[머신러닝 10주차-1] 비지도학습- Clustering: Hierarchical Clustering(계층적 클러스터링), K-means
🎯 Clustering(군집분석)이란?
개체들을 분류하기 위한 기준이 없는 상태에서, 주어진 데이터의 속성값을 비교해 유사한 개체끼리 그룹화(클러스터화)하는 것입니다.
그룹 내의 차이를 줄이고, 그룹 간의 차이는 최대화하여 대표성을 찾는 원리라고 볼 수 있죠.
주어진 정답이 없는 상태에서 분류학습을 진행하므로, 비지도학습이라고 합니다.
[* No labels are given. Thus, learn the structure of the unlabeled data in the collections. ]
Clustering의 유형
Non-Hierarchical Clustering(비계층적 클러스터링)
- 중심 기반(centroid-based) : K-means
- 밀도 기반(density-based) : DBSCAN
Hierarchical Clustering(계층적 클러스터링)
K-means

기본적으로 centroid-based 클러스터링 기법입니다.
각 군집(cluster)의 중심(center)인 centroid를 기준으로, 각각의 데이터가 해당 군집의 centroid로부터 얼마나 떨어져있는지 측정합니다.
K-means에서 K의 의미는, 군집의 개수를 의미 합니다.
K-means 의 알고리즘 단계
Step 1. [초기화] Initialize cluster centroid , , ... , ∈ randomly

Step 2. Repeat [1], [2] until convergence
[1] assign each to nearest (가장 가까운 cetnroid의 군집에 각 데이터 할당)

For every ,
[2] Update the Centroid based on s. (각 데이터들이 할당된 군집에 기반하여, cetroid 업로드)
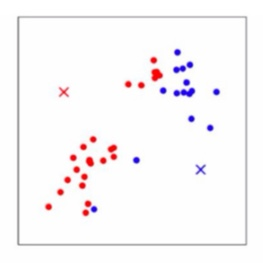
For every ,
K-means의 특징
1) 초기 Centroid는 random하게 결정되므로, 마지막 분류된 최종 군집들(클러스터들)은 초기 Centroid값을 어떻게 설정하느냐에 따라 달라질 수 있다.
2) 군집(클러스터)의 갯수인 K를 어떻게 결정할 것인가?
AVW(Average Lowest With-in cluster variation): 군집 내에서의 가장 낮은 variation을 지닌 평균값인 K를 찾는다.
=
Hierarchical Clustering(계층적 클러스터링)
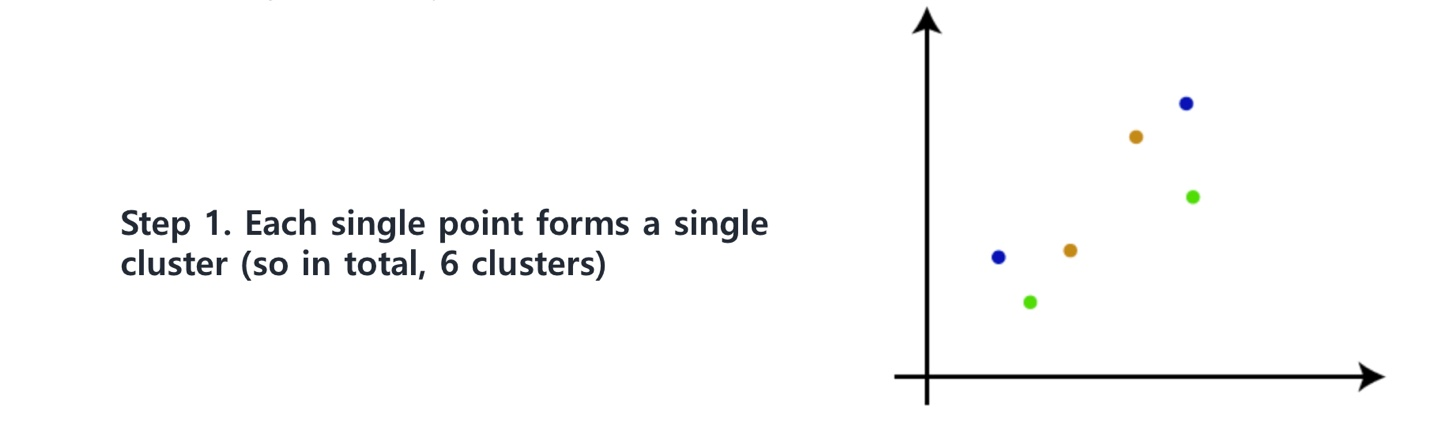
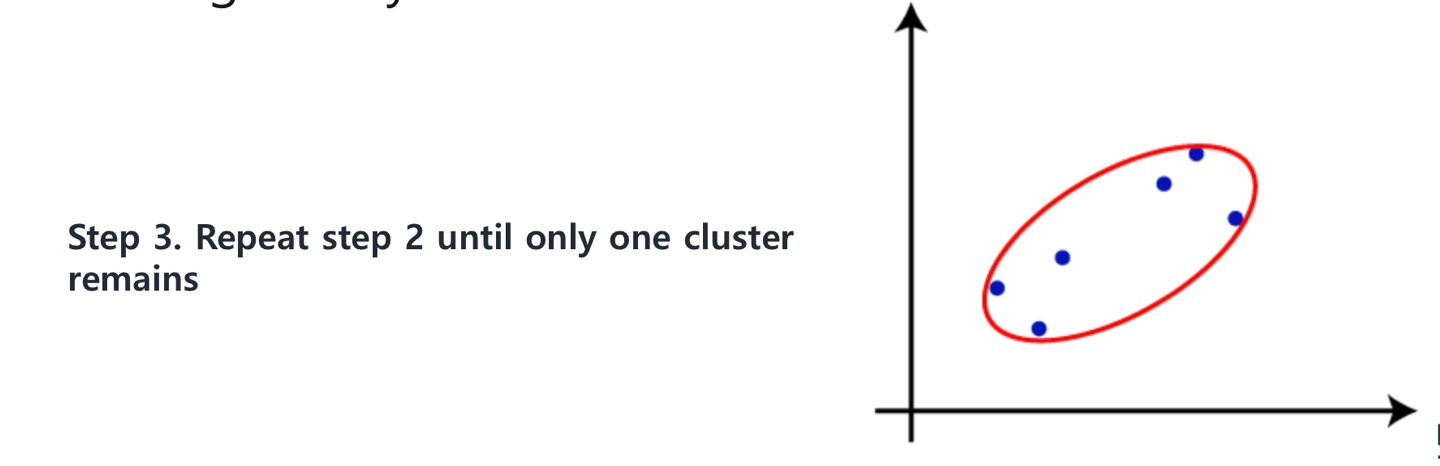
Step 1. 각 데이터 포인트들을 하나의 군집 으로 취급한다.
Step 2. 가장 가까운(the most similarity) pair wise한 클러스터들을 병합하며
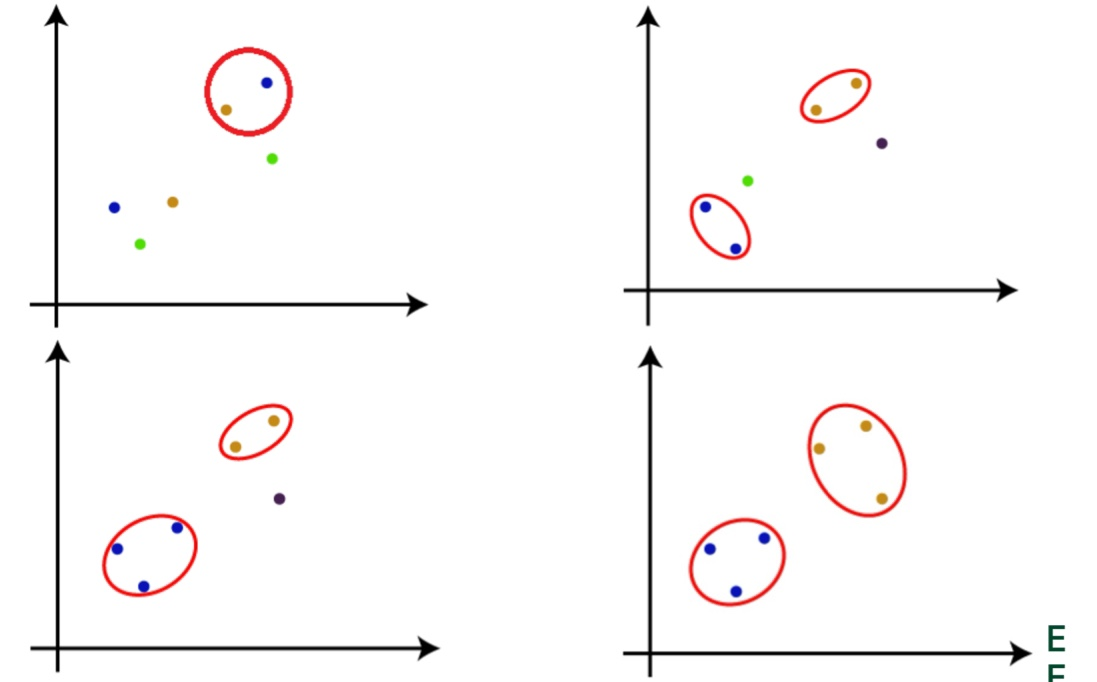
Step 3. 하나의 커다란 군집(one-giant) 을 얻기까지 반복한다.
Similarity 기준
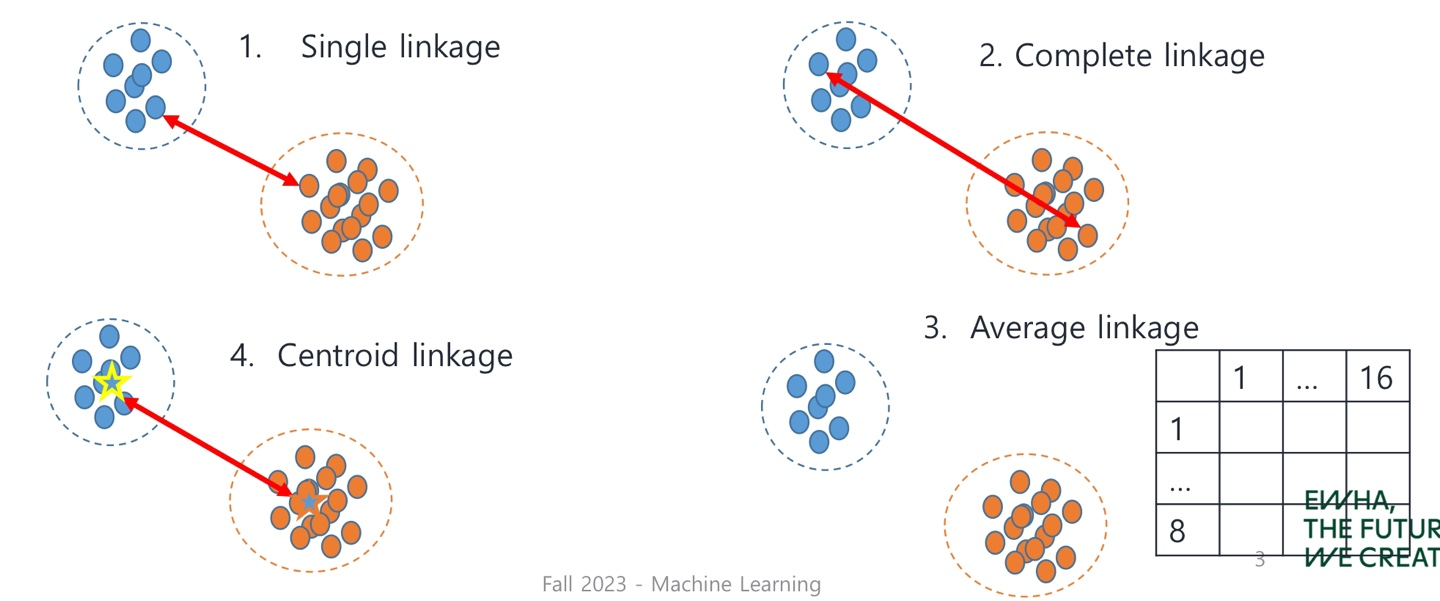
1) Single Linkage
- 군집들 사이의 가장 짧은 거리 계산 하여 측정
2) Complete Linkage
- 군집들 사이의 가장 긴 거리 계산 하여 측정
3) Average Linkage
- 군집들 사이의 pair-wise한 거리들을 계산하여, 평균을 취해주어 측정
4) Centroid Linkage
- Centroid 사이의 거리를 계산하여 측정
군집을 어떻게 고를 것인가: Dendogram