Exponential Family
p(x;θ)=exp(θTT(x)−A(θ))h(x)
- A(θ) is called log partition function.
- T(x) is called sufficient statistics.
- A(θ) is convex.
- A(θ)'s first derivative with respect to θ is Expectation of T(x), and second derivative with respect to θ is the Variance of T(x).
- Since A(θ) is (1) a function of the natural parameter, θ, (2) convex function, we can solve the following equation, and obtain an expression for the natural parameter, θ using the moment parameter, μ.
dθdA(θ)=μ Solving for θ, we can obtain,θ=ψ(μ)
In short, for a random variable X that is from natural exponential family distribution, the moment generating function is given by the following:
-Note that natural exponential family distribution has sufficient statistics, T(x)=x
Recall that the definition of Moment Generating Function is given as follows
Mx(t)=E(exp(tx))=1+tm1+2!t2m2+...
Applying the moment generating function to T(x),
MT(x)(t)=E(exp(T(x)t))=exp(A(t+θ)−A(θ)).
Furthermore,
E(T(x))=E(X)=A′(θ)Var(T(x))=Var(X)=A′′(θ)
- MLE (Maximum Likelihood Estimation) for exponential family is the same as moment matching.
(a) Log likelihood of a generic exponential family: const+θT(∑T(xi))−nA(θ)
(b) Taking the gradien w.r.t. θ: ∑T(xi)−nΔθA(θ)
(c) Setting equal to zero and solving for ΔθA(θ): ΔθA(θ)=n1∑T(xi)→μ=n1∑T(xi)
Bayesian POV
After writing down the likelihood of the dta given the natural parameter, we want to pick a prior over the natural parameter, and work out the posterior over the natural parameter.
P(x∣θ)∼exp(θTT(x)−A(θ))P(θ)∼exp(λTT(θ)−A(λ))P(θ∣x,λ)∼exp(θTT(x)+λTT(θ)+A(θ)+A(λ))
Generalized linear models (GLIM)
Components
- Linear predictor: Linear function of regressors,
λi=α+β1Xi1+...+βkXik
- Link function: Transforms the expectation of the response variable, μi=E(Yi) to the linear predictor. In other words, the link function linearizes the expectation of the response variable:
g(μi)=λi=α+β1Xi1+...+βkXik
- Because the link function is invertible, we can write
μi=g−1(λi)=g−1(α+β1Xi1+...+βkXik)
Assumptions
Y∼exponentialFamilyλ=ψ(μ=f(ϵ=θTx))
where Y are the responses, x are the fixed inputs, θ are parameters we need to learn, and f and ψ give us added flexibility if we want it.
Graphical Representation of GLM Models
We can describe the process as the following graph.
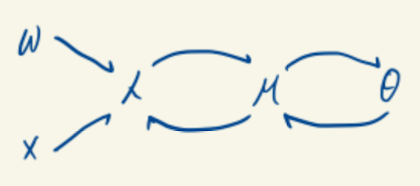
- W are the parameters.
- λ=WTX.
- μ is called standard parameters, and signifies the mean of Y∣X.
- θ is called natural parameters, that governs the shape of the density Y∣X. It can be the case that μ=θ (e.g.,normal), but this doesn't need to be true (Poisson distribution, for example).
- We are aiming to model a transformation of the mean, μ by finding g(μ) that satisfies θ=g(μ)=λ(X)=WTX.
MLE for Undirected Graphical Models###
1. Data
D={x(n)}n=1N
2. Model
In a typical setup for Undirected Graphical Models, it is bett
p(x∣θ)=Z(θ)1c∈C∏ψc(xc)
3. Objective
l(θ;D)=n=1∑Nlogp(x(n)∣θ)
4. Learning
θ∗=argmaxθ l(θ;D)
5. Inference
- Marginal Inference; Inference over the variables of interest.
p(xc)=x′:x′c=xc∑p(x′∣θ)
- Partition Function; Normalizing function for the Gibbs distribution obtained by factorization.
Z(θ)=x∑C∈c∏ψC(xC)
- MAP Inference; Compute variable assignment with highest probability.
