동적 계획법
복잡한 문제를 여러 개의 간단한 문제로 분리하여 부분의 문제들을 해결함으로써 최종적으로 복잡한 문제의 답을 구하는 방법
특정한 알고리즘이 아닌 하나의 문제해결 패러다임
DP를 쓰는 이유
왜 DP를 사용할까?
사실 일반적인 재귀(Naive Recursion) 방식 또한 DP와 매우 유사하다.
큰 차이점은 일반적인 재귀를 단순히 사용 시 동일한 작은 문제들이 여러 번 반복 되어 비효율적인 계산될 수 있다는 것이다.
예를 들어, 동적 계획법의 가장 대표적인 문제인 피보나치 수열을 살펴보자.
피보나치 수열은 아래와 같다.
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144 ...
피보나치 수를 구하고 싶을 때 재귀로 함수를 구성하면 어떻게 될까?
return f(n) = f(n-1) + f(n-2)
- 피보나치 수열 공식
D[N] = D[N-1] + D[N-2] // N번째 수열 = N-1번째 수열 + N-2번째 수열
그런데 f(n-1), f(n-2)에서 각 함수를 한 번씩 호출하면 동일한 값을 2번씩 구하게 되고, 이로 인해 100번째 피보나치 수를 구하기 위해 호출되는 함수의 횟수는 기하급수 적으로 증가한다.
왜냐하면, f(n-1)에서 한 번 구한 값을 f(n-2)에서 또 다시 같은 값을 구하는 과정을 반복하게 되기 때문이다.
아래의 그림처럼 반복되는 계산을 또 하게 된다.
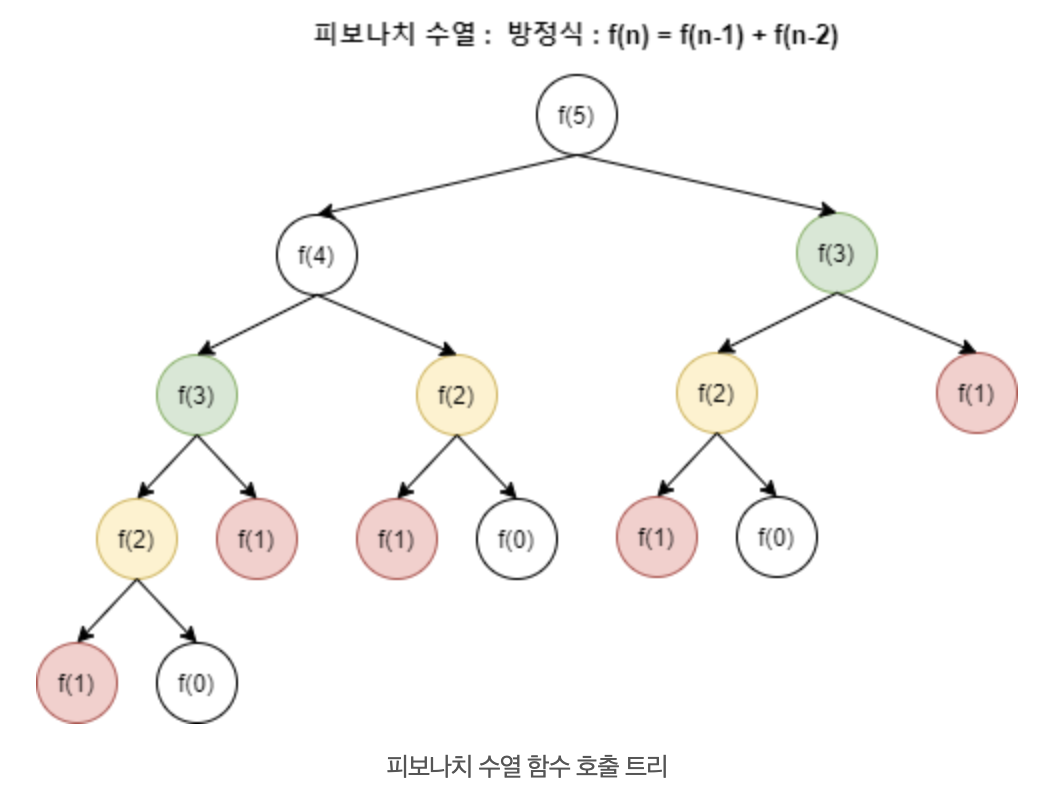
한 번 구한 작은 문제의 결과 값을 저장해두고 재사용 한다면 어떨까?
앞에서 계산된 값을 다시 계산할 반복할 필요가 없어지는것이다.
즉, 매우 효율적으로 문제를 해결할 수 있게 된다. 시간복잡도를 기준으로 아래와 같이 개선이 가능하다.
DP의 사용 조건
DP가 적용되기 위해서는 2가지 조건을 만족해야 한다.
1) Overlapping Subproblems(겹치는 부분 문제)
2) Optimal Substructure(최적 부분 구조)
① Overlapping Subproblems
DP는 기본적으로 문제를 나누고 그 문제의 결과 값을 재활용해서 전체 답을 구한다. 그래서 동일한 작은 문제들이 반복하여 나타나는 경우에 사용이 가능하다.
즉, DP는 부분 문제의 결과를 저장하여 재 계산하지 않을 수 있어야 하는데, 해당 부분 문제가 반복적으로 나타나지 않는다면 재사용이 불가능하니 부분 문제가 중복되지 않는 경우에는 사용할 수 없다.
예를 들어, 이진 탐색(참고)와 피보나치 수열의 경우를 비교해 보자.
이진 탐색은 특정 데이터를 정렬된 배열 내에서 그 위치를 찾기 때문에 그 위치를 찾은 후 바로 반환할 뿐 그것을 재사용하는 과정을 거치지 않는다. 반면, 피보나치 수열은 f(n) = f(n-1) + f(n-2) 인데, 아래와 같은 트리 구조로 함수가 호출되게 된다.
다시 한 번, 앞에서 본 그림을 보자.
f(3), f(2), f(1)과 같이 동일한 부분 문제가 중복되어 나타난다. 그러므로 우리는 1회 계산했을 때, 저장된 값을 재활용할 수 있게 되는 것이다.
② Optimal Substructure(최적 부분 구조)
부분 문제의 최적 결과 값을 사용해 전체 문제의 최적 결과를 낼 수 있는 경우를 의미한다. 그래서 특정 문제의 정답은 문제의 크기에 상관없이 항상 동일하다!
만약, A - B까지의 가장 짧은 경로를 찾고자 하는 경우를 예시로 할 때, 중간에 X가 있을 때, A - X / X - B가 많은 경로 중 가장 짧은 경로라면 전체 최적 경로도 A - X - B가 정답이 된다.
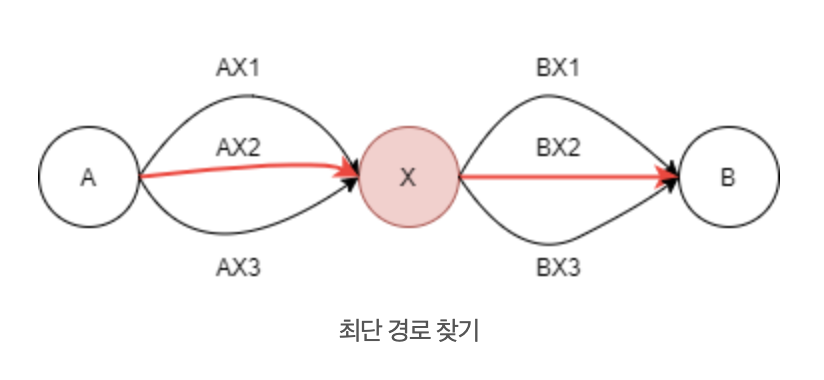
위의 그림에서 A - X 사이의 최단 거리는 AX2이고 X - B는 BX2이다. 전체 최단 경로는 AX2 - BX2이다. 다른 경로를 택한다고 해서 전체 최단 경로가 변할 수는 없다.
이와 같이, 부분 문제에서 구한 최적 결과가 전체 문제에서도 동일하게 적용되어 결과가 변하지 않을 때 DP를 사용할 수 있게 된다.
피보나치 수열도 동일하게 이전의 계산 값을 그대로 사용하여 전체 답을 구할 수 있어 최적 부분 구조를 갖고 있다.
DP 사용하기
DP는 특정한 경우에 사용하는 알고리즘이 아니라 하나의 방법론이므로 다양한 문제해결에 쓰일 수 있다.
그래서 DP를 적용할 수 있는 문제인지를 알아내는 것부터 코드를 짜는 과정이 난이도가 쉬운 것부터 어려운 것까지 다양하다.
일반적으로 DP를 사용하기 전에는 아래의 과정을 거쳐 진행할 수 있다.
1) DP로 풀 수 있는 문제인지 확인한다 : 겹치는 부분 문제 , 최적 부분 구조
2) 문제의 변수 파악
3) 변수 간 관계식 만들기(점화식)
4) 메모하기(memoization or tabulation) : 메모이제이션기법
5) 기저 상태 파악하기
6) 구현하기 : 톱-다운 방식, 바텀-업 방식
① DP로 풀 수 있는 문제인지 확인
애초에 이 부분 부터 해결이 매우 어렵다. 우선 DP의 조건 부분에서 써내렸듯이, 현재 직면한 문제가 작은 문제들로 이루어진 하나의 함수로 표현될 수 있는지를 판단해야 한다.
즉, 위에서 쓴 조건들이 충족되는 문제인지를 한 번 체크해보는 것이 좋다.
보통 특정 데이터 내 최대화 / 최소화 계산을 하거나 특정 조건 내 데이터를 세야 한다거나 확률 등의 계산의 경우 DP로 풀 수 있는 경우가 많다.
② 문제의 변수 파악
DP는 현재 변수에 따라 그 결과 값을 찾고 그것을 전달하여 재사용하는 것을 거친다. 즉, 문제 내 변수의 개수를 알아내야 한다는 것. 이것을 영어로 "state"를 결정한다고 한다.
예를 들어, 피보나치 수열에서는 n번째 숫자를 구하는 것이므로 n이 변수가 된다. 그 변수가 얼마이냐에 따라 결과값이 다르지만 그 결과를 재사용하고 있다.
또한, 문자열 간의 차이를 구할 때는 문자열의 길이, Edit 거리 등 2가지 변수를 사용한다. 해당 문제를 몰라도 된다.
또, 유명한 Knapsack 문제에서는 index, 무게로 2가지의 변수를 사용한다. 이와 같이 해당 문제에서 어떤 변수가 있는지를 파악해야 그에 따른 답을 구할 수 있다.
③ 변수 간 관계식 만들기
변수들에 의해 결과 값이 달라지지만 동일한 변수값인 경우 결과는 동일하다. 또한 우리는 그 결과값을 그대로 이용할 것이므로 그 관계식을 만들어낼 수 있어야 한다.
그러한 식을 점화식이라고 부르며 그를 통해 우리는 짧은 코드 내에서 반복/재귀를 통해 문제가 자동으로 해결되도록 구축할 수 있게 된다.
예를 들어 피보나치 수열에서는 f(n) = f(n-1) + f(n-2) 였다. 이는 변수의 개수, 문제의 상황마다 모두 다를 수 있다.
④ 메모하기
변수 간 관계식까지 정상적으로 생성되었다면 변수의 값에 따른 결과를 저장해야 한다. 이것을 메모한다고 하여 Memoization이라고 부른다.
변수 값에 따른 결과를 저장할 배열 등을 미리 만들고 그 결과를 나올 때마다 배열 내에 저장하고 그 저장된 값을 재사용하는 방식으로 문제를 해결해 나간다.
이 결과 값을 저장할 때는 보통 배열을 쓰며 변수의 개수에 따라 배열의 차원이 1~3차원 등 다양할 수 있다.
⑤ 기저 상태 파악하기
여기까지 진행했으면, 가장 작은 문제의 상태를 알아야 한다. 보통 몇 가지 예시를 직접 손으로 테스트하여 구성하는 경우가 많다.
피보나치 수열을 예시로 들면, f(0) = 0, f(1) = 1과 같은 방식이다. 이후 두 가지 숫자를 더해가며 값을 구하지만 가장 작은 문제는 저 2개로 볼 수 있다.
해당 기저 문제에 대해 파악 후 미리 배열 등에 저장해두면 된다. 이 경우, 피보나치 수열은 매우 간단했지만 문제에 따라 좀 복잡할 수 있다.
⑥ 구현하기
개념과 DP를 사용하는 조건, DP 문제를 해결하는 과정도 익혔으니 실제로 어떻게 사용할 수 있는지를 알아보고자 한다. DP는 2가지 방식으로 구현할 수 있다.
1) Bottom-Up (Tabulation 방식) - 반복문 사용
2) Top-Down (Memoization 방식) - 재귀 사용
구현 방법
① Bottom-Up 방식 (Tabulation 방식)
이름에서 보이듯이, 아래에서 부터 계산을 수행 하고 누적시켜서 전체 큰 문제를 해결하는 방식이다.
메모를 위해서 dp라는 배열을 만들었고 이것이 1차원이라 가정했을 때, dp[0]가 기저 상태이고 dp[n]을 목표 상태라고 하자. Bottom-up은 dp[0]부터 시작하여 반복문을 통해 점화식으로 결과를 내서 dp[n]까지 그 값을 전이시켜 재활용하는 방식이다.
왜 Tabulation?
사실 위에서 메모하기 부분에서 Memoization이라고 했는데 Bottom-up일 때는 Tabulation이라고 부른다.
왜냐면 반복을 통해 dp[0]부터 하나 하나씩 채우는 과정을 "table-filling" 하며, 이 Table에 저장된 값에 직접 접근하여 재활용하므로 Tabulation이라는 명칭이 붙었다고 한다.
사실상 근본적인 개념은 결과값을 기억하고 재활용한다는 측면에서 메모하기(Memoization)와 크게 다르지 않다.
② Top-Down 방식 (Memoization 방식)
이는 dp[0]의 기저 상태에서 출발하는 대신 dp[n]의 값을 찾기 위해 위에서 부터 바로 호출을 시작하여 dp[0]의 상태까지 내려간 다음 해당 결과 값을 재귀를 통해 전이시켜 재활용하는 방식이다.
피보나치의 예시처럼, f(n) = f(n-2) + f(n-1)의 과정에서 함수 호출 트리의 과정에서 보이듯, n=5일 때, f(3), f(2)의 동일한 계산이 반복적으로 나오게 된다.
이 때, 이미 이전에 계산을 완료한 경우에는 단순히 메모리에 저장되어 있던 내역을 꺼내서 활용하면 된다. 그래서 가장 최근의 상태 값을 메모해 두었다고 하여 Memoization 이라고 부른다.
위 방법을 코드를 통해서 더 직관적으로 이해해보자.(아래에서는 숫자 크기를 감안해 30번째 피보나치 수열 계산)
public class Fibonacci{
// DP 를 사용 시 작은 문제의 결과값을 저장하는 배열
// Top-down, Bottom-up 별개로 생성하였음(큰 의미는 없음)
static int[] topDown_memo;
static int[] bottomup_table;
public static void main(String[] args){
int n = 30;
topDown_memo = new int[n+1];
bottomup_table = new int[n+1];
long startTime = System.currentTimeMillis();
System.out.println(naiveRecursion(n));
long endTime = System.currentTimeMillis();
System.out.println("일반 재귀 소요 시간 : " + (endTime - startTime));
System.out.println();
startTime = System.currentTimeMillis();
System.out.println(topDown(n));
endTime = System.currentTimeMillis();
System.out.println("Top-Down DP 소요 시간 : " + (endTime - startTime));
System.out.println();
startTime = System.currentTimeMillis();
System.out.println(bottomUp(n));
endTime = System.currentTimeMillis();
System.out.println("Bottom-Up DP 소요 시간 : " + (endTime - startTime));
}
// 단순 재귀를 통해 Fibonacci를 구하는 경우
// 동일한 계산을 반복하여 비효율적으로 처리가 수행됨
public static int naiveRecursion(int n){
if(n <= 1){
return n;
}
return naiveRecursion(n-1) + naiveRecursion(n-2);
}
// DP Top-Down을 사용해 Fibonacci를 구하는 경우
public static int topDown(int n){
// 기저 상태 도달 시, 0, 1로 초기화
if(n < 2) return topDown_memo[n] = n;
// 메모에 계산된 값이 있으면 바로 반환!
if(topDown_memo[n] > 0) return topDown_memo[n];
// 재귀를 사용하고 있음!
topDown_memo[n] = topDown(n-1) + topDown(n-2);
return topDown_memo[n];
}
// DP Bottom-Up을 사용해 Fibonacci를 구하는 경우
public static int bottomUp(int n){
// 기저 상태의 경우 사전에 미리 저장
bottomup_table[0] = 0; bottomup_table[1] = 1;
// 반복문을 사용하고 있음!
for(int i=2; i<=n; i++){
// Table을 채워나감!
bottomup_table[i] = bottomup_table[i-1] + bottomup_table[i-2];
}
return bottomup_table[n];
}
}
/*
결과
832040
일반 재귀 소요 시간 : 9
832040
Top-Down DP 소요 시간 : 0
832040
Bottom-Up DP 소요 시간 : 0
*/5. 기타 내용
Q. 두 가지 방법(Top-Down vs Bottom-Up) 중 더 나은 것이 있는지, 하나만 가능한 경우가 있는지?
두 방법 중 어느 것이 시간적으로 더 효율이 있는지 묻는 데 그 답은 '알수 없다'이다. 실제로 재귀는 내부 스택을 만들고 함수를 호출하는 과정이 더 있어보여서 반복이 더 빠를 것 같다고 느낄 수 있다.
하지만, Top-Down을 통해 문제를 풀어가는 경우에는 점화식에 따라 불 필요한 계산을 오히려 Bottom-Up보다 덜하는 경우가 있기 떄문에 궁극적으로는 알 수 없다.(이 경우는 추후에 문제를 풀어가며 그 경우를 찾아 본다.)
그 외, Top-Down은 재귀를 통해 내려가니까 Stack이 쌓여 StackOverflow 같은 에러가 발생하지 않느냐라고 하는데, 우리가 해결해야 하는 수준의 문제에서는 그러한 경우는 거의 없다.
(근데 Python은 제대로 해도 StackOverflow가 나오는 경우가 많다. 그러면 Bottom-up으로 풀면 된다.)
혹시나 발생했다면 점화식을 잘못 만들었을 가능성이 높으니 다시 한 번 시도해보자.
책에서는 바텀-업이 좀 더 안전하다고한다.
-> 톱-다운 방식은 재귀형태이기때문에 재귀 깊이가 매우 깊어질 경우 런타임 에러가 발생할 수 있다고 한다.
또한, 2가지 방법 중 2가지를 모두 사용하지는 못하고 하나만 사용할 수 있는 경우가 있느냐는 질문에는 '있다' 라고 할 수 있다. 하지만 그것은 DP에 익숙해지고 나서 경험적으로 많이 알아낼 수 있다.
Q. Divide and Conquer(분할 정복)와 차이점은?
분할 정복과 동적 프로그래밍은 주어진 문제를 작게 쪼개서 하위 문제로 해결하고 연계적으로 큰 문제를 해결한다는 점은 같다.
차이점은, 분할 정복은 분할된 하위 문제가 동일하게 중복이 일어나지 않는 경우에 쓰며, 동일한 중복이 일어나면 동적 프로그래밍을 쓴다는 것이다.
예를 들어, 병합 정렬을 보자.
병합 정렬을 수행 시에 작은 하위 문제로 쪼개지지만 중복하여 하위 문제가 발생하지 않는다. 무슨 말이냐면, 분할된 부분 부분은 모두 독립적이고, 동일한 부분을 중복하지 않는다는 것이다!
중복되는 경우는 어떤 것인가? 피보나치 수열을 생각해보자.
피보나치 수열은 fn=fn−1+fn−2라는 수식을 갖는다.
즉, n이 어떤 수가 되던, n-1번째 수와 n-2번째 수를 더해야 한다.
즉, n=5일 때, n-1은 4이고, n-2는 3인데, 3을 구하기 위해선 n-2가 1인 경우까지 하위 문제로 내려가야 한다. 즉, n이 어떤 수이든, 그 하위 수를 구하는 부분은 중복해서 나타난다!
그래서 병합 정렬은 분할 정복으로, 피보나치 수열은 동적 프로그래밍으로 해결이 가능한 것이다.
참고
https://hongjw1938.tistory.com/47
Do it! 알고리즘 코딩 테스트 자바 편
