SROBB: Targeted Perceptual Loss for Single Image Super-Resolution
0. Abstract
최근 percptual loss 기반 super resolution 연구들은 성능 향상을 이뤄왔다. 이와 같은 objective function들은 거의 사진과 유사한 결과를 생성한다. 하지만 이는 이미지 내의 semantic information들을 고려하지 않고, 동일한 방식으로 전체 이미지의 reconstruction error를 계산하기 때문에 그 성능이 제한된다. 본 논문에서는 보다 객관적인 방법으로 perceptual loss로부터 benefit을 얻을 수 있는 새로운 방법을 제안하고 있다. 저자는 다양한 semantic level에서 image에 패널티를 주는 targeted objective function으로 deep network-based decoder를 최적화 시켰다고 한다. 특히, 이 방법은 segmentation 된 OBB(Object, Background, Boundary) label 정보를 활용하여 경계에 대한 적절한 perceptual loss를 추정하고, 배경에 대한 texture 유사성을 고려하게 해준다고 말한다.
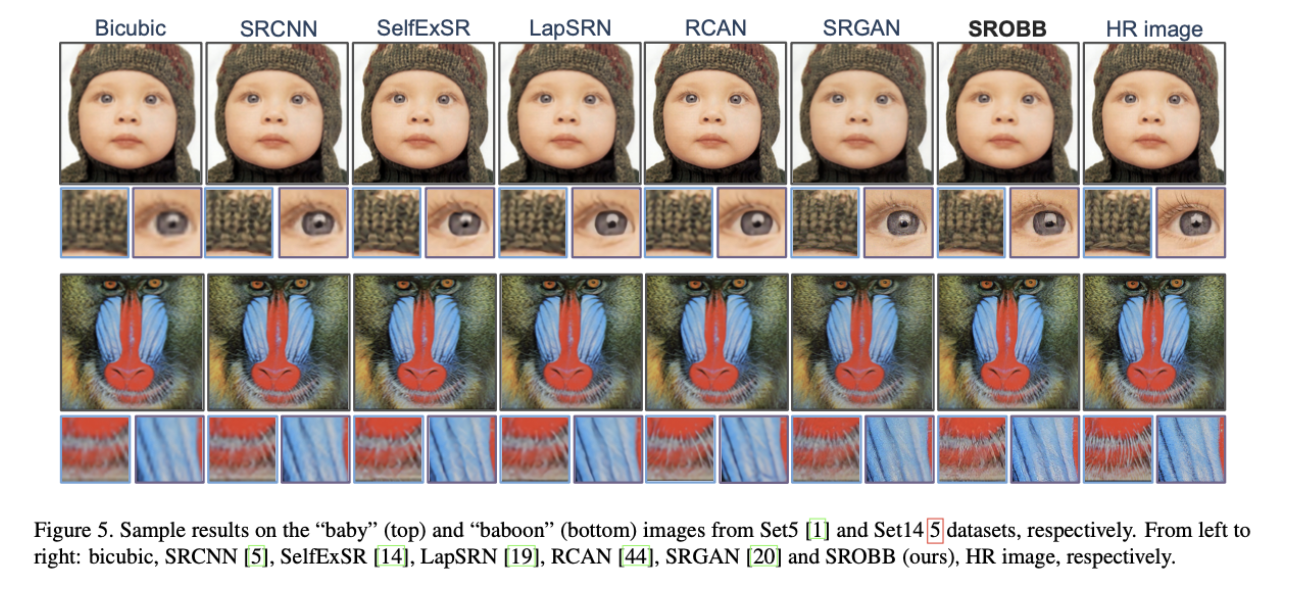
저자는 제안한 방식은 보다 사실적인 texture와 더 sharpe한 edge를 제공하며 SOTA를 능가한다고 말한다.
1. Introduction
SISR(Single Image Super Resoultion)은 LR 이미지로부터 HR 이미지를 복구해내는 것이다. CNN의 도입으로 높은 성능 향상을 보여온 SISR분야는 per-pixel loss와 MSE를 사용하는 대신 perceptual loss를 사용하면서 더욱 발전했다. 이를 사용함으로써 MSE 기반의 loss function에서 보여온 texture가 블러링되는 현상을 해결했다. 또한, adversarial loss와 함께 학습하여 이미지 품질 측면에서 거의 photorealistic한 reconstruction을 가능하게 하였다.
기존 loss function은 perceptual similarity를 사용하는 아이디어로부터 이점을 얻는다. 사전 훈련된 classifier 네트워크를 사용하여 HR과 SR 이미지를 특징 공간에 맵핑하고, deep feature domain에서 GT와 SR을 비교하여 모델을 최적화한다. 이러한 방법이 SISR에 성능 향상을 보이지만, semantic information을 고려하지 않고 적용할 때 그 성능은 제한적이다.
논문에서는 먼저 perceptual loss를 계산하는데 사용되는 pretrained CNN과 이를 이용해 네트워크를 어떻게 최적화시키는지 설명하고 있다. pretrained CNN의 초기 컨볼루션 레이어에서 각 뉴런은 출력에 영향을 미치는 입력의 크기와 모양을 가진 receptive field를 가지고 있다. SOTA CNN 접근 방식에서 일반적으로 사용되는 작은 커널은 그만큼 작은 receptive field를 갖게 된다. 이를 이용하면 낮은 레벨의 공간 정보만을 추출할 수 있다. pretrained CNN의 깊은 단계에서는 각각의 뉴런들의 receptive field가 커지는데, 이를 이용하면 global semantic meanings, abstract object information을 학습할 수 있다.
Perceptual function에 대해서는, 우선 SISR과 비슷한 task에서의 SOTA CNN들은 각각의 쓰임에 맞는 다른 level에서의 feature를 사용한다.
- local information —> low level feature
- texture —> mid level feature
- semantic informatoon —> high level feature
결국 전체 이미지에 대해 동일한 perceptual loss를 적용시키므로, edge, object, foreground, background에 관계없이 동일한 perceptual loss가 사용되었다는 의미이다. 이는, 나무와 같이 무작위의 텍스쳐 내에서의 edge detail들에 대한 loss는 불필요한 penalty를 고려한 것이 될 것이며, 따라서 필요성이 덜한 정보들을 학습하게 되는 것이다. 다른 한편으로, 영상 내의 edge부근에 대해 mid-level feature를 사용한 경우 날카로운 edge를 만들어내기는 커녕, "noisy" loss만 커질 것이다
이런 문제들을 다루기 위해, 저자는 perceptual loss를 더욱 objective 한 방법(각각 적합한 loss를 취하는 방법인듯)으로 사용하는 법을 제시한다. Figure 1은 제안하는 방법에 대한 개요를 나타낸다.
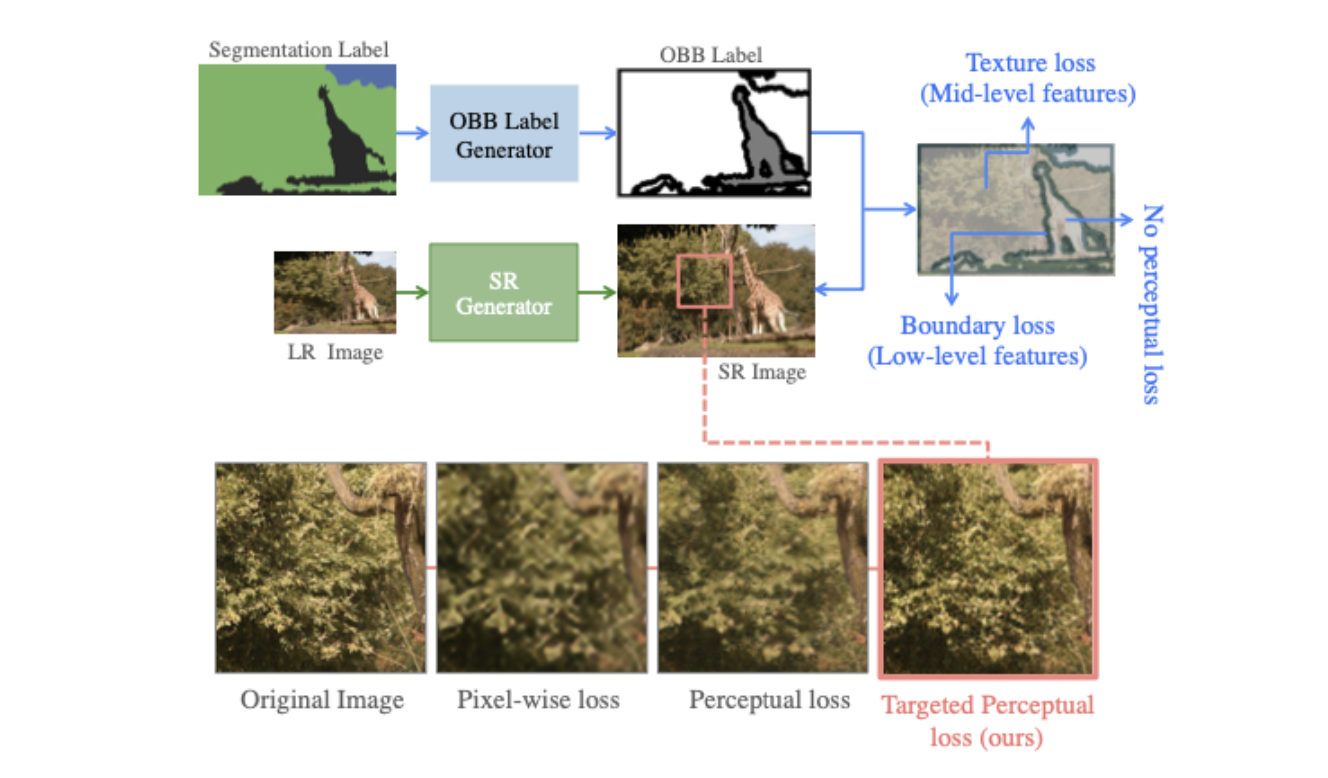
pixel-wise segmentation annotation을 저자가 제안하는 OBB label 기법에 활용하며, 이를 통해 원하는 perceptual feature를 사용하여 (edge 부근의 loss와 texture부근의 loss 등) 적절한 loss를 최소화시키는 방법으로 모델을 학습시킬 수 있다.
2. Related works
현재 CNN-based SISR은 end-to-end deep network 구조가 사용되고 있다. recursive한 형태를 띠며 구조가 깊을수록 SISR 성능을 높인다.
Vareiety of end-to-end deep network architectures:
- recursive CNN
- how deeper network architectures increase the performance of SISR
- residual blocks + skip connections
- removed BN, used several skip connections
- laplacian pyramid structure : proposed to progressively reconstruct the sub-band residuals of HR images.
3. Methodology
모델 아키텍쳐보다 objective function에 집중.
- Pixel-wise loss
- HR image와 SR image의 pixel 값 사이의 MSE 계산.
- 단점) 과한 스무딩 reconstruction. —> perceptual quality가 좋지 못하고, 고주파 edge나 texture등이 매우 부족해짐
- Adversarial loss
- Discriminator를 이용하여 adversarial 학습방법 채택ㄱ
- G는 D를 속일 fake image를 생성하기 위해 노력하며, D는 fake image를 구분하기 위해 서로 적대적 학습을 하며, 성능을 향상시킨다.
- pixel wise MSE, 기본적인 perceptual loss보다 좋은 성능
- Targeted perceptual loss
- perceptual loss 사용 SOTA: HR, SR 이미지를 VGG와 같은 classification net의 deep feature domain의 feature space로 mapping 시킨 뒤, 이들 간의 perceptual similarity 측정.
- 주로 feature map 간의 L2 distance를 최소화시키는 방향으로 사용
- perceptual loss + adversarial loss + MSE loss 동시 사용 시, 더욱 사실적인 SR이미지를 얻을 수 있는 이유 검증? 알려주기? 위해서 —> perceptual loss 계산에 사용되는 CNN 레이어의 원리, SR 이미지의 edge와 texture에 대해 HR이미지와 더욱 시각적으로 비슷해 보이게 만들어주는 방법 제안
- OBB (Object, Background and Boundary label)
- targeted perceptual loss는 o,b,b와 같은 semantic details들 활용에 집중한다.
- segmentation 라벨링이 boundary와 같은 edge 영역을 제외하고 background와 object로 나뉘는 기존 annotations에 대해, 이 논문에서는 semantic information을 활용할 수 있는 새로운 labeling 제안
- 미분을 통해 color-space에서 segmentation label의 edge를 계산한다. 그리고 더 두꺼운 edge를 얻기 위해 ... 음 이거 못쓸 듯
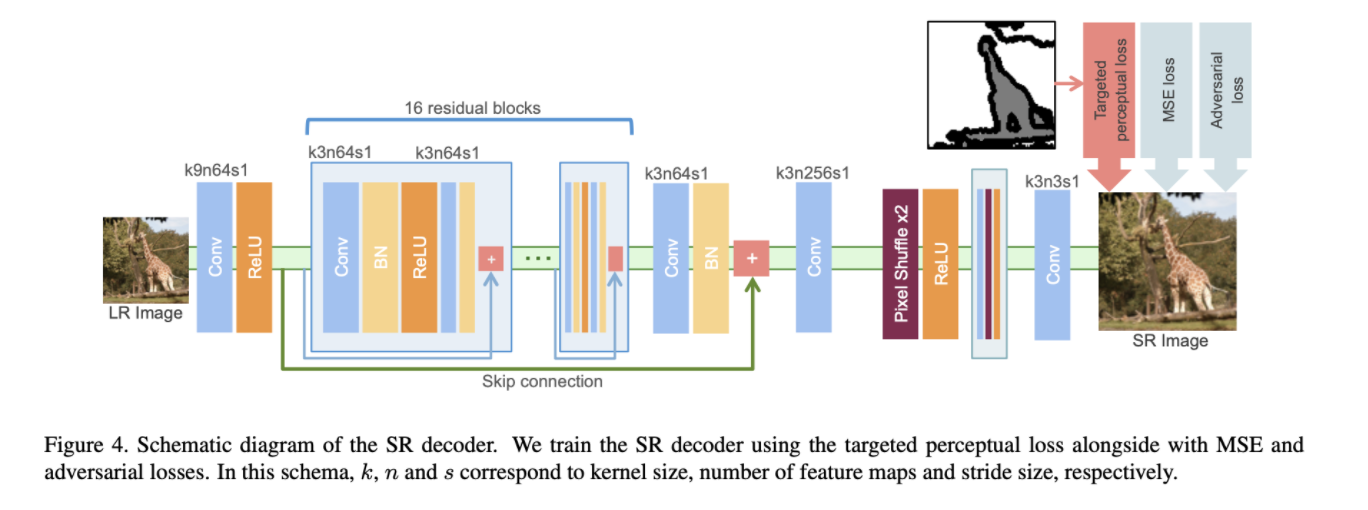
Architecture
4. Experimental Result