〰️ 내용
[1] Optimization
(1) Two problems with SGD

What's the problem with SGD?
SGD struggles when the gradient of the loss function varies significantly across different directions. In flatter directions, it progresses very slowly, while in steeper directions, it oscillates excessively
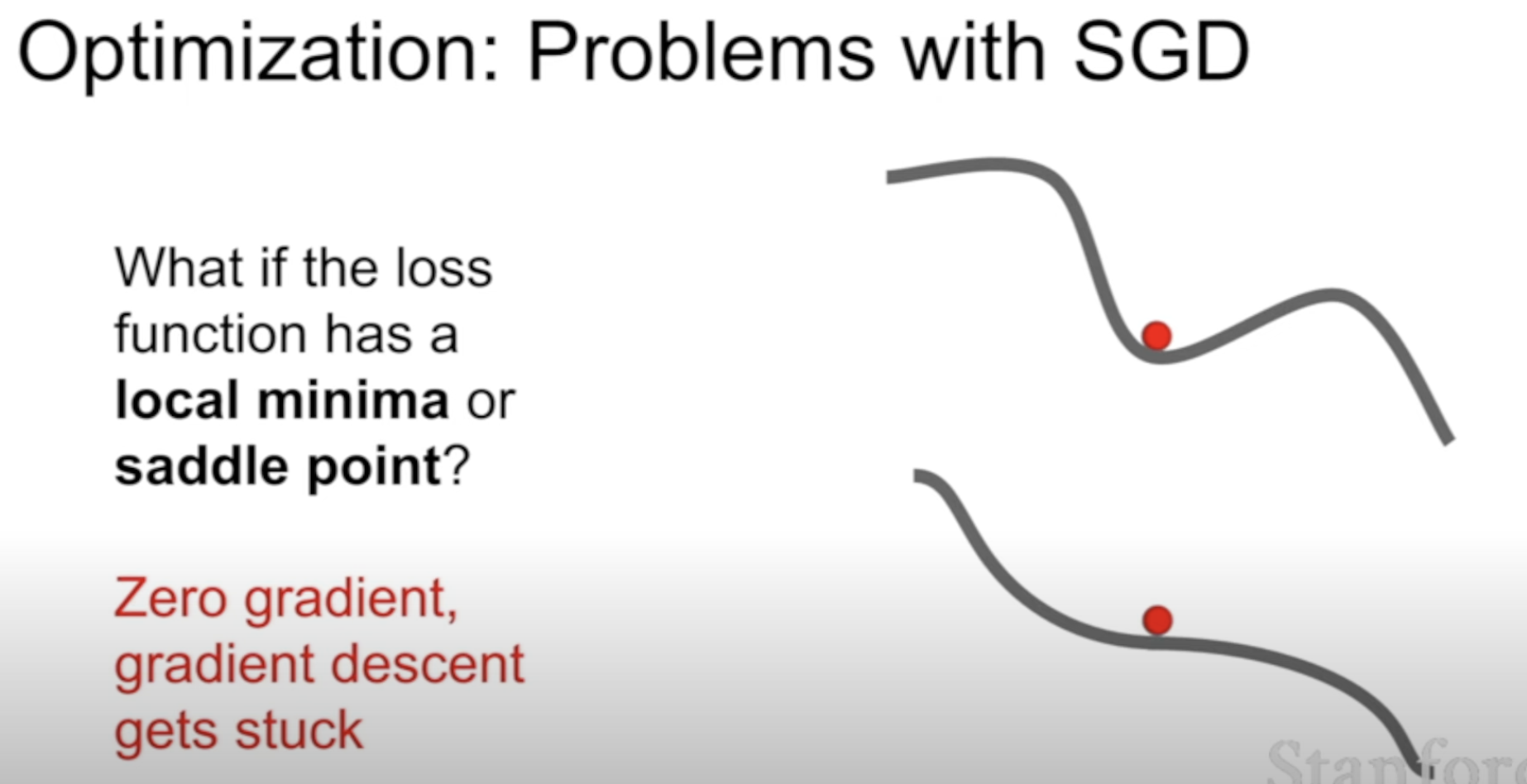
SGD gets stuck at these points because the gradients are zero
And the saddle points are common in high-dimensional settings
(2) SGD + Momentum

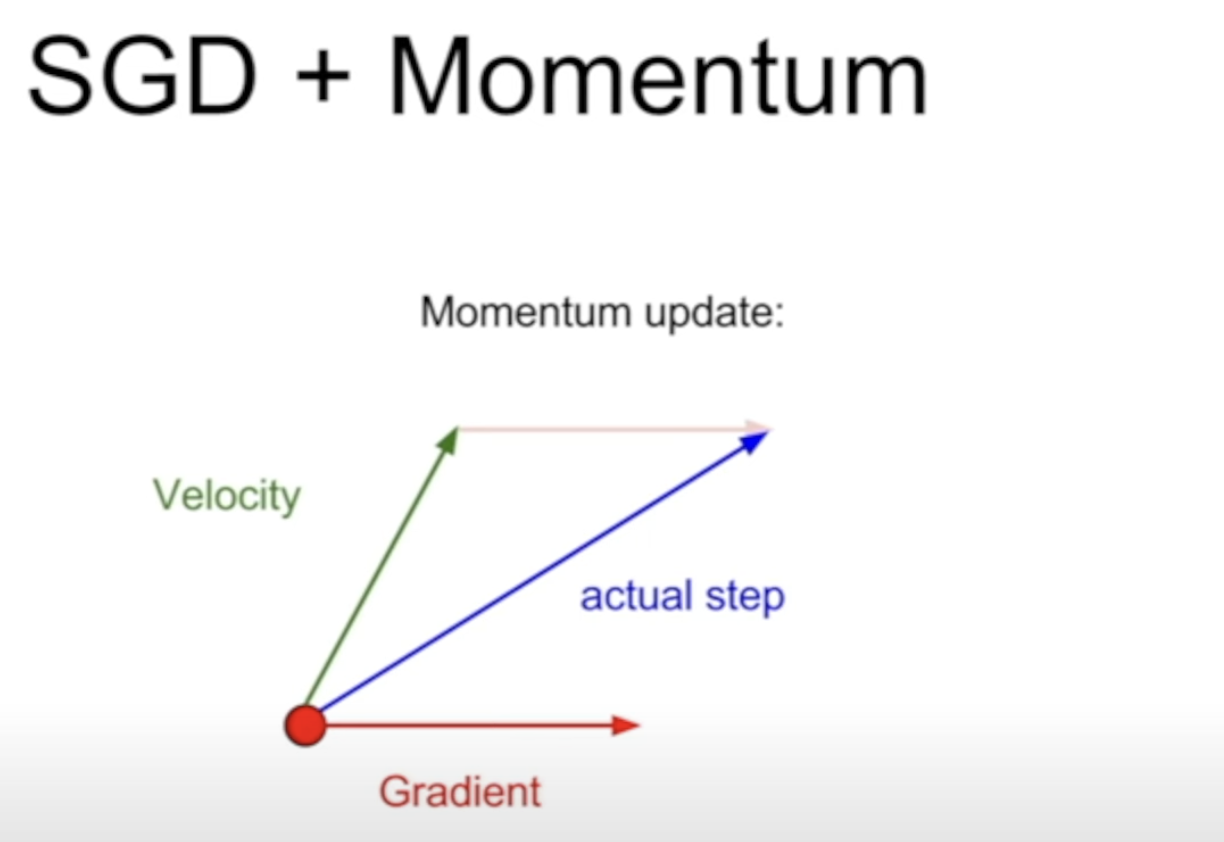
adding a momentum term helps in problems like saddle points by not always taking a step in the direction of the gradient.
Keypoint is to step in the direction of the "velocity" rather than the gradient
(3) AdaGrad

What changed?
Not the velocity anymore, rather adaptive step size
Momentum focused more on "Where to go"
AdaGrad focused on "How much to go?"
