📌 TP, TN, FP, FN의 개념
계속 헷갈리는 개념이라 정리하여 써놓겠습니다.
- True Positive
- True Negative
- False Positive
- False Negative
4가지의 개념은 실제값과 예측값에 따라 계산합니다. 뒤에서부터 해석하면 용이하다는 점을 들어, 뒤에서부터 해석하는 습관을 기르도록 합시다.
Positive/Negative는 예측값이 기준 레이블과 맞았는지 (예측값==기준값?) 여부에 따라 결정되고,
True/False는 해당 예측의 정답(예측값==실제값?) 여부에 따라 결정된다고 한다.
예시를 들어 설명해보겠습니다.
이진 분류(Binary Classification)문제를 생각해보면,
0과 1, 즉 2개의 레이블에 대하여 분류하는 문제를 풀었고,
레이블 0에 대하여 분류해보면,
우선 기준값은 레이블 0이 되겠죠.
[1] True Positive는 예측값이 0이고(레이블 0과 같으므로 Positive), 실제값도 0이라 예측이 맞습니다.
[2] True Negative는 예측값이 1이고(레이블 0과 다르므로 Negative), 실제값은 1이라 예측이 맞습니다.
[3] False Positive는 예측값이 0이고(레이블 0과 같으므로 Positive), 실제값은 1이라 예측이 틀립니다.
[4] False Negative는 예측값이 1이고(레이블 0과 다르므로 Negative), 실제값은 0이라 예측이 틀립니다.
🎯 Model Performance 측정하기
Accuracy(정확도)
Accuracy란, "모든 예측값들" 중 "예측이 맞은(옳은 예측을 한)" 비율을 말합니다.
그렇다면 이 Accuracy를 구하는 식이 되겠죠.
=
데이터셋이 imbalanced할 때는 좋지 않겠죠.
Precision
Precision이란, "예측값이 기준 레이블값(0)과 동일한 것 중(positive)", "실제로도 예측이 맞는(예측값=실제값)" 비율을 말합니다.
=
Recall(TP rates)
Recall이란, "실제값이 기준 레이블값(0)인 것들 중(TP or FN)", "맞게 예측한 것(TP)"의 비율
=
QUIZ
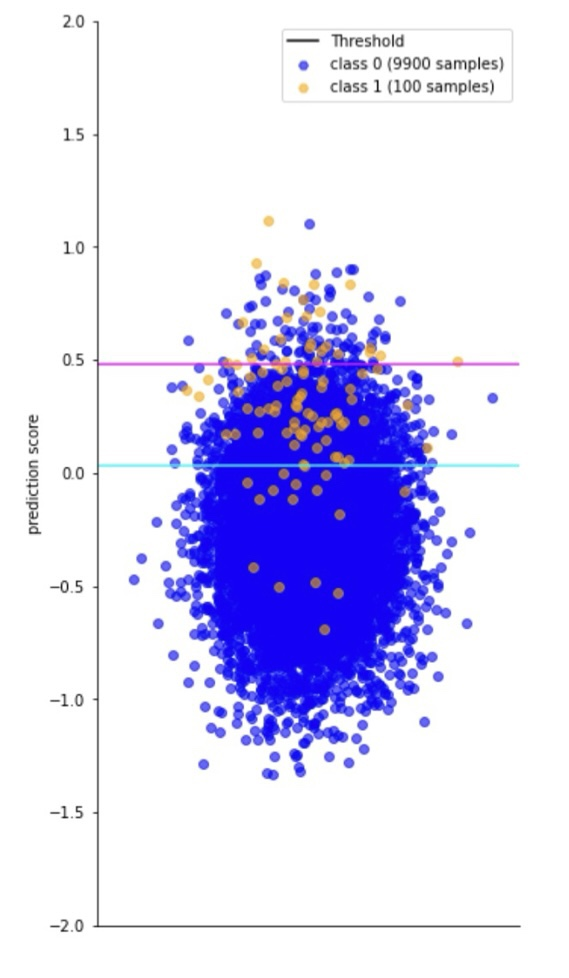 threshold(bar)을 기준으로 예측값이 Positive인지 Negative인지 나뉩니다.
threshold(bar)을 기준으로 예측값이 Positive인지 Negative인지 나뉩니다.
Q1. What portion indicates Recall and Precision?
- Recall = TP / (TP+FN) = bar위에 있는 파란색 samples/파란색 samples
- Precision = TP / (TP+FP) = bar위에 있는 파란색 samples/bar위에 있는 모든 samples
Q2. What if bar goes up? (blue -> pink)
Threshold가 오르면, Positive로 예측되는 sample의 양 자체가 줄어듭니다.
Precision은 증가하는 반면, Recall은 줄어듭니다.
Q3. What metric works better against imbalanced dataset?
imbalance한 데이터셋에 대해서는 precision이 더 잘 맞습니다.
Q4. If the bar is located at very bottom, what does the precision indicate?
- Precision = TP / (TP+FN)
threshold가 가장 아래에 있으면, 데이터셋의 전체 예측값이 모두 positive가 됩니다. 따라서 전체 데이터셋의 비율 중 positive sample의 비율이 됩니다.