
💎 Indexing, Inverted indexing
- 개인 정리 : 색인이 문서들에서 키워드를 뽑아낸다면, 역색인은 뽑아낸 키워드들을 바탕으로 그 키워드가 포함된 문서를 찾아나간다.
- 관계형 데이터베이스에서는 보통 단방향 색인을 사용한다. 1:N의 관계에서는 보통 N개의 데이터가 1개의 데이터를 칼럼에 저장하는 방법을 사용한다. 이와 같이 색인이 된 경우에, 만약 '특정한 1개의 tuple을 Foreign key로 가지고 있는 N개의 row를 찾아라'라는 쿼리를 돌릴 때, DBMS는 하염없이 N개의 데이터를 검색하고, 중간에 찾았다고 질의를 끊지도 못한다.(뒤에 더 있다는 가능성을 간과하지 못하기 때문에) 이러한 현상을 개선하기 위해 나온 것이 역색인(inverted-index)이다
1. 색인(indexing)
색인(索引)은 책 속의 낱말이나 구절, 또 이에 관련한 지시자를 찾아보기 쉽도록 일정한 순서로 나열한 목록을 가리킨다. 인덱스(index)라고도 한다.
색인 종류
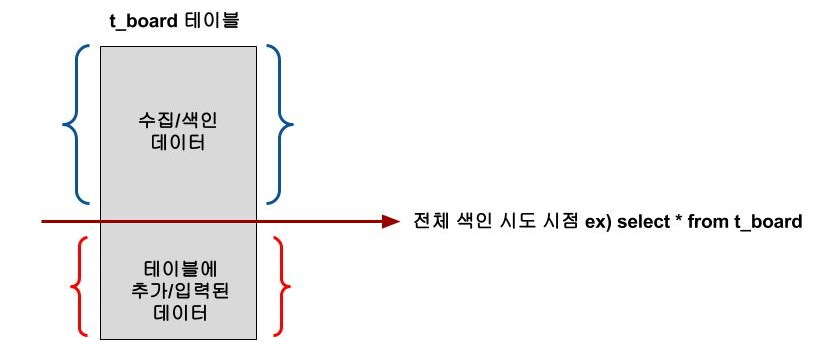
1️⃣ 전체 색인 (static index) : 정적색인이라고도 하며 색인을 시도하는 시점 이전의 데이터를 수집/색인한다.
2️⃣ 증분 색인 (dynamic index) : 동적색인 이라고도 하며 전체색인 완료 시점 부터 추가된 데이터를 수집/색인한다.
3️⃣ 메뉴얼 색인 (manual index) : 데이터의 PK 혹은 고유값을 통한 데이터 재 수집/ 재색인한다.1. 전체 색인
진행과정
- 데이터 수집 대상 테이블에 추가/입력되는 데이터가 없다면 그 테이블에 입력된 row 갯수 만큼 데이터 수집/색인작업 진행
- 데이터 수집 대상 테이블에 추가/입력되는 데이터가 있다면 색인 시도 시점 이전에 입력된 row 갯수 만큼 데이터 수집/색인 작업 진행
2. 증분 색인
개요
- 데이터 수집 대상 테이블에 추가/입력된 데이터를 수집/색인 하는 작업
- 증분 색인 방법으로 여러가지 방법이 있으나 "날짜기준 수집/색인" 과 "CRUD 발생시 Queue 기록 수집/색인" 방법이 주류를 이룬다
1️⃣ 날짜 색인
검색엔진에 최종적으로 수집/색인된 데이터의 날짜를 가지고 와 그 날짜 이후 입력된 데이터를 select 한다
$
2️⃣ CRUD 발생시 Queue 기록 수집/색인 방법
데이터 CRUD에 대한 히스토리를 기록하여 기록된 정보를 가지고 데이터의 수집/색인이 이루어지도록 한다.3. 메뉴얼 색인
진행 과정
- 데이터 수집 대상 테이블에서 특정 PK값을 조회하여 데이터 재 색인 과정을 거친다.
- 보통 전체색인 쿼리에서 where 조건에 조회할 PK값을 넣어 데이터 색인/수집을 진행한다.
- 증분색인 방법에 태워 별도의 작업 없이 queue에 update action 값과 대상 PK값을 기록하여 메뉴얼 색인 작업을 대신 할 수도 있다.
2. 역색인(Inverted indexing)
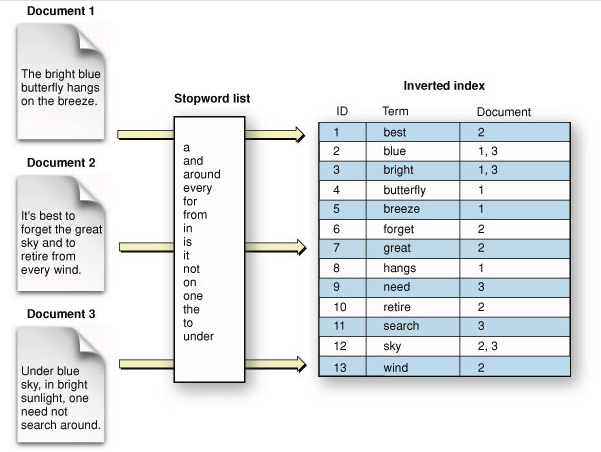
역색인이란 어떠한 데이터를 색인할 때 단어 기준으로 색인을 수행하는 것이다. 이는 데이터 색인 시 인간의 사고와 좀 더 가깝게 체계를 구성한 것이다. 색인이 문서들에서 키워드를 뽑아낸다면, 역색인은 뽑아낸 키워드들을 바탕으로 그 키워드가 포함된 문서를 찾아나간다. 여기서 BTree 또는 Trie, 해싱 방식의 자료구조를 사용한다.
색인어를 추출 및 키워드를 찾는 과정
과정
- 원문에서 색인어를 추출한다
- 원문에서 각 문서당 색인어 숫자를 센다
- 키워드 순서로 정렬한다
- 키워드당 역색인 벡터를 만든다(단어 -> 문장의 Index)
- 역색인 벡터를 압축한다.
- 키워드당 검색 순위를 미리 만든다.
- Lexicon을 Hashing, Btree, TRIE등의 자료구조로 색인한다.
- 키워드가 요청되면 정리된 자료구조에서 찾는다.
참조

오늘도 공부 📖🌙