📌Self Attention
Transformer 은 attention 연산만 사용하여 seq2seq 구조를 구현하는 방법이다.
self attention 과 attention 의 차이점
-
attention 의 경우, output 문장과 관련된 input 문장과의 연관성을 측정한다. seq2seq 모델의 경우, input sequence 에 대해서, decoder part 에서 input sequence 와의 attention scores -> attention distribution -> attention output 을 생성한다.
-
self attention 의 경우, input sequence 에서 모델이 입력된 데이터 내의 각 요소가 서로 얼마나 연관되어있는지 학습하게 해주는 역할을 한다. 이때, self-attention 은 입력 데이터 내 모든 요소간의 관계를 동시에 고려하게 된다.
📌Transformer
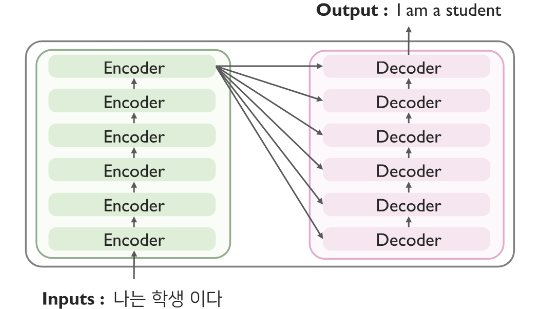
트랜스포머 역시, Encoder-Decoder 구조로 이루어져 있다.
단, Encoder Decoder 구조가, 개의 동일한 구조의 모듈로 이루어져 있다.
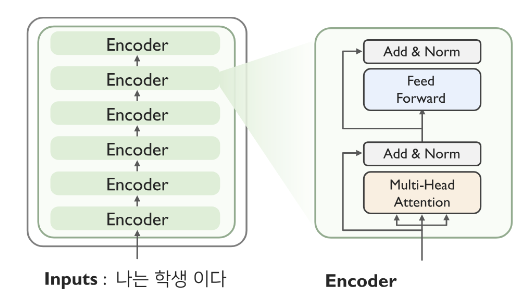
Encoder 의 sublayer 은 크게 2가지로 이루어져 있다.
(1) Multihead attention
(2) Feed Forward Network(Fully connected)
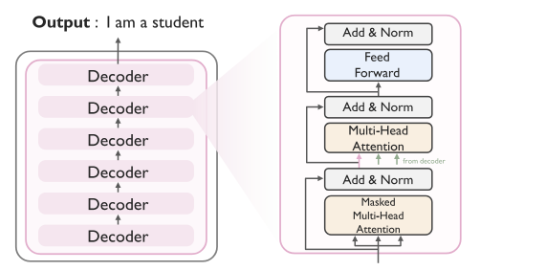
Decoder 의 sublayer 은 크게 3가지로 이루어져 있다.
(1) Masked multihead attention
(2) Encoder - Decoder attention
(3) Feed Forward Network(Fully connected)
다음은, Encoder - Decoder 구조의 전체적인 도식화이다.
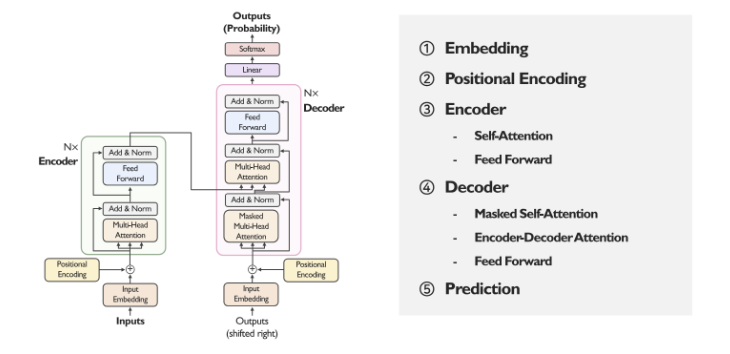
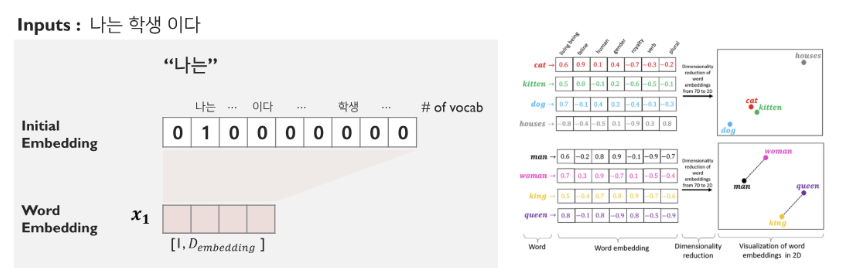
1. Embedding
-
단어(토큰) 형태의 데이터를 수치적으로 변환한다.
-
초기에는 원-핫 벡터의 형태이며, embedding layer 을 통해 학습된다.
-
유사 단어는 유사한 값을 가지도록 embedding 이 수행된다.
-
nn.Embedding(vocab, d_model) -
2. Positional Encoding
- RNN 과 다르게, 단어간의 순서성이 부여되지 않았으므로, 직접 부여해준다.
- 순차성을 부여하고, -1~1 사이의 범위를 가지게 하도록 삼각함수를 활용한다.

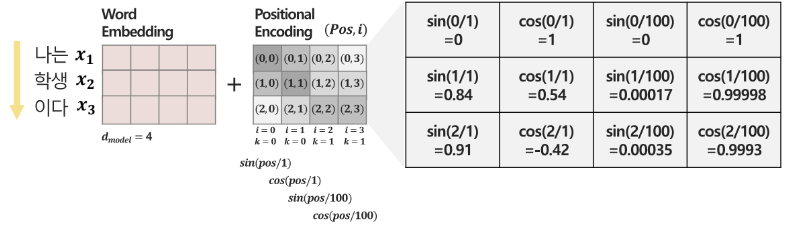
- positional encoding 의 경우, 모든 위치에서 인코딩 벡터의 크기가 동일해야 한다 -> 워드 임베딩에 내재된 정보의 훼손을 막기 위해 (sin, cos 을 돌려 쓰는 이유)
- 두 단어 사이의 거리가 멀수록 해당 단어들의 포지션 인코딩 간 거리가 멀어야한다.
3.1. Encoder : Self-Attention
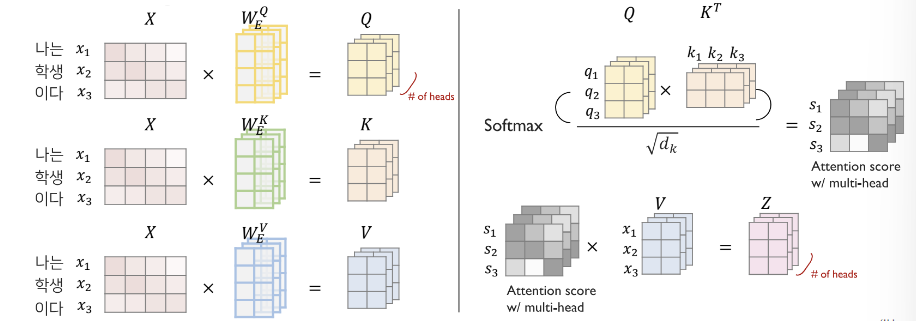
- Encoder 로 들어온 input sequence 에 대해서, embedded 된 토큰들에게 모두 라는 linear function 을 사용해 Query,Key,Value 를 얻는다.
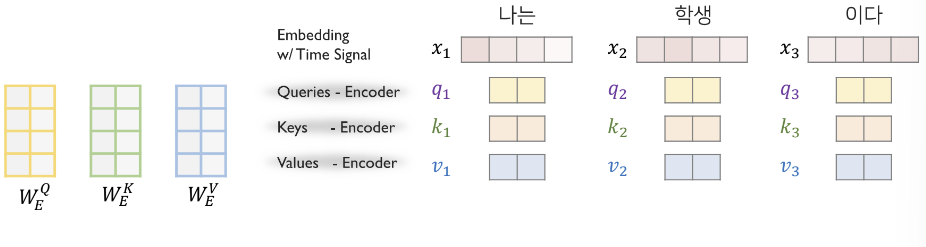
- Multi head attention 구조로 확장시키는 경우, 가 num_head 만큼 존재하게 된다.
- = // num_head
- Attention score =
- Attention value = (Attention score) =
- 이후, 들을 모두 concat 연산한 후에, 를 곱해서 , 출력
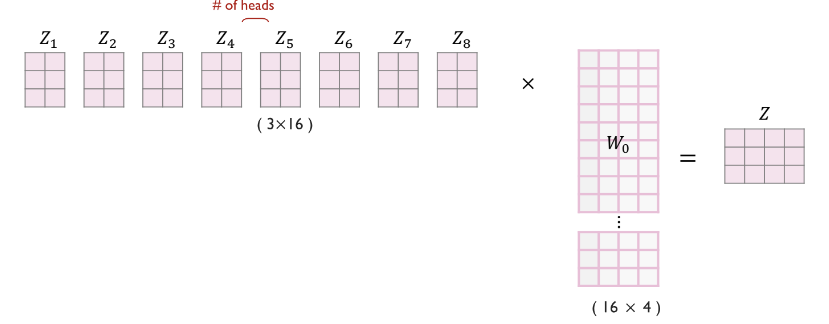
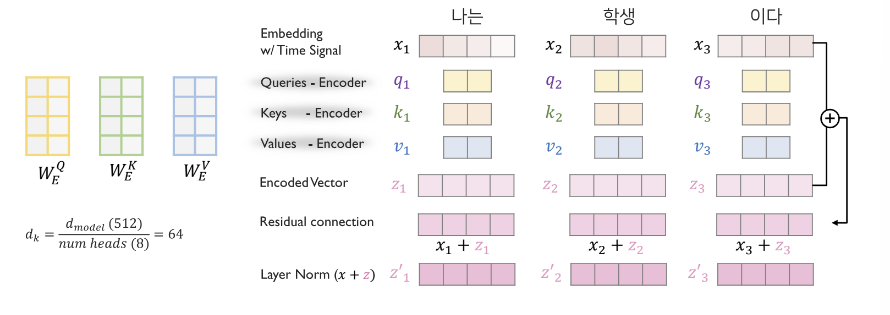
- Multihead attention 이 끝나면, Add & Norm, Residual connection(원 벡터 를 더하는 것) 과 LayerNorm(정규화) 를 처리한다.
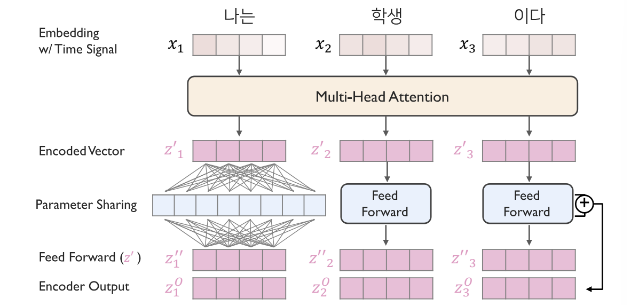
3.2. Encoder: Feed Forward Network
- 각 단어에 대응되는 값들을 개별적으로 FFN 을 적용하여 비선형성을 부여한다.
- FFN 이후에도 Residual connection 과 LayerNorm 처리를 진행한다.
4.1. Decoder: Masked Self-Attention
- Decoding 을 진행할때는, 뒤에 나오는 단어에 대해서 cheating 을 방지하기 위해서 masking 기법을 사용한다.
- Attention score 를 시점 이후 시점부터 으로 처리하여, softmax 연산을 진행하면 0 의 가중치를 가지게 한다.
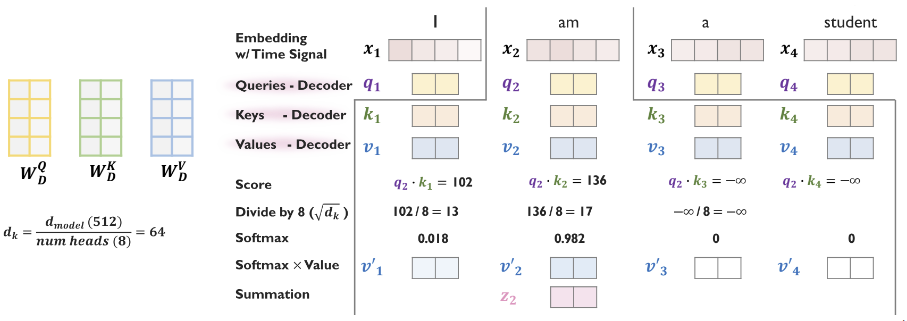
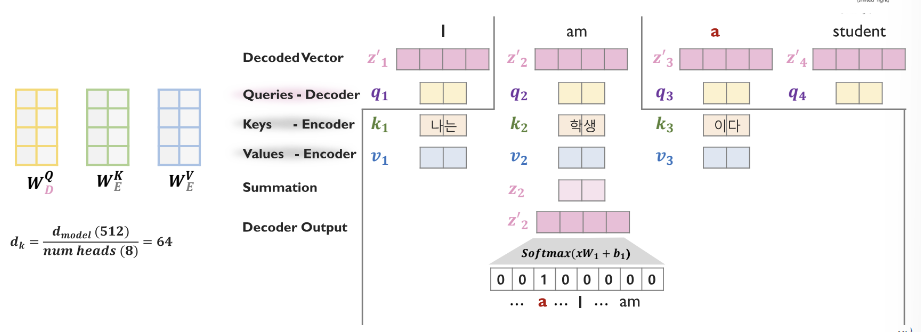
4.2. Decoder: Encoder-Decoder Attention
- 이미 한번 Masked Self-Attention 을 통과한 , Decoded Vector 에 대해서 attention 을 한번 더 수행한다.
- Query 행렬 는 decoder 의 query 행렬을 사용한다.
- Encoding 의 정보를 고려하기 위해서 Key 와 Value 행렬은 로 encoder 의 key, value 행렬을 사용한다.

4.3. Decoder: Prediction
- 해당 모듈은 수행하고자하는 Task 에 따라 변형이 가능하다.
📌Dimention
-
입력 임베딩
- 입력 텍스트가
X ∈ ℝ^{batch_size × seq_len × d_model}형태로 임베딩.
- 입력 텍스트가
-
Multi-Head Attention
a. Q, K, V 생성- Query:
Q = X @ W_Q, 여기서W_Q ∈ ℝ^{d_model × d_model}. 결과는Q ∈ ℝ^{batch_size × seq_len × d_model}. - Key:
K = X @ W_K, 여기서W_K ∈ ℝ^{d_model × d_model}. 결과는K ∈ ℝ^{batch_size × seq_len × d_model}. - Value:
V = X @ W_V, 여기서W_V ∈ ℝ^{d_model × d_model}. 결과는V ∈ ℝ^{batch_size × seq_len × d_model}.
b. 헤드로 분할
- Q, K, V를
num_heads로 나눠서 차원 변경, transpose(1,2)Q ∈ ℝ^{batch_size × num_heads × seq_len × d_k}, 여기서d_k = d_model / num_headsK ∈ ℝ^{batch_size × num_heads × seq_len × d_k}V ∈ ℝ^{batch_size × num_heads × seq_len × d_k}
c. Self-Attention 계산
- Attention Scores:
attention_scores = (Q @ K^T) / sqrt(d_k), 여기서attention_scores ∈ ℝ^{batch_size × num_heads × seq_len × seq_len} - Softmax:
softmax(attention_scores) - Attention Output:
attention_output = softmax(attention_scores) @ V, 결과는attention_output ∈ ℝ^{batch_size × seq_len × num_heads × d_k}
- Query:
-
Concatenation and Linear Transformation
- 헤드 Concatenation:
attention_output을 헤드별로 Concatenate 해서[batch_size × seq_len × d_model]로 변환 - Linear Transformation:
output = attention_output @ W_O, 여기서W_O ∈ ℝ^{d_model × d_model}. 결과는output ∈ ℝ^{batch_size × seq_len × d_model}
- 헤드 Concatenation:
-
Position-wise Feedforward Network
- Feedforward Network:
output을 두 개의 Linear Layer를 통과시키며[batch_size × seq_len × d_model]로 유지됨.
- Feedforward Network:
-
Add & Norm
- Residual Connection과 Layer Normalization을 통해 최종 출력이
[batch_size × seq_len × d_model]로 유지됨.
- Residual Connection과 Layer Normalization을 통해 최종 출력이
import torch
import torch.nn as nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(SelfAttention, self).__init__()
self.num_heads = num_heads
self.d_k = d_model // num_heads
# Linear layers for Q, K, V
self.W_Q = nn.Linear(d_model, d_model)
self.W_K = nn.Linear(d_model, d_model)
self.W_V = nn.Linear(d_model, d_model)
# Output linear layer
self.W_O = nn.Linear(d_model, d_model)
def forward(self, X):
batch_size, seq_len, d_model = X.size()
# Linear projections
Q = self.W_Q(X) # [batch_size, seq_len, d_model]
K = self.W_K(X) # [batch_size, seq_len, d_model]
V = self.W_V(X) # [batch_size, seq_len, d_model]
# Reshape and transpose for multi-head attention
Q = Q.view(batch_size, seq_len, self.num_heads, self.d_k) # [batch_size, seq_len, num_heads, d_k]
K = K.view(batch_size, seq_len, self.num_heads, self.d_k) # [batch_size, seq_len, num_heads, d_k]
V = V.view(batch_size, seq_len, self.num_heads, self.d_k) # [batch_size, seq_len, num_heads, d_k]
Q = Q.permute(0, 2, 1, 3) # [batch_size, num_heads, seq_len, d_k]
K = K.permute(0, 2, 3, 1) # [batch_size, num_heads, d_k, seq_len]
V = V.permute(0, 2, 1, 3) # [batch_size, num_heads, seq_len, d_k]
# Scaled dot-product attention
scores = torch.matmul(Q, K) / self.d_k**0.5 # [batch_size, num_heads, seq_len, seq_len]
attention_weights = F.softmax(scores, dim=-1) # [batch_size, num_heads, seq_len, seq_len]
attention_output = torch.matmul(attention_weights, V) # [batch_size, num_heads, seq_len, d_k]
# Concatenate heads and pass through final linear layer
attention_output = attention_output.permute(0, 2, 1, 3) # [batch_size, seq_len, num_heads, d_k]
attention_output = attention_output.contiguous().view(batch_size, seq_len, d_model) # [batch_size, seq_len, d_model]
output = self.W_O(attention_output) # [batch_size, seq_len, d_model]
return output
# Example usage:
d_model = 512
num_heads = 8
batch_size = 2
seq_len = 10
self_attention = SelfAttention(d_model, num_heads)
X = torch.rand(batch_size, seq_len, d_model)
output = self_attention(X)
print(output.shape) # Should print: torch.Size([batch_size, seq_len, d_model])📚출처
이유경 멘토님 자료
https://github.com/pilsung-kang/Text-Analytics/tree/master/08%20Seq2Seq%20Learning%20and%20Pre-trained%20Models
https://www.phontron.com/class/anlp2022/index.html
https://web.stanford.edu/class/cs224n/
https://kh-kim.gitbook.io/natural-language-processing-with-pytorch
