Background
Moore의 법칙
반도체 칩에 들어가는 트랜지스터의 수는 매년 지수적으로 증가한다. (미세화의 한계로 이제는 적용되지 X)
Amdahl의 법칙
Performance = 1 / ((1 - P) + P / S)
(P=전체에서 개선된 부분이 차지하는 비율, S=이전에 비해 성능이 향상한 정도)
컴퓨터 시스템 일부를 개선할 때 전체적인 성능 향상 정도를 계산하는 데 사용된다. 예를 들어 어떤 작업의 40%를 2배 개선할 때, P는 0.4, S는 2라고 할 수 있다. 식에 대입해보면 전체 성능은 이전에 비해 1.25배가 된다.
또한, 병렬 프로그래밍으로 성능을 향상시킬 수 있는 부분의 한계를 암시하기도 한다. 이는 프로세서 수와 성능이 비례할 것이라는 생각을 깨트렸다. 성능 향상을 위해서는 프로세스를 무작정 늘리기 보다 병렬화할 수 없는 부분도 개선해야 한다.
RISC vs. CISC
| - | RISC | CISC |
|---|---|---|
| 명령어 | 간단하고 적은 수의 명령어 | 복잡하고 많은 수의 명령어 |
| 명령어 길이 | 고정(pipelining이 쉬움) | 다양 |
| 메모리 접근 명령어 제한 | O | X |
| 속도 | 빠름 | 느림 |
| 레지스터 | 많음 | 적음 |
| 캐시 사용 | O | X |
캐시 메모리가 나오기 이전으로 돌아가면, CPU와 메모리의 속도 차이 때문에 CPU의 유휴 상태가 길었다. 따라서 메모리에서 하나의 instruction을 가져와 많은 일을 처리하는 것이 이득이었고, 그에 따라 CISC가 한 시대를 풍미했다. 하지만 캐시 메모리가 나오자 CPU와 메모리 사이의 간극이 메워졌다. 그러다 보니 한 instruction이 한번에 많은 일을 처리하는 것보다 간단한 일을 처리하는 instruction 여러 개를 pipelining시키는 RISC가 더 효과적이게 됐다.
RISC의 성능이 더 좋은데 왜 CISC를 사용하는 x86을 아직 쓸까?
x86은 겉으로는 CISC이지만 내부적으로 CISC를 RISC로 변환한 후 실행한다. CISC의 시장이 이미 커져버려서 성능을 얻고자 RISC로 바꾸면 이전에 사용했던 것들(?)을 그대로 가져다 쓸 수 없다.
컴퓨터의 경우에는 x86을 쓰지만 휴대폰, 임베디드 시스템 등에서는 RISC인 ARM architecutre를 쓴다. ARM은 특히 저전력을 사용하도록 설계되어 전력의 소모량이 중요한 곳에 쓰인다.
Performance
performance ⬆️ = time ⬇️, throughput ⬆️
CPU Time
CPU Time = Clock Cycles * Clock Cycle Time = IC * CPI * Clock Cycle Time
| - | IC | CPI | Clock Cycle Time |
|---|---|---|---|
| Program | ✔️ | ||
| Compiler | ✔️ | ||
| ISA | ✔️ | ✔️ | |
| Organization | ✔️ | ✔️ | |
| Technology | ✔️ |
IC: RISC > CISC
CPI: RISC < CISC
좋은 organization, design technology를 써서 CPI와 clock cycle time을 줄이는 게 목표!
Throughput
밑에서 다룰 sequential implementation과 pipelined implementation의 차이는 throughput이다. pipelined implementation은 CPI가 1임을 보장한다.
ISA
interface between software and hardware
ADT
Data: register file & memory
Operation: instruction
MIPS
Design Principle
- Different kinds of instruction formats for different instructions
- Keep all instructions the same length
R-Format
opcode(6 bit), rs(5 bit), rt(5 bit), rd(5 bit), shamt(5 bit), funct(6 bit)
ADD, SUB, SLL, SRL, SLT, AND, OR, NOR
I-Format
opcode(6 bit), rs(5 bit), rt(5 bit), constant or address(16 bit)
LW, SW, BEQ, SLTI, ADDI, SUBI, ANDI, ORI
J-Format
opcode(6 bit), address(26 bit)
J, JAL
Branch Addressing
BEQ, BNE에서 타겟 주소는 16 bit address를 32bit로 sign extend, shift left by 2한 후 PC에 더한 값이다. 비트 수가 한정적이고 보통 타겟 주소가 현재 PC 근처에 있기 때문에 PC에 대한 상대주소를 구한다.
Jump Addressing
J, JAL에서 주소는 26 bit로 나타낼 수 있다. 특히 이 명령어들은 조건문과 관련이 없기 때문에 현재 PC와 상관 없는 곳으로 이동할 가능성이 크다. 제한적인 비트 수로 가능한 넓은 주소 범위를 만들기 위해서 모든 명령어들의 주소는 word 단위로 존재함을 이용한다. PC[31..28]에 26 bit address를 shift left by 2한 값을 이어 붙인다.
Addressing Mode
- Immediate Addressing: I-Format 중 immediate field를 사용하는 명령어
- Register Addressing: R-Format
- Base Addressing: I-Format LW, SW
- PC Relative Addressing: I-Format BEQ, BNE
- Pseudodirect addressing: J-Format
Sequential Implementation
Single-Cycle
한 명령어들을 한 cylce에 처리한다.
장점
- 복잡하지 않다.
단점
- 가장 오래 걸리는 명령어가 critical path가 되어 cycle time이 정해진다. 따라서 빨리 끝나는 명령어들을 처리한 프로세서는 유휴 상태에 빠진다.
- 한 cycle에 동일한 resource를 여러 번 사용할 수 없다. 예를 들어, ALU로 주소를 계산했으면 다음 cycle에서 ALU를 다시 사용할 수 있다. (그래서 duplicated resource가 필요하며 utilization은 떨어진다.)
Multi-Cycle
한 명령어를 여러 cycle에 나누어 실행한다. 서로 다른 명령어는 걸리는 cycle 수가 다르다. (ex. R-Format은 4 cycle, Load는 5 cycle)
장점
- 각 cycle마다 resource를 서로 다른 용도로 사용할 수 있다. (그래서 single-cycle과 달리 1 memory, 1 ALU만 필요하다.)
단점
- 각 cycle마다 다음 cycle 위한 명령어 정보를 저장해야 한다.
- 각 cycle이 하나의 resource만 사용하게 하는 등 각 cycle의 일의 균형을 맞춰야 한다.
Control Signal
instruction decode 시 각 명령어마다 수행해야 하는 control signal을 만든다. control signal은 multiplexor(RegDst(add or lw), ALUSrc(register or sign extended), PCSrc, MemtoReg(add or lw)), ALU operation, read/write를 제어하기 위한 용도로 구성된다. 하지만 branch instruction의 경우 instruction decode에서 만든 control signal만으로는 부족한데 두 레지스터를 비교해야만 다음 PC를 알 수 있다.
Overlapped(Pipelined) Implementation
한 명령어를 여러 cycle에 나누어 실행하고, 새로운 사이클마다 새로운 명령어를 실행한다. 따라서 임의의 명령어는 다음 cycle에서 필요한 정보를 모두 저장해야 한다.
각 cycle마다 하나의 명령어가 끝나면서 throughput이 증가하게 된다. (CPI = 1)
Hazard
다음 cycle에서 뒤따라오는 instruction이 어떠한 이유로 실행되지 못하는 현상을 가리킨다.
Structural Hazard
서로 다른 명령어가 동일한 cycle에 동일한 resource를 요구하는 경우
Solution
1. Resource Duplication: instruction과 data용 메모리를 따로 둔다.
2. Time-Multiplexed: 한 cycle을 subcycle로 나누어 읽기와 쓰기로 사용한다.
3. Multi-Port register: 동시에 두 개의 레지스터를 읽고 하나의 레지스터를 쓴다.
Data Hazard
명령어들 간 레지스터 의존성에 의해 sequential execution의 결과와 달라져 data incorrectness가 발생하는 경우
Solution
1. Stall: 다음 명령어는 레지스터를 사용할 수 있을 때까지 기다린다.
2. Forwarding: 다음 명령어는 레지스터를 사용할 수 있는 WB 단계까지 기다리지 않고 결과가 available하면 끌어다 사용한다. 1) ALU 연산 결과를 EX 단계에서 forwarding하는 경우 (stall 0), 2) 메모리 접근 결과를 MEM 단계에서 forwarding 하는 경우 (stall 1)
3. 컴파일러 스케쥴링: 레지스터 간 의존성을 고려해 명령어들의 순서를 재배치한다.
Branch Hazard
branch instruction에서 PC가 non-sequential하게 바뀌는 경우
Solution
1. Stall: 조건 비교 연산이 EX 단계에서 끝나고 타겟 주소가 MEM 단계에서 계산될 때까지 기다린다. (stall 3)
2. Optimized Branch Processing: 조건 비교 연산과 주소 계산을 ID 단계로 옮긴다. (stall 1) PC+4가 타겟 주소로 바뀌어야 할 경우 IF를 flush한다. 추가적인 하드웨어와 forwarding이 필요하다.
3. Branch Prediction: 다음 PC를 예측한다. 예측에 실패하면 로드해두었던 명령어를 flush한다. (2번 방법과 같이 사용하면 stall 1) static과 dynamic 방법이 있다.
4. Delayed Branch: sequential execution의 semantic을 변경하는 방법이다. (pipelining, concurrent execution에서는 semantic 변경을 하지 않는다.) 다음 PC 주소가 결정되는 사이에 어느 조건에서도 실행되는 명령어들을 실행할 수 있다.
Speculation
Make the common case fast(optimization)
어떤 일의 필요 여부가 결정될 때까지 기다리기보다 결과를 예측하고 수행함으로써 성능을 최적화시키는 기법이다. 만약 해당 일이 필요 없는 것으로 판명되면 그 일이 일어나기 전으로 상태를 되돌린다. 예로는 dynamic branch prediction, 메모리 접근 특성인 locality를 활용한 cache replacement policy, virtual memory의 prepaging가 있다.
performance와 power의 tradeoff가 생긴다.
speculation과 lookahead는 다르다.
Correctness
Make the rare case correct
프로세서의 성능을 높이기 위해 어떤 방법을 수행하더라도 sequential execution 시의 결과와 동일해야 한다. 예를 들어 speculation의 branch prediction의 예측이 실패했을 때, exception이 발생했을 때, pipelining이나 cache memory를 사용했을 때가 있다. Data hazard에서 레지스터 간에 의존성이 있는 경우 이를 제어하지 않아도 correctness는 깨진다.
Concurrent Execution
기본적으로 명령어들은 순서대로 실행된다. (sequential execution)
하지만 (1) data hazard로 인한 stall을 막고자 명령어들의 순서를 재배치하고, (2) branch hazard를 해결하는 delayed branch에서 명령어들의 순서를 재배치하며 concurrent execution(out-of-order execution)이 될 수 있다. 이 경우 레지스터 간에 의존성을 파악해 데이터의 correctness를 지키도록 해야 한다.
out-of-order execution으로 실행된다고 하더라도 machine state는 sequential execution 순서대로 업데이트해야 한다. (reorder buffer 사용)
명령어 I0, I1에 대하여 읽기, 쓰기 레지스터들의 집합을 각각 R(I0), W(I0), R(I1), W(I1), 메모리 접근 주소를 M(I0), M(I1)라고 한다면, (R(I0) ∩ W(I1)) ∪ (R(I1) ∩ W(I0)) ∪ (M(I0) ∩ M(I1)) == ∅인 경우에만 I0, I1을 concurrently 실행할 수 있다.
Exception Handling
- PC를 EPC(exception program counter)에 저장한다.
- CAUSE 레지스터에 exception이나 interrupt가 발생한 이유를 기록한다.
- ISR(interrupt service routine)으로 점프한다.
- rfe(return from exception) 명령어로 PC를 EPC로부터 복구한다.
exception이 발생한 명령어 이전으로는 다 실행되고 이후로는 실행되지 않은 것과 같도록 만들어야 한다. 앞의 명령어들이 모두 exception이 발생되지 않았다는 보장이 있어야 하므로 machine state는 sequential execution 순서대로 업데이트해야 한다. (reorder buffer 사용)
Comparison
| - | CPI⬇️ | CPI⬆️ |
|---|---|---|
| Clock Cycle Time⬆️ | Single-Cycle | - |
| Clock Cycle Time⬇️ | Pipelined | Multi-Cycle |
Datapath Summary
프로세서의 성능을 향상시키기 위해 pipelining, concurrent execution, speculation 등의 기법을 쓸 수 있지만, data correctness를 유지하는 것이 중요하다.
Memory Hierarchy
CPU < Cache Memory < Main Memory < Secondary Storage
빠른 속도, 싼 가격, 작은 크기를 가질수록 메모리의 상위 계층에 존재한다. 속도가 빠를수록 CPU에 가까이 위치시킴으로 메모리 접근을 빠르게 한다.
cache memory의 속도는 ns, main memory의 속도는 ns, secondary storage의 속도는 ms단위다. cache memory랑 main memory를 소프트웨어적으로 처리하려고 하면(OS), 기본적으로 ms 정도 걸린다. 따라서 cache memory는 하드웨어가 관리한다. (TLB miss 시 메모리에서 page table을 가져오는 건 flexibility(ex. replacement policy) 때문에 OS가 담당한다.)
secondary storage는 느리기 때문에 DRAM을 hard disk로 가는 access를 최소화해야 한다. 따라서 OS가 좋은 알고리즘으로 intelligently 처리한다.
RAM(Random Access Memory)
Volatile
ex. cache memory(SRAM), main memory(DRAM)
ROM(Read Only Memory)
Non-Volatile
ex. 부트로더
Cache Memory
Goal
To provide a virtual memory technology(illusion) that has an access time of the highest level of memory with the size and cost of the lowest level memory
cache memory는 메모리 접근의 non-uniform 특성(locality)과 메모리 기술의 한계(?)로 탄생했다. 메모리는 빠를수록 비싸고, 느릴수록 싸다. 비쌀수록 크기는 작아질 수 밖에 없다. 만약 빠르고 크고 값싼 메모리가 존재했다면 cache memory는 탄생하지 않았을 것이다. cache memory는 locality의 특성을 이용하기 때문에 마치 빠르고 크고 값싼 메모리가 존재한다는 illusion을 심어준다.
cache memory는 physical address로 이루어져 있어 virtual address에서 physical address로 바꾸어야 한다.
장점
- CPU와 메모리 사이에 CPU 캐시가 생기면서 메모리 접근이 줄어든다. 그에 따라 시스템 버스는 I/O 연산에 더 많은 시간을 할애하여 성능이 향상한다.
- ISA를 바꿀 필요 없이 캐시 크기를 키울수록 성능을 높일 수 있다.
단점
- 동일한 데이터가 여러 군데에 존재하면 data incorrectness를 조심해야 한다.
Locality
Temporal Locality: 한번 참조된 메모리 주소는 가까운 시간 내에 다시 참조될 가능성이 높다. (ex. loop 내 명령어, 변수)
Spatial Locality: 참조된 메모리 주소의 근처에 있는 주소들도 참조될 가능성이 높다. (ex. array, sequential instruction fetch)
Terminology
Cache Hit: 찾고자 하는 데이터가 캐시에 존재할 때
Hit Ratio: 캐시에서 데이터를 찾은 횟수/전체 데이터 접근 횟수
Hit Time: 캐시에서 데이터를 가져오는 데 걸리는 시간
Cache Miss: 찾고자 하는 데이터가 캐시에 존재하지 않아 아래 계층에서 가져와야 할 때
Miss Ratio: 1 - Hit Ratio
Miss Penalty: 아래 계층에서 block을 가져와서 교체하는 시간 + 프로세서에게 block을 전달하는 시간
AMAT(Average Memory Access Time): Hit Time + Miss Penalty * Miss Ratio
Cacheline(Cache Block): 아래 계층에서 caching을 위해 가져오는 데이터의 단위
Cache Miss
Cold Miss(Compulsory Miss): 비어 있는 캐시에 처음 접근할 때 생긴다.
Capacity Miss: 캐시가 모두 차서 더이상 저장할 공간이 없을 때 생긴다.
Conflict Miss: 주어진 인덱스에 대한 엔트리는 있지만 태그가 다를 때 생긴다.
Coherency Miss: 여러 개의 CPU가 같은 캐시라인을 가지고 있고 한 CPU가 이를 업데이트할 때 다른 CPU들의 캐시라인을 invalidate시키면서 발생한다. 그후로 invalidate된 데이터는 메모리에서 참조하게 된다.
Structure
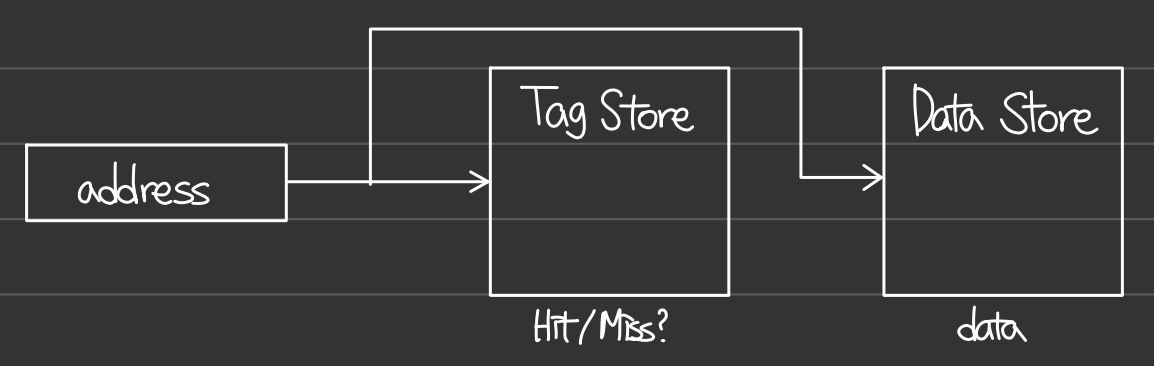
tag store에서 찾고 있는 주소의 tag를 찾을 수 있다면 hit, 없다면 miss이다. locality 특성에 따라 접근하려는 메모리 주소와 그 근처 주소들을 같이 caching한다.
Terminology
Cache에 접근하기 위한 물리적 주소의 구성
Byte Offset
Block Offset
Block Number(Index)
Tag
Performance를 위한 추가적인 하드웨어
Valid Bit
Protection Bit
Dirty Bit
Reference Bit
Fully-Associative Cache
주소는 tag와 block offset, byte offset으로 이루어져 있다. tag store 내 모든 tag를 비교하는 comparator가 필요하다.
장점
- 공간이 남기만 하면 데이터를 저장할 수 있다.
단점
- tag store 내 위치가 고정이 되어 있지 않기 때문에 검색 시간이 오래 걸린다.
Direct-Mapped Cache
주소에서 일부 비트를 tag store 내 위치를 나타내는 index로 둔다. 주소는 tag, block number, block offset, byte offset으로 이루어져 있다.
장점
- 구현이 간단하다.
- 검색 시간을 줄인다.
단점
- 비어 있는 공간이 있더라도 기존의 데이터와 교체하여 저장하므로 conflict miss가 발생한다.
Set-Associative Cache
index를 공유하는 여러 cacheline을 만들자. direct-mapped cache의 conflict miss를 보완하기 위해 fully-associative를 섞었다. 주소는 tag, block number, block offset, byte offset으로 이루어져 있다. index를 공유하는 여러 tag들을 비교하기 위한 N comparator가 필요하다.
associativity가 1이면 direct-mappped cache, cacheline의 총 개수와 같다면 fully-associative cache다.
장점
- directe-mapped cache의 conflict miss를 줄일 수 있다.
- fully-associative cache의 검색 시간을 줄일 수 있다.
Associativity vs. Miss Rate
associativity가 증가하면 temporal locality를 잘 활용하기 때문에 miss rate가 줄어든다. cacheline의 수는 그대로이기 때문에 capacity miss에는 영향을 주지 않는다. 하지만 associativity가 증가할수록 하드웨어가 복잡해지고 검색 시간이 증가한다.
Tradeoff
| - | Positive Effect | Negative Effect |
|---|---|---|
| Cache Size ⬆️ | capacity miss 감소 | access time 증가 |
| Block Size ⬆️ | cold miss 감소 | miss penalty 증가 |
| Associativity ⬆️ | conflict miss 감소 | access time 증가 |
일반적으로 캐시의 크기가 커질수록 block의 크기를 늘리면 spatial locality를 이용해 miss rate을 줄일 수 있다. 하지만 캐시의 크기가 충분히 크지 않은 상태에서 어느 수준보다 block의 크기를 키우면, block의 수가 동시에 줄어들므로 miss rate가 증가한다. 이는 spatial locality로 얻을 수 있는 이익보다 temporal locality를 제대로 이용하지 못하는 손해가 더 크기 때문이다.
associativity는 temporal locality, block size는 spatial locality와 관련이 있다.
Hit Time ⬇️
cache size ⬇️ but miss rate ⬆️
use direct-mapped cache but miss rate ⬆️
Miss Rate ⬇️
cache size ⬆️ but hit time ⬆️ (capacity miss)
associativity ⬆️ but hit time ⬆️ (conflict miss)
block size ⬆️ but miss penalty ⬆️ (cold miss)
Miss Penalty ⬇️
block size ⬇️ but miss rate ⬆️ (cold miss)
add another level of cache (first level은 hit time을 줄이고 second level은 miss rate를 줄인다.)
Write Policy
Hit
Write-Through: cache에 쓸 때 메모리에도 써준다. 성능이 떨어진다.
Write-Back: 각 cacheline 마다 dirty bit를 둔다. caching된 이후 값이 변경되었다면 dirty bit로 표시를 하고 후에 replacement될 때 메모리에 써준다. 성능은 좋지만 data incorrectness를 유발할 수 있다.
Miss
Write-Allocate: 메모리에 쓸 때 cache를 할당하고 써준다.
Write-No-Allocate: 메모리에 쓸 때 cache에 할당하지 않는다.
I/O Inconsistency
1) I/O가 메모리에 있는 데이터를 변경할 때 & 데이터가 cache에 있을 때
Write-Through, Write-Back 경우
OS가 I/O가 시작되기 전에 cache에 있는 데이터를 invalidate한다.
2) write-back 정책을 사용하는 프로세스가 cache에 있는 데이터를 변경할 때 & I/O가 데이터를 참조할 때
Write-Back 경우
OS가 I/O가 시작되기 전에 cache에 있는 데이터를 flush한다.
Cache Replacement
LRU나 second chance algorithm을 사용하여 교체할 cacheline을 고른다.
Fully-Associative Cache: 모든 cacheline 중에서 가장 오래전에 참조된 cacheline을 선택한다.
Direct-Mapped Cache: cache replacement가 따로 없다.
Set-Associative Cache: tag를 공유하는 cacheline들 중에서 가장 오래전에 참조된 cacheline을 선택한다.
Virtual Memory
하나의 물리적인 프로세서를 가졌음에도 여러 개의 논리적인 프로세서를 가졌다는 illusion을 심어준다. 다른 말로 하면, physical address space은 하나지만 N개의 virtual address space를 가졌다는 뜻이다. 각 프로세스는 실제 물리적인 메모리 크기보다 훨씬 큰 공간이 할당되어 있다고 착각하게 만든다.
프로세서에서 메모리에 접근하는 경우는 명령어 fetch, load/store로 두 가지가 있다. 그리고 모든 주소는 virtual address이기 때문에 physical address로 변환되어야 한다.
Terminology
EAT(Effective Access Time) = Memory Access Time + Disk Access Time * Page Fault Rate
Functionality
하드웨어 측면에서는 MMU, exception mechanism, 소프트웨어 측면에서는 page table, page table에 기반한 루틴이 필요하다.
Performance를 위한 추가적인 하드웨어
Valid Bit
Protection Bit
Dirty Bit
Reference Bit
Page Table
physical address에 대한 virtual address의 맵핑
프로세스마다 하나씩 있다.
TLB
page table의 cache
context switch 될 때 TLB를 invalidate해서 다음 프로세스가 잘못된 주소에 접근하는 것을 막는다.
TLB Miss
exception mechanism on TLB miss
main memory에 해당 프레임이 main memory에 있으면 exception을 리턴한다. 만약 없다면 page fault을 처리한다.
main memory에서 TLB로 페이지를 가져오기만 하면 된다면, 하드웨어를 사용해 빠르게 처리할 수 없을까? 하드웨어를 사용하려면 페이지 테이블의 구조 등 여러 가지를 fix해두어야 한다. 성능은 좋을지 몰라도 inflexible하다. 소프트웨어적으로 처리하면 TLB replacement policy를 바꾸거나 바뀐 페이지 테이블의 구조를 처리할 수 있다.
CPU Cache vs. Virtual Memory
공통점
일종의 illusion을 제공해 프로세서의 성능을 높인다. CPU cache는 빠른 메모리 접근을, virtual memory는 보다 더 많은 프로세스를 지원함으로써 CPU의 이용률을 높인다.
cache와 page replacement은 LRU, second changce algorithm이 있다.
CPU cache는 CPU와 main memory 사이에, virtual memory는 main memory와 secondary storage 사이에 존재하고, locality 특성을 이용해 프로세서가 메모리에 빠르게 접근하게 하며 프로세스의 이용률을 높인다. 둘다 dirty bit을 두어 두 메모리 계층 간 오버헤드를 줄인다.
차이점
CPU Cache: direct-mapped 방식을 사용한다. main memory도 충분히 빠르기 때문에 소프트웨어적으로 처리하면 cache를 장점을 활용할 수 없다. direct-mapped은 비교 연산이 없고 replacement policy가 없어 하드웨어만으로 구현한다.
Virtual Memory: secondary storage의 속도가 느리고 디스크에 접근하는 시간을 최소화하기 위해 소프트웨어적으로 intelligently 처리할 수 있다.
