def 네이버블로그순위(text):
리스트 = [] # 제목들을 저장할 배열 선언
for i in range(0, 10) : # 상위 10개니까 10개만 반복
# start={i} : i번쨰 목록을 보여주는 코드이기 때문에 반복문 실행시 차례로 증가하게 작성
# query={text} : 검색 단어를 보여주는 코드, 함수의 매개변수로 자유롭게 입력가능.
# data 변수로 get 요청을함
# soup 변수는 가져 온 데이터들을 \ 부분을 공백으로 재가공함
# 글리스트 변수는 가져 온 전체 데이터 중에, a태그 중에, 클래스가 api_txt_lines 인 값들을 모두 다 가져옴.
# 각제목들 변수는 싸그리 가져온 값 중에 [i]번쨰의 문자를 출력. (제목이 출력됨)
# 차례로 가져온 각제목들을 리스트 배열에 각각 추가. (1번째 제목추가, 2번째 제목 추가....)
data = requests.get(f'https://s.search.naver.com/p/review/search.naver?rev=44&where=view&api_type=11&start={i}&query={text}&nso=&nqx_theme=&main_q=&mode=normal&q_material=&ac=0&aq=0&spq=0&st_coll=&topic_r_cat=&nx_search_query=&nx_and_query=&nx_sub_query=&prank=61&sm=tab_jum&ssc=tab.view.view&ngn_country=KR&lgl_rcode=09350105&fgn_region=&fgn_city=&lgl_lat=37.6799006&lgl_long=127.0549781&abt=&_callback=viewMoreContents')
soup = BeautifulSoup(data.text.replace('\\', ''), 'html.parser')
글리스트 = soup.select('a.api_txt_lines')
각제목들 = 글리스트[i].text
리스트.append(각제목들)
#print(글리스트[0]['href'])
# 한글 깨짐 방지를 위한 encoding
# 기록할 파일 생성 및 열기
f = open('a.txt', 'w', encoding="UTF-8")
for i in range(len(리스트)): # 현재 리스트에 10개가 쌓여있고 그 크기만큼 반복해라
f.write(리스트[i] + '\n') # 순서대로 배열의 i번째 값을 파일에 작성해라 (열 줄 만들어짐)
f.close # 다 했으면 닫아라.
# 내가 검색하고 싶은 문자 아무거나 파라미터 자리에 입력
# 함수 실행하면 a.txt 파일에 열 줄이 뙇!
네이버블로그순위('abcd')- 결과 확인
- 네이버에 abcd 검색
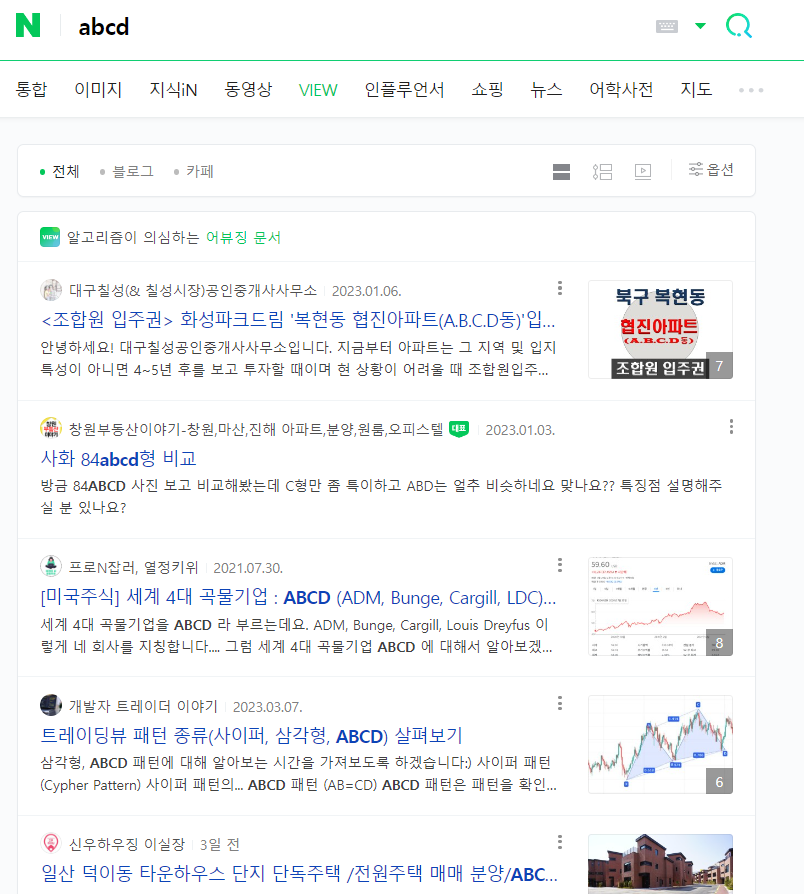
크롤링 성공!

안녕하세요.