복제 DB를 이용한 성능 개선을 공부하고자 합니다.
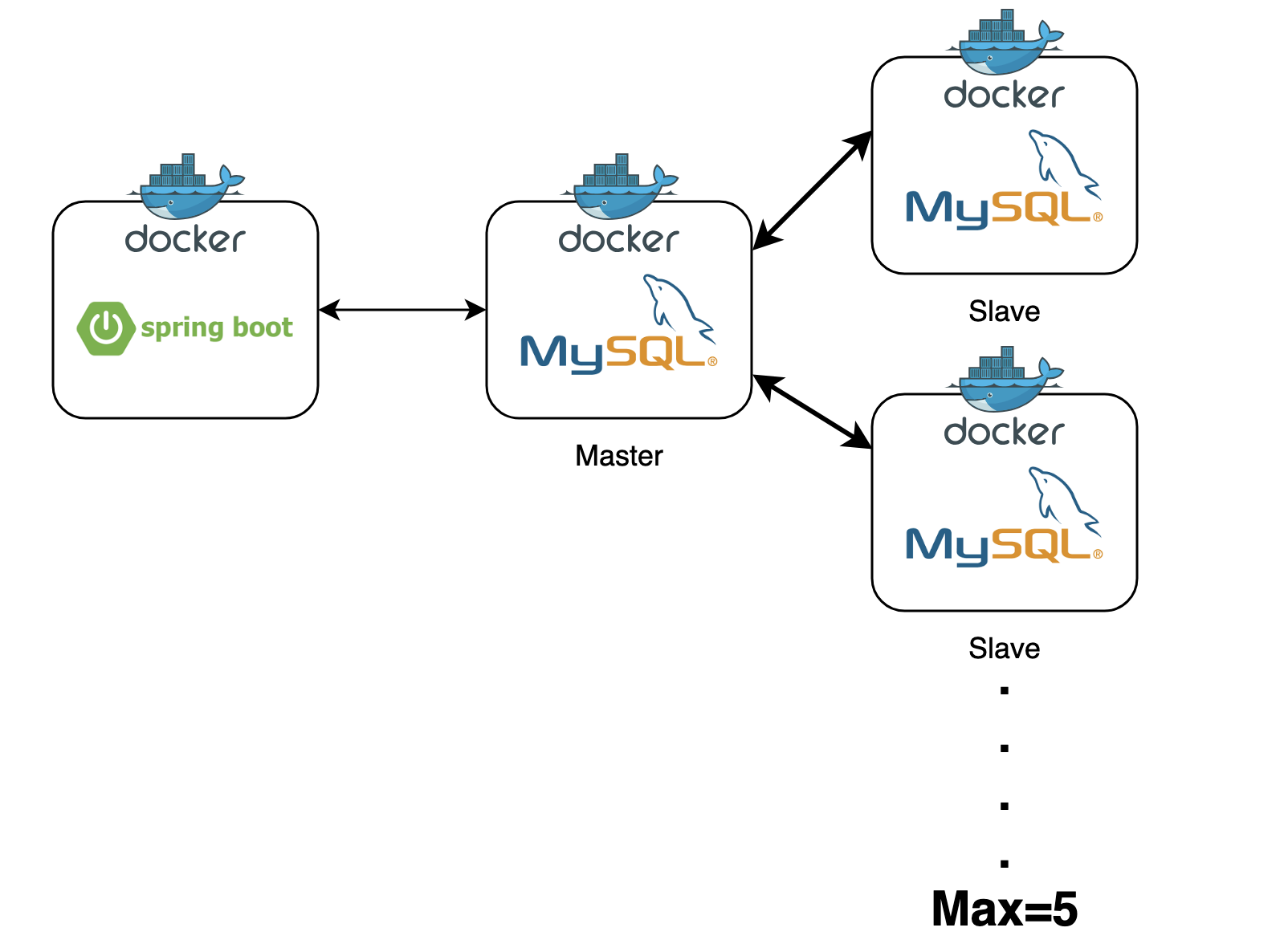
위와 같이 환경을 구축하였습니다.
Master DB는 쓰기 전용, Slave DB는 읽기 전용입니다.
이번 테스트는 읽기 전용 API를 통해 실행하기 때문에 Slave DB 인스턴스들을 이용해 테스트를 진행합니다.
DB 성능만을 체크할 예정이기 때문에 서버어플리케이션의 성능이 영향을 최대한 덜 미치도록 로컬에 리소스 제한을 두지 않고 실행했습니다.
(서버 인스턴스의 리소스 부족으로 오류가 생기면 DB 성능 테스트가 정확해지지 않기 때문입니다.)
실험 환경
실험동안 바뀌는 DB 인스턴스 리소스는 다음과 같습니다.
- 1 CPU, 1GB Memory 1개 인스턴스
- 1 CPU, 1GB Memory 2개 인스턴스
- 1 CPU, 1GB Memory 4개 인스턴스
- 2 CPU, 2GB Memory 1개 인스턴스
- 4 CPU, 4GB Memory 1개 인스턴스
실험 방식
조회 쿼리를 날리는 동일한 API를 여러 쓰레드를 통해 동시에 호출합니다.
JMeter를 통해 진행하였습니다.
쓰레드 개수는 500,1000,1500,2000,2500,3000,3500,4000개 입니다.
모든 실험은 5회 진행 후, 평균을 내었습니다.
Throughput 결과
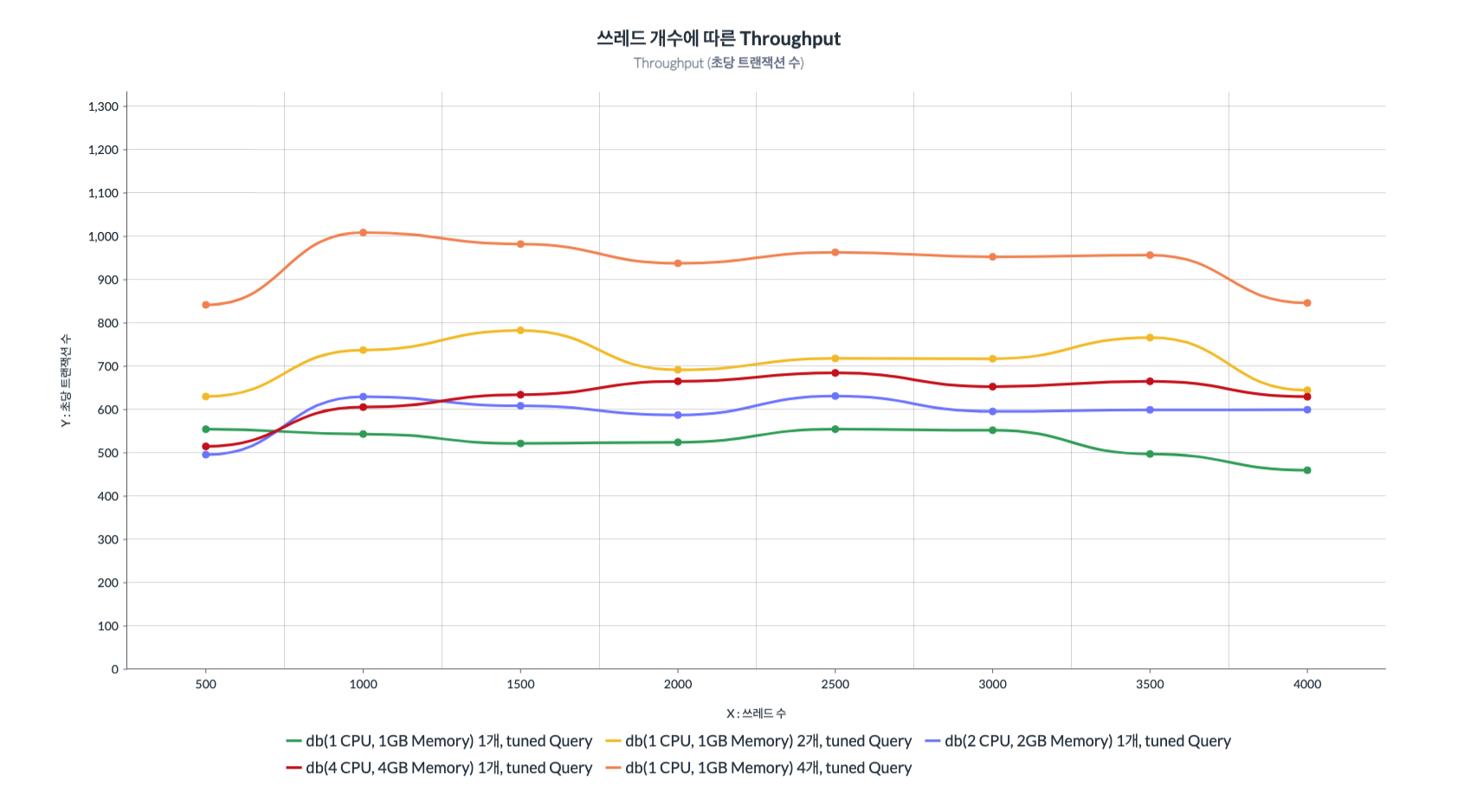
1 CPU, 1GB Memory 4개 인스턴스인 케이스가 압도적으로 좋은 성능을 보였습니다.
또한 1 CPU, 1GB Memory 2개 인스턴스인 케이스가 2 CPU, 2GB Memory 1개 인스턴스와 4 CPU, 4GB Memory 1개 인스턴스와 비교해서 거의 동등하거나, 우위에 있는 결과를 보였습니다.
Response Time 결과
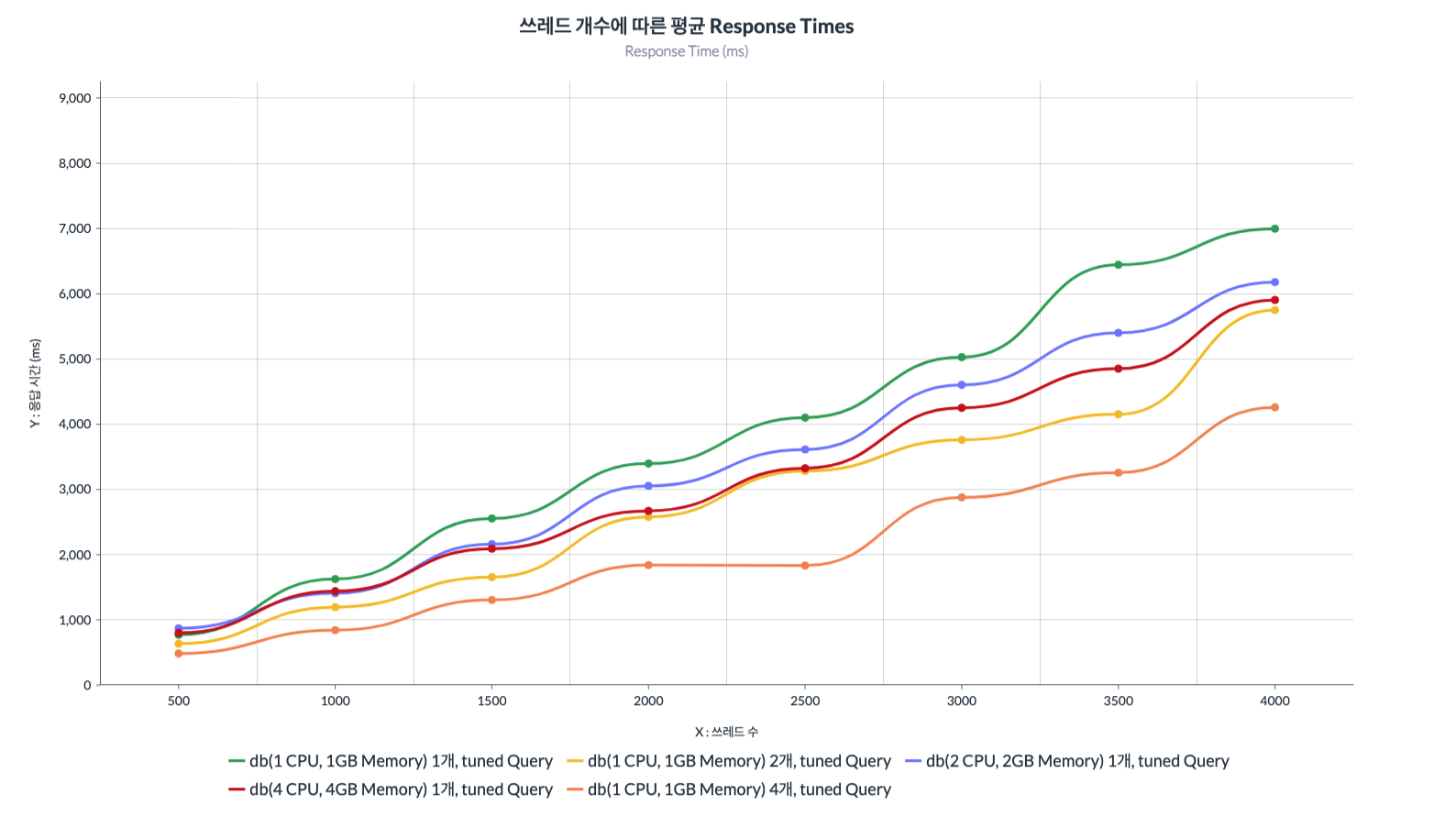
Response Time 역시 1 CPU, 1GB Memory 4개 인스턴스인 케이스가 압도적으로 좋은 성능을 보였습니다.
또한 역시 1 CPU, 1GB Memory 2개 인스턴스인 케이스가 2 CPU, 2GB Memory 1개 인스턴스와 4 CPU, 4GB Memory 1개 인스턴스와 비교해서 거의 동등하거나, 우위에 있는 결과를 보였습니다.
이 결과가 정확하진 않을 수 있지만 (여러가지 환경들로 인해) 조회 DB는 복제 DB를 이용하여 분산시키는 것이 성능에 큰 영향을 미칠 수 있다는 것을 알게 되었습니다.
주의점
복제 DB는 타 DB와 동기화 되는데에 시간이 필요합니다. 따라서 읽기와 쓰기 역할을 나누어 DB를 구축한 경우 DB에 쓰자마자 읽기 DB에서 읽어오려고 하면 아직 읽기용 DB에 동기화가 되지 않은 경우가 있습니다. 따라서 데이터를 저장한 후, 바로 읽으려면 쓰기용 DB를 통해 조회해야 합니다.
여담
실험에 사용된 API는 페이징 쿼리를 날리고 있습니다. 이는 offset을 사용하지 않는 성능 튜닝이 된 쿼리입니다.
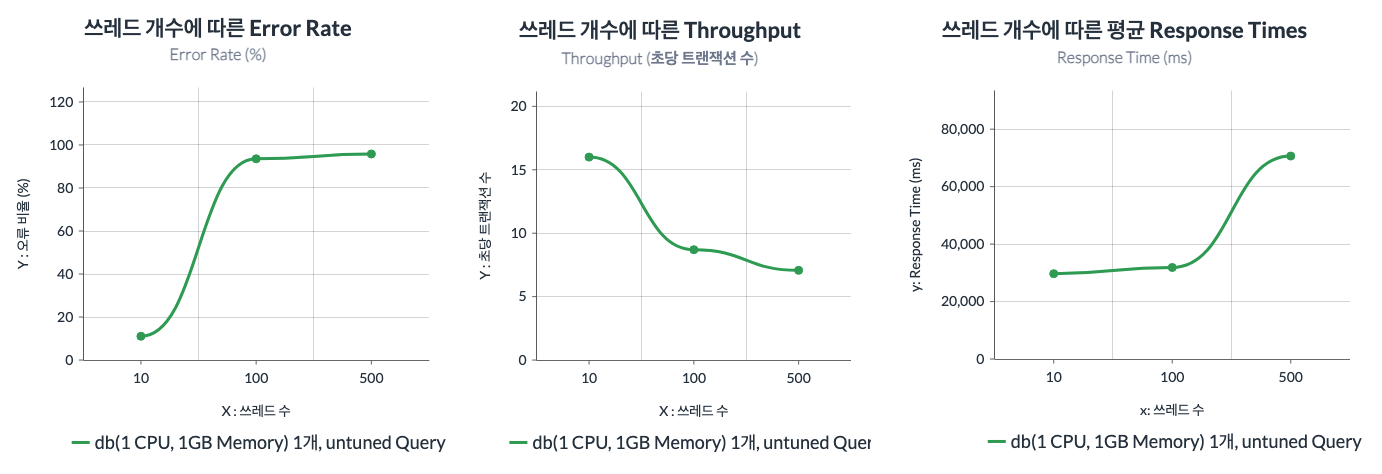
원래는 튜닝이 안되어있는 쿼리도 함께 테스트를 하려했습니다.
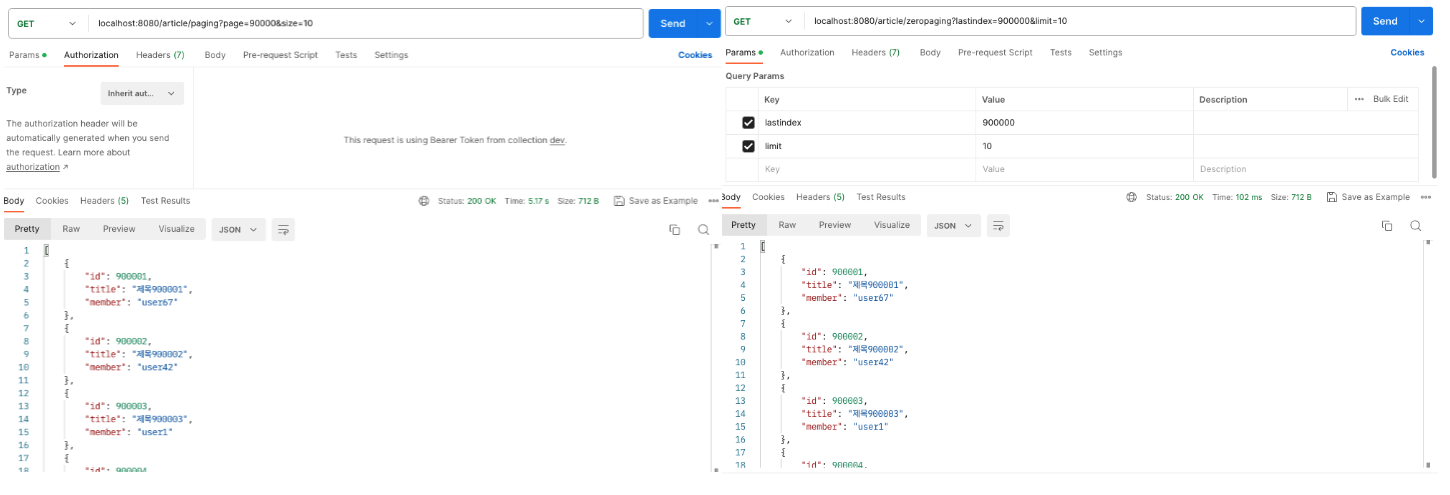
같은 기능을 하지만 하나는 쿼리 튜닝이 되어있고, 하나는 되어있지 않습니다. 둘은 약 50배의 속도 차이가 나는 것을 알 수 있다.
하지만 아래 결과와 같이 튜닝이 안되어있는 쿼리는 비교를 할 수도 없을 정도로 성능이 좋지 않습니다. 위의 실험과 같은 환경에서 쓰레드 수를 고작 500으로 설정하였는데, 초당 트랜젝션 수가 7까지로 떨어졌습니다.
위의 실험에서 아무리 성능이 떨어지는 케이스에도 트랜잭션 수가 500 정도였던 것을 고려하면 서버 성능을 고려하는 것보단 역시 쿼리 튜닝을 우선적으로 고민해야한다고 생각됩니다.