지난 학기에 배웠던 컴파일러 수업을 며칠 동안 되짚어 보며 복습을 했다. 잊어버릴 때마다 두고두고 볼 수 있도록 글을 쓰려 한다.
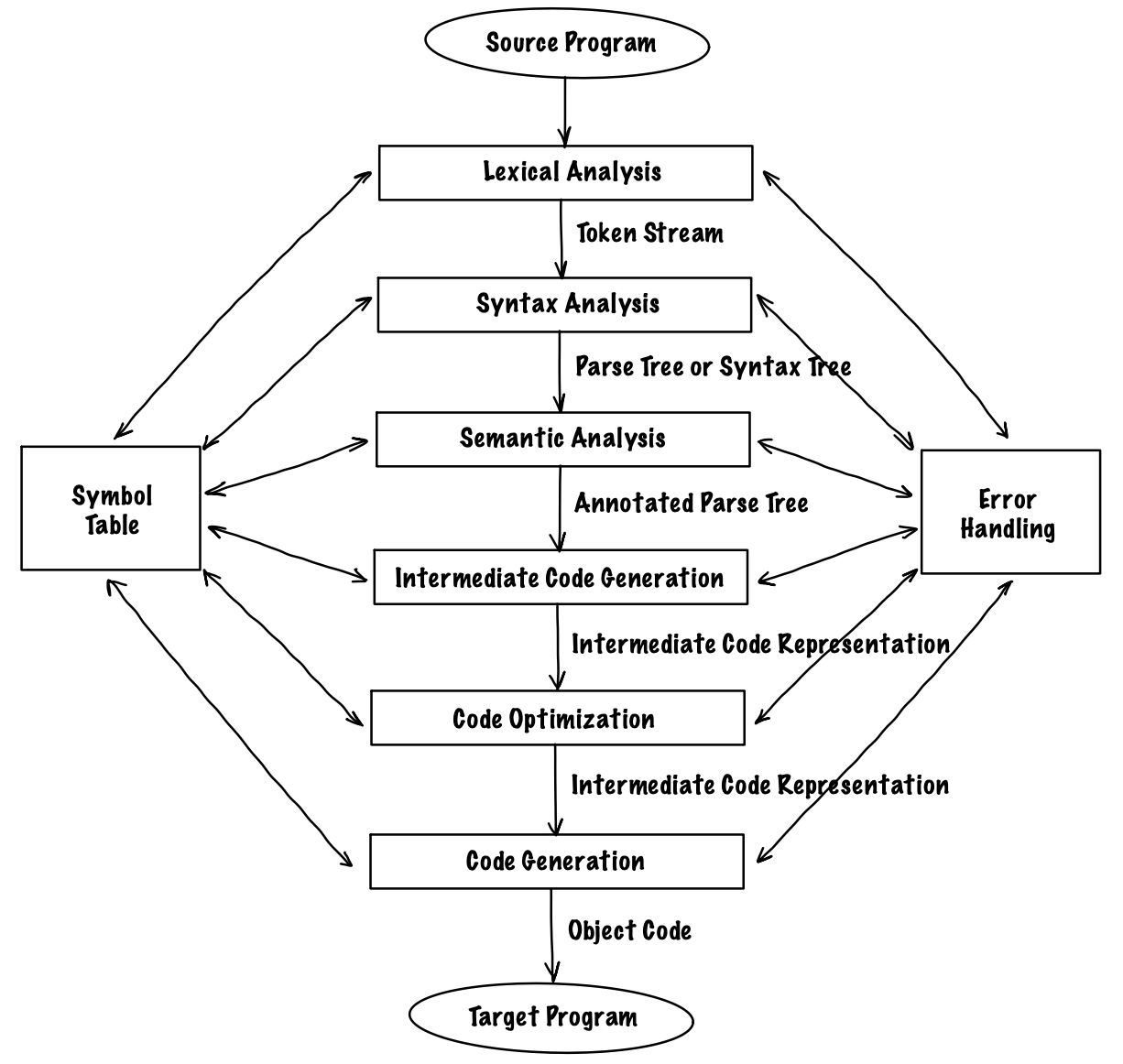
일반적으로 사용되고 있는 컴파일러는 2-패스 컴파일러로 IR(intermediate representation)을 기준으로 전단부(front-end)와 후단부(back-end)로 나뉜다.
전단부는 소스 프로그램을 받아 IR로 바꾸는 역할을 책임지며 어휘 분석(lexical analysis), 구문 분석(syntax analysis), 의미 분석(semantic analysis), 중간 코드 생성(intermediate code representation) 단계가 해당한다.
후단부는 IR(혹은 intermediate code)을 받아 실행 가능한 object code로 바꾸는 역할을 책임지며, 코드 최적화(code optimization), 코드 생성(code generation) 단계가 해당한다.
2-패스 컴파일러는 무엇을 의미할까? 패스는 하나의 입력 파일을 단 한 번만 읽는 것으로 구성되는 단위다. 2-패스 컴파일러는 IR을 기준으로 두 패스로 나뉘며, 1-패스는 초창기 컴파일러가 사용했던 방식으로 IR이 존재하지 않아 6개의 단계가 하나의 패스에 포함됐다.
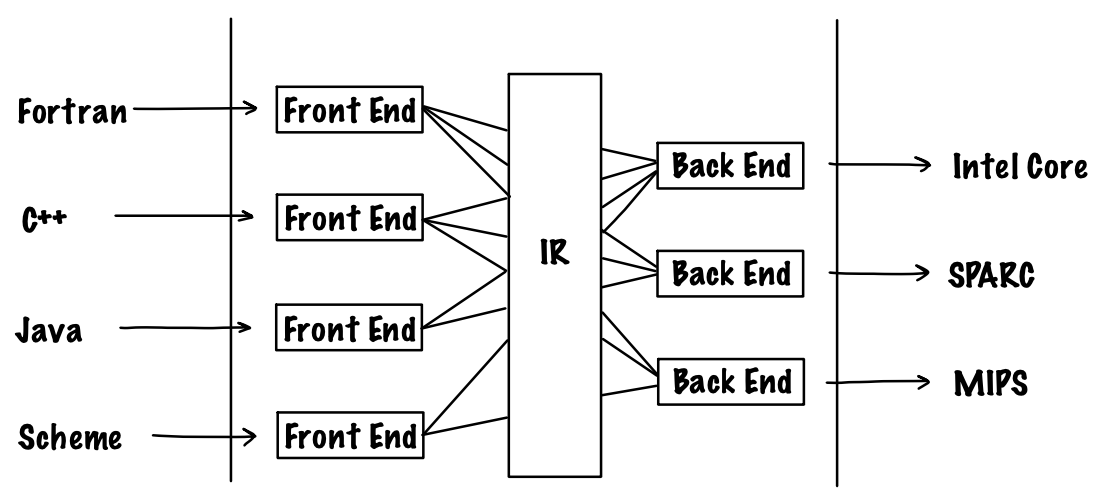
그렇다면 IR이 생겨난 이유가 있을 것이다. 상식적으로 다수의 프로그래밍 언어가 존재하고 이를 컴파일 과정을 통해 CPU 아키텍처에 의존적인 실행이 가능한 코드로 바꾸려면 컴파일러가 복잡해질 수밖에 없다. 하지만 서로 다른 프로그래밍 언어로 짜인 프로그램도 모두 똑같은 표현법(=IR)으로 바꿔주고 이를 서로 다른 CPU 아키텍처에 맵핑하게 된다면 훨씬 간단해질 것이다.
Lexical Analysis
입력으로 소스 프로그램을 받아 일련의 문자들을 토큰(token)이라고 하는 의미 있는 단위로 모으고, 결과로 토큰 스트림(token stream)을 만들게 된다.
토큰에는 예약어(if, for, while ...), 상수, 연산자, 식별자, 구분자(,, ;, { ...) 총 5가지의 종류가 있다.
구문 분석기를 만드는 방법은,
1. 해당 문법이 어떠한 토큰 종류를 사용하는지 파악하고
2. 각 토큰을 정규 표현식으로 나타내고
3. 정규 표현식을 받아들일 수 있는 유한 오토마타(finite automata)로 표현하면 된다.
Syntax Analysis
입력으로 토큰 스트림을 받고 주어진 문법에 맞는지 검사한다. 만약, 주어진 문법에 맞다면 구문 트리(syntax tree) 혹은 파스 트리(parse tree)가 결과물이 되고, 그렇지 않다면 에러 메시지를 출력한다.
Semantic Analysis
구문 트리와 심볼 테이블(symbol table)을 이용해 소스 프로그램이 언어 정의에 의미적으로 일치하는지 검사하고, IR을 생성하기 위해 자료형 정보를 수집하여 구문 트리나 심벌 테이블에 저장한다.
구문은 두가지 종류로 나뉜다.
정적 구문: 런타임 이전에 결정되는 프로그래밍 언어적 특성이다. 예를 들어 타입 검사 등이 있다.
동적 구문: 런타임에 결정되는 것으로 배열 범위 검사 등이 있다.
