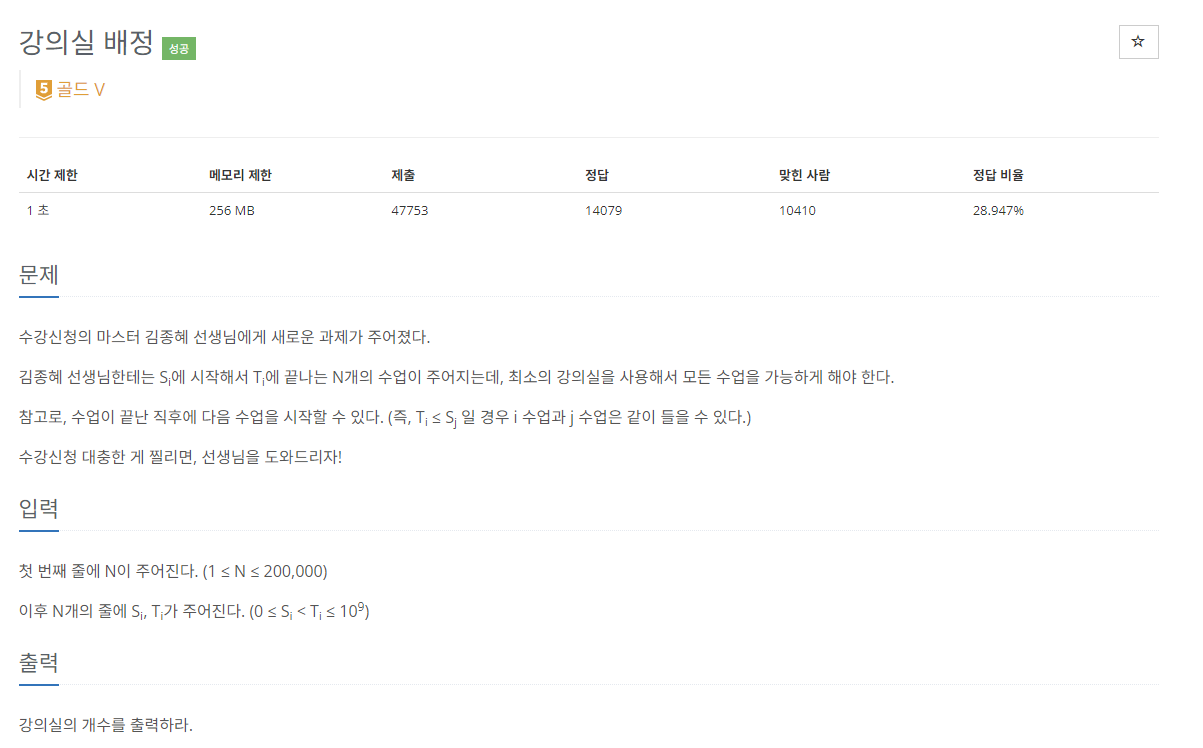
문제 출처풀이우선 문제를 보면 기존의 그리디 알고리즘으로 풀리던 강의실 문제 유형과는 다르다. 이 문제는 한 강의실에 최대 몇 개의 강의가 들어갈 수 있냐고 묻는 그리디 알고리즘 형태의 문제가 아니라. 모든 강의를 수용 할 수 있는 강의실의 개수를 원한다. 이 문제는
8.[C++]백준 13904번: 과제
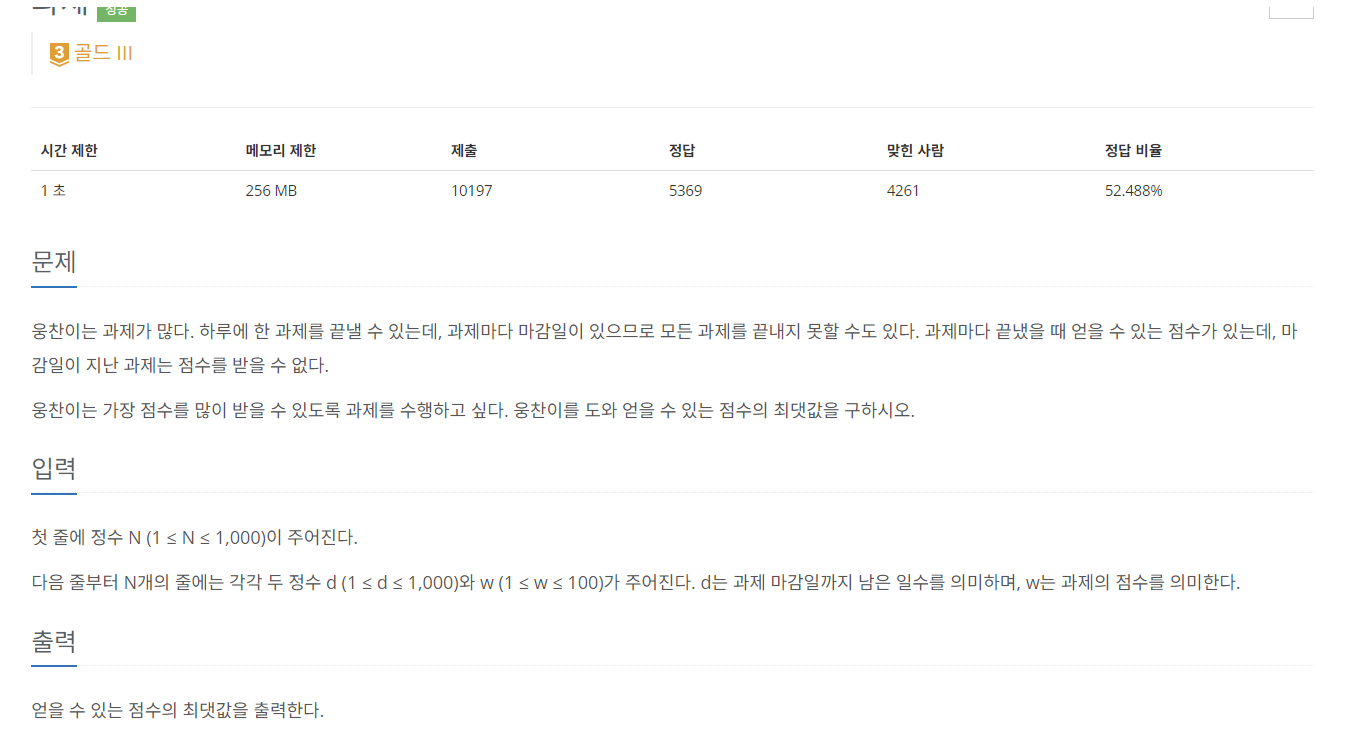
문제 출처풀이1.주어진 d,w한 쌍을 w의 내림차순으로 정렬한다.2\. 뽑힌 (d,w)한 쌍에 대해 d일부터 1일까지 아직 과제가 할당되지 않은 일차에 해당 과제가 들어가면 된다.
9.[C++]백준 1744번: 수 묶기
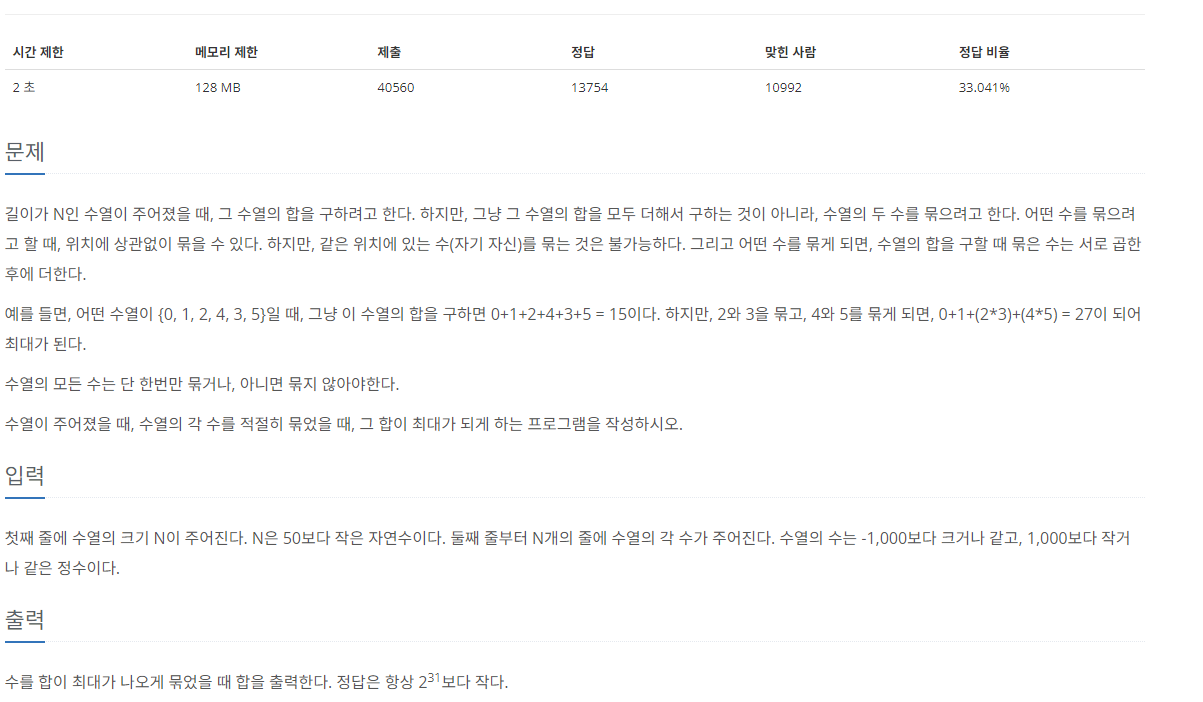
문제 출처이 문제는 한눈에 봐도 그리디알고리즘인 것을 알 수 있다. 이 문제가 까다로운 이유는 분기가 많기 때문이다. 어떤 수열의 원소 x가 주어졌을 때 분기는 다음과 같다.x > 1x = 1x = 0x < 01은 다른 수와 묶였을 때(곱해졌을 때) 오히려 수가
10.[C++]백준 2638번: 치즈

문제 출처BFS/DFS보단 "구현"문제가 맞는 것 같다.이 문제에서 유의해야할 사항은 다음과 같다.빈 공간은 외부의 빈 공간(-1)/ 치즈 속의 빈공간(0) 두개로 분리된다.두 면의 외부의 빈공간에 노출된 치즈를 한 꺼번에 업데이트 해야한다.치즈가 녹음으로써 치즈 속의
11.[C++]백준 12861번: 숨바꼭질 2
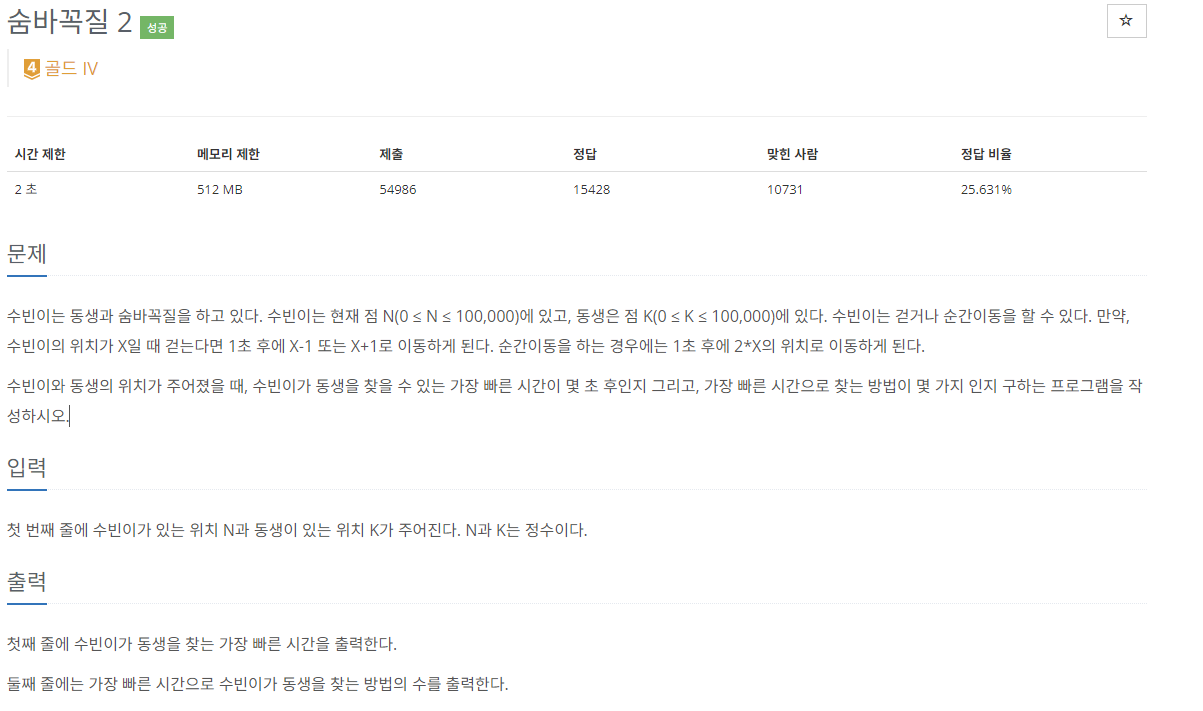
문제 출처현재 위치에서 -1, +1, 2중 하나를 택하여 옮겨간다. 그러다 K에 도달하면 골인이다. 이때 걸린 시간과 방법의 수를 출력하여야 한다. BFS라는 것을 눈치챌 수 있다. 중간에 도달한 수를 a라고 하면 조금의 가지치기를 통해 a가 K를 지나치게 되면 a-1
12.[C++]백준 2230번: 수 고르기
문제 출처풀이이 문제는 전형적인 투 포인터 문제라고 느낌이 빡온다. input원소들을 정렬한 후 left =0, right = 0에서 시작해서 diff = arrright-arrleft가 M보다 작으면 right를 늘려 차를 키운다. M보다 크거가 같으면 우리가 원하는
13.[C++]백준 15681번 : 트리와 쿼리
문제 출처DFS로 풀면 쉽게 풀리는 문제이다. root부터 시작해서 leaf까지 DFS를 한다. leaf의 서브트리에 속한 정점의 수는 1이므로 이것들을 다 더해서 root까지 보내주면 완성이다. 사실 이 문제 밑에 있는 내용이 꽤 유익해서 한번쯤 읽어보는 것을 추천한
14.[C++]백준 1781번: 컵라면
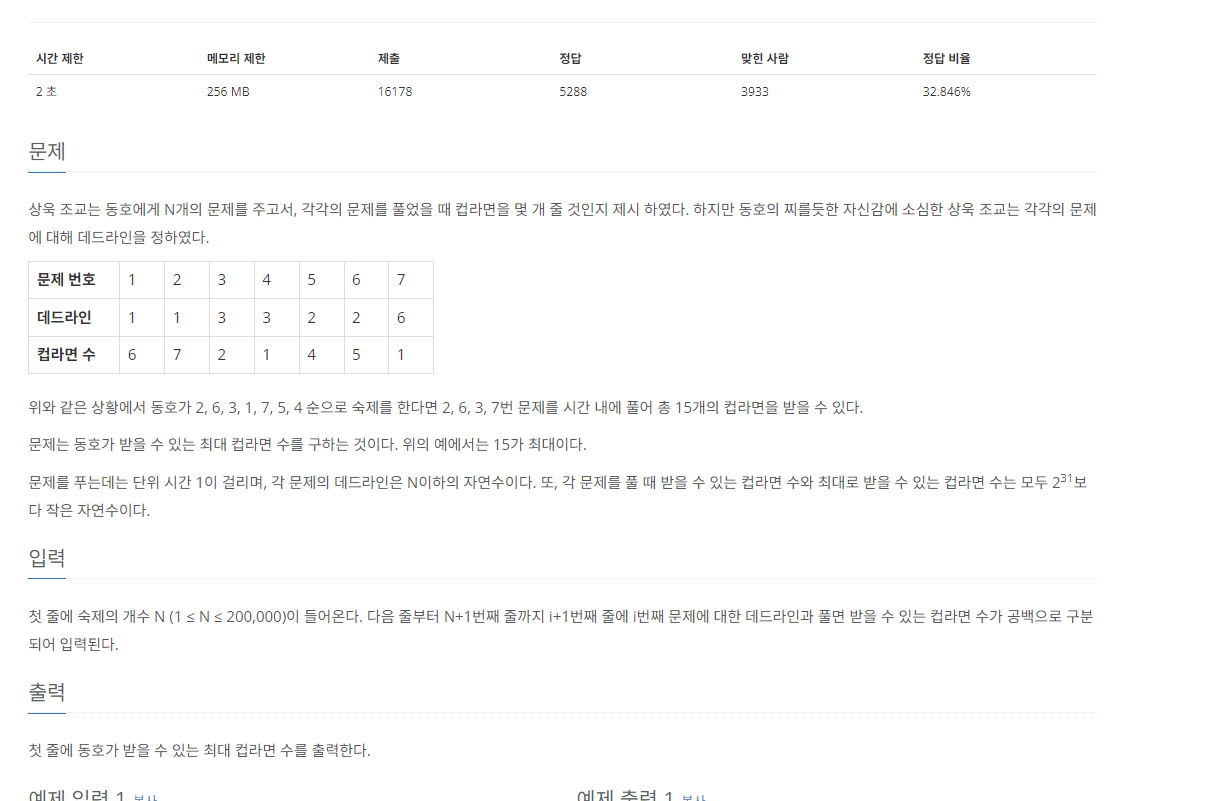
문제 출처그리디 문제이다. 컵라면 수가 많은 문제를 먼저 뽑고 싶다는 생각이 든다. 하지만, 데드라인에 맞게 컵라면 수가 높은 문제들을 차례대로 뽑기 어렵다. 이때 우선순위 큐를 사용하여 문제를 설계하면 비교적 쉽게 풀이를 할 수 있다.우선 문제들을 데드라인의 오름차순
15.[C++]백준 14621번: 나만 안되는 연애

문제 출처간단한 최소거리 구하는 문제였다. 그럼에도 골드3에 랭크되어 있는 이유는 단 하나의 조건이 추가되어서인데, 바로 노드끼리의 타입이 달라야한다는 조건이다. 즉 간선으로 연결된 두 노드 중 한 노드가 M이면 다른 노드는 W여야한다. 이 조건만 신경쓰고 나머지는 일
16.[C++]백준 1600번: 말이 되고픈 원숭이
문제 출처문제를 보는데 정답 비율이 너무 낮아 일반적인 BFS 방식으로 풀면 분명히 뭔가 틀리겠구나 했다. 아마도 메모리 초과로 많이 틀렸을 것으로 예상이 되었으며 그 이유는 queue에 y좌표, x좌표, 현재 말 점프 횟수(k) 이렇게 3가지 int값을 넣을 뿐더러,
17.[C++]백준 4256번: 트리

문제 출처재귀적으로 분할정복을 사용하였다. 전위 순회배열의 원소를 하나씩 보면서 중위 순회배열에서 해당 원소를 찾았고 그 원소의 위치보다 왼쪽에 있으면 left node, 오른쪽에 있으면 right node로 설정하였다.다음은 전체 코드이다.
18.[C++]백준 15486번: 퇴사 2
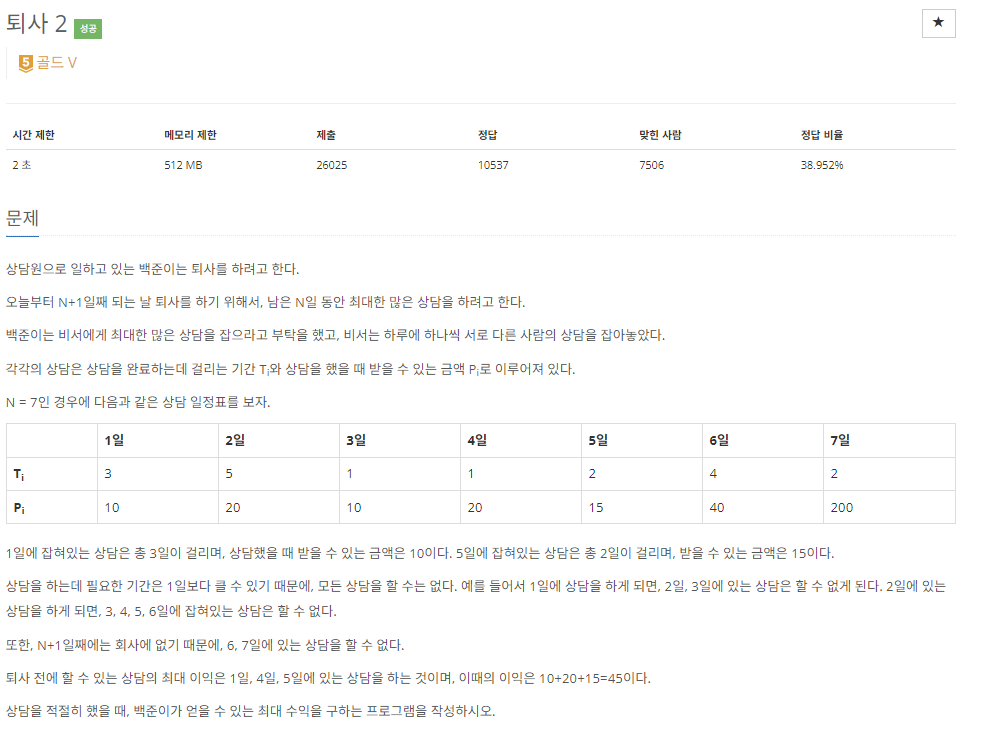
문제 출처i일 금액을 결정하는 데에는 두 가지 선택권이 있다. i-1일의 것을 선택한다.i일 이전에 i일까지 딱 마감된 금액을 선택한다.2가 무슨 말이냐면 예를 들어 1일차에 T1 = 3이고 P1 = 10이면 4일차에 금액이 0이 아닌 10부터 시작하는 것이다. 그리고
19.[C++]백준 1949번: 우수 마을
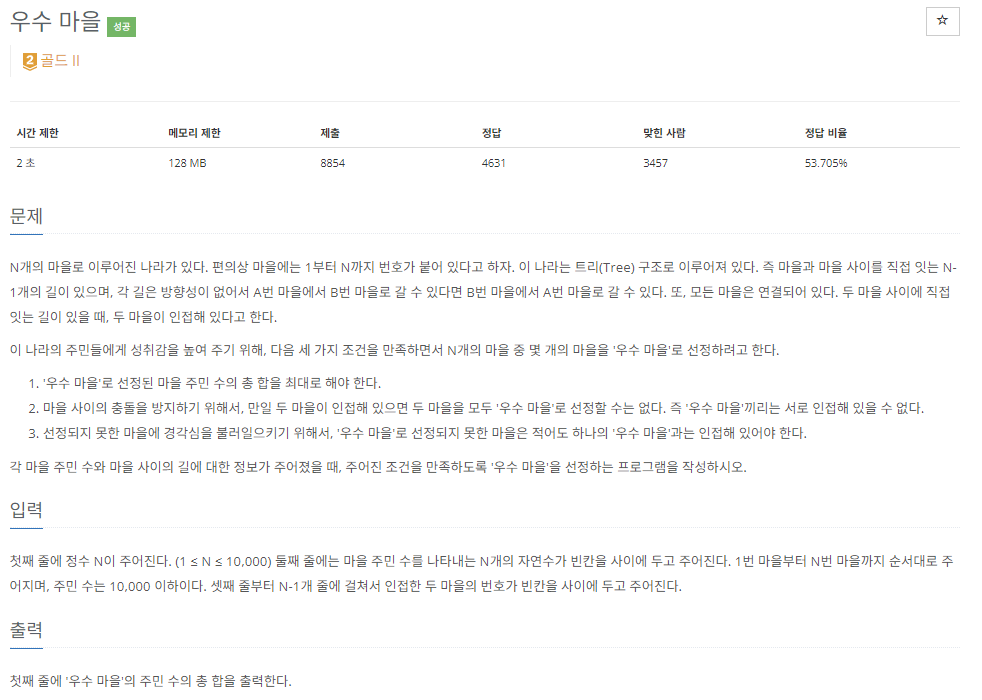
문제 출처이 문제는 2번과 3번 규칙에 유의해야한다. 2번 규칙에서 어느 한 마을이 우수마을로 선정되면 주변 마을은 모두 우수마을이 될 수 없다. 하지만,우수마을이 아닌 마을들 끼리는 인접할 수 있다. 무슨 말이냐면 무조건 우수 - 우수아님 - 우수 - 우수아님이럴 필
20.[C++]백준 2213번: 트리의 독립집합
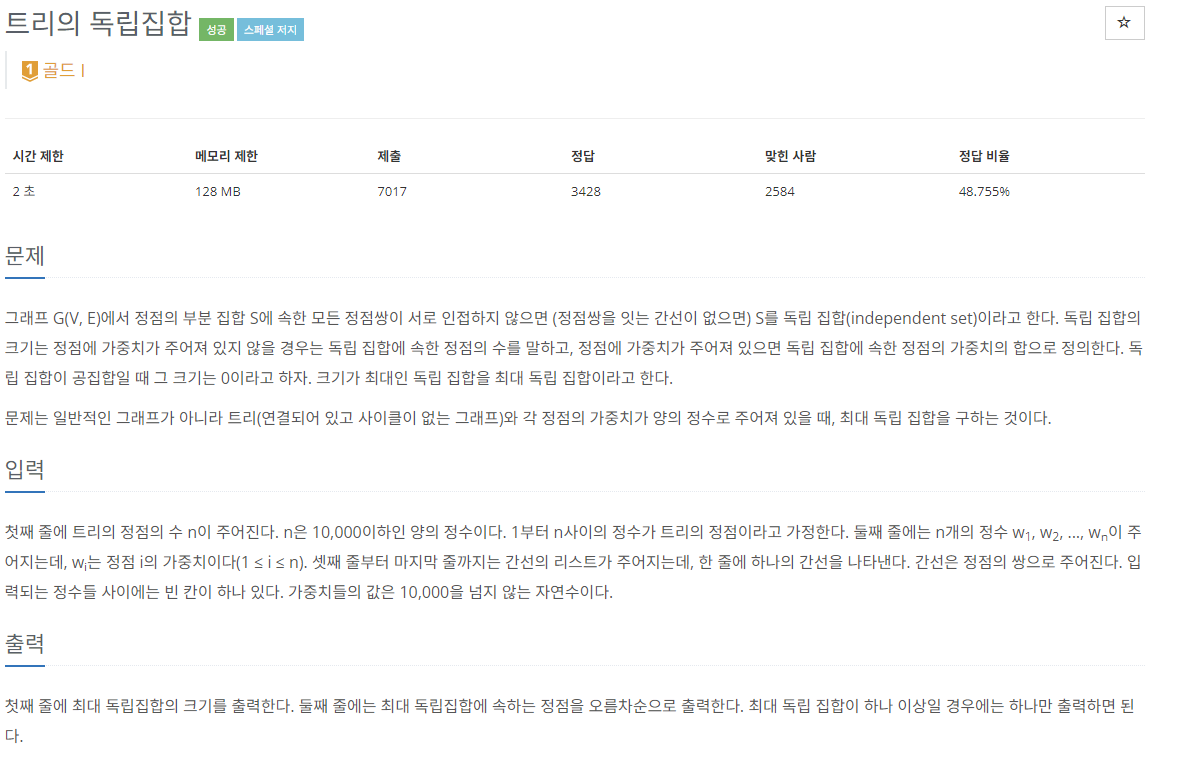
문제 출처이전 포스트의 문제였던 우수마을과 거의 동일한 문제이다. 다른 점은 이전 포스팅으로 비유하면 우수마을로 선정된 노드들도 같이 출력하는 것이 다른 점이다. 우수마을로 선정된 노드들을 찾는 방법은 트리의 루트에서 역으로 내려가서 탐색하는 방법이 있다.두 가지 상황
21.[C++]백준 1561번: 놀이 공원
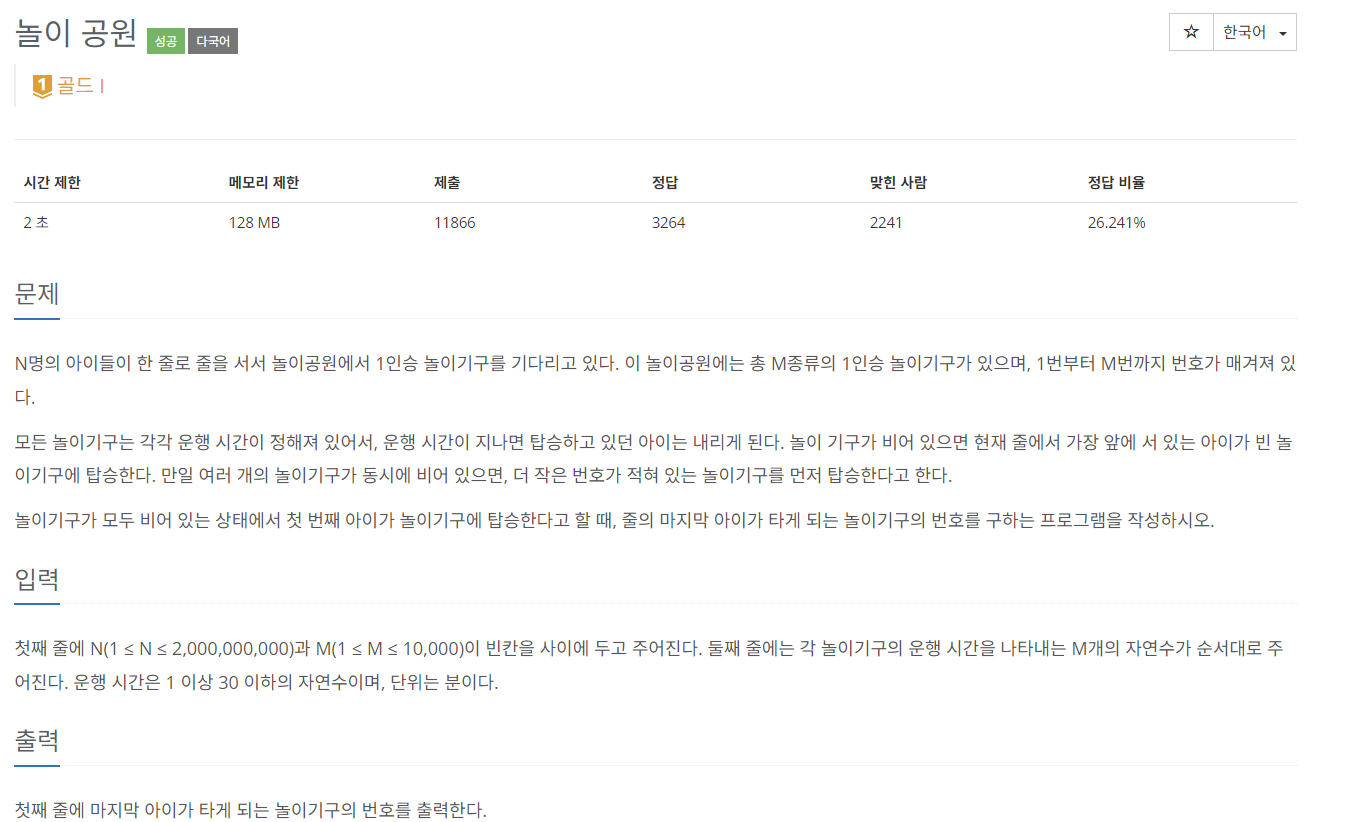
문제 출처처음에 도저히 감이 안잡혔다가 이분탐색이라는 힌트를 듣고 문제를 풀 수 있었다. 맨 처음에 N과 운행 시간의 최댓값을 right로 잡는다. left는 0이다. 그러고 mid = (right + left)/2로 잡는다. 이 mid값으로 운행시간에 해당하는 값들로
22.[C++]백준 2143: 두 배열의 합
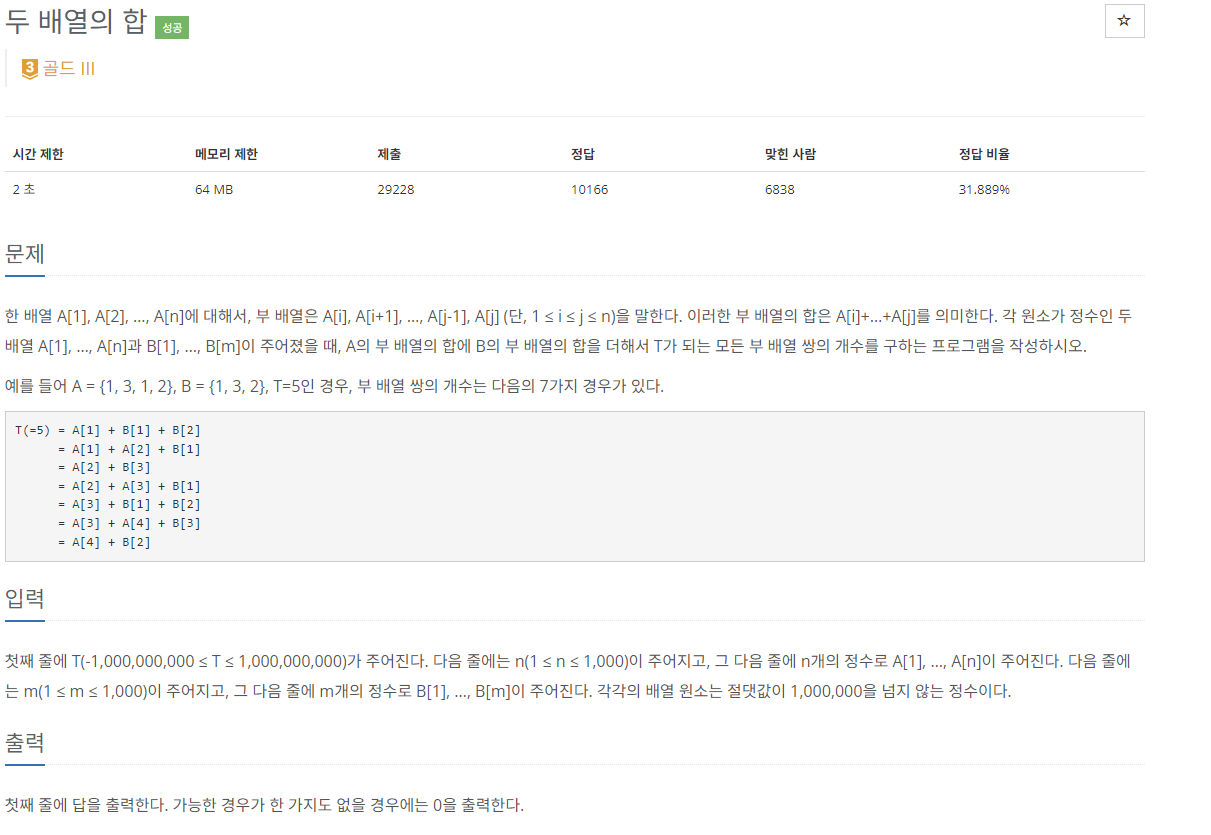
문제 출처문제를 보자마자 누적합 문제라는 것은 쉽게 알 수 있다. 하지만 일반적인 누적합 문제로 접근을 하면 시간초과가 발생할 수 밖에 없는데, 그 이유가 n = 1000이라고 했을 때 만들 수 있는 부 배열 쌍의 수가 1000 \* 1001 /2가 된다. 즉 대략 5
23.[C++]백준 1261번: 알고스팟
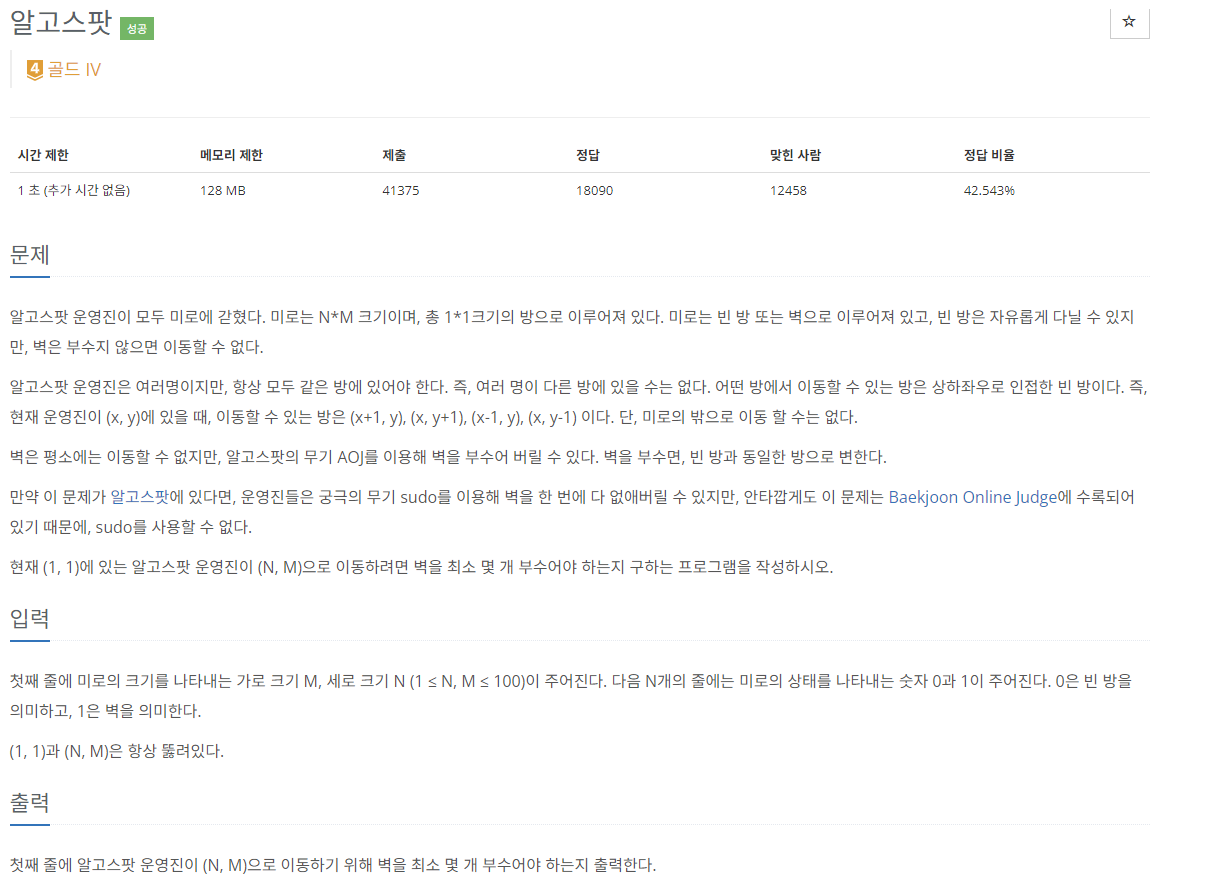
문제 출처전형적인 BFS문제라고 생각했고 그렇게 접근했지만 알고리즘이 번뜩 떠오르지가 않았다. 그렇게 힌트를 보다 0-1BFS 알고리즘이라는 것을 접했고 이를 소개하고자 한다.0-1 BFS0-1BFS는 모든 간선의 가중치가 0 또는 1인 것을 뜻한다. 일반적인 다익스트
24.[C++]백준 13002번: Happy Cow
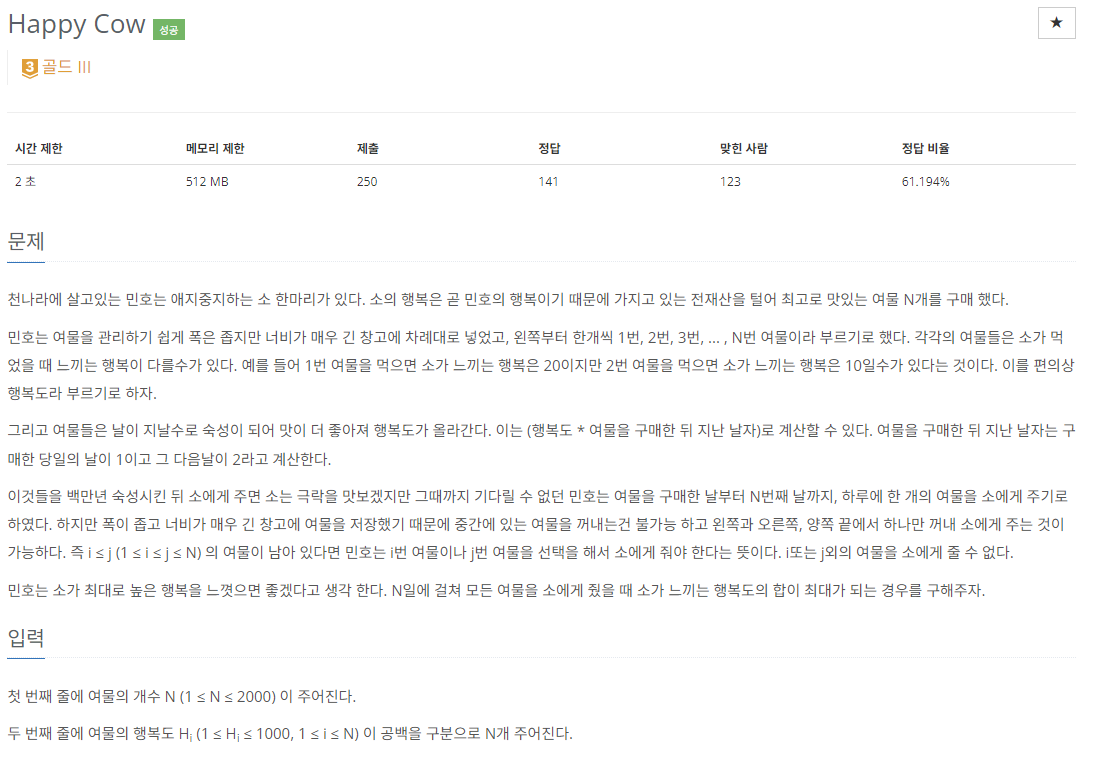
문제 출처문제가 생각보다 간단하다. n일째 날에는 n-1일째 날의 정보를 바탕으로 왼쪽 혹은 오른쪽에서 여물을 빼와서 계산하면 되는 문제이다. n일에 n-1일의 정보가 필요하므로 DP문제이다. 여물의 총 길이가 N이라고 하자. 그럼 여물 배열의 0부터 N-1까지 여물이
25.[C++]백준 5557번: 1학년
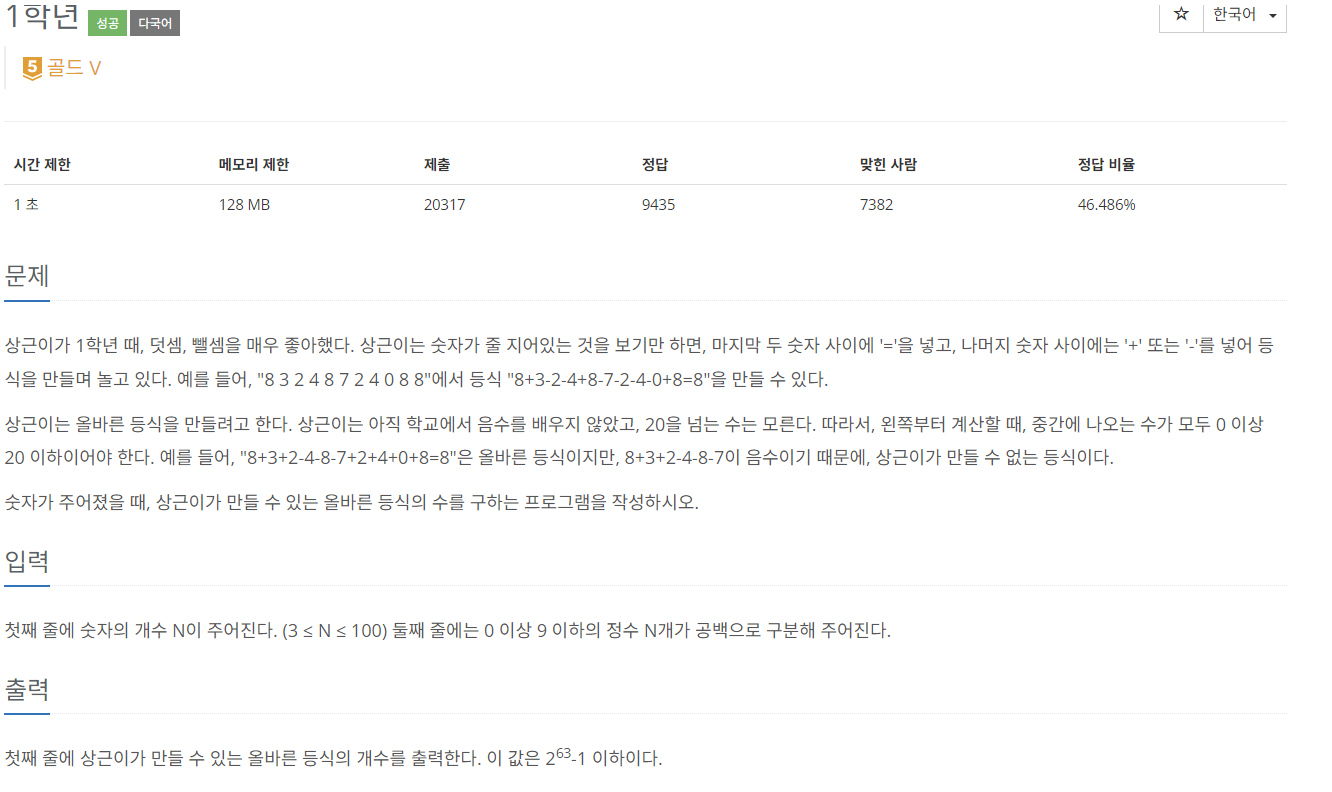
문제 출처전형적인 DP문제였다. 앞에서부터 계산하기보다는 뒤에서부터 계산해나가는 것이 편해보였다. 이 문제가 DP로서 풀리는 이유는 0부터 20까지의 제한 덕분인데 이것이 없었다면 계산복잡도가 엄청났을 것이다. 수의 제한이 0부터 20까지이기 때문에 우리는 dpN짜리
26.[C++]백준 17135번: 캐슬 디펜스
문제 출처문제를 읽으며 궁수의 위치를 배치할 때에는 백트래킹, 혹은 조합을 사용해야겠다는 생각이 들었으며 가까운 적부터 공격하며 거리가 같으면 왼쪽 적부터 공격한다고 했기에 BFS를 생각했다. 그리고 적들이 한칸씩 내려오며, 이것을 적이 없을 때까지 반복해야 되기에 구
27.[C++]백준 13549번: 숨바꼭질 3
문제 출처처음 접했을 때 BFS문제라는 것을 인식했다. 그리고 0초가 존재한다는 것을 보고 이건 0-1BFS라는 생각이 바로 들었다. 0-1BFS를 구현하기 가장 편리한 컨테이너는 deque이다. 따라서 나는 deque를 사용하였고 0초, 즉 2\*x로 이동할때에는 d
28.[C++]백준 17298번: 오큰수
문제 출처이 문제를 보고 자료구조 문제라는 것은 짐작하였다. 처음에 했던 생각은 뒤에서부터 탐색을 시작하는 것이었다. 마지막 인덱스(N-1)의 오큰수는 당연히 -1 이고 N-2를 탐색할 때 N-1이랑 비교해서 자리를 위치를 알맞게 조정하는 것을 생각하였었다. 하지만,
29.[C++]백준 17472번: 다리 만들기 2

문제 출처오랜만에 빡구현 문제를 만났다. 처음에 접근하기를 우선 BFS를 통해 섬들을 구분하자였고, 그 다음은 이 섬들 간의 거리를 배열에 저장시켜서 이것을 활용해먹자는 생각이었다. 하지만, 거리를 배열에 저장해놓고 이것을 어떻게 활용해먹지? 라는 의문이 사라지지 않았
30.[C++] 백준 11437번: LCA
문제 출처개인적으로 쉬운 문제라 생각했는데 계속 시간초과가 떠서 당황했다. 도저히 해결할 방법이 없어 여기저기 찾아보니 내가 구현한 것에서 level이라는 개념을 도입해 tree의 level을 같게 만들어준 다음 거기서부터 탐색을 하는 방법이 있었다. 물론 이 방법은
31.[C++] 백준 2437번: 저울
문제 출처오랜만에 되게 재밌는 문제를 만났다. 처음엔 DP를 생각하였지만 1,000,000 \* 1000이 이미 십억이기에 일반적인 DP로는 풀 수 없겠다. 생각하고 변형DP를 찾아보았지만 그마저도 쉽지 않았다. 그러다 예시에 나와있는 숫자들을 하나씩 써보니 해답이 나