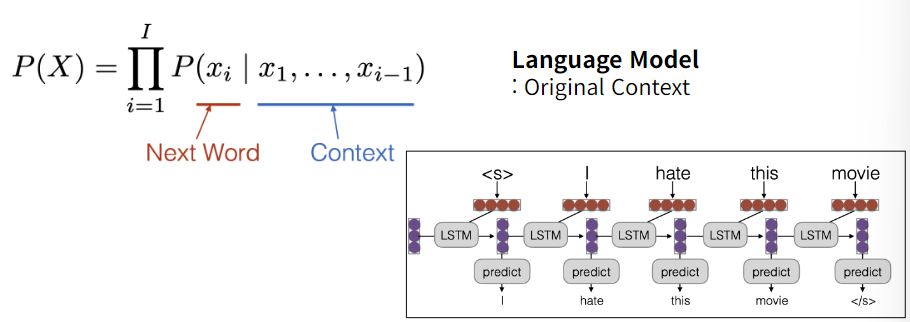
📌Language model
Language model 이란 text generate 를 위한 modeling 이다.
Language model 자체를 input, output, task 으로 나눌 수 있는데, 이 경우 output 은 항상 text 일 것이다.

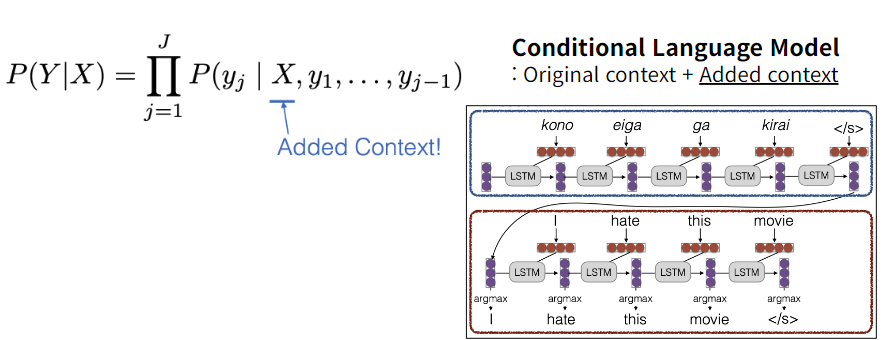
Conditional Language model?
conditional language model 의 경우, 원래 context 를 제외한 added context가 존재한다.
원 context 를 사용하는 language model 의 경우, 다음 단어를 예측, 학습하는데 사용된다.
conditional language model 의 경우, 위 그림처럼 task 를 수행하는 방법으로 학습된다.
📌Seq2seq
sequence to sequence 의 경우, input sequence 를 output sequence 로 변환하는데 사용되는 Neural Network 이다. 구조의 경우, 크게 Encoder-Decoder 구조로 이루어져 있다.
(conditional language model)
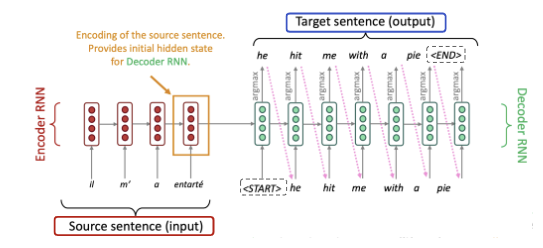
그림에서 argmax 의 경우, decoder 가 output sequence를 생성할 때 각 단계에서 다음 토큰을 선택하게 하는 연산자이다. 
-
Encoder
- Input sequence 를 고정된 길이의 벡터로 변환하는 작업을 수행한다. (context vector)
- Seq2seq 의 encoder 내부에는, RNN 과 LSTM cell 의 반복적 사용으로 sequence data 를 순차적으로 처리한다.
-
Decoder
- Encoder 으로부터 전달받은 Context vector 를 사용해서 target sequence 를 생성한다.
- context vector 를 initial state 를 사용하여 순차적으로 decoding 한다.
- 각 step 에서는 이전 단계의 출력을 입력으로 사용한다. 이때, teacher forcing 이란, 틀린 값을 decode 하였을때 이를 바로잡아 준다. 이는 training 에서만 활용된다.
정리해보자면, Seq2seq 모델의 경우
- Encoder 에서 입력 벡터 를 받아들여 고정된 길이 벡터 를 만들어낸다.
- Decoder 에서 initial state 의 경우 고정벡터 일 것이고, 각 시점 t 에서 이전단계 출력값인 과 이전 단계 hidden state 인 를 사용해 decoding 을 진행한다.
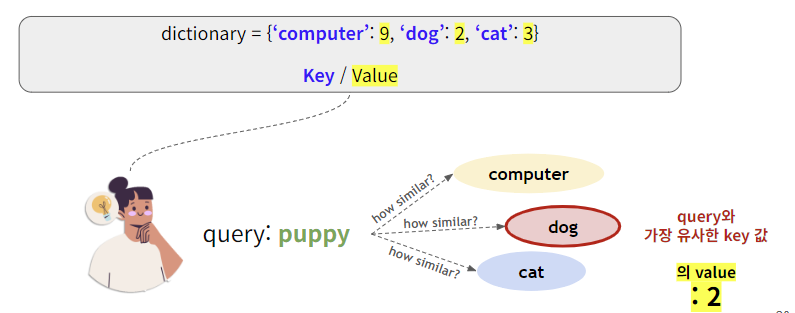
📌Attention
Attention 이란, 입력값인 Query 와 비슷한 값을 가진 , 비슷한 내용을 가진 Key 를 찾아 이에 해당하는 Value 를 찾는 과정이다
Seq2seq 문제의 한계점
-
Bottleneck problem
Encoder state 에서 Context vector 의 경우, 입력 벡터 를 받아들여 고정된 길이 벡터 를 반환하는데, source sentence 에 모든 정보를 담아야한다. 이때, Information 의 bottleneck problem 이 발생한다.
-
Linear interaction distance
- Long distance dependency : 입력 문장의 길이가 길어지면 초기의 정보를 잃어버린다.
- 문장의 Linear order 에 크게 의존하게 된다.
-
Lack of parallelizability
- RNN 특성상 병렬처리가 어렵다. (t시점은 t-1시점에 의존하므로)
- GPU같은 병렬 처리 장치의 장점을 충분히 활용하지 못하게 만듦
Seq2seq with attention mechanism
Decoder 의 각 step 에서 encoder 와 direct connection 을 통해, Encoder 의 일부 내용을 직접적으로 참조할 수 있게 만들어준다.
Query : Time step t의 hidden state
Key : Encoder Hidden state (embedded)
Value : Encoder Hidden state (embedded) (same as Key)
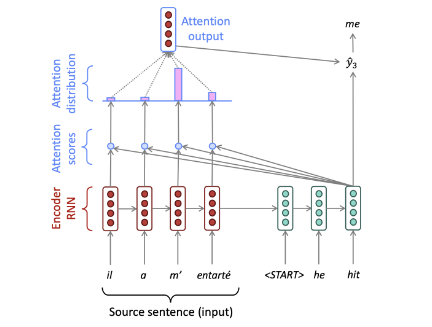
(기본구조)
-
다음 Q,K,V 에 대해서 각 step 별 attention score 인
-
이후 softmax 연산을 통해 attention distribution
-
encoder hidden state 가 value 이므로, 이를 attention distribution 과의 weighted sum 을 통해 attention output 을 얻는다.
📚출처
이유경 멘토님 자료
https://www.phontron.com/class/anlp2022/index.html
https://web.stanford.edu/class/cs224n/
https://kh-kim.gitbook.io/natural-language-processing-with-pytorch
