〰️ 내용 요약
[1] Loss Function

The question is, which Loss Function to use?
(1) Multiclass SVM loss (Hinge Loss)

car score(5.1) appears to be bigger than cat score(3.2) and this is bad
By the function, if the score is smaller than 2.2, loss equals 0.
So we can use this Loss Function to measure the loss.

Even worse, the classifier failed to output a high score(-3.1) for the frog. And this results in high loss

Final loss for the 3 training examples would be
the mean of the losses of each individual loss
The number 1 in this Multiclass SVM loss is arbitrary!
(2) Regularization
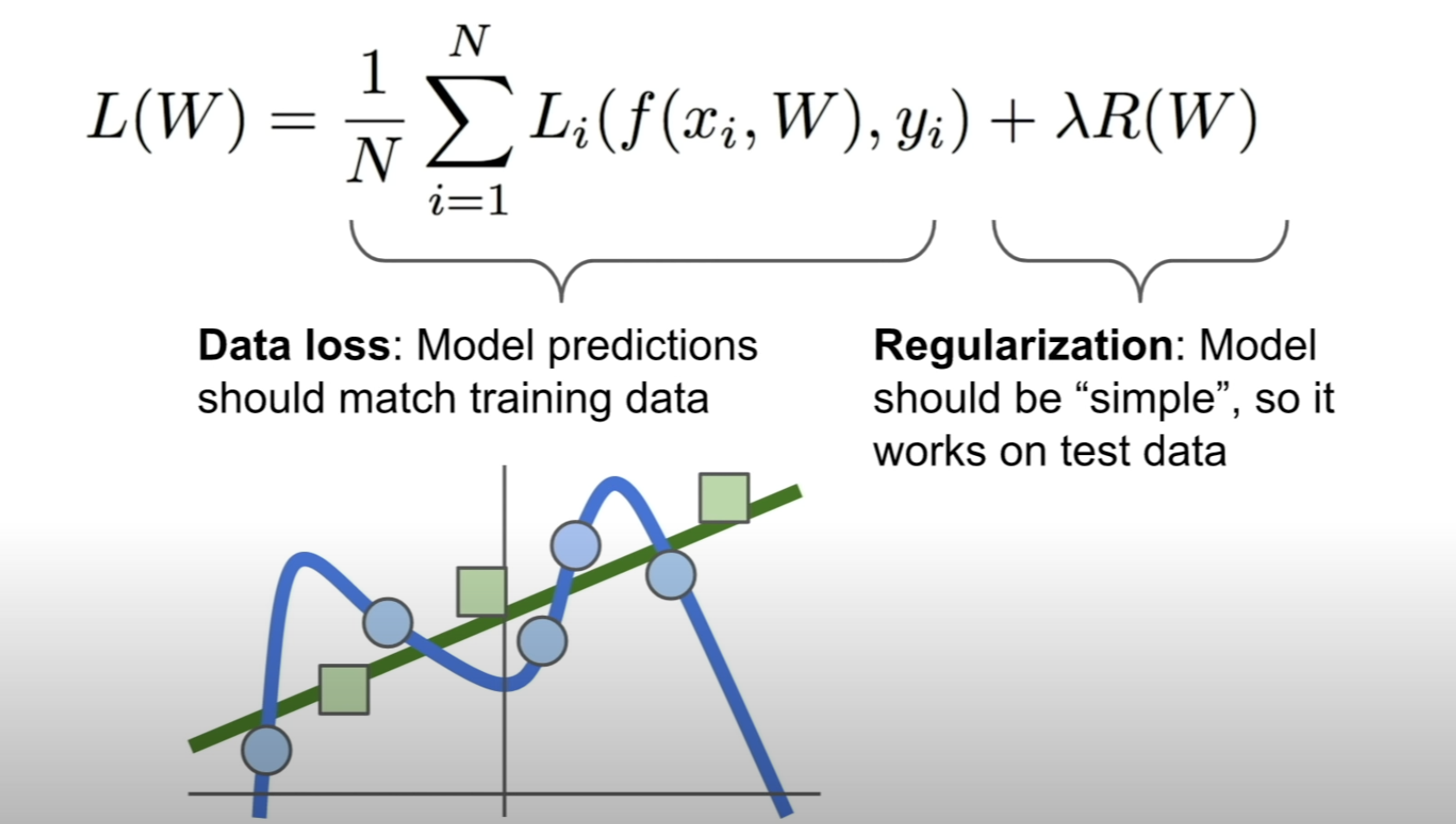
By just using the loss function, overfitting could happen which makes it hard for the model to generalize to new data
Regularization term is used to prevent this overfitting = penalize complex models
What kinds of Regularization are there?

(3) Multinomial Logistic Regression (Softmax Regression)
What's the difference?
Multiclass SVM loss...
1) focused on the loss, not the scores (what we could want)
2) not really probabilistic interpretation (intuitive)

We can think of two questions here
1) Why use the exponential?
2) Why use the log after normalization?
exponentials are used to make the outputs to positive
and calculating derivatives are quite easy
logs are used to penalize when the predictions are wrong

What it really means : maximize the log likelihood?
minimize the negative log likelihood?

Picture shows Binary Classification
(4) hinge loss vs cross-entropy loss
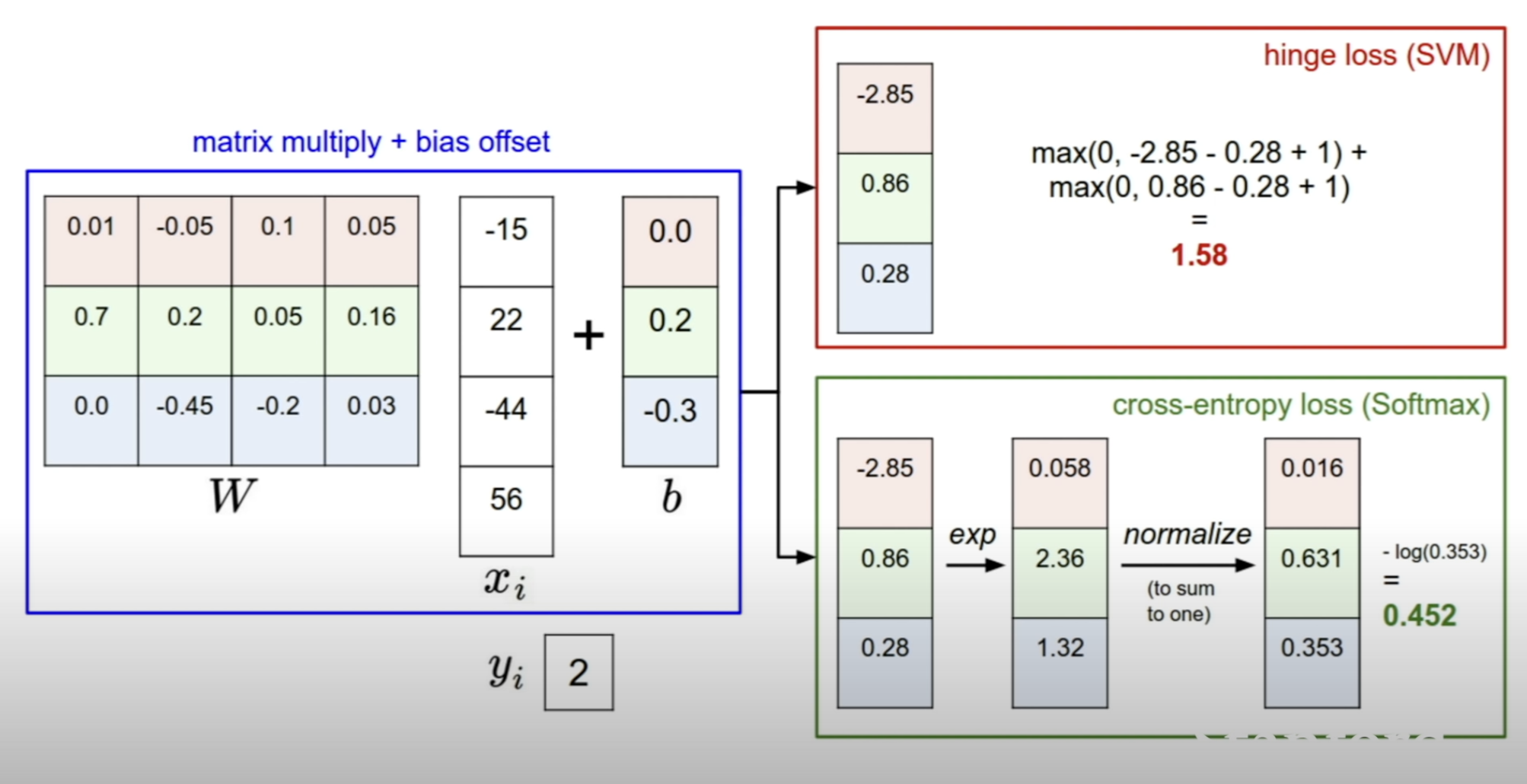
How is the [-2.85, 0.86, 0.28] interpreted?
SVM: look at the margins between the scores of the correct class and the scores of the incorrect class for penalizing
Softmax : compute the probability distribution and minus log probability
The calculation for cross-entropy loss follows
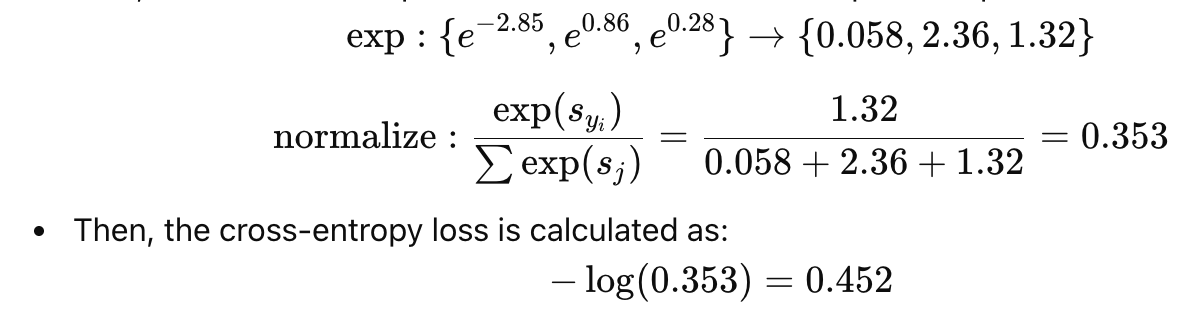
To recap what's been dealt

Use a linear classifier to get a score function to compute the scores depending on the input x
Then use the loss function to quantatively measure the predictions made
Now the question is, how to find the W that minimizes loss?
[2] Optimization
Gradient Descent
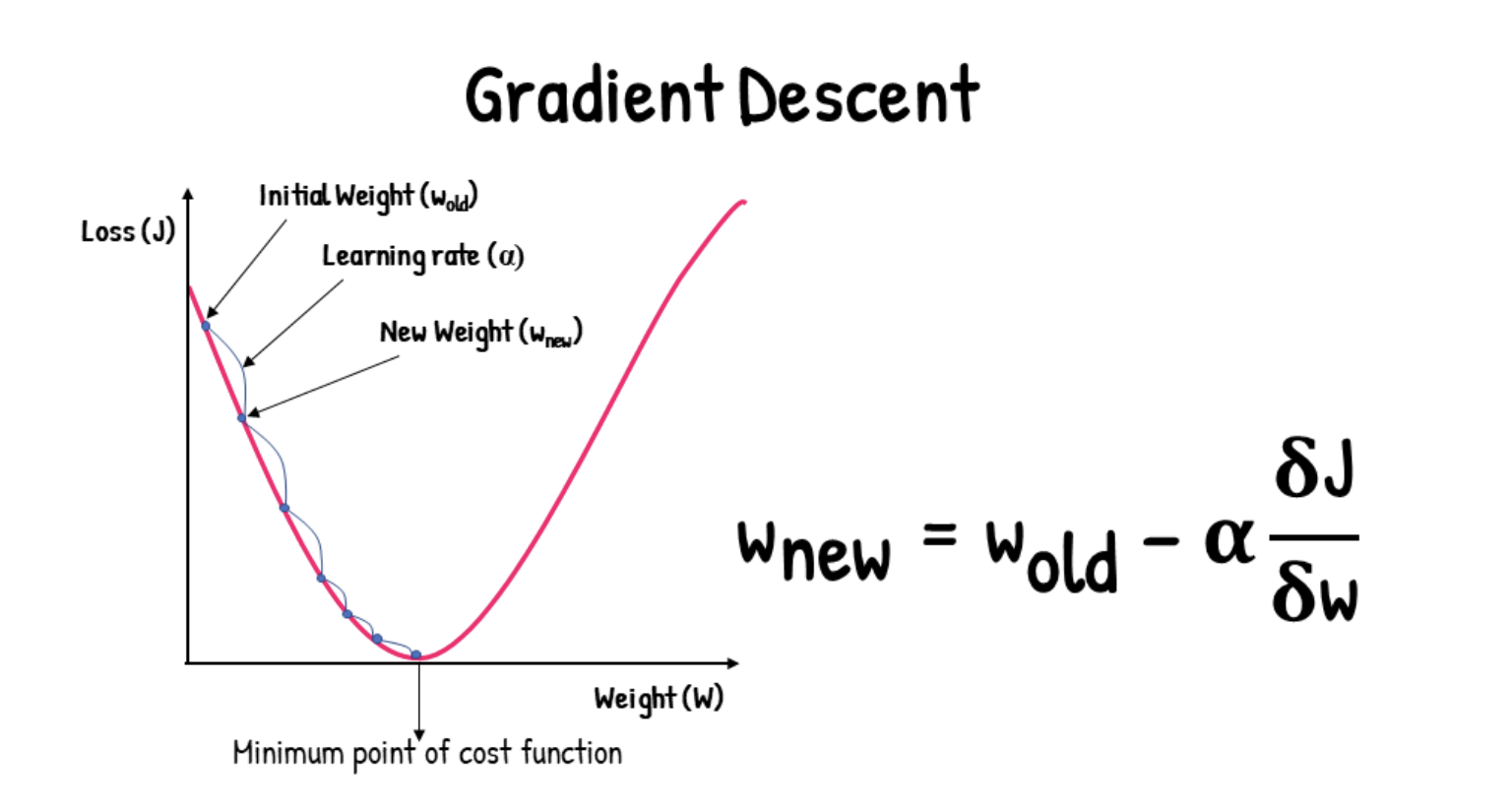
Step size (alpha) is the primary hyperparameter to decide
There are times when the dataset is large

This is when SGD comes in.
Using minibatch to estimate the total loss sum
〰️ 질문

As long as the difference between the score of car and other classes is higher than 1, the loss is zero. And this is due to the arbitrary number 1.

min loss : 0
when all the scores for the right class and other classes are bigger than 1.
This means the classifier has given a high score like the car case.
This also means the classifier is working well!
max loss : infinity

The loss would be # of classes - 1
And this is because there is one right class for each example, and each incorrect class contributes a loss of 1 at initialization when all scores are approximately zero.
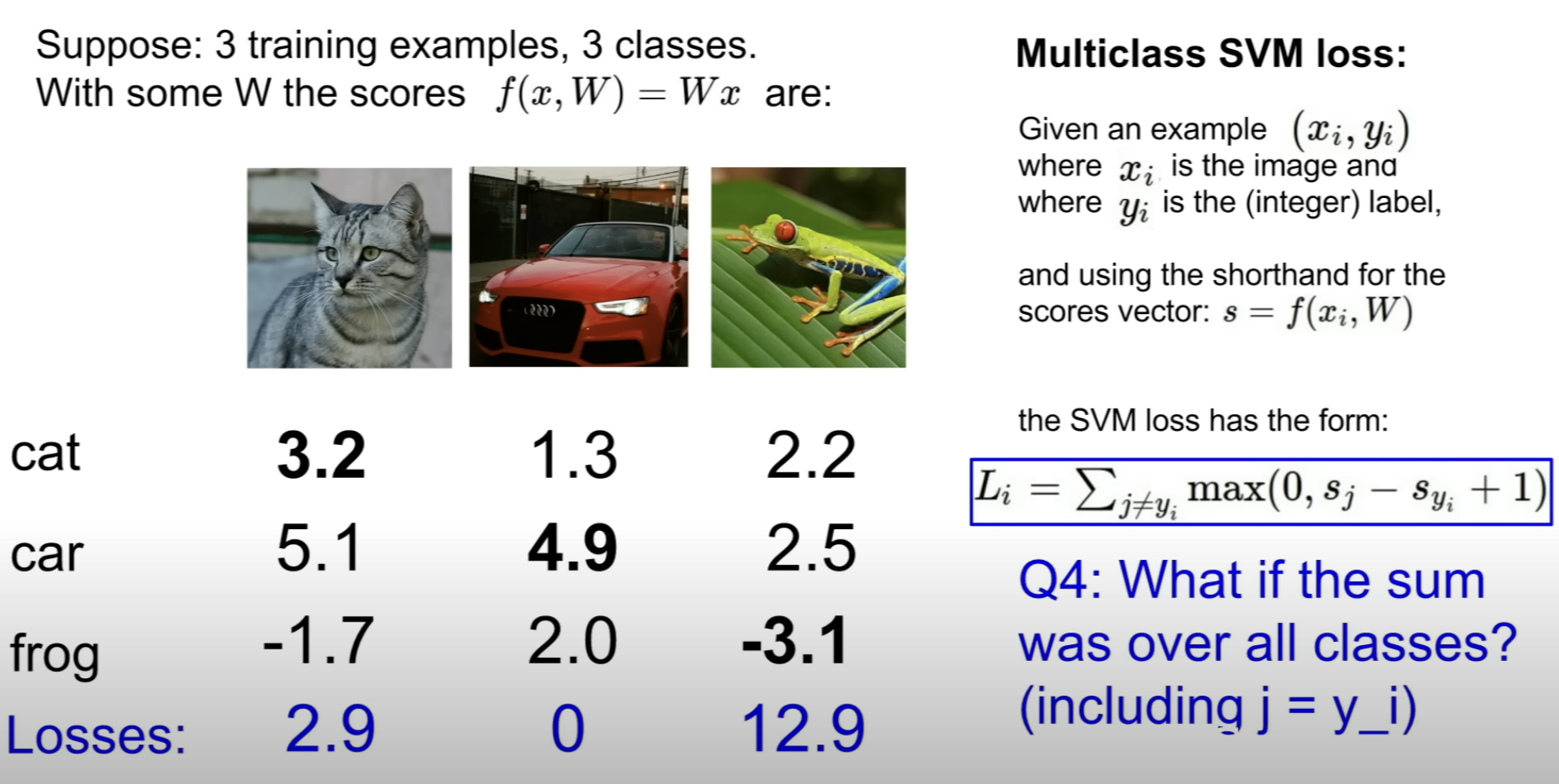
The loss increases by one when j = y_i.

This is squared hinge loss.
And this is a different loss function omitting different loss
Could be used when you want to penalize the misclassified output strongly

W is not unique!
Just to give an example, 2W & 0.5W also has L = 0

Theoretically, min = 0, max = inf
When the model predicts with probability 1 on the right label [1 0 0 ]
When the model predicts with probability 0 on the right label [0 1 0]

Evenly distributed over all the classes
Loss = log(# of classes)

〰️ 첨언
L1 Regularization vs L2 Regularization
L1 Regularization
asdf
L2 Regularization
asdf
Softmax & Cross-Entropy Loss
Softmax = Multinomial Logistic Regression
logits -> probability
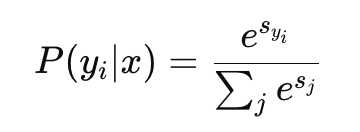
Cross-Entropy Loss
probability -> loss
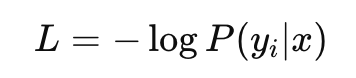
Then why -log?
An intuition used to "minimize" the loss
