유니온 파인드
-
일반적으로 여러 노드가 있을 때 특정 2개의 노드를 연결해 1개의 집합으로 묶는 union 연산과 두 노드가 같은 집합에 속해 있는지를 확인하는 find 연산으로 구성되어있는 알고리즘
-
그래프 알고리즘의 일종으로서 상호 배타적 집합, Disjoint-set 이라고도 한다.
-
서로소 집합을 구하는 알고리즘이다. 서로소 집합은 공통 원소가 없는 집합들을 뜻한다.
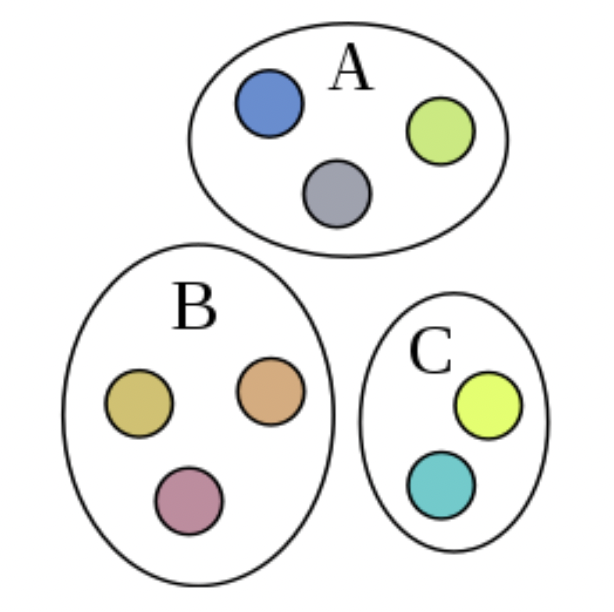
위 그림에서 8개 원소가 있고, 서로소 집합은 3개이다.
다음과 같은 유형에서 사용하면 된다. (물론 DFS/BFS로도 풀이가 가능하다!)
- 연결 정보가 주어졌을 때 2개의 원소는 서로 같은 집합에 속해 있는가?
- 연결 정보가 주어졌을 때 독립적인 섬의 갯수는 몇개인가?
Union-Find 관련 문제는 해당 원소들의 부모 정보들을 저장, 비교, 업데이트를 통해서 해결한다.
따라서 각각 원소들의 부모 정보에 대해서 특별히 신경써주면 된다.
핵심이론
union, find 연산을 완벽히 이해하는 것이 핵심!
-
union 연산
각 노드가 속한 집합을 하나로 합치는 연산
노드 a,b가 a∈A, b∈B 일 때, union(a,b)는 AUB를 말한다. -
find 연산
특정 노드 a에 관해 a가 속한 집합의 대표 노드를 반환하는 연산
노드 a가 a∈A일 때, find(a)는 A 집합의 대표 노드를 반환한다
->해당 원소들의 parent를 비교하고 연결의 참/거짓을 확인한다.
원리 이해하기
유니온 파인드 알고리즘 구현방법을 알아보자.
- 유니온 파인드를 표현하는 일반적인 방법은 1차원 배열을 이용하는것이다.
처음에는 노드가 연결되어있지 않으므로 각 노드가 대표노드이다. 따라서 배열은 자신의 인덱스 값으로 초기화한다.
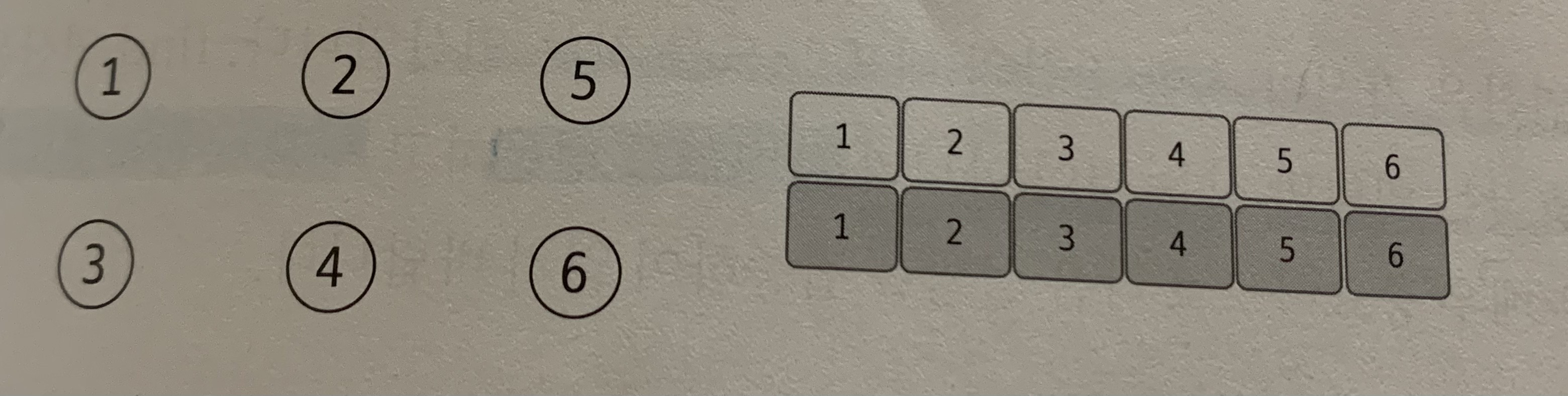
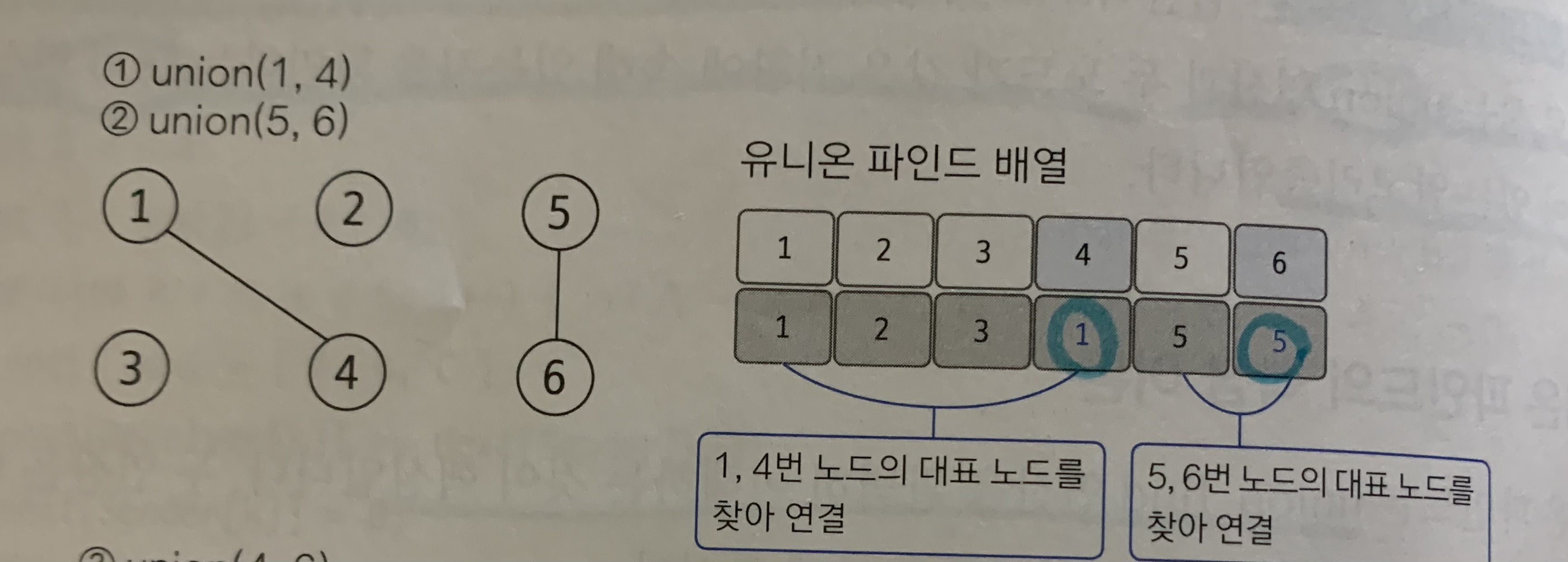
- 2개의 노드를 선택해 각각의 대표 노드를 찾아 연결하는 union 연산을 수행한다.
예시를 보면 1,4와 5,6을 union연산으로 연결한다 : 배열[4] = 1, 배열[6] = 5로 업데이트
업데이트의 의미를 이해해야한다!
예시로 살펴보자.
1은 대표 노드, 4는 자식노드로 union연산을 하므로 배열[4]의 대표 노드를 1로 설정한것이다.
즉, 자식 노드로 들어가는 노드값 4를 대표 노드값 1로 변경.
그 결과 각각 집합이었던 1,4는 하나로 합쳐진다.
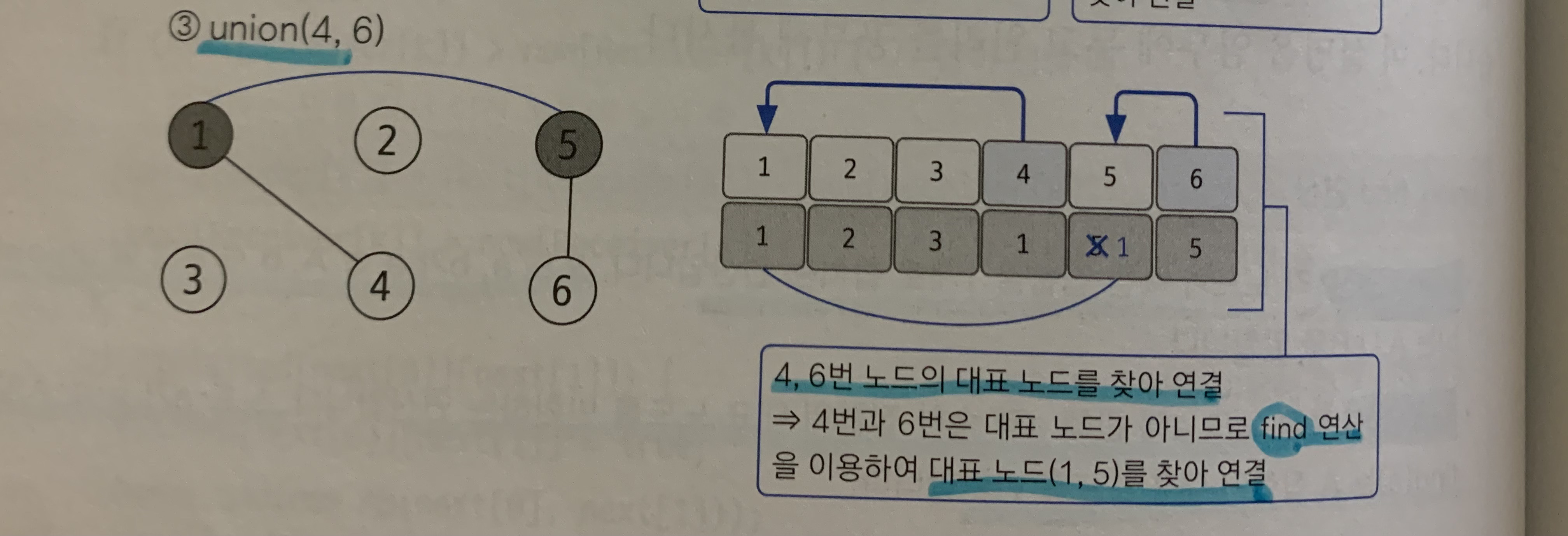
union(4,6)으로 4와 6을 연결해보자.
근데 4,6은 대표 노드가 아니다. 그래서
각 노드의 대표 노드를 찾아 올라간 다음 그 대표 노드를 연결한다. 지금의 경우 4의 대표 노드 1, 6의 대표노드 5를 연결한 것이다.
- find 연산은 자신이 속한 집합의 대표 노드를 찾는 연산이다.
단순히 대표 노드를 찾는 역할만 하는 것이 아니라 그래프를 정돈하고, 시간 복잡도를 더 좋게한다.
find연산의 작동 원리
- 대상 노드 배열에 index값과 value값이 동일한지 확인한다.
- 동일하지 않으면 value값이 가리키는 index 위치로 이동한다.
- 이동 위치의 index값과 value값이 같을 때까지 과정1~2를 반복한다. 반복이므로 이 부분은 재귀 함수로 구현한다.
- 대표 노드에 도달하면 재귀 함수를 빠져나오면서 거치는 모든 노드값을 루트 노드값으로 변경한다.
find연산은 잘 생각하면 시간 복잡도가 줄어드는 효과를 얻는다.
연산을 할 때 거치는 노드들이 대표 노드와 바로 연결되는 형태로 변경되는 것을 알 수 있기때문에, 이렇게되면 추후 노드와 관련된 find 연산 속도가 O(1)로 변경된다.
다음 예시를 보자.
한번의 find연산을 이용해 모든 노드가 루트 노드에 직접 연결되는 형태로 변경되는 것을 볼 수 있다.
이러한 형태로 변경되면 이후 find연산이 진행될 때 경로 압축의 효과가 나타난다.
예를 들어, 이후 find(4) 연산을 수행하면 한 번의 이동으로 바로 대표 노드를 찾을 수 있다.
유니온 파인드 구현
구현은 간단한 트리를 통해서 이루어진다.
그 전에 왜 배열은 이용하지 않는지, 트리를 사용하였을 때의 장점은 무었인지에 대해 알아보자!
-배열로 표현하기
가장 간단한 방법으로 1차원 배열로 집합을 표현한다.
예를 들어
'Array[i] : i번 원소가 속하는 집합의 번호'라 하면
- 초기화 : Array[i] = i와 같이 각자 다른 집합 번호로 초기화 한다.
- Union (합치기) 연산 : 두 집합을 합치기 위해 배열의 모든 원소를 순회 하면서 하나의 집합 번호를 나머지 한개의 집합 번호로 교체한다.
아래의 그림은 3번 집합을 2번 집합으로 합치는 과정입니다. O(N)
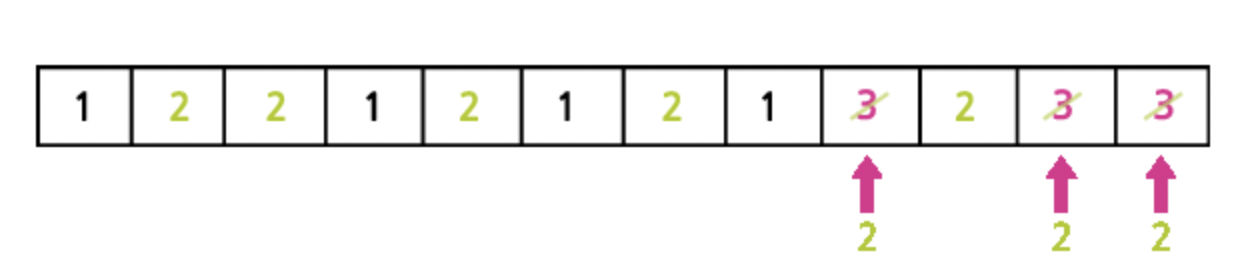
- Find (찾기) 연산 : 한 번만에 원소가 속하는 집합 번호를 알 수 있습니다. O(1)
배열로 Union-Find를 구현 할 수는 있지만, 위에서 보았듯 Union 연산 수행 시 배열의 모든 원소를 순회해야 하기 때문에 시간복잡도가 O(N) 이 됩니다.
물론 Find 연산은 빠르지만, Union 연산 수행 횟수가 많기 때문에 우리는 더 빠른 Union 연산을 원합니다.
더 좋은 방법은 없을까요?
-트리로 표현하기
바로 트리로 Union-Find 를 구현하면 배열보다 빠르게 Union 연산을 수행할 수 있다.
트리 구조로 표현하기 위해 필요한 기본적인 내용을 먼저 알아보자.
Base 1
한 집합에 속하는 원소들을 하나의 트리로 묶어주기 때문에, 자료구조는 아래 그림과 같이 트리 들의 집합으로 표현됩니다.
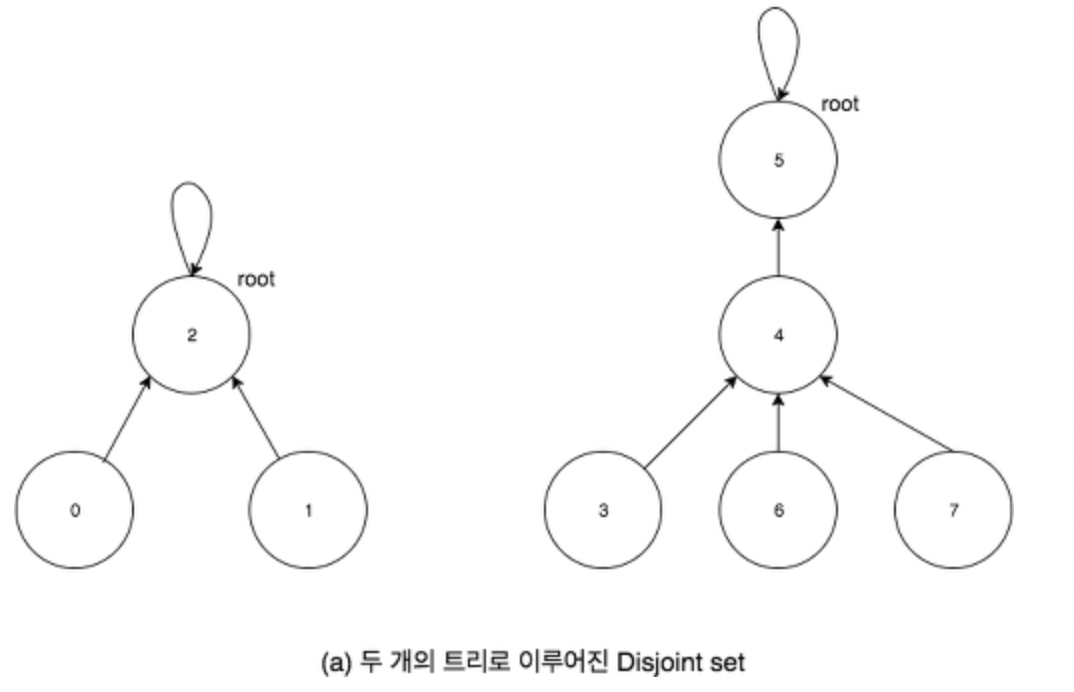
Base 2
트리 구조 에는 트리의 대표 노드 라고도 볼 수 있는 루트 노드 가 존재 하므로, 각 원소가 속하는 집합 번호를 바로 이 루트 노드의 원소로 정합니다.
Base 3
Union 연산을 수행하기 위해서는 두 원소가 같은 집합에 속하는지를 먼저 확인한 후, 다른 집합에 속할 때만 합쳐야 합니다.
같은 집합에 속한다는 뜻은, 같은 루트 노드를 가진다는 말과 대응되므로 어떤 원소의 루트 노드 를 찾는 Find 연산을 지원해야 합니다.
Base 4
이러한 Find 연산을 지원하기 위해서 모든 자식 노드가 부모에 대한 포인터 정보를 가지고 있도록 합니다. 이러한 설정은 가진 정보를 바탕으로 포인터를 따라가 결과적으로 최종 부모인 루트 노드 가 무었인지 찾을 수 있게 됩니다.
단, 부모 노드에서 자식 노드로 내려가는 일은 발생하지 않기 때문에, 부모가 자식에 대한 포인터 정보는 가질 필요가 없습니다.
✏️이제 union find 연산을 알아보자.
-
초기화 : 모두 각자 다른 집합이 됩니다. 각 노드는 모두 루트 노드 가 되며 N 개의 루트 노드를 생성하고 자기 자신을 가리키는 포인터를 가지도록 설정합니다.
-
Union (합치기) 연산 : 각 트리의 루트를 찾은 뒤, 다르다면 하나를 다른 한쪽의 자손으로 넣어 두 트리를 합칩니다.
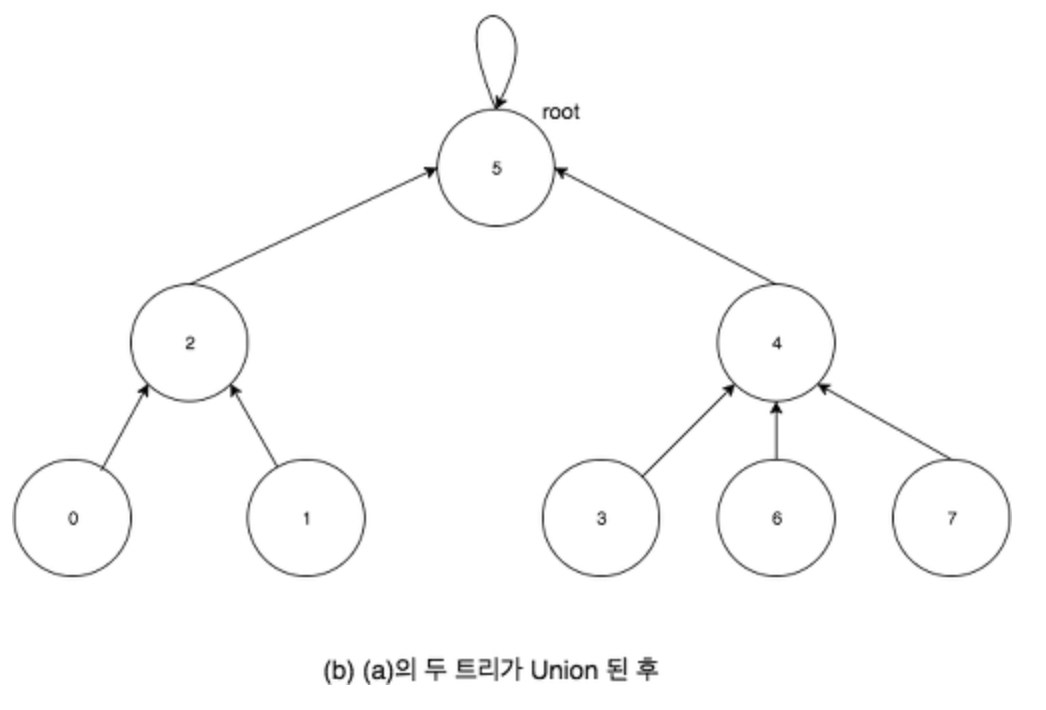
-
Find (찾기) 연산 : 각 노드에 저장된 포인터 정보를 따라가 주어진 원소가 포함된 트리의 루트 노드를 찾습니다. ( 트리의 높이와 시간복잡도가 비례 )
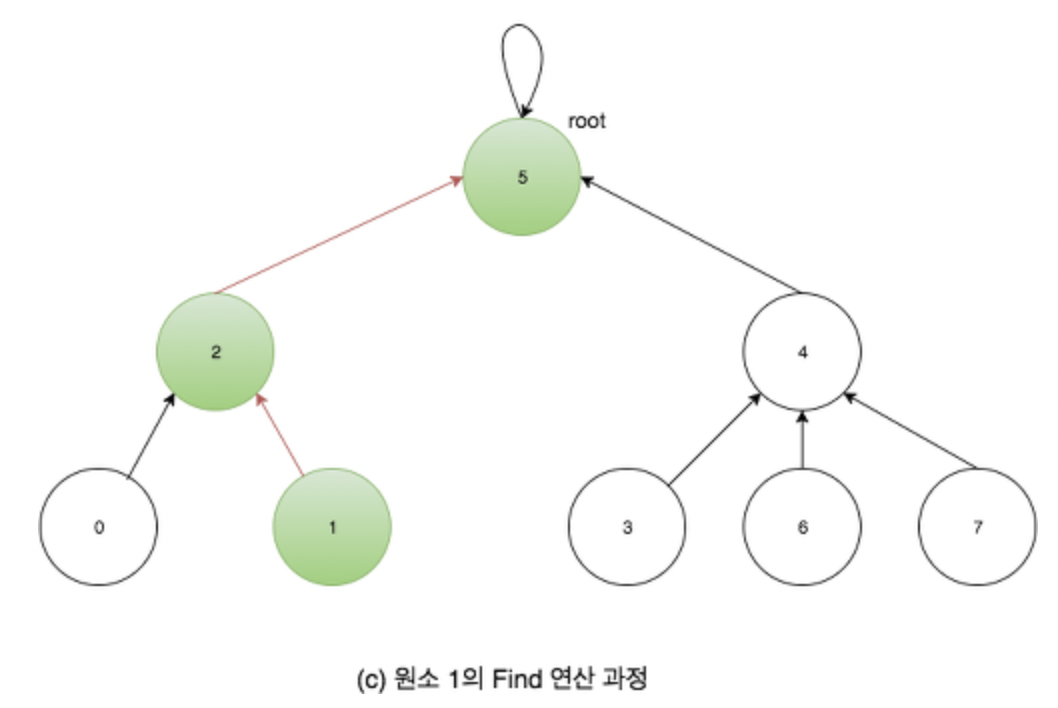
Find 연산 수행 시 걸리는 시간이 트리의 높이 와 비례하게 되고, Union 연산 수행시간 역시 Find 연산 수행 시간이 지배하게 됩니다.
이처럼 Union 연산시간 복잡도가 배열로 나타내었을 때의 보다 줄어 들었음을 알 수 있습니다.
-최적화하기
트리로 구현하는 방법에는 큰 문제점이 발생할 수 있습니다.
바로 최악의 경우 완전히 비대칭적인 트리, 즉 연결 리스트 형태가 되어버릴 수 있다는 것입니다.
예를 들어 두 트리 a 와 b 를 합칠 때, a 의 루트 노드를 항상 b 의 루트 노드의 자식으로 넣는다고 가정한다면, 다음과 같이
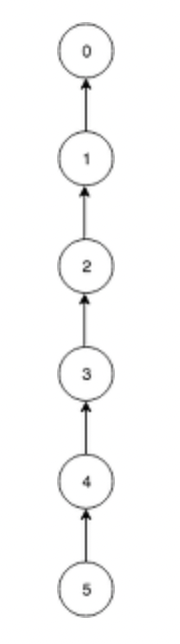
원소의 갯수가 N일때, 트리의 높이가 N-1인, 트리의 장점을 전혀 살릴 수 없는 연결 리스트 형태가 되고 맙니다.
이렇게 되면 Union 연산도, Find 연산도 수행시간이 O(N)이 되어버려 배열로 구현했을 때 보다도 효율이 나빠지게 됩니다.
이 문제는 두 트리를 합칠 때, 항상 높이가 더 낮은 트리를 높은 트리 밑에 넣음 으로써 해결가능 합니다. 이렇게 되면 트리의 높이가 크게 높아지는 상황을 방지 할 수 있습니다.
이러한 최적화를 union-by-rank 라 하며, 여기서 rank 는 해당 트리의 높이를 저장합니다.
-최적화 하기
위의 코드에서 경로 압축 최적화 ( path compression ) 과정도 함께 추가 되었는데, 이를 수행하면 다음 그림과 같습니다.
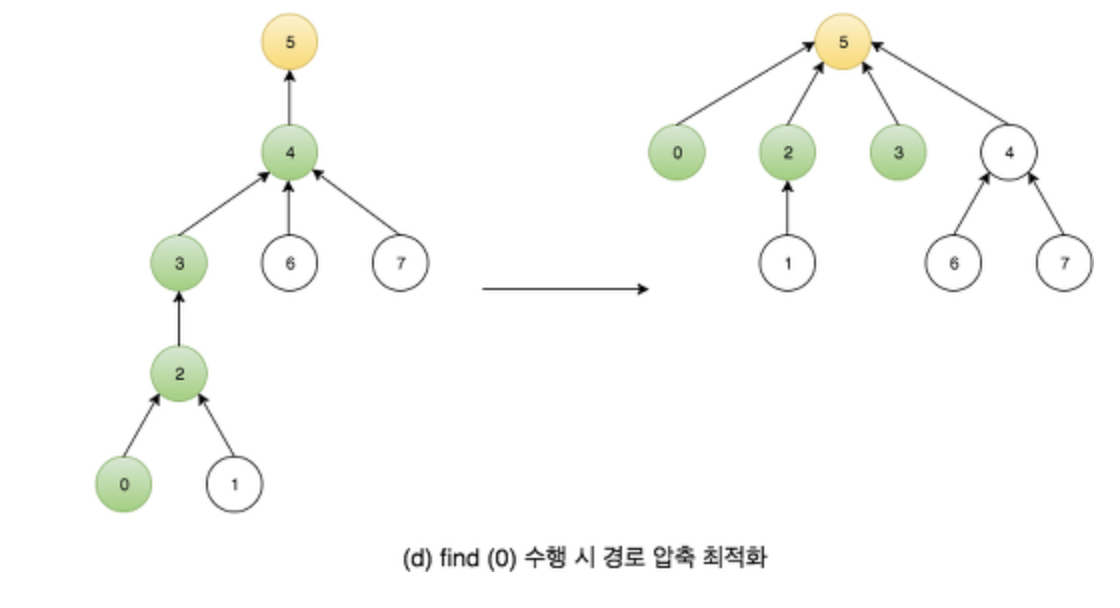
구현!
parent[i] 를 i 노드의 부모 노드 라고 정의하고 초기화 해줍니다.
parent[i] = i 인 경우, 루트노드 임을 의미합니다.
int parent[MAX_SIZE];
for (int i=0; i<MAX_SIZE; i++)
parent[i] = i;- find 함수 구현
int find(int x){
if (x==parent[x]){
return x;
}
else {
return find[parent[x]];
}
}x == parent[x] 라면 부모노드가 자기자신, 즉 본인이 루트노드라는 의미입니다.
따라서 이 자체를 그대로 return 해줍니다.
그렇지 않다면 재귀적으로 루트를 찾아 반환해줍니다.
하지만! 이렇게 find 를 구현한 경우 문제점이 발생합니다.
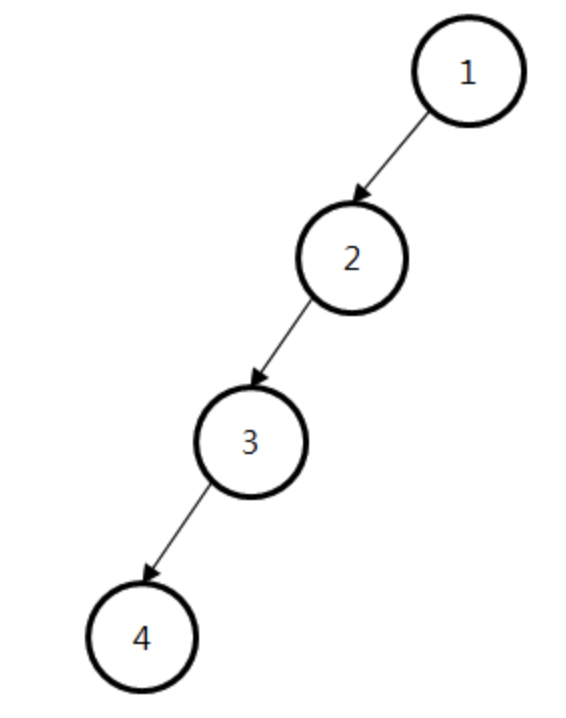
위 그림과 같이 한 쪽으로만 tree 가 치우져진 경우, find 함수가 루트노드를 찾는데 O(N) 의 시간복잡도가 걸려 tree 로 구현하는 이점이 사라집니다.
이를 해결하기 위해서 다음과 같이 개선할 수 있습니다.
int find(int x){
if (x==parent[x]){
return x;
}
else{
int y = find(parent[x]);
parent[x] = y;
return y;
}
}루트노드인 y 를 찾았으면 x 의 부모를 바로 루트노드로 바꿔주어 아래와 같이 바꿔줍니다.
결과적으로 아래 그림과 같이 바꿔 find 의 효율을 올려줄 수 있습니다.
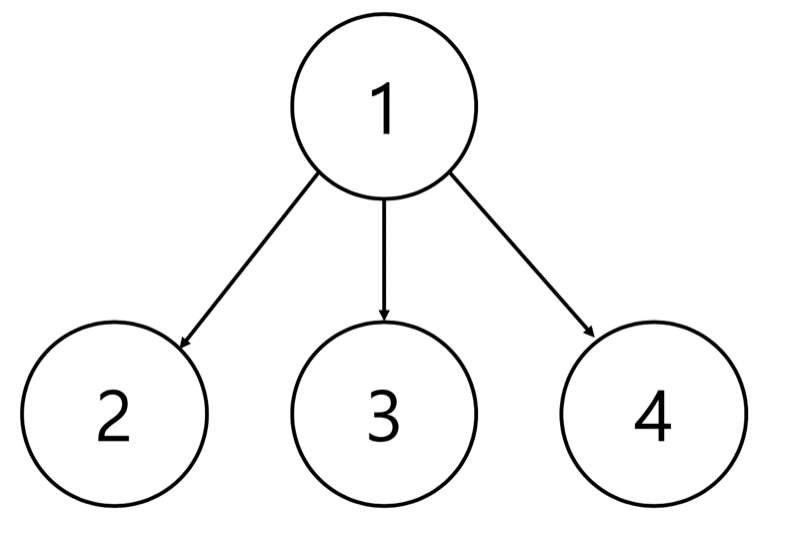
- union 함수 구현
union 함수는 매개변수로 두 개의 값을 받습니다. 두 노드가 각 포함되어있는 집합을 합쳐줘야 하는데 편의상 union(x,y) 에 대해 y 의 집합을 x 의 집합에 합치도록 하겠습니다.
즉, y 의 parent 가 x 가 되는 것이죠.
void union(int x,int y){
x = find(x);
y = find(y);
if (x!=y)
parent[y] = x;
}find 를 통해 각각의 root 를 찾아준 후, 두 집합의 root 가 다른 경우 y 의 부모노드를 x 로 바꿔주도록 합니다.
하지만 이 경우도 문제점이 발생합니다.
높이가 더 높은 트리가 높이가 낮은 트리 밑으로 들어가게 되면 트리가 점점 깊어질 위험이 있습니다.
따라서 트리의 높이가 낮은 트리가 높은 트리 밑으로 들어가야 하는데 이를 위해서는 트리의 높이를 기록해두어야 합니다.
트리의 높이를 기억하는 rank 라는 배열을 선언하고 초기화 해줍니다.
int rank[MAX_SIZE];
for (int i=0; i<MAX_SIZE; i++)
rank[i] = 1;이제 union 할 시 크기를 비교해주고 합쳐줄 경우에는 크기를 갱신해주어야합니다.
void union(int x, int y){
x = find(x);
y = find(y);
if (x == y)
return;
if (rank[x] > rank[y]){
parent[y] = x;
rank[x] += rank[y];
}
else {
parent[x] = y;
rank[y] += rank[x];
}
}Weighted Union Find
위에서 살펴본 경우, parent 배열도, size 배열도 존재하여 메모리를 두 배로 사용하게 됩니다.
그래서 이를 개선하고자 Weighted Union Find 방법이 고안되었습니다.
이는 find 함수도 약간 바뀌므로 전체 코드로 알아보겠습니다.
우선 parent 배열은 음수일 경우, 부모노드로서 음수의 절대값은 size가 되고, 양수일 경우에는 부모노드를 가르키게 됩니다.
예를 들어서 parent[2] = -3 일 경우 2번 노드 밑에 두 개의 노드가 더 있어서 총 3개의 노드가 존재한다는 의미이고, parent[3] = 5 일 경우에는 3번 노드의 부모가 5번 노드라는 의미입니다.
int parent[MAX_SIZE];
for (int i=0; i<MAX_SIZE; i++)
parent[i] = -1;
int find(int x){
if (parent[x] < 0){
return x;
}
else{
int y = find(parent[x]);
parent[x] = y;
return y;
}
}
void union(int x, int y){
x = find(x);
y = find(y);
if (x == y)
return;
// parent[x], parent[y] 값은 음수이므로 값이 작은 경우가 더 높이가 큰 노드이다.
if (parent[x] < parent[y]){
parent[x] += parent[y]; // 꼭 값을 더해준 후
parent[y] = x; // 값 업데이트 해야함! 선후관계 중요! -> 선후관계 바뀌면 스택 오버플로우 에러 남
}
else {
parent[y] += parent[x];
parent[x] = y;
}
}정리
위의 최적화 과정을 모두 적용한 Disjoint Set 의 연산 수행시간은 분석하기 아주 어렵습니다. 왜냐하면 Find 연산을 호출 할 때마다 수행시간이 달라지기 때문입니다. ( 트리의 높이 변화에 의해 )
참고한 책에 의하면 평균 수행시간은 O(a(N))이다.
a(N)은 에커만 함수를 이용해 정의되는 함수
따라서 거의 모든 크기의 N에 대해 4 이하의 값을 가진다고 합니다.
즉, 현실적인 모든 입력에 대해 상수시간에 동작한다고 봐도 무관 하다고 합니다.
이처럼 Union-Find 는 그 자체로 구현이 매우 간단하고 동작 속도가 아주 빠르기 때문에 다른 알고리즘의 일부로 자주 사용됩니다.
주의할 점
-
find 연산 수행할 때 재귀함수 나오면서 탐색했던 모든 노드의 값을 이번 연산에서 빌견한 대표노드로 변경!
-
union 연산에서 선택된 노드끼리 연결하는 것이 아닌 선택된 노드의 대표 노드끼리 연결!
-
Weighted Union Find의 union 연산에서
if (parent[x] < parent[y]){
parent[x] += parent[y]; // 꼭 값을 더해준 후
parent[y] = x; // 값 업데이트 해야함! 선후관계 중요! -> 선후관계 바뀌면 스택 오버플로우 에러 남
}
else {
parent[y] += parent[x];
parent[x] = y;
}과정이 있는데, 값을 더해준 후 업데이트 하는 과정의 선후관계가 중요!!
선후가 바뀌면 런타임에러(StackOverflow)발생!
Tip..?
- 합치는 과정에서 서로 다른 원소의 부모를 비교할 때 값이 더 작은 부모의 값으로 통일하면 편하다.
ex) 2, 4 값을 합칠 때 2의 부모가 0이고 4의 부모가 1이면 부모를 0으로 통일합니다.
출처
Do it! 알고리즘 코딩 테스트 자바편
https://ssungkang.tistory.com/198
https://escapefromcoding.tistory.com/184
https://bowbowbow.tistory.com/26
