1. 글자 가져 오기
-
파이썬 파일 폴더로 열기.
-
터미널에서 아래 코드 입력하여 라이브러리 설치해야함.
- pip install requests
- pip install bs4
import requests # 크롤러 기본 라이브러리
from bs4 import BeautifulSoup # 크롤러 기본 라이브러리
데이터 = requests.get('https://finance.naver.com/item/sise.naver?code=005930') # 데이터 가져 올 주소
# print(데이터.status_code) 200떠야댐.
soup = BeautifulSoup(데이터.content, 'html.parser') #주소에서 가져온 데이터를 html형식으로 수정
print(soup.find_all('strong', id="_nowVal")[0].text) # 출력 : 59,800
print(soup.find_all('span', class_="tah")[5].text) # 출력 : 10,287,203
#이렇게 가져 올 수도 있음.
print(soup.select('.f_up em')[1].text)
soup.select('.class명')
soup.select('#id명')
soup.select('태그명') (HTML 태그명은 아무것도 안붙임)
soup.select('.class명1 .class명2') (띄어쓰기는 '~내부의' 라는 뜻)
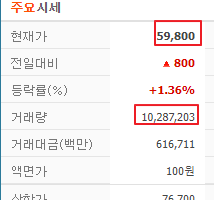
웹 주소에서 글자 가져오기 성공!
2. 이미지 가져오기
import requests
from bs4 import BeautifulSoup
import urllib.request #이미지 가져 올 라이브러리
데이터 = requests.get('https://finance.naver.com/item/sise.naver?code=005930')
soup = BeautifulSoup(데이터.content, 'html.parser')
이미지 = soup.select('#img_chart_area')[0]['src'] #이미지 주소 출력됨
urllib.request.urlretrieve(이미지, '테스트.jpg') # 현재 폴더에 '테스트.jpg' 이미지 저장됨
안녕하세요.