1. Introduction
AI 모델이 특정 상황에서 유용하게 사용되기 위해서는 그 상황의 배경지식에 접근할 수 있어야 한다
이에 대해 개발자들은 RAG 를 사용하여 배경지식을 제공해주는데, RAG 는 지식 corpus 에서 관련 정보를 검색하여 사용자 프롬프트에 추가하여 모델의 응답을 향상시키는 방법이다.
traditional RAG 에서는 배경지식 정보를 Encoding 할 때 context 가 유실되어 관련 정보를 검색하지 못하는 경우가 있다. 이것에 대해 간략히 설명하자면, traditional RAG 에서 Chunking 을 진행하여, 문서를 쪼개면서 이웃 청크와의 관계(전체적 문맥) 를 잃어버리게 된다.
이 글에서는 RAG의 검색 단계를 획기적으로 개선하는 방법을 간략히 설명한다. 이 방법은 "Contextual Retrieval"이라고 불리며, "Contextual Embeddings"과 "Contextual BM25"라는 두 가지 하위 기술을 사용한다. 이후, 선택에 따라 Reranker 와 연계하여 Reranking 까지 진행 가능하다.
물론 더 긴 프롬프트를 사용하여, 프롬프트 내부에 배경 지식을 포함 시키는 방법이 있지만, 이는 지식 베이스가 200,000 토큰 (약 500p) 보다 작을 경우 효과적이다. 지식 베이스가 커지게 될 경우, 확장 가능한 솔루션인 Contextual Retrieval 이 필요하게 된다.
2. RAG primer
2.1 Scaling to larger knowledge bases - Traditional RAG
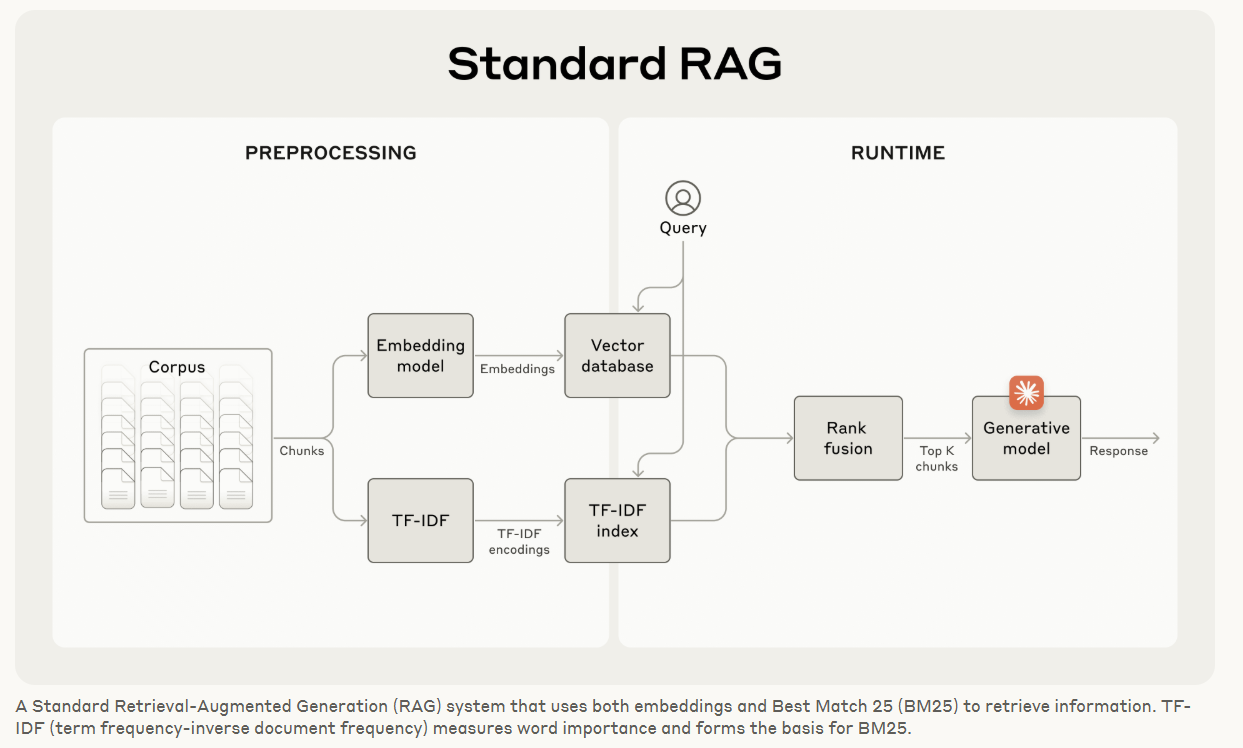
context window 에 담을 수 없는 대규모 지식 베이스의 경우, RAG가 일반적인 해결책이다. RAG는 다음 단계를 통해 지식 베이스를 전처리하는 방식으로 작동한다.
- 지식 베이스(Document corpus)를 수백 토큰(token) 이하의 작은 텍스트 조각(chunk)으로 분해한다.
- 임베딩 모델을 사용하여 이 조각들을 의미를 인코딩하는 벡터 임베딩(vector embedding)으로 변환한다.
- 이 임베딩들을 의미론적 유사성(semantic similarity)으로 검색할 수 있는 벡터 데이터베이스(vector database)에 저장한다.
실행 시간에 사용자가 모델에 쿼리를 입력하면(특정 지식 베이스에 접근하고자 하면), 벡터 데이터베이스는 쿼리와의 의미론적 유사성에 기반하여 가장 관련성 높은 document chunk들을 찾는다. 그런 다음, 이 가장 관련성 높은 조각들이 생성 모델에 전송되는 프롬프트에 추가된다.
임베딩 모델은 의미론적 관계를 포착하는 데 뛰어나지만, 중요한 단어의 exact match를 놓칠 수 있다. 이를 해결하기 위해 BM25는 정확한 단어 구를 찾는 순위 결정 함수이다. 즉, query 와 document chunk 의 단어 매칭을 진행한다.
이때, BM25는 TF-IDF 개념을 기반으로 작동한다. TF-IDF는 컬렉션 내의 문서에서 특정 단어가 얼마나 중요한지를 측정한다. BM25는 여기에 문서 길이를 고려하고 단어 빈도에 포화 함수를 적용하여 이를 개선하며, 이는 자주 등장하는 일반적인 단어가 검색 결과 전체를 차지하는 것을 방지하는 데 도움이 됩니다. (the, a 와 같이, 많이 나오지만 문서 대부분에 존재하여 중요도가 낮은 단어 처리 + 문서 길이가 길어질 수록 패널티)
다음은 의미론적 임베딩이 실패하는 지점에서 BM25가 성공하는 방식이다:
- 사용자가 기술 지원 데이터베이스에서 "에러 코드 TS-999"를 쿼리한다
- 임베딩 모델은 일반적인 에러 코드에 대한 콘텐츠를 찾을 수는 있지만, 정확한 "TS-999" 일치는 놓칠 수 있다.
- 이때 BM25는 이 특정 텍스트 문자열을 검색하여 관련 문서를 식별한다.
RAG 솔루션은 다음 단계를 사용하여 임베딩과 BM25 기술을 결합함으로써 가장 적절한 조각을 더 정확하게 검색할 수 있다:
-
지식 베이스(문서 "코퍼스")를 수백 토큰 이하의 작은 텍스트 조각으로 분해한다.
-
이 조각들에 대해 TF-IDF 인코딩과 의미론적 임베딩을 생성한다.
-
BM25를 사용하여 정확한 일치를 기반으로 상위 조각을 찾습니다.
-
임베딩을 사용하여 의미론적 유사성을 기반으로 상위 조각을 찾는다.
-
rank fusion 기술을 사용하여 (3)과 (4)의 결과를 결합하고 중복을 제거한다.
-
응답을 생성하기 위해 상위 K개의 조각을 프롬프트에 추가한다.
하지만 이러한 전통적인 RAG 시스템에는 중대한 한계가 있는데, 이는 문맥(context)을 파괴하는 경우가 많다는 것이다.
2.2 Context conundrum in traditional RAG
전통적인 RAG에서는 효율적인 검색을 위해 문서를 일반적으로 더 작은 chunk으로 분할한다. 이 접근 방식은 많은 응용 프로그램에서 잘 작동하지만, 분할된 개별 chunk 에 충분한 context, 즉 문맥이 부족할 때 문제점이 발생한다.
예를 들어, 지식 베이스에 금융 정보(가령, 미국 SEC 서류) 모음이 임베딩되어 있고 다음과 같은 query 를 생각해보자.
"What was the revenue growth for ACME Corp in Q2 2023?
관련된 chunk 에는 다음과 같은 텍스트가 포함될 수 있다.
"The company's revenue grew by 3% over the previous quarter"
하지만 이 조각만으로는 어느 회사를 지칭하는지 또는 관련 기간이 언제인지 명시되지 않아, 올바른 정보를 검색하거나 해당 정보를 효과적으로 사용하기 어렵다. 즉, "ACME Corp" 와 "2023" 이라는 정보가 소실된다.
3. Contextual Retrieval
3.1 Introducing Contextual Retrieval
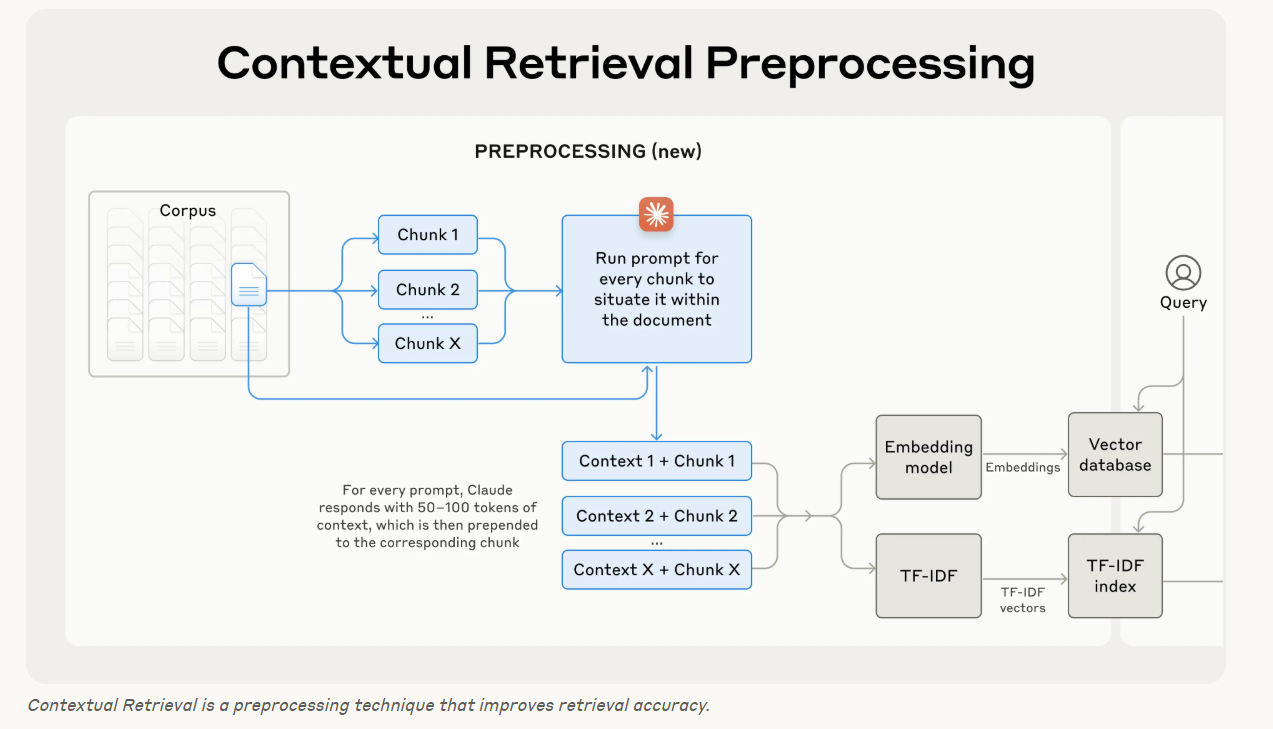
Contextual Retrieval은 Contextual Embeddings 및 Contextual BM25 에 chunk별 설명 문맥을 각 청크 앞에 추가함으로써 이 문제를 해결한다.
앞선 예시에서의 contextualized chunk 가 만들어지는 방법은 다음과 같다.
original_chunk = "The company's revenue grew by 3% over the previous quarter."
contextualized_chunk = "This chunk is from an SEC filing on ACME corp's performance in Q2 2023; t
he previous quarter's revenue was $314 million.
The company's revenue grew by 3% over the previous quarter."3.2 Implementing Contextual Retrieval
지식 베이스에 있는 수천, 수백만 개의 chunk에 수동으로 해당 chunk 의 위치, 문맥을 다는 것은 불가능하다. 'Contextual Retrieval'을 구현하기 위해 Claude를 활용했다. 모델이 전체 문서를 기반으로 해당 청크를 설명하는, 간결하고 청크 특화된 문맥을 지시하는 프롬프트를 작성하였다.
<document>
<!-- 전체 DOCUMENT -->
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
<!-- 문맥을 추가하고자 하는 청크 -->
{{CHUNK_CONTENT}}
</chunk>
<!-- 프롬프트; 문맥 추가 -->
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else. 이 생성된 문맥이 추가 된 Chunk 는 embedding 되기 전, BM25 인덱스를 생성하기 전에 Chunk 에 추가된다.
3.3 Using Prompt Caching to reduce the costs of Contextual Retrieval
Claude 에선 prompt caching 을 지원하여, 모든 청크마다 전체 document 를 전달할 일 없이, 캐시에 한번만 로드한 다음, 이전 캐시 된 whole document 을 참고하면 된다고 한다.
3.4 Performance improvements
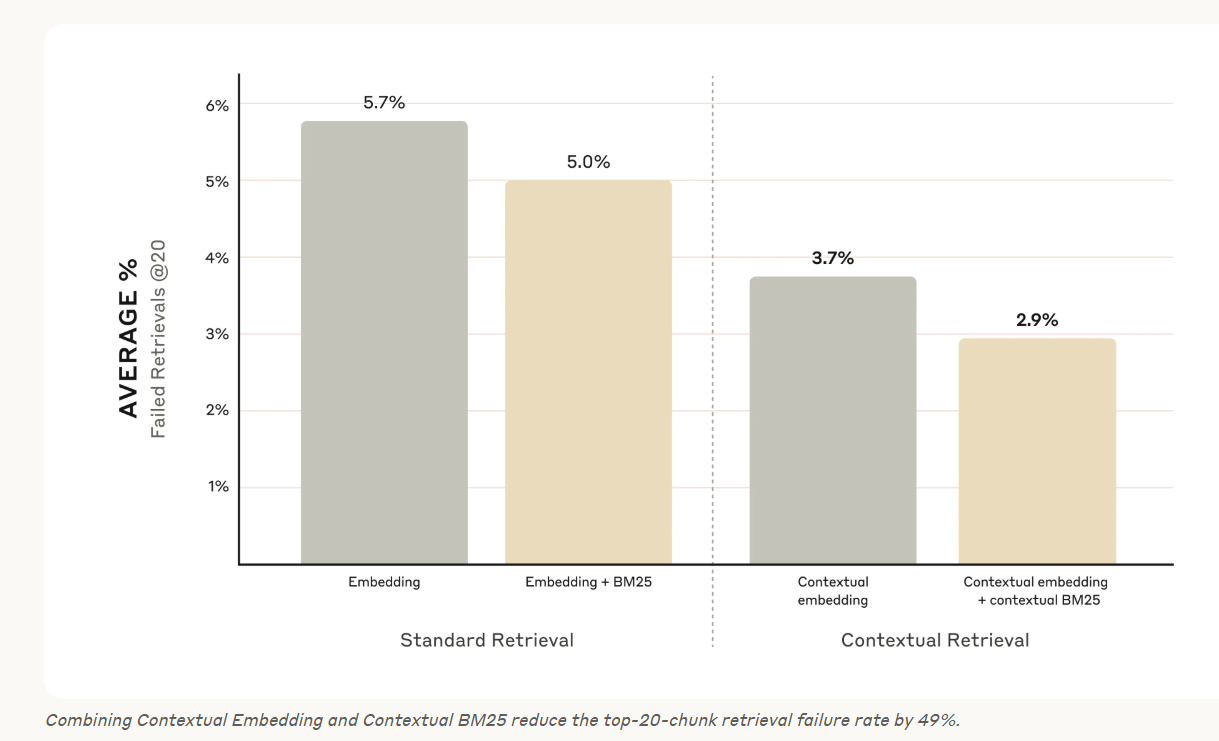
Contextual Embeddings 만을 단독으로 사용했을 때는 은 상위 20개 청크 검색 실패율을 35% (5.7% → 3.7%) 감소시켰다.
Contextual Embeddings 과 Contextual BM25를 결합하면 상위 20개 청크 검색 실패율을 49% (5.7% → 2.9%) 감소시켰다.
3.5 Implementation considerations
다음은 Contextual Retrieval 을 구현 시 염두해야할 사항들이다.
- Chunk boundaries: 문서를 청크로 분할하는 방식을 고려해야 한다. 청크 크기, 청크 경계, 청크 겹침의 선택이 검색 성능에 영향을 미칠 수 있다.
- Embedding model: Contextual Retrieval 은 테스트한 모든 임베딩 모델에서 성능을 향상시켰지만, 일부 모델은 다른 모델보다 더 큰 이점을 얻을 수 있다. 특히 Gemini와 Voyage 임베딩 모델이 효과적이었다.
- Custom contextualizer prompts: 앞서 제공한 일반적인 프롬프트 뿐만 아니라, 특정 도메인, 지식 베이스 특화된 프롬프트를 사용하게 되면 훨씬 더 좋은 결과를 얻을 수 있다.
- Number of chunks: 컨텍스트 창에 더 많은 청크를 추가하면 관련 정보를 포함할 확률이 높아진다. 하지만 정보가 많을수록 모델의 attention을 분산시킬 수 있으므로 한계가 있다. chunk 의 개수를 5,10,20 으로 전환하여 실험해본 결과, 해당옵션 중에선 20개의 chunk 의 성능이 가장 좋았다.
- Always run evals: 문맥화된 청크를 전달하고, 무엇이 문맥이고 무엇이 청크인지 구분하여 전달함으로써 응답 생성이 개선될 수 있다.
4. Reranking
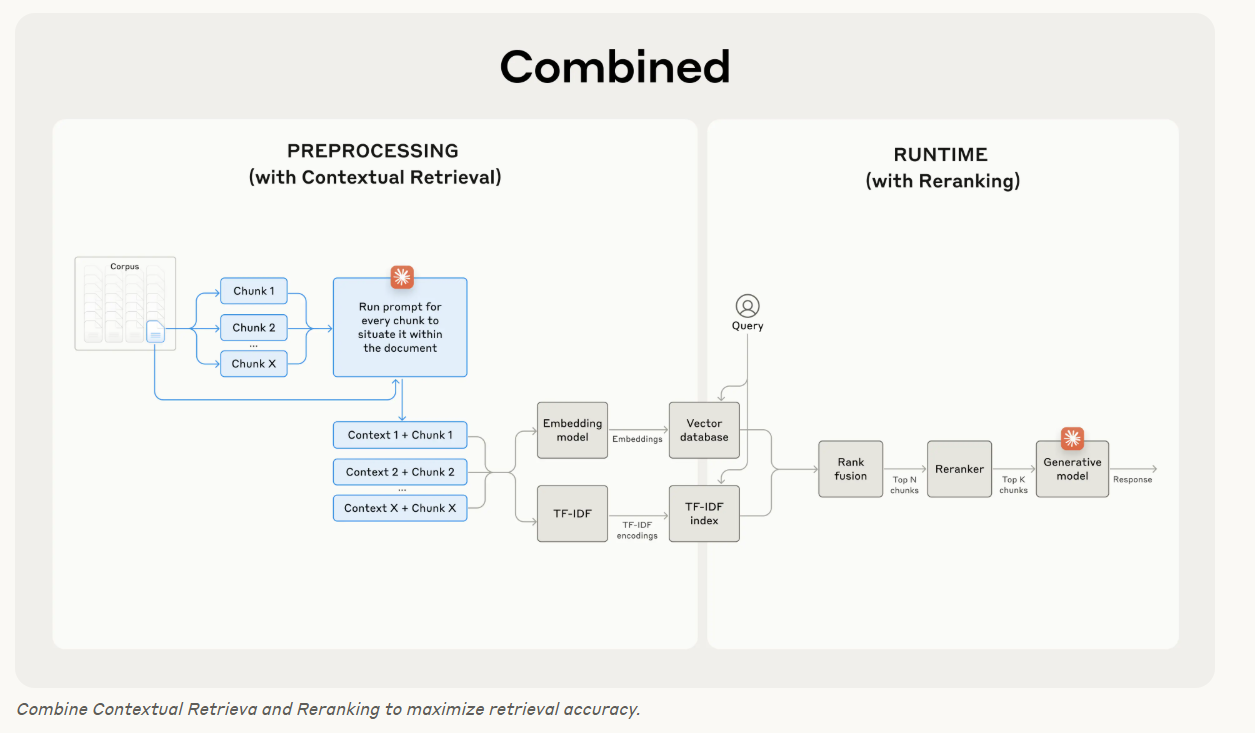
Contextual Retrieval의 경우, 마지막 단계로 reranker 를 두어 성능을 더욱 향상 시킬 수 있다.
Reranking 은 모델에 가장 관련성 높은 청크만 전달되도록 보장하기 위해 일반적으로 사용되는 필터링 기술이다. Reranking 은 모델이 더 적은 정보를 처리하기 때문에 더 나은 응답을 제공하고 비용과 지연 시간을 줄인다. 핵심 step 은 다음과 같다.
- Contextual Retrieval 을 수행하여 잠재적으로 관련 있는 상위 top-N 의 chunk 를 가져온다.
- 상위 N개의 청크를 사용자 query와 함께 reranking model 에 전달한다.
- reranking 을 사용하여 프롬프트에 대한 관련성과 중요도에 따라 각 청크에 점수를 매긴 다음, 상위 K개의 청크를 선택한다.
- 상위 K개의 청크를 모델에 context 으로 전달하여 최종 output 을 만들어낸다.
4.1 Performance improvements
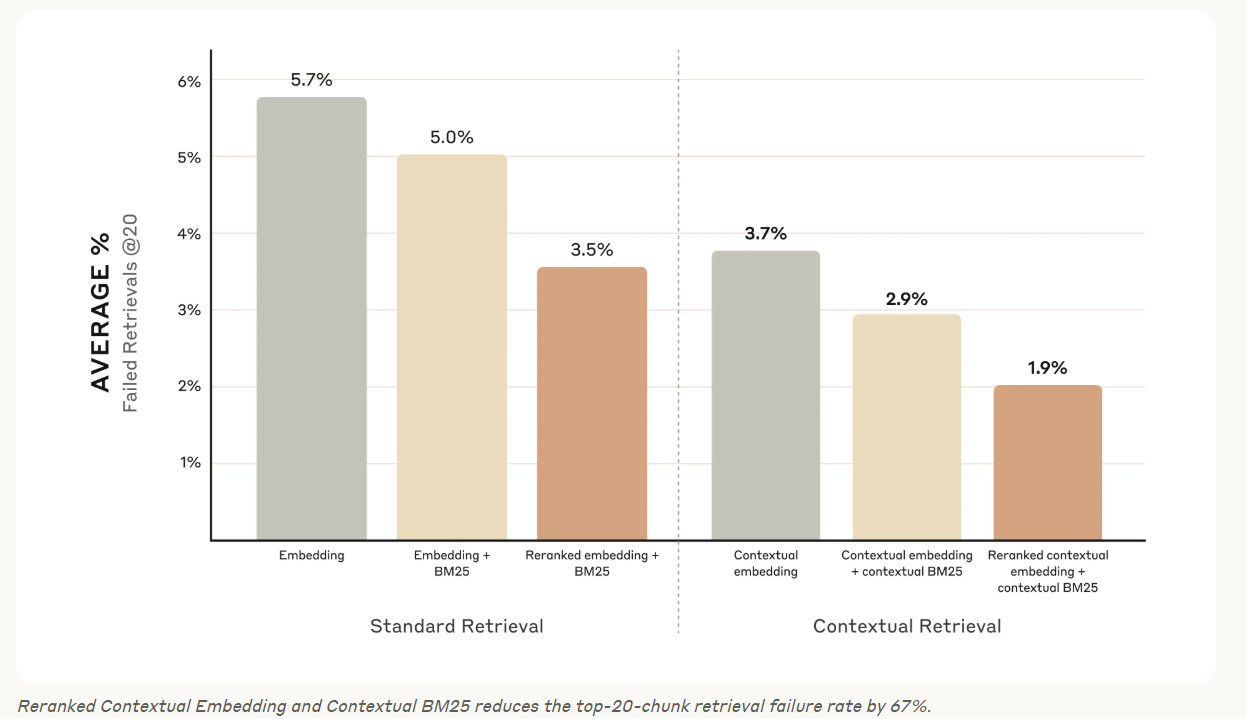
reranking 된 Contextual Embedding과 Contextual BM25가 상위 20개 청크 검색 실패율을 67% (5.7% → 1.9%)까지 감소시키게 되었다.
4.2 Cost and latency considerations
Reranking 에서 한 가지 중요한 고려 사항은 latency과 cost에 미치는 영향이다. 특히 많은 양의 chunk 를 Reranking 할 경우 runtime에 추가 단계를 더하기 때문에, Reranker 가 모든 청크의 점수를 병렬로 계산하더라도 필연적으로 약간의 지연 시간을 추가하게 된다.
즉, 더 나은 성능을 위해 더 많은 청크를 Reranking하는 것과, 더 낮은 지연 시간과 비용을 위해 더 적은 수를 Reranking하는 것 사이에는 trade-off가 있게 된다.
