
lec 11-1
Contents
- Convolutional Neural Networks
- Convolutional layer
ㅤ
ㅤ
ㅤ
오늘은 앞에서 배운 CNN에 대해 자세히 알아볼 것이다.
CNN은 고양이 실험에서 비롯되었다.
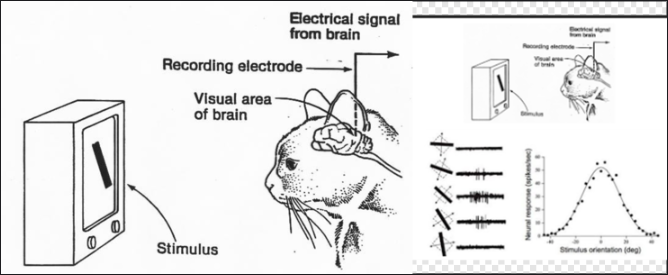
LeCun교수는 Hubel & Wiesel의 고양이 인지 실험에서 아이디어를 얻어 1989년 논문에서 CNN을 처음 소개하였다.
고양이 실험은 고양이가 그림이나 사물을 볼 때 읽어 들이는 뉴런들이 한 번에 동작하는 것이 아니라 그림이나 사물의 부분부분마다 다른 뉴런들이 활성화된다는 것을 알아낸 실험이다.
ㅤ
ㅤ
ㅤ
ㅤ
Convolutional Neural Networks
하나의 이미지가 있으면, 그 이미지를 부분적으로 잘라내 각각의 입력으로 넘기는데, 이 층을 Convolutional layer라고 한다.

CONV, RELU, POOL 과정을 여러번 반복해 FC과정을 거쳐 레이블링 한다.
ㅤ
처음 이미지를 입력 받게 되면, 필터링 과정을 통해 이미지의 사이즈를 읽어 하나의 값(one number)(Wx+b)으로 변경한다.
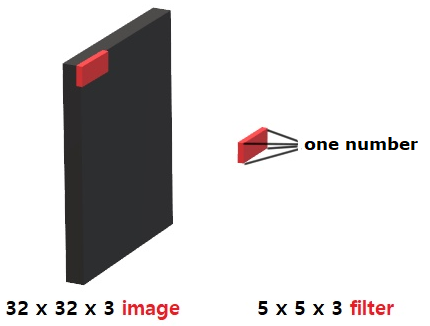
같은 필터에서의 w 값은 모두 같다. 만약 전체 크기가 7x7이고 filter 크기가 3x3일 때, 옆으로 한 칸씩 이동해가며 이미지를 확인하면 출력의 갯수는 5x5로 25개가 출력된다.
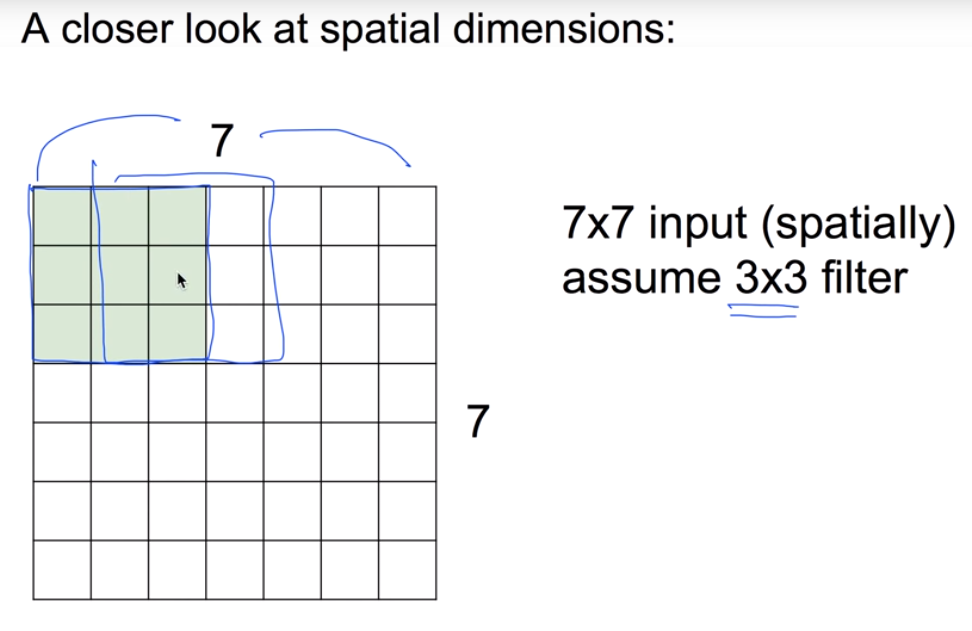
(한 칸씩 움직인다 =
stride가 1이다.)
아래의 사진을 보면 filter를 이해하기 쉬울 것이다.

stride가 2면 3x3=9의 output이 나오게된다. stride가 커질수록 outputsize가 작아지는데, 이것은 정보를 잃어버리는 양이 커진다는 것을 의미한다.
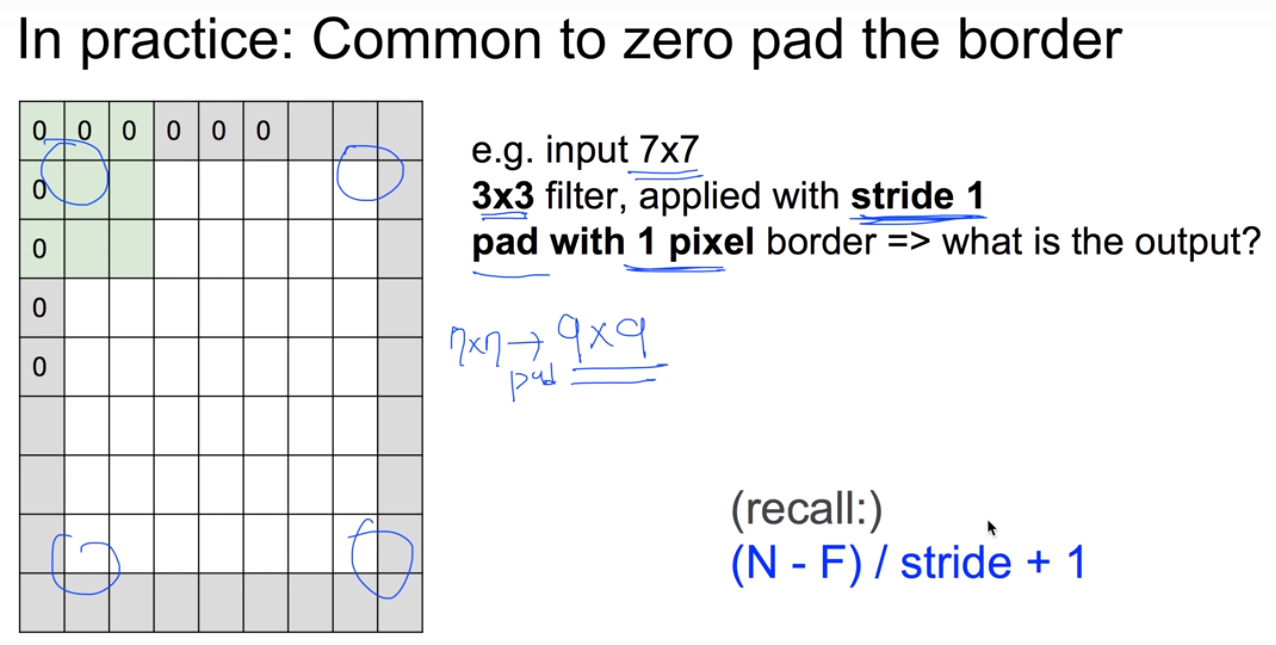
이를 방지하기 위해서 padding을 사용하는데, 테두리에 0을 둘러 그림이 급격히 작아지는 것을 방지하고 모서리를 network에 알려주는 역할을 하기도 한다.
7x7에서 1px씩 padding해주면 9x9로, output은 똑같이 7x7이 된다.
ㅤ
ㅤ
ㅤ
ㅤ
Convolutional layer
이런 filter를 여러개 적용하는 것이 CONV layer가 된다.
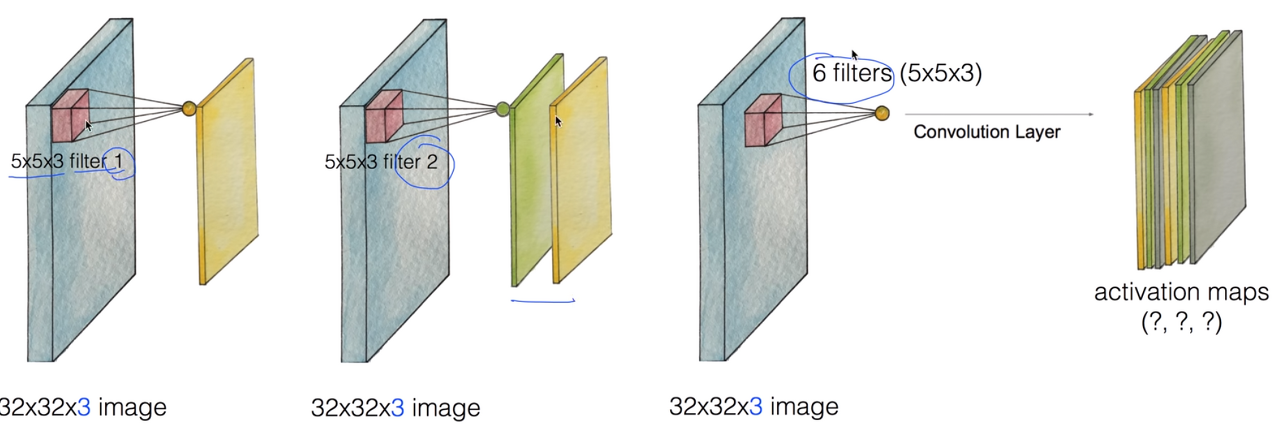
각각의 필터마다 w이 다르기 때문에 output이 조금씩 다를 수 있다.
필터를 6개 사용하면 값의 깊이는 6이 되고, 값은 activation maps(x, y, 6)이 나온다.
ㅤ
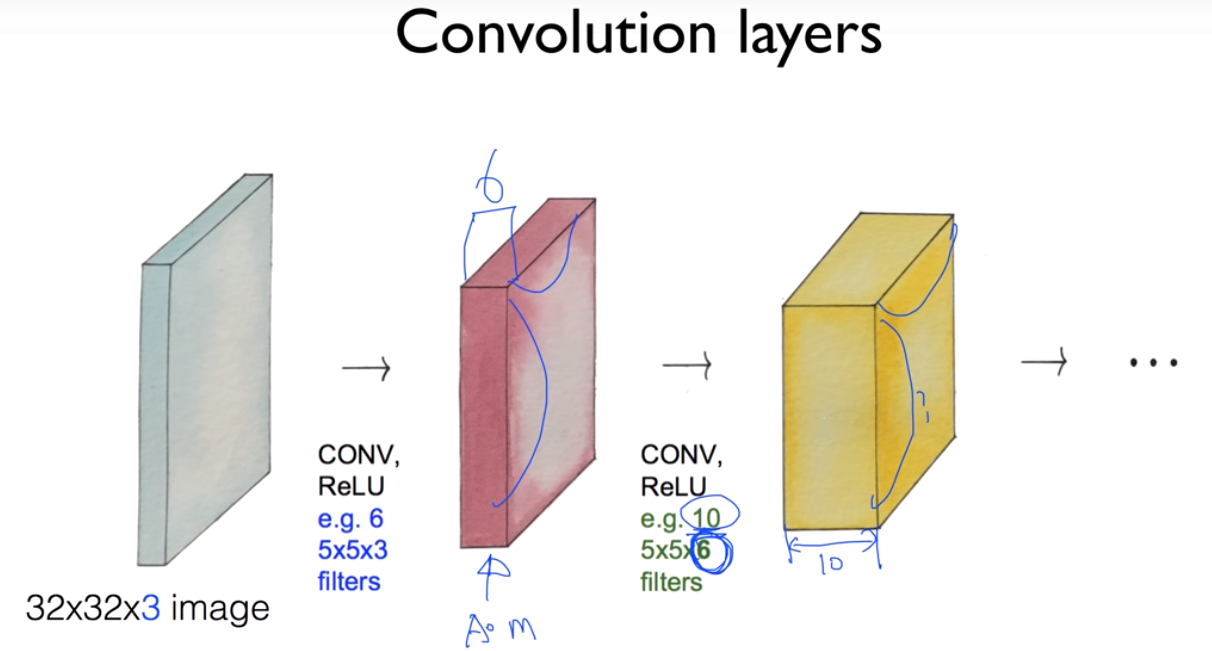
(CONV + RELU) + (CONV + RELU) + (CONV + RELU) + ...
이 형태가 CNN인 것이다.
