누군가 설명해달라고 했을 때 제대로 설명할 수 있어야 내 지식!
Transfer Learning
Transfer Learning 이란, pre-trained model을 이용하여 새로운 model을 만들 때 학습을 빠르게 하며, 예측 정확도를 높이는 방법이다.
Why use it?
- Convolution Network를 처음부터 학습시키는 일은 시간과 비용 측면에서 좋지 않다. 대부분 이미 학습된 모델을 사용하여 문제를 해결할 수 있다.
- 복잡한 모델일수록 학습 비용이 높아진다.
- 처음부터 학습시키려면 layer의 갯수, hyper parameter등 고려해야 할 사항이 많으며, 성능을 높이기 위한 많은 시도가 요구된다.
- 이미 잘 훈련된 모델이 있고, 해당 모델과 유사한 문제를 해결해야할 때, Transfer learning을 이용하여, 높은 학습 성능을 얻을 수 있다.
Fine tuning
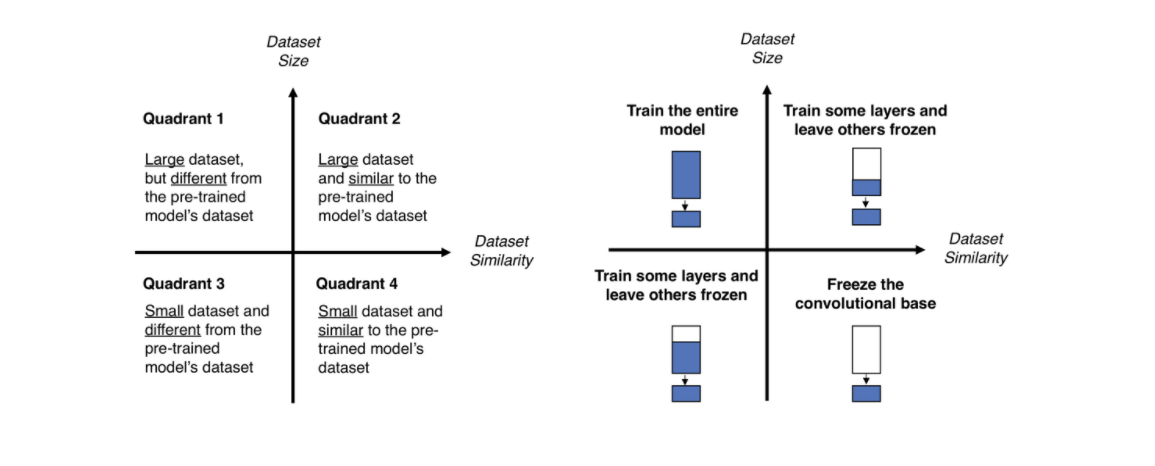
Small dataset, similar to the pre-trained model's dataset
- dataset이 적고, 기존 pre-trained model의 dataset과 유사한 경우이다.
적은 양의 데이터가 있기 때문에, 전체 네트워크에 대하여 fine-tuning을 할 경우, over fitting 문제가 발생할 가능성이 높다. 따라서, 최종 FC layer (LR = original LR / 10)에 대해서만 fine tuning을 진행한다. 이 때, Conv.layer의 학습을 막기 위해, LR을 0으로 하고, 학습하는 layer에 대하여는 기존 Conv.layer의 LR의 1/10 값으로 이용한다. (높은 값의 LR을 사용할 경우, 기존에 있던 정보들은 새로운 dataset에 맞춰 새로 업데이트 되어, pre-train의 이유가 사라지기 때문이다.)
Large dataset, similar to the pre-trained model's dataset
- dataset이 많고, 기존 pre-trained model의 dataset과 유사한 경우이다.
새로 학습할 dataset이 많다는 것은 over fitting의 위험이 낮다는 뜻이며, Conv.layer에 대해 fine tuning을 진행한다. 하지만, dataset이 유사하기 때문에, 시간적인 측면에서 전체 layer에 대해 fine tuning을 진행할 필요는 없다. 따라서, Conv.layer의 약간을 이용하여 기존 Learning rate의 1/10의 값으로 학습을 진행한다.
small dataset, different from the pre-trained model's dataset
- dataset이 적고, 기존 pre-trained model의 dataset과 유사하지 않은 경우이다.
data의 양이 적기 때문에, 적은 layer를 fine tuning하기에 학습 효과가 부족하고, 많은 layer를 fine tuning 하기에는 적은 dataset에 의해 overfitting 문제가 발생한다. 이와 같은 case의 경우, 적당한 양의 layer를 fine tuning 해야하는 어려움을 겪는다.
Large dataset, different from the pre-trained model's dataset
- dataset이 많고, 기존 pre-trained model의 dataset과 유사한 경우이다.
dataset에 차이가 있으므로, 아예 새로운 ConvNet을 만들수도 있지만, 실질적으로는 Transfer learning의 효율이 더 좋다. 이 경우 전체 Conv.layer를 fine tuning 하더라도, overfitting 문제가 크게 발생하지 않는다.
(20.04.07 - 곧 랩미팅이라서 여기까지 !)

𝑯𝒐𝒏𝒆𝒔𝒕𝒚 𝑰𝒏𝒕𝒆𝒈𝒓𝒊𝒕𝒚 𝑬𝒙𝒄𝒆𝒍𝒍𝒆𝒏𝒄𝒆