부하 테스트
지난번에 진행했던 부하테스트는 처음이었기도 하고, 객관적인 분석을 하기가 여러모로 힘든 결과 데이터 같아서 다시 진행해보려 한다.
다음과 같은 설정으로 컨테이너에 1메모리를 할당하였고, 1코어의 CPU를 할당하여서 리소스를 제한시켰다.
docker run -p 8081:8080 —network=net -m 1g —cpus="1" -e USE_PROFILE=test hyuksoon/happyscrolls
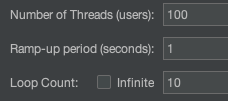
위 사진 처럼 Ramp-up period는 1, Loop Count는 10으로 고정한 후, Number of Threads를 늘려가며 테스트할 예정이다.
Number of Threads를 100,500,1000,1500,3000 순으로 테스트를 했으며, 인스턴스의 수도 1,2,3개 순으로 늘려서 서버의 개수와 성능 간의 상관관계를 알아보았다.
사용된 API
이번 실험에서는 db에 접근 없이 순수 서버의 성능을 알아보기 위해 요청시 다른 곳을 거치지 않고 바로 값을 반환하는 간단한 api가 사용되었다. 따라서 db나 다른 미들웨어같은 외부 요인에 영향받지 않도록 하였다.
테스트 결과
- 인스턴스 1개
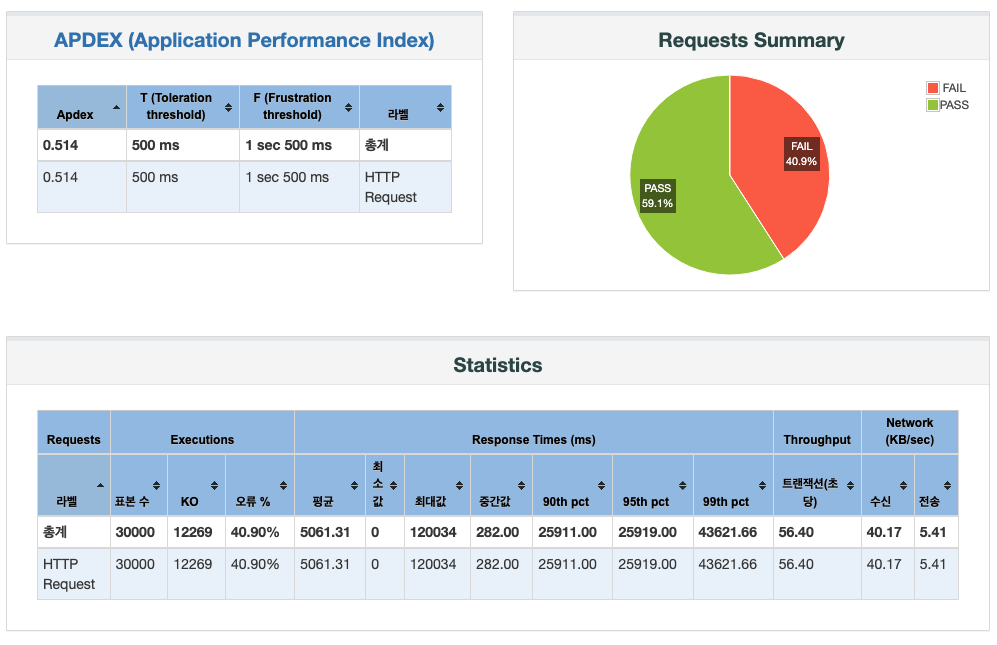
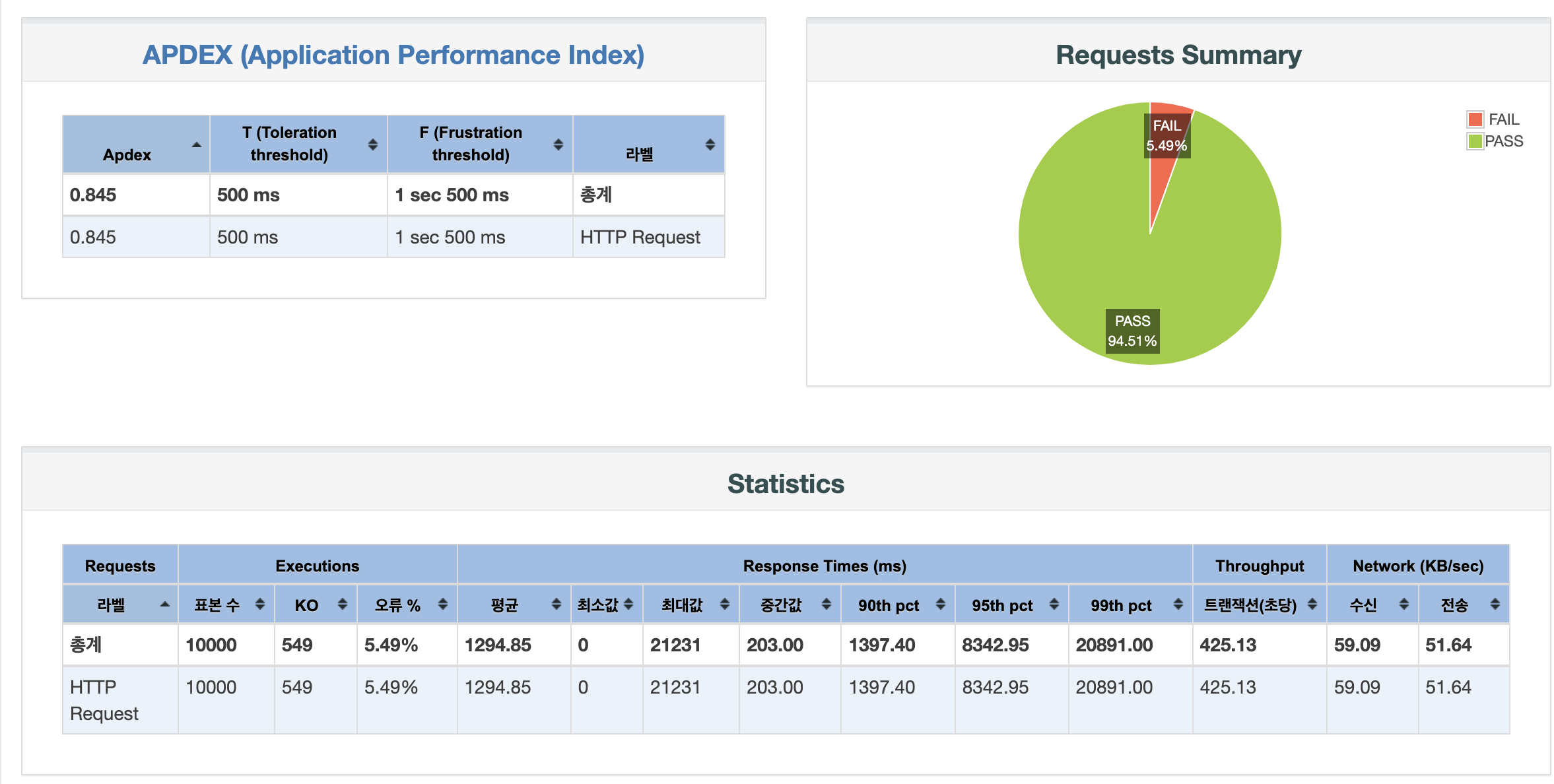
쓰레드 수를 3000으로 했을 때의 결과가 충격적이라 가져와보았다. 서버의 성능을 고려하지 않고 배포하면 사용자가 조금이라도 몰릴 때 어떠한 결과를 초래할지 배울 수 있었다.
아래 결과들은 Jmeter 결과 보고서를 그래프로 정리한 결과이다.
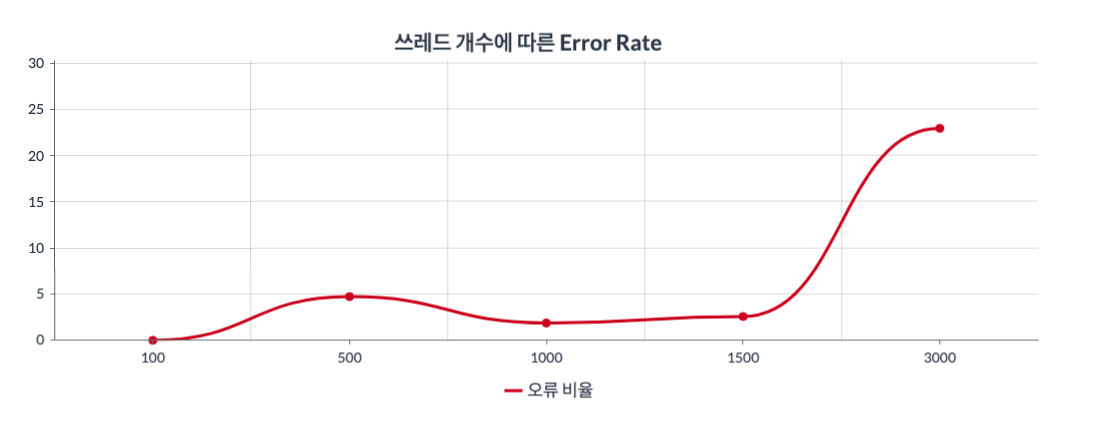
그래프1 : x축은 쓰레드의 수(100~3000)를 뜻하고 y축은 Error Rate를 뜻한다.
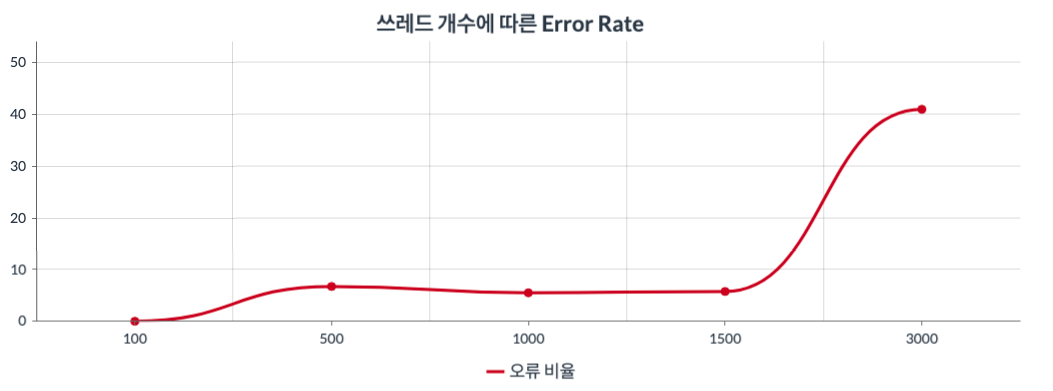
100개의 쓰레드에서는 0%의 오류율을 보이고, 500,1000,1500 구간에서는 약 5%의 준수한 오류율을 보인다. 하지만 3000개의 쓰레드 테스트에서는 40%가 넘어가는 사용 불가 수준의 오류율을 보인다. 따라서 3000개의 쓰레드가 넘어가는것을 고려한다면 서버의 수를 늘려야 함을 알 수 있다.
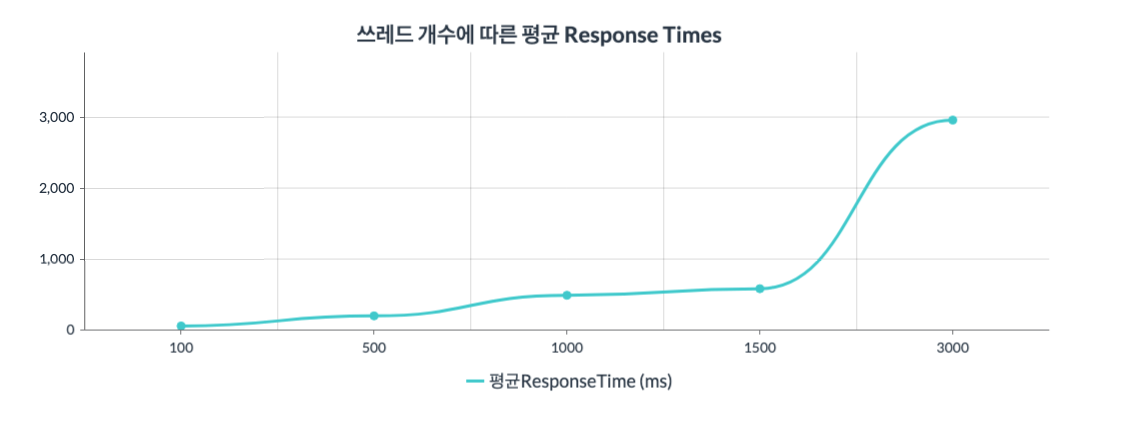
그래프2 : x축은 쓰레드의 수(100~3000)를 뜻하고 y축은 Response Time을 뜻한다.
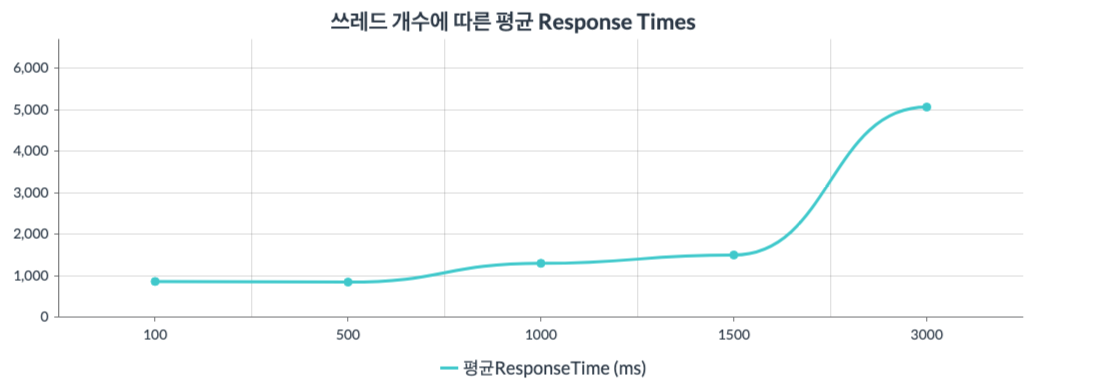
앞서 Error Rate에서는 500,1000,1500 쓰레드가 비슷한 양상을 띄어서 1500개의 쓰레드까지는 성능에 무리가 없는것으로 보였다. 하지만 Response Time을 살펴보니 달랐다.
500개 쓰레드 테스트에서는 857ms가 나온 반면, 1500개 쓰레드 테스트에서는 1495ms가 나왔다. 2배에 육박하는 Response Time 차이가 남을 알 수 있고, 3000개 쓰레드 테스트의 Response Time이 워낙 큰 숫자를 나타내고 있어서 잘 안보일 뿐, 스케일 아웃을 고려할 만한 성능 저하라고 생각된다.
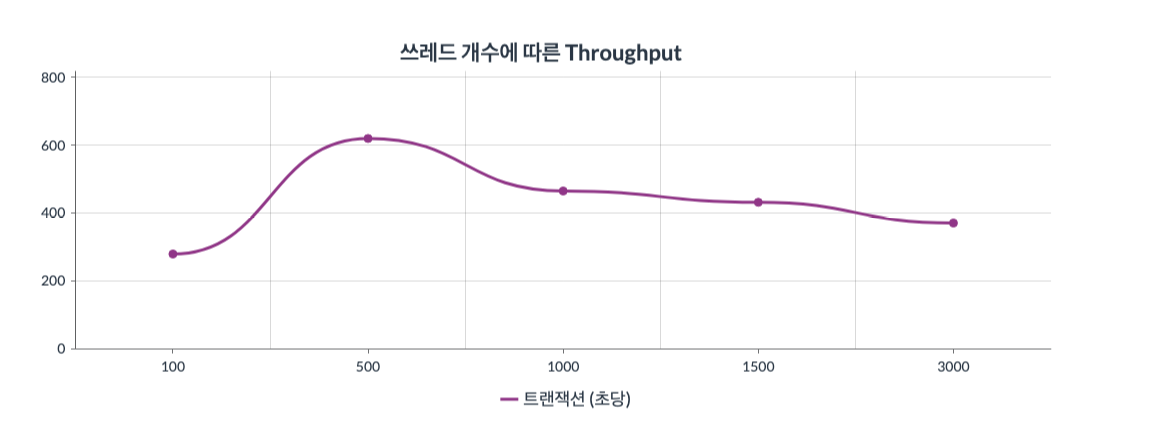
그래프3 : x축은 쓰레드의 수(100~3000)를 뜻하고 y축은 Throughput를 뜻한다.
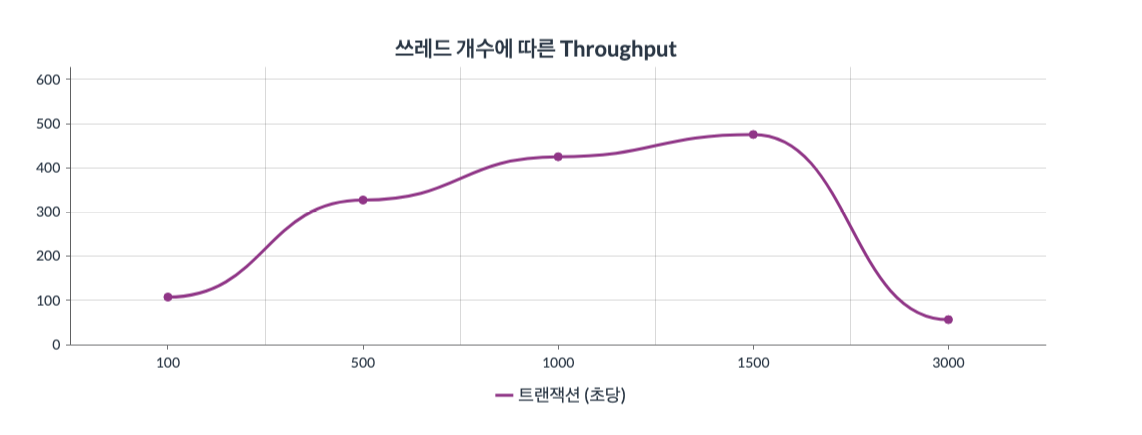
Throughput 쪽에서는 500개~1500개 쓰레드로 늘어나는 동안 성능 저하의 지표는 나타나지 않은것으로 보인다. 초당 320의 트랜잭션 처리에서 480 트랜잭션 처리까지 늘어났고, 3000개 쓰레드 테스트에서는 100미만의 처리량을 보인다. 1500개 쓰레드 테스트까지는 Troughput 부문에서는 무리 없는 성능을 가용할 수 있는것으로 판단된다.
실험을 진행하는 동안 CPU 사용량을 그라파나로 관측한 결과이다.
처음에 CPU를 1코어 제한해서 컨테이너를 생성했기 때문에 CPU Usage가 1을 초과하지 않는 모습이다. 다만 2번째 실험인 500개의 쓰레드를 테스트하는 과정에서부터 이미 CPU 최대치를 사용함을 알 수 있다.

- 인스턴스 2개
그래프1 : x축은 쓰레드의 수(100~3000)를 뜻하고 y축은 Error Rate를 뜻한다.
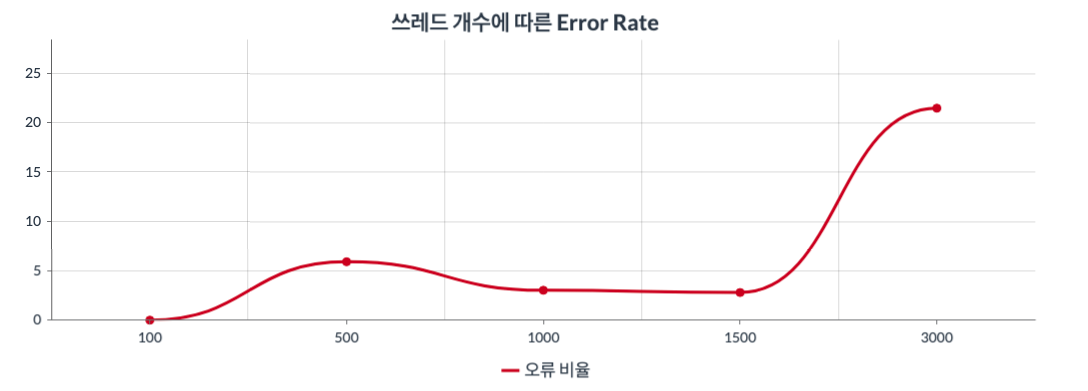
그래프2 : x축은 쓰레드의 수(100~3000)를 뜻하고 y축은 Response Time을 뜻한다.
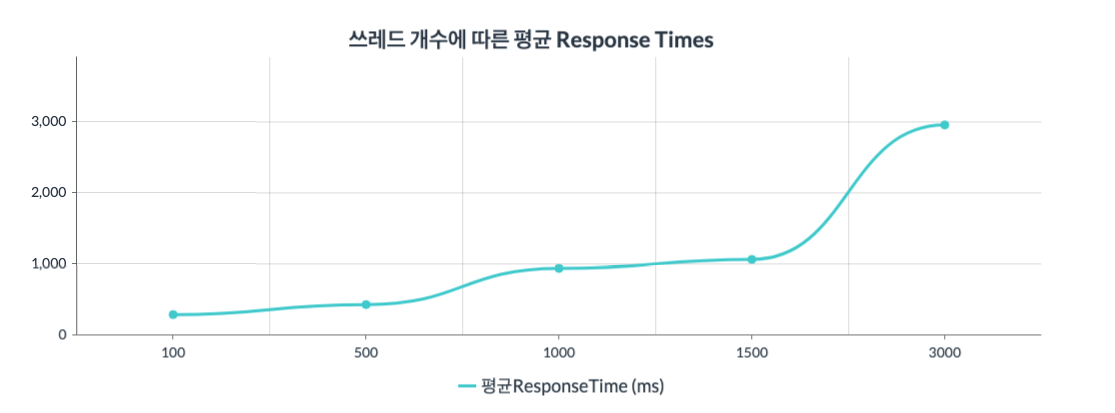
그래프3 : x축은 쓰레드의 수(100~3000)를 뜻하고 y축은 Throughput를 뜻한다.
실험을 진행하는 동안 CPU 사용량을 그라파나로 관측한 결과이다.

- 인스턴스 3개
그래프1 : x축은 쓰레드의 수(100~3000)를 뜻하고 y축은 Error Rate를 뜻한다.
그래프2 : x축은 쓰레드의 수(100~3000)를 뜻하고 y축은 Response Time을 뜻한다.
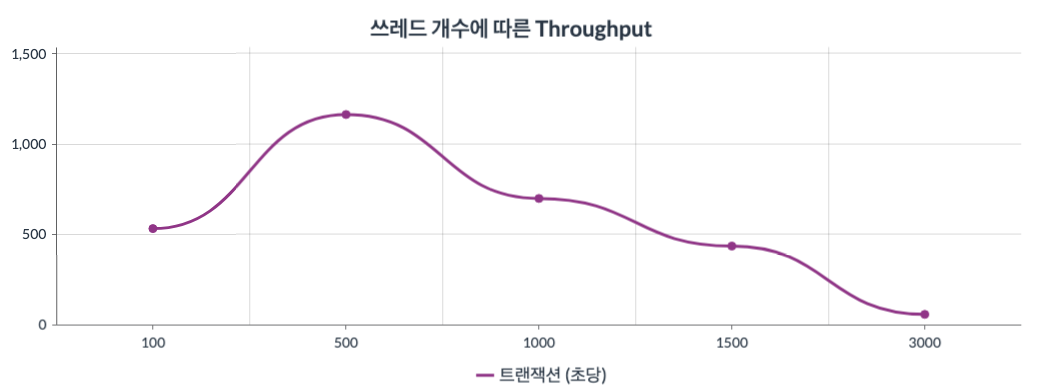
그래프3 : x축은 쓰레드의 수(100~3000)를 뜻하고 y축은 Throughput를 뜻한다.
실험을 진행하는 동안 CPU 사용량을 그라파나로 관측한 결과이다.

- 인스턴스 5개
그래프1 : x축은 쓰레드의 수(100~3000)를 뜻하고 y축은 Error Rate를 뜻한다.
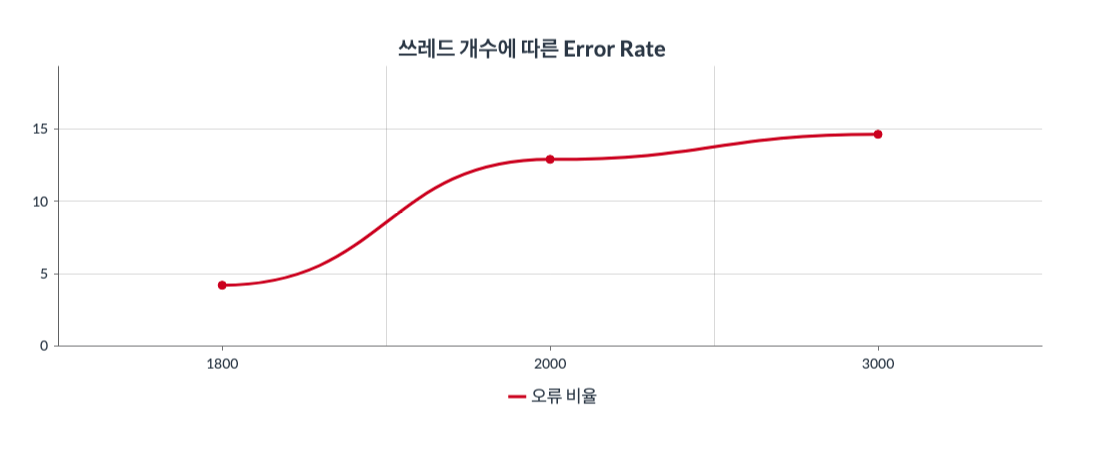
그래프2 : x축은 쓰레드의 수(100~3000)를 뜻하고 y축은 Response Time을 뜻한다.
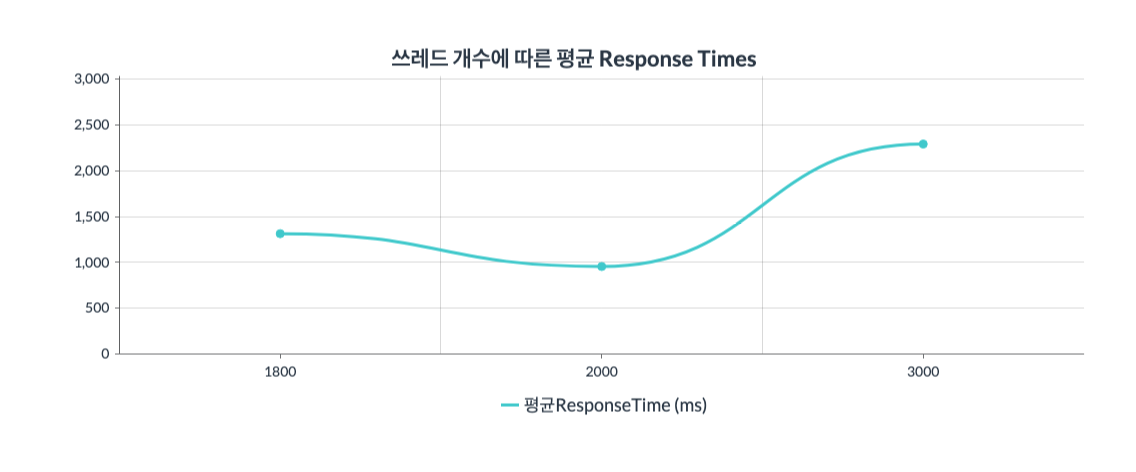
그래프3 : x축은 쓰레드의 수(100~3000)를 뜻하고 y축은 Throughput를 뜻한다.
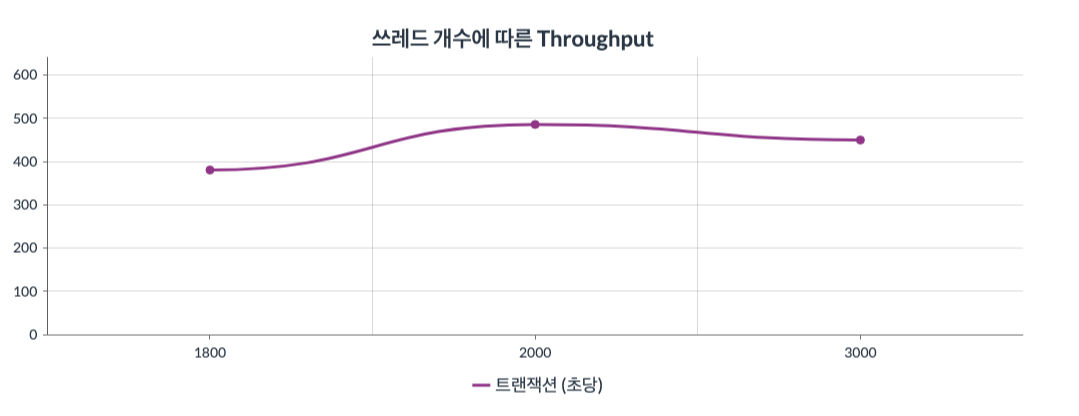
실험을 진행하는 동안 CPU 사용량을 그라파나로 관측한 결과이다.

종합 결과
그래프1 : x축은 쓰레드의 수(100~3000)를 뜻하고 y축은 Error Rate를 뜻한다.
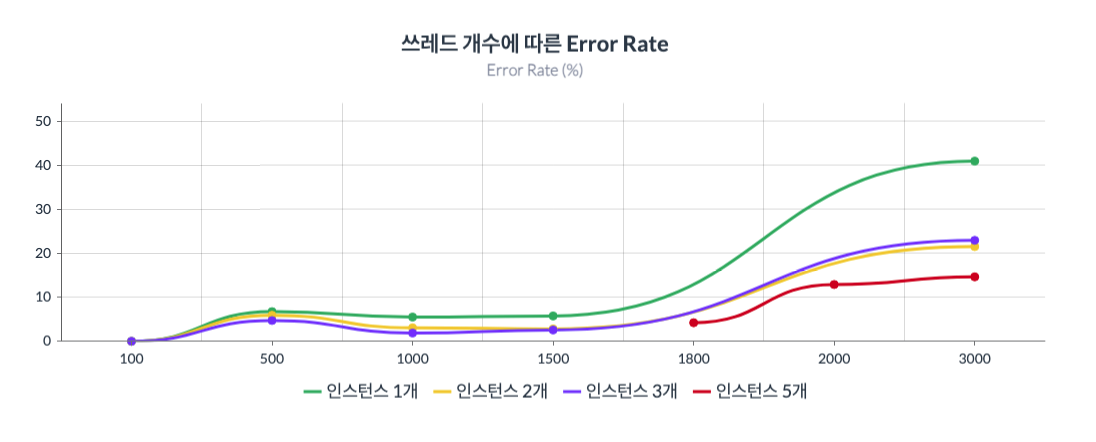
인스턴스 5개인 경우가 압도적으로 error rate가 낮음을 알 수 있다.
그래프2 : x축은 쓰레드의 수(100~3000)를 뜻하고 y축은 Response Time을 뜻한다.
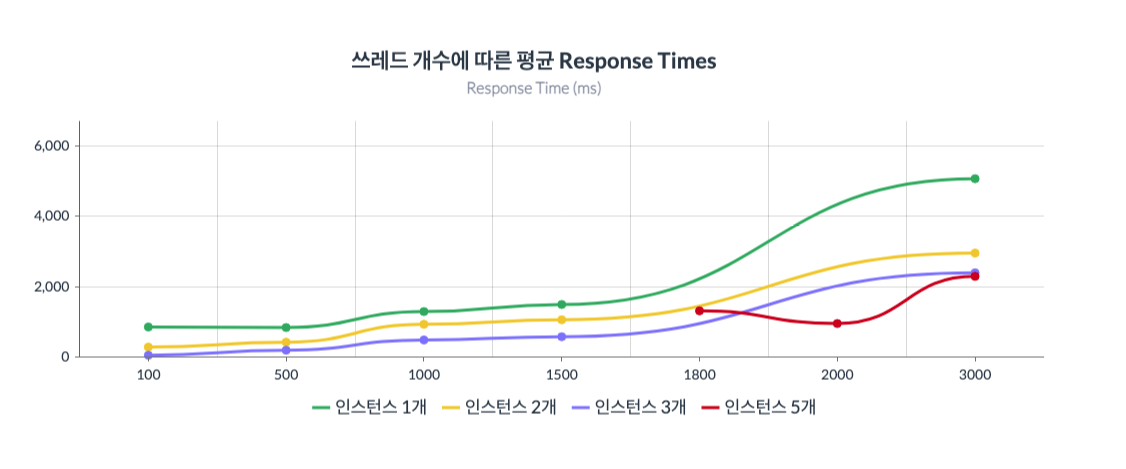
Response Time의 경우 인스턴스 5개가 3개인 경우와 비교해서 비슷하지만 근소하게 앞섰고, 1,2개일 경우와 비교에 있어선 우위를 보였다.
그래프3 : x축은 쓰레드의 수(100~3000)를 뜻하고 y축은 Throughput를 뜻한다.
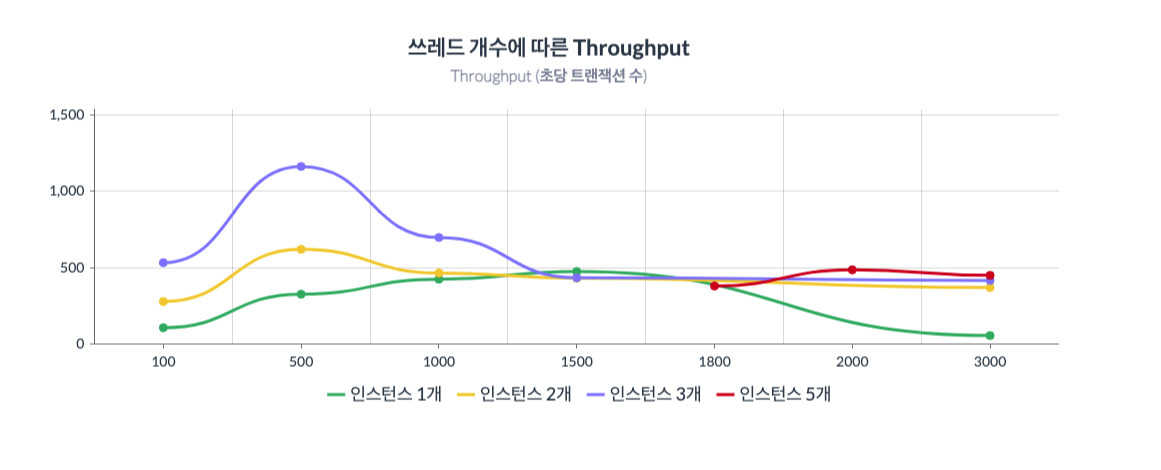
Throughput의 경우 인스턴스 5개가 나머지 경우와 비교해서 비슷하지만 근소하게 앞섰다.
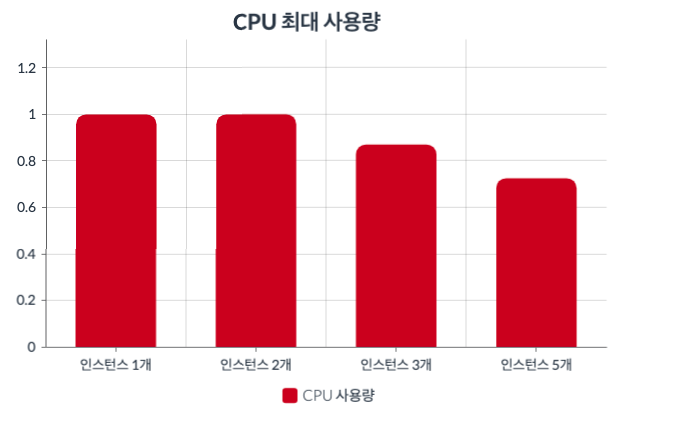
cpu 사용량은 5개인 경우가 압도적으로 낮았다.
결론
실험이 정확하지 않았을 수 있으므로 이 결과가 정답이라고 할 수는 없을 것 같다.
서버 인스턴스 개수가 늘어난다고 성능이 개수와 정비례로 좋아지진 않는것 같다. 하지만 cpu 사용량을 고려했을 때, 적절한 CPU 사용량을 유지할 수 있도록 서버 인스턴스 개수를 조절해주는 것이 좋아보인다.
