〰️ Introduction

기존에 우리는 Supervised Learning을 배웠다. 이는 label이 존재하는 데이터
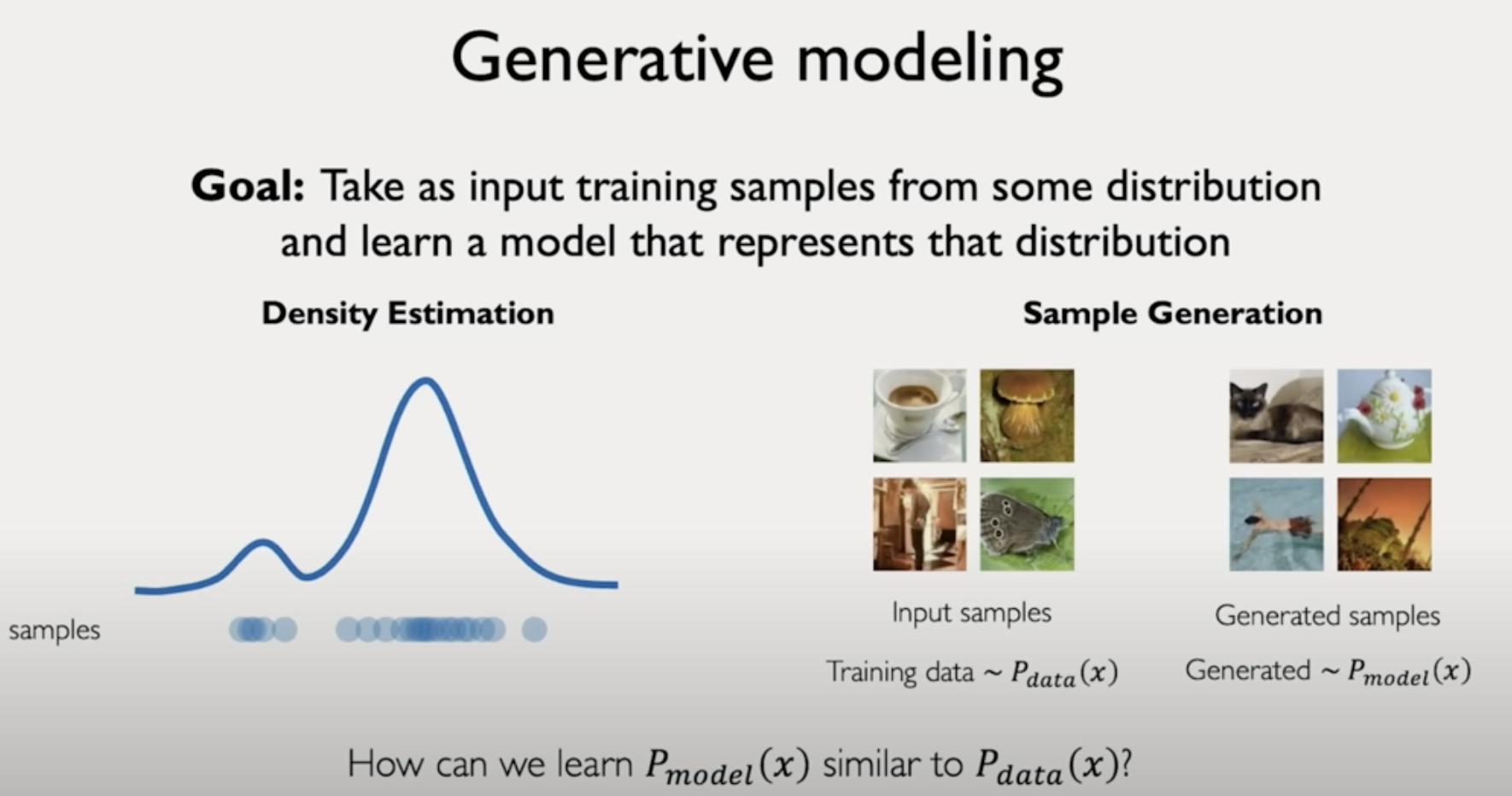
그렇다면 Generative Modeling의 목표는?
Goal : Take as input training samples from some distribution and learn a model that represents the distribution

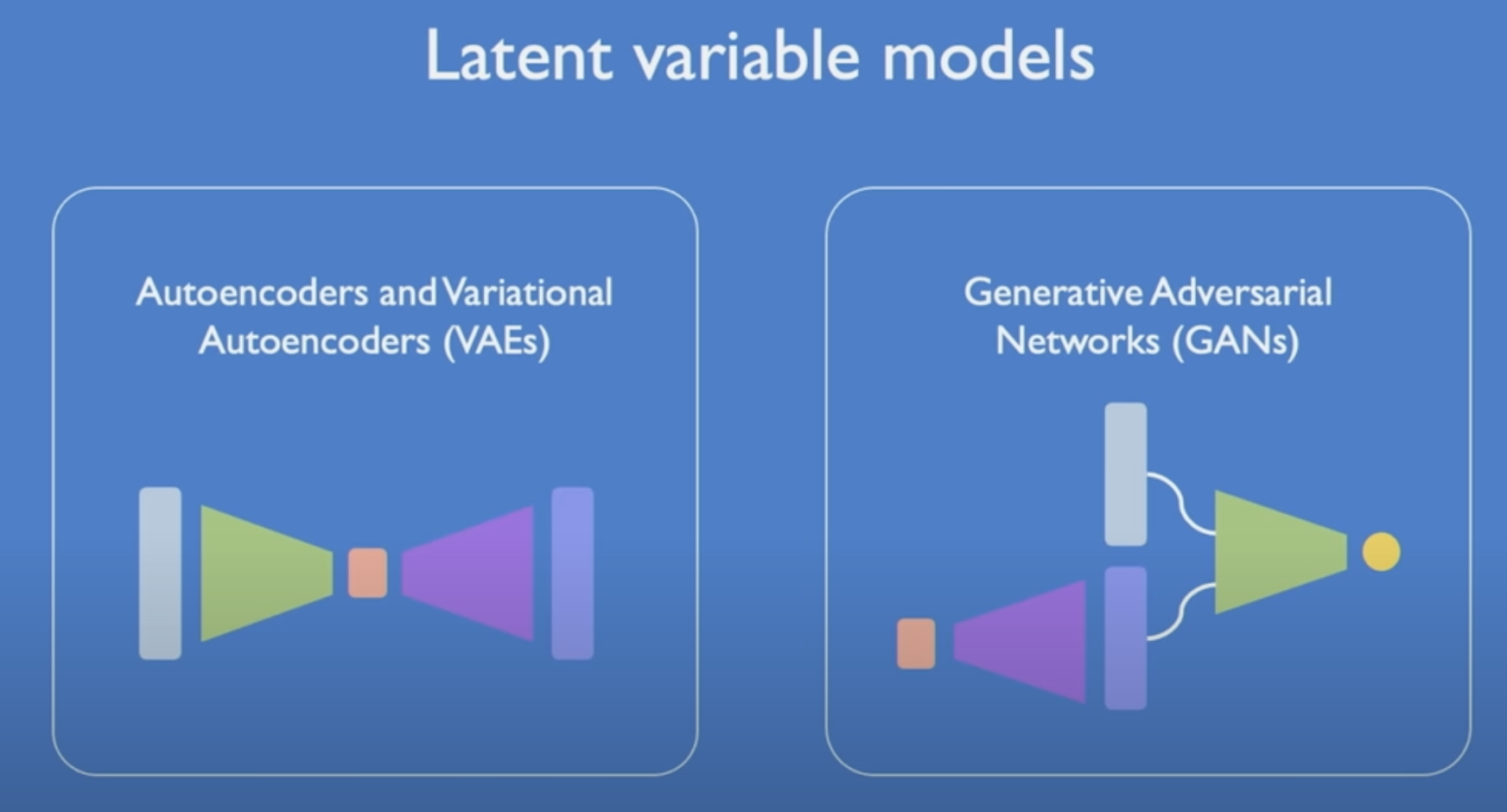
생성 모델의 2가지 기본 클래스에 대해 살펴볼 것이다.
〰️ latent variable

〰️ Autoencoders & VAEs
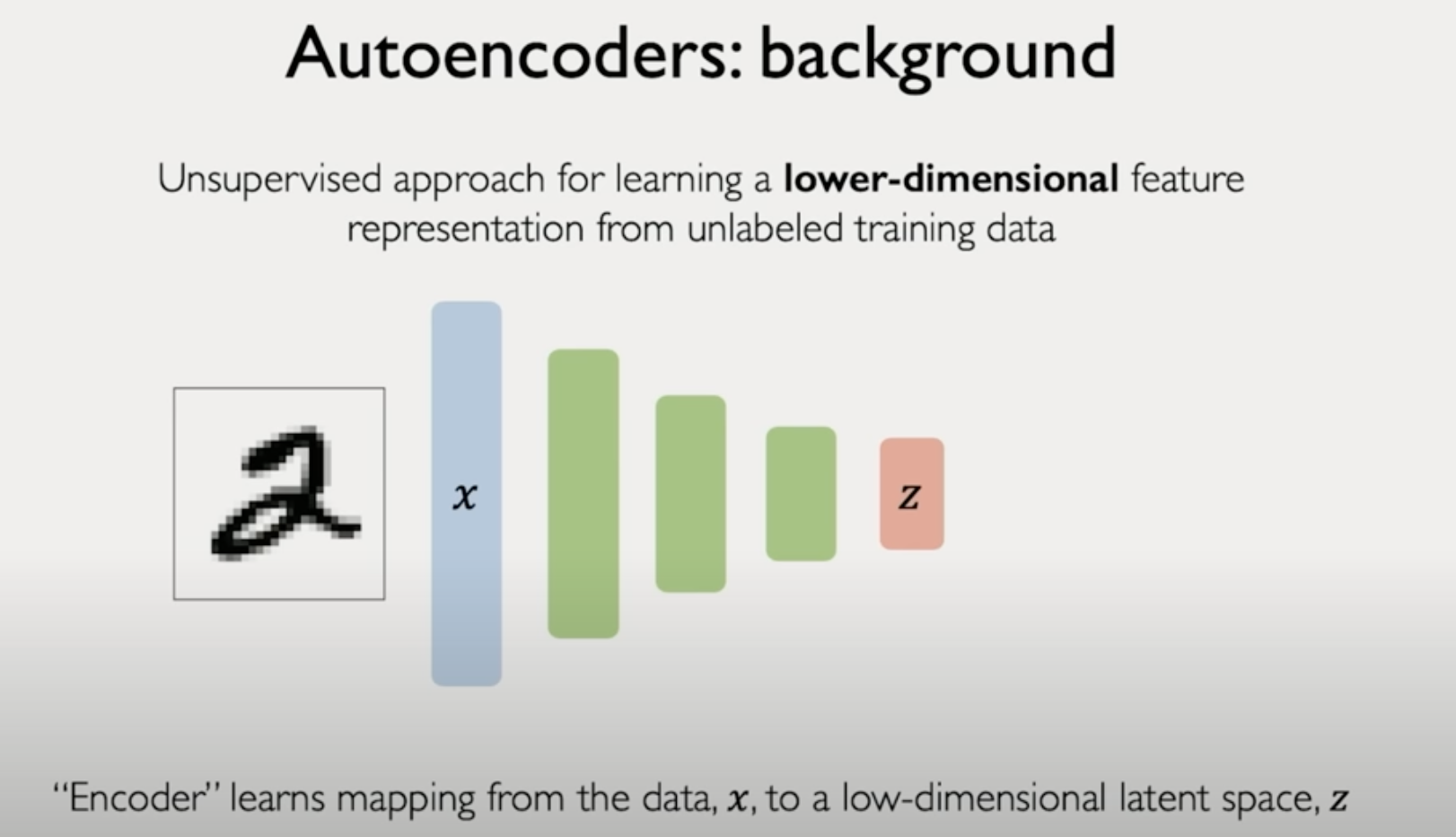
목표는 low-dimensional latent space, z를 얻는것
여기서 lower dimension을 해주는 것은 효과적으로 compressing 한다는 것
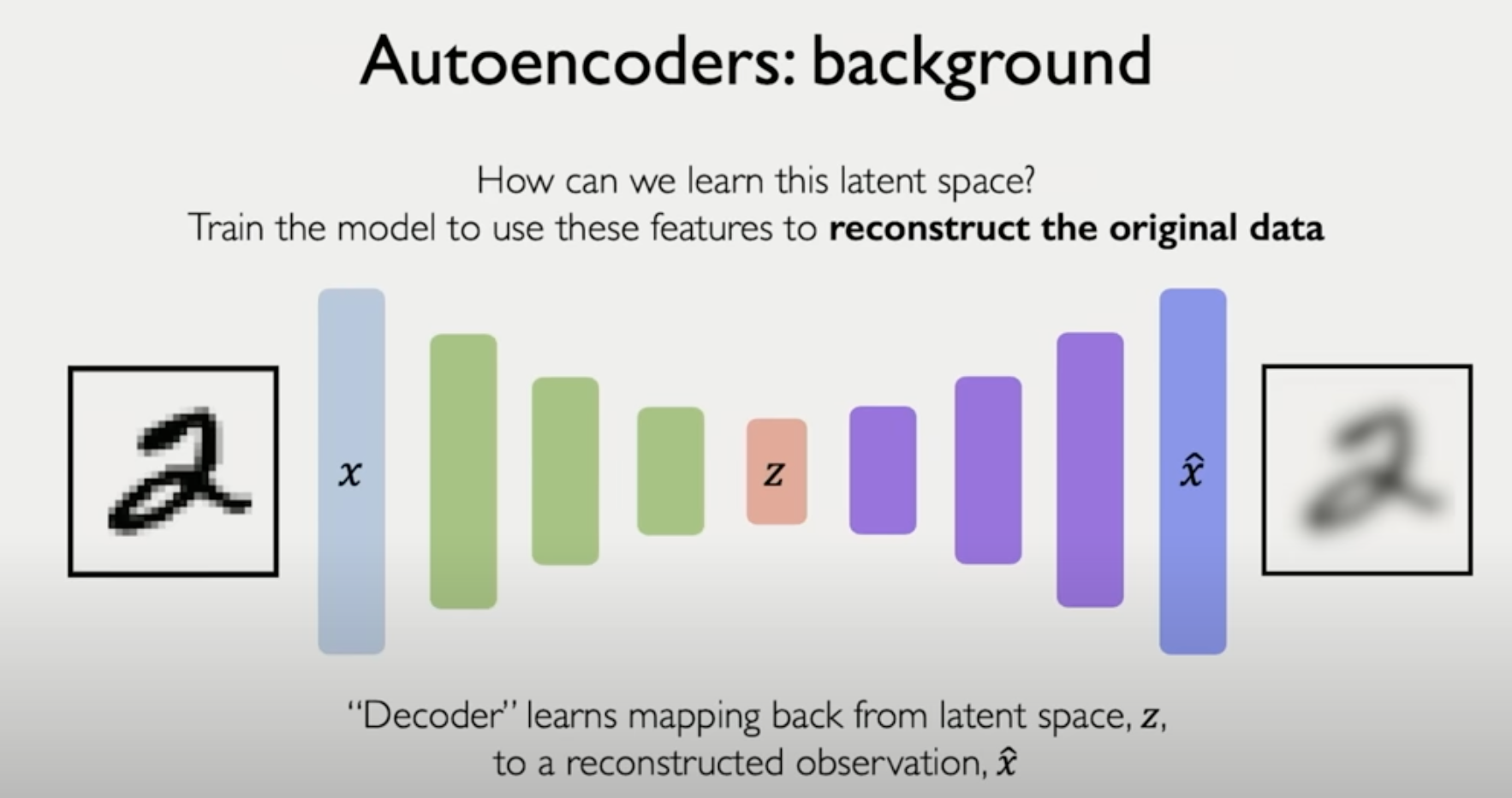
목표는 decoding model을 만들어서 사진을 원상복구 시키는것
그리고는 원본 사진과, 만들어진 사진을 비교하면서 거리가 최소화되게 학습할 수 있다.
거리를 측정하는데는 MSE를 사용할 수 있다.

이 사진에서는 compressing 차원이 낮아질수록, 재건축의 성능은 떨어진다.
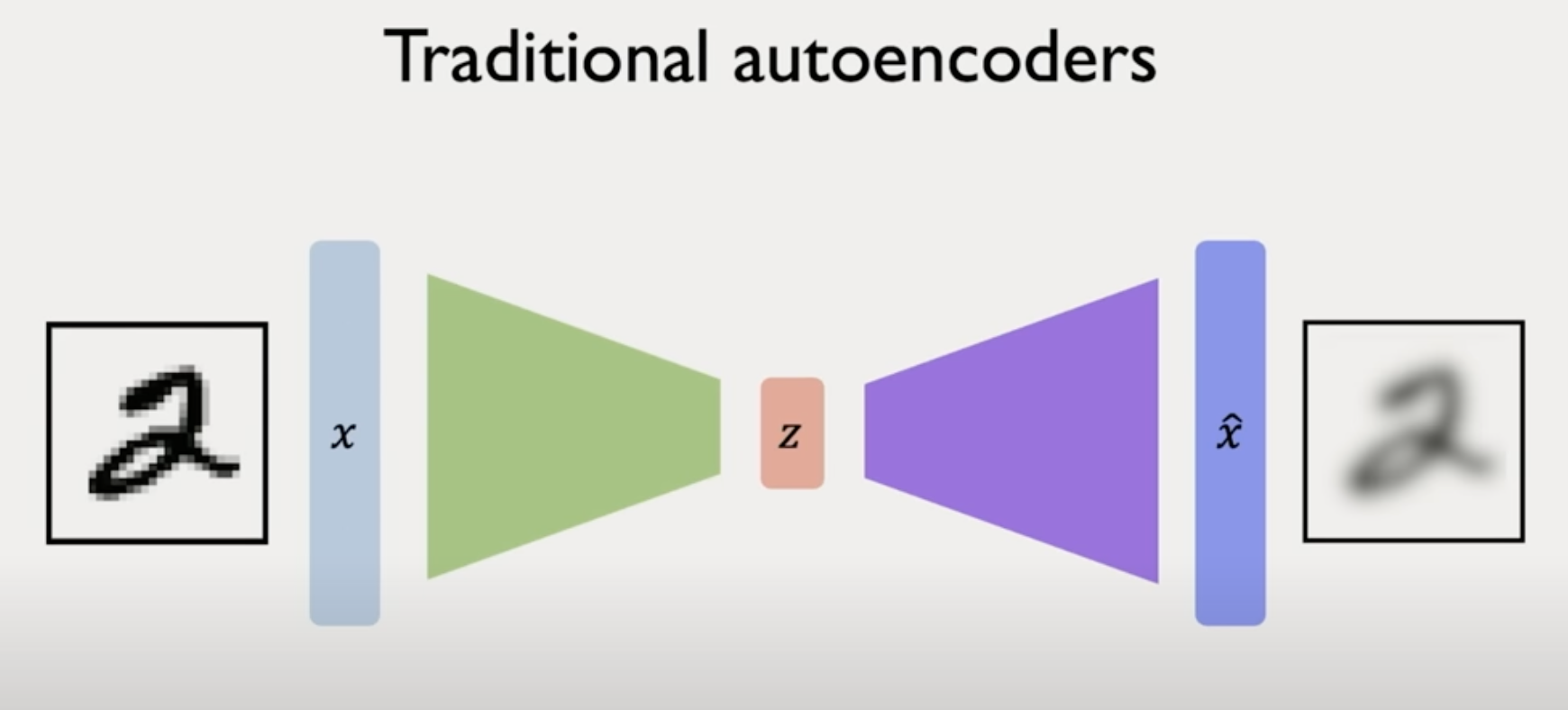
전통적인 autoencoder는 deterministic
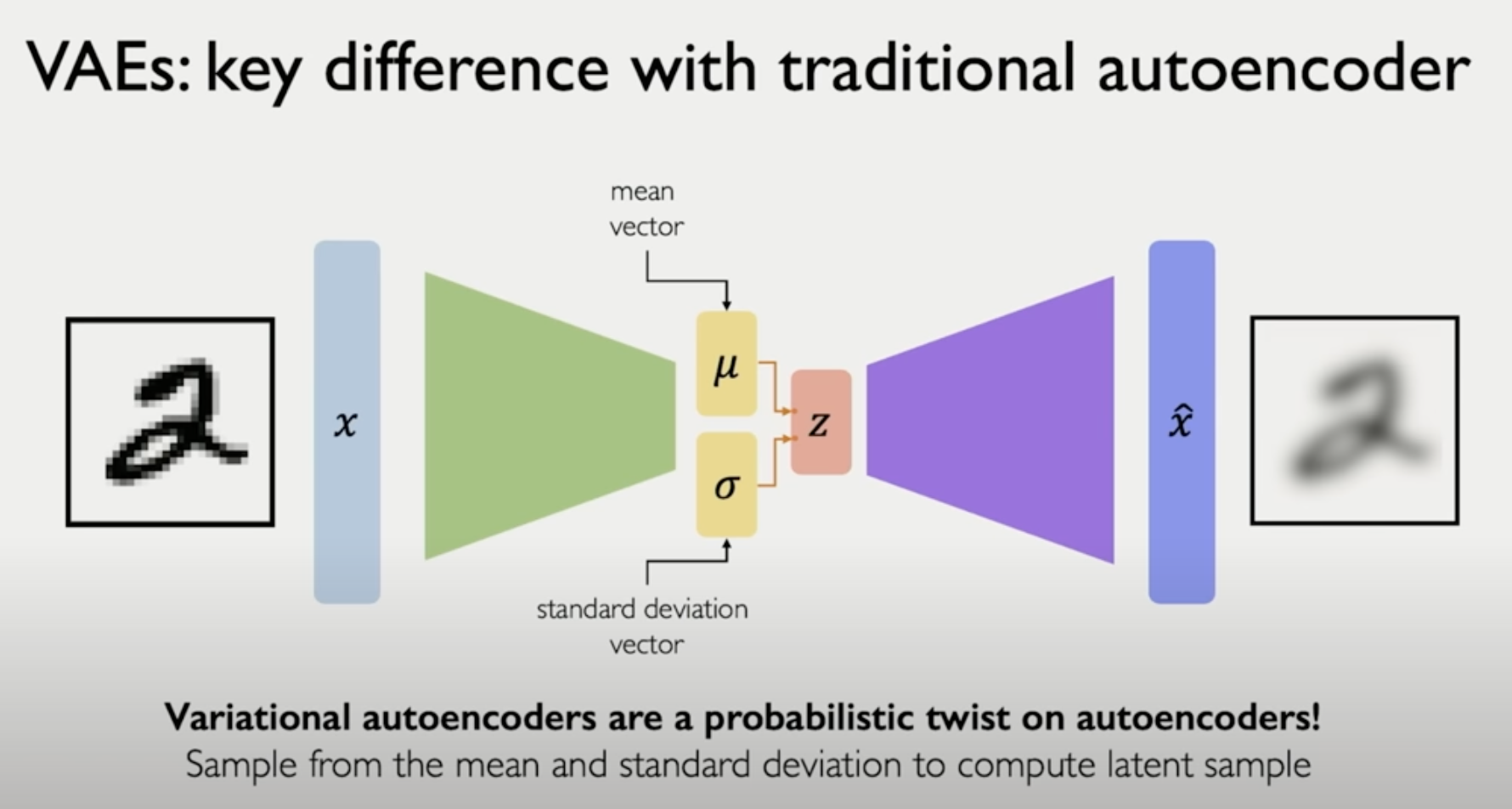
VAEs에서는 good quality의 latent space를 위해서 randomness를 더해준다.
stochasiticity를 더해준다고 한다.
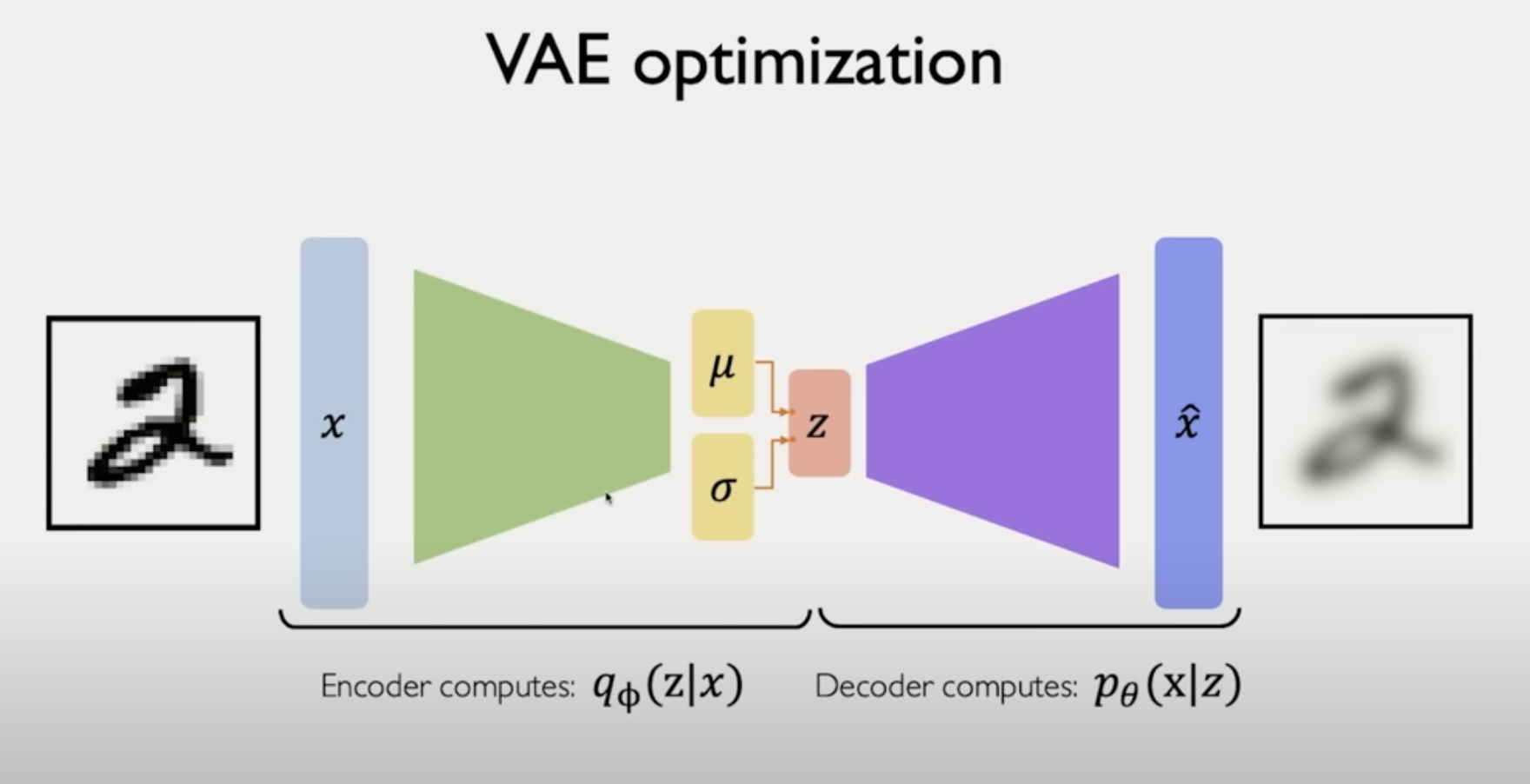
결국 encoder와 decoder는 확률 분포 (probability distribution) 을 배우는 것이다.
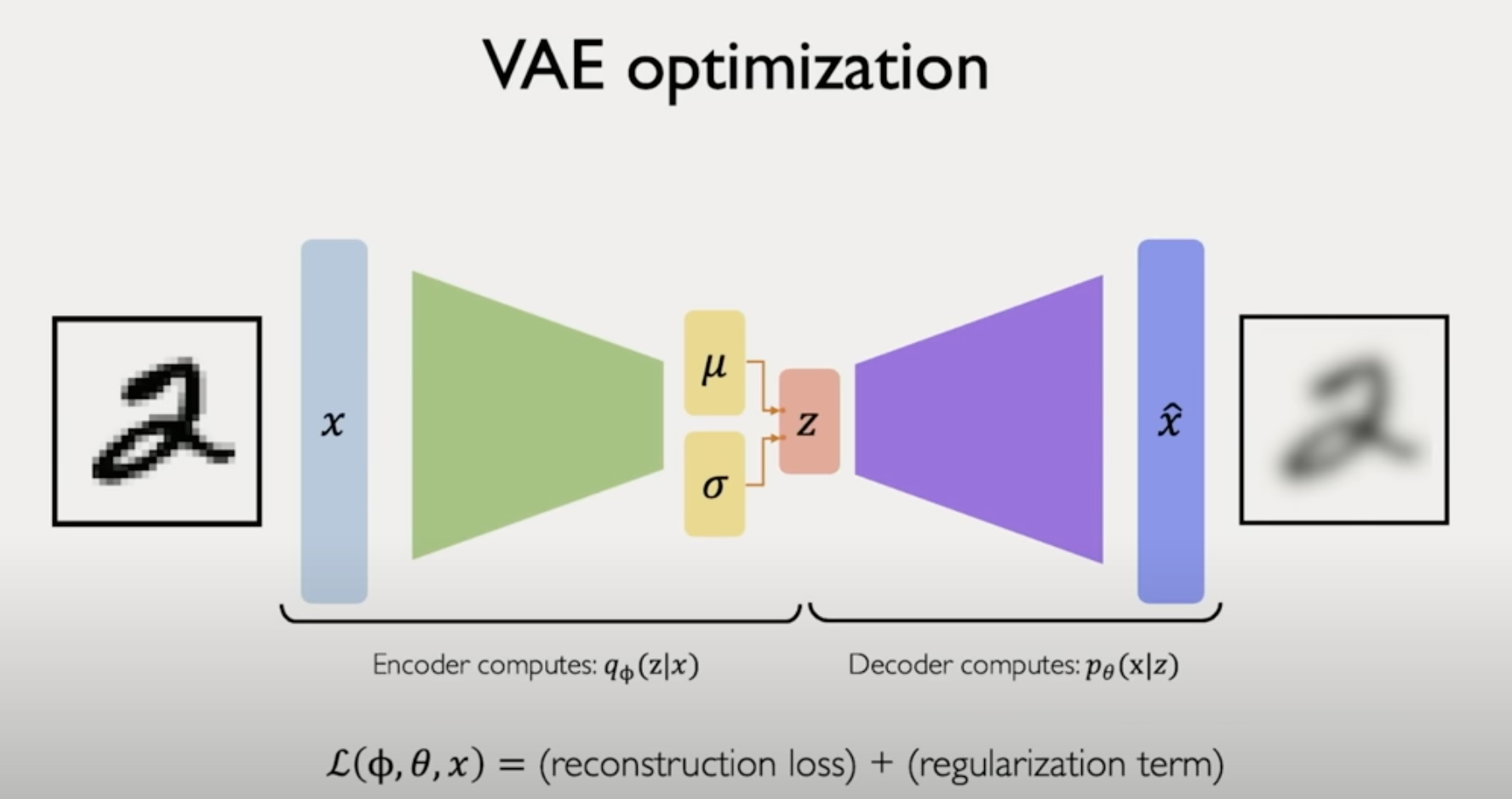
그래서 이 두 개의 확률 분포를 합치면, 하나의 Loss Function이 된다.


2개의 확률 분포 (probability distribution) 가 얼마나 가까운지를 측정하기 위해
KL-divergence 사용
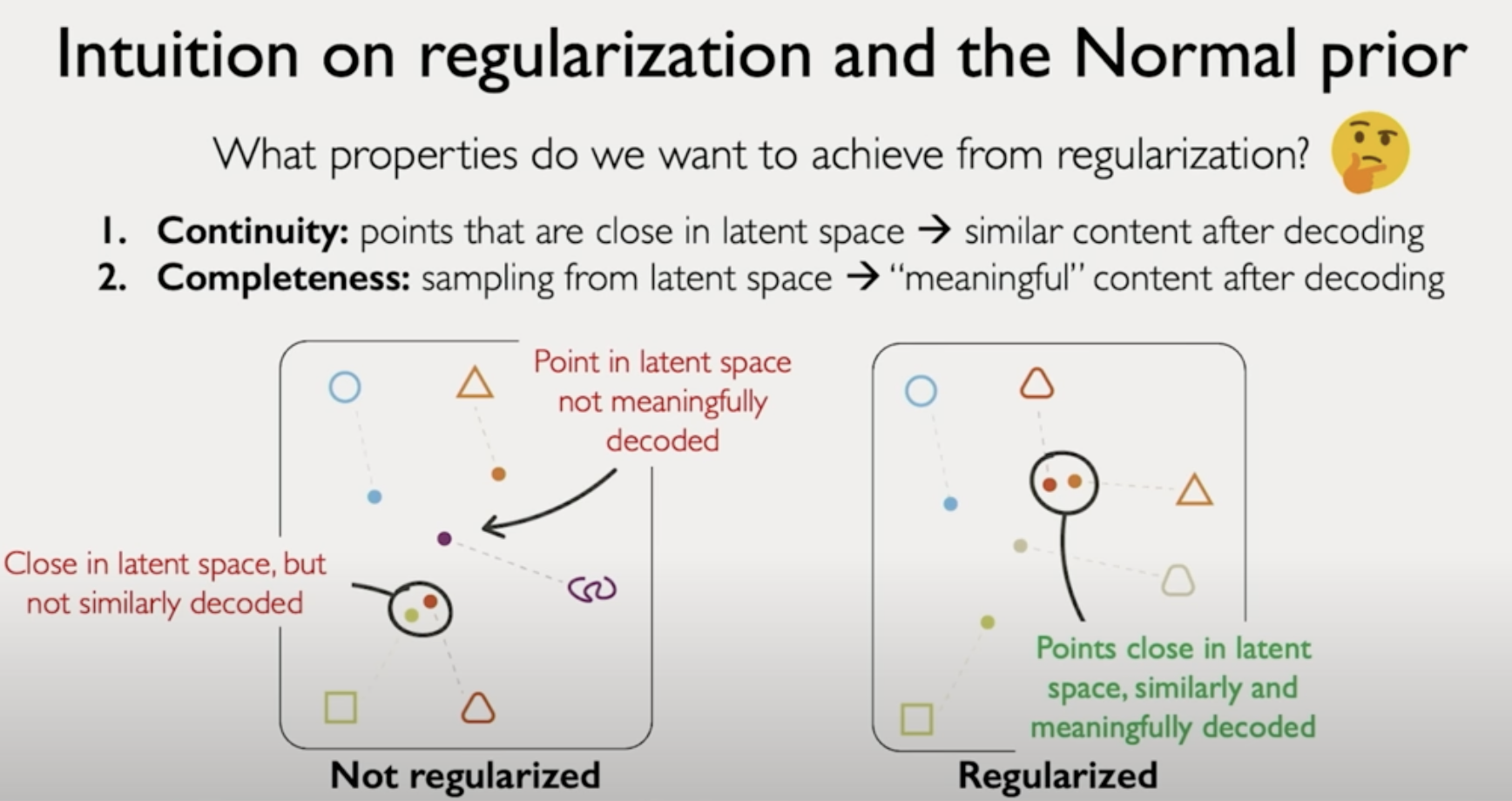
asdf
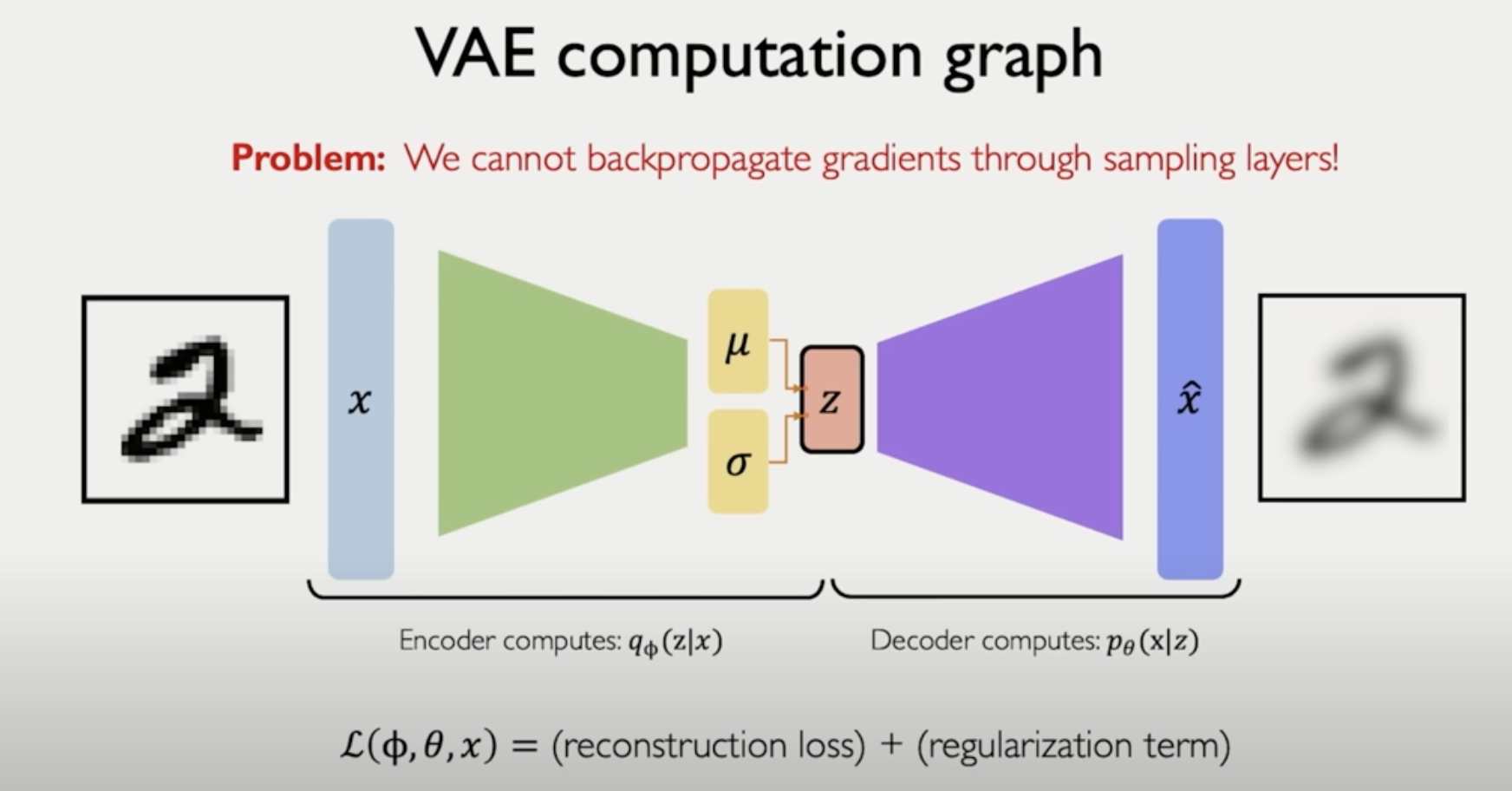
문제점
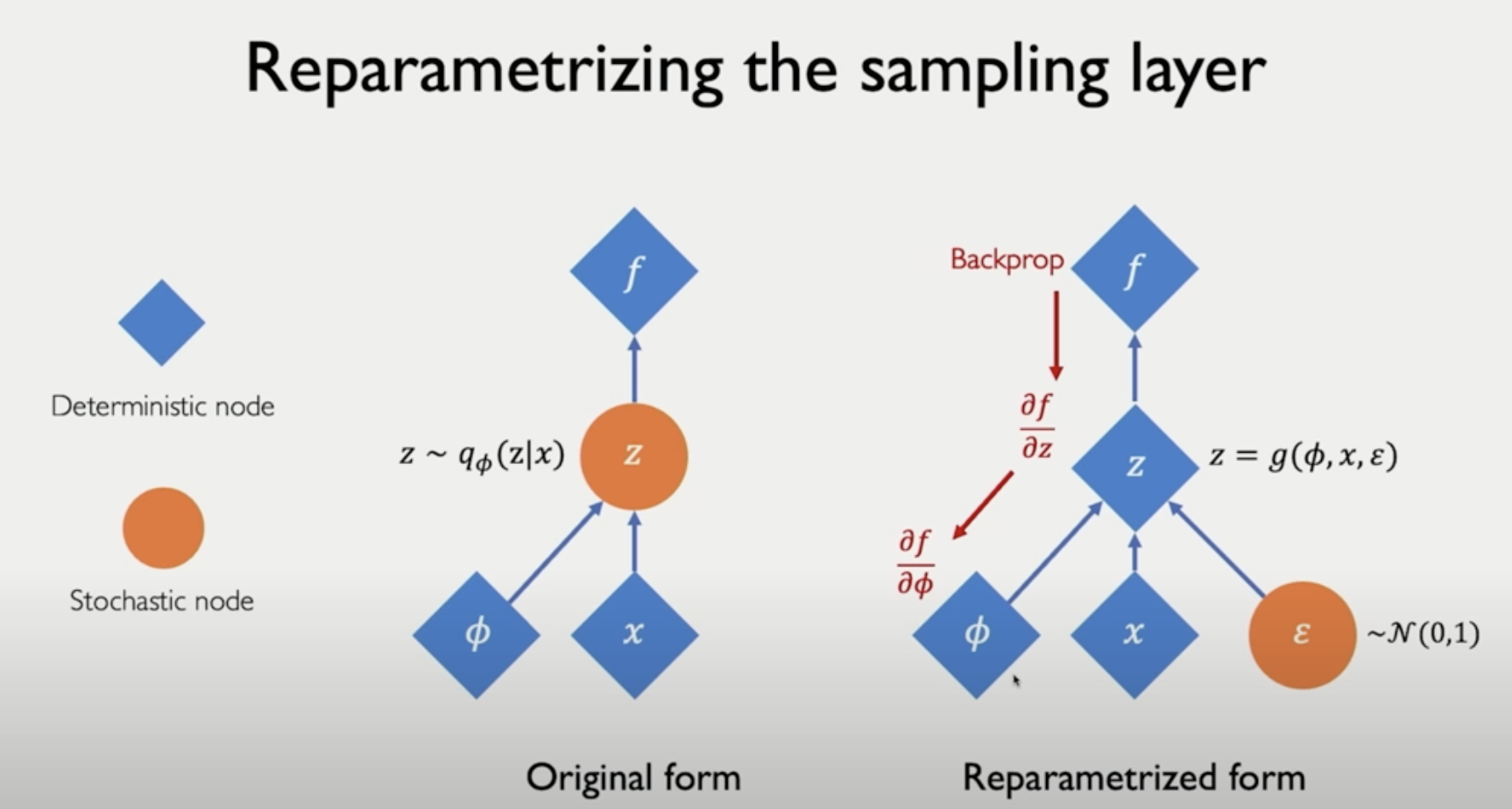
그래서 이렇게 바꾼다
