Differentiable Augmentation for Data-Efficient GAN Training
0. Abstarct
GAN을 학습시킬 때 제한된 양의 훈련 데이터가 사용될 경우, Discrimiator가 훈련 데이터를 기억하기 때문에 성능이 크게 저하되는 문제가 발생한다.
논문에서는 이를 해결하기 위해 실제 샘플과 가짜 샘플 모두에 다양한 유형의 augmentation을 적용하여 GAN의 데이터 효율성을 향상시키는 데이터 어그멘테이션을 제안한다.
훈련 데이터를 직접 증가시키려는 이전의 시도들은 실제 이미지의 분포를 조작하였기 때문에 성능에 있어서 이점이 없었지만, 논문에서 제안하는 DiffAugment를 사용하면 생성된 샘플에 대해 미분가능한 어그멘테이션을 선택하고 훈련을 효과적으로 안정화하여 더 나은 결과를 보인다고 말한다.
1. Introduction
딥러닝 알고리즘은 빅데이터를 통해 빠른 발전을 이뤄웠다. 특히 GAN의 SOTA 성능은 다양한 카테고리의 hight-fidelity한 이미지를 생성할 수 있게 되었다. 이러한 성공적인 결과는 많은 양의 계산과 데이터를 필요로 한다.
최근 연구자들은 모델 추론의 컴퓨팅 효율을 향상시키는 기술(Efficient Architectures for Interactive Conditional GANs)들을 제안했지만 데이터 효율성이 근본적인 해결 문제로 남아있다.
GAN은 방대한 양의 diverse하고 high-quality인 학습 데이터에 크게 의존한다. (ex. FFHQ, ImageNet) 하지만 이런 대규모 데이터셋을 만드려면 많은 annotation 비용과 인적 자원을 필요로 할 것이고, 희귀한 이미지나 특정 인물의 데이터의 경우에는 대량의 데이터셋을 만들 수 없는 경우도 발생한다.
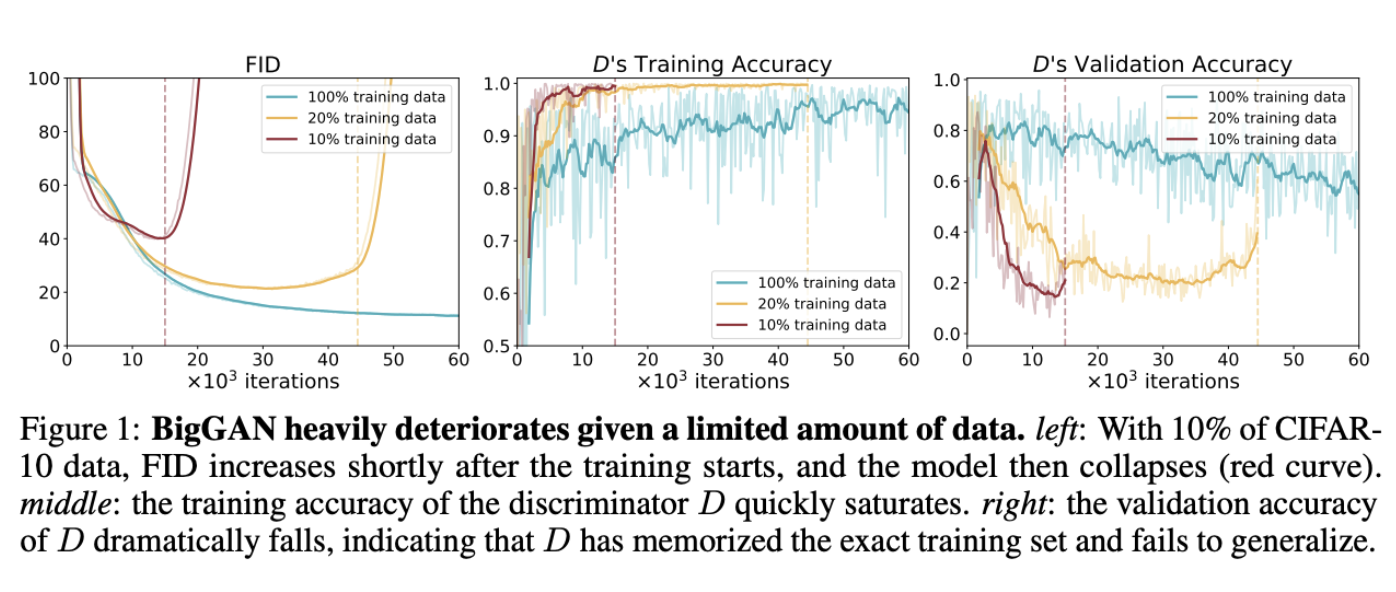
따라서, GAN 학습을 위한 방대한 데이터셋의 필요성을 제거하는 것이 critical한 문제일 수 밖에 없다. 그런데 트레이닝셋의 양을 줄이면 아래 사진처럼 overfitting되는 것을 볼 수 있다. —> 이미지 품질 저하 (아래 사진)
-
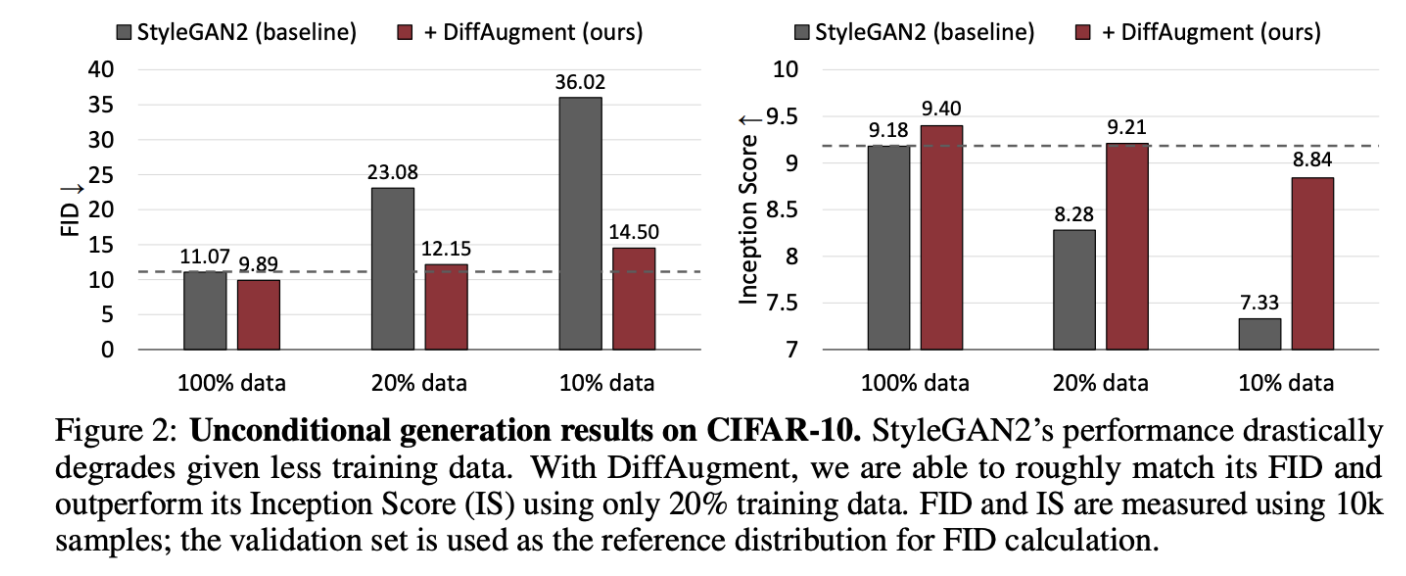
트레이닝 데이터가 적을 때 style GAN2의 성능 저하;
DiffAugment를 통해 FID를 대략적으로 일치시키고 20%의 트레이닝 데이터만 사용하여 Inception Score(IS)를 능가할 수 있다.
Image classification에서는 오버피팅을 줄이기 위해 새로운 샘플을 수집하지 않고, 학습 데이터의 diversity를 증가시키는 데이터 어그멘테이션을 사용하고 있다. (ex. cropping, flipping, scaling, color jittering, region masking; for vision model)
❗️GAN의 data augmentation은 근본적으로 다른 방법을 취한다.
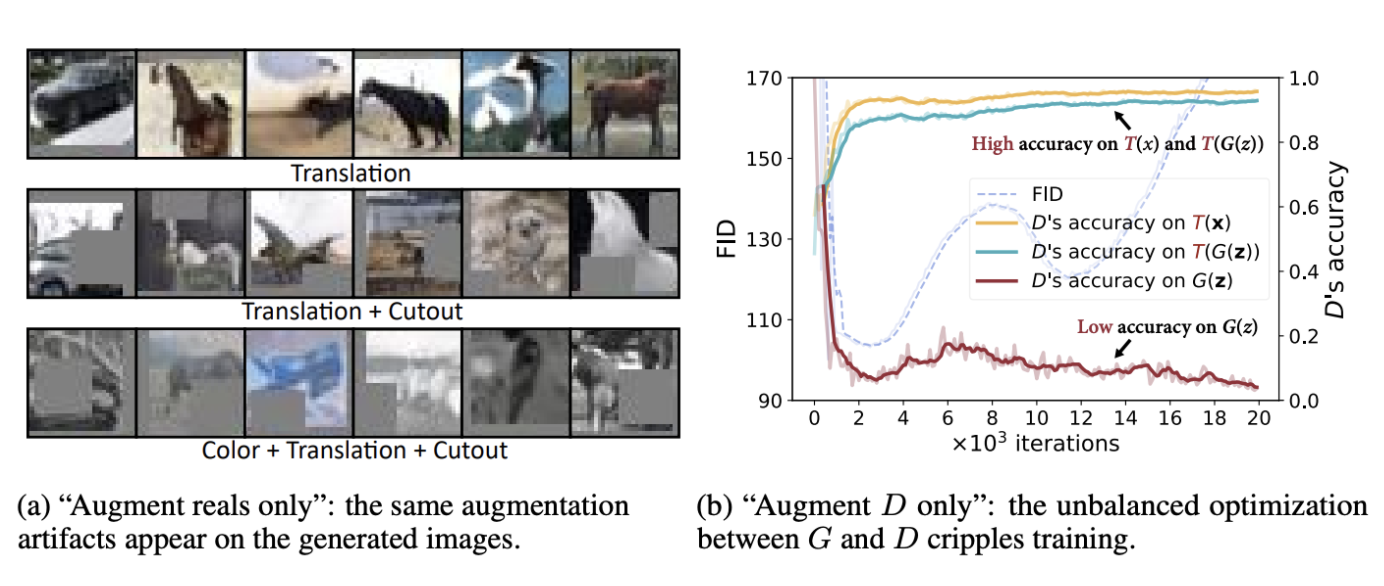
Transformation이 real image에만 추가된 경우, Generator는 augmented image의 분포와 일치하도록 권장된다. 결과적으로, 아웃풋은 distribution의 이동과 도입된 artifact로 인해 가려진 영역 또는 부자연스러운 색상과 같은 결과를 얻는다. (a)
Discriminator를 학습할 때 real 이미지와 generated 이미지를 둘 다 augmetation할 수도 있지만, 이는 G와 D 사이의 균형을 깨뜨려 다른 목표를 최적화하므로 convergence가 떨어진다. (b)
💡Diff Augment
Diff augment는 G와 D 훈련을 위해 실제 이미지와 fake 이미지 모두에 differntiable augmentation을 적용한다.
이 방법은 augmentation을 통해 gradient가 다시 Generator로 전파되게끔 하고, 타겟의 분포를 조작하지 않고 Discriminator를 정규화하며, 트레이닝의 균형을 유지한다. 다양한 GAN에다가 실험을 했을 때 일관적인 효과가 있는 것을 확인했다고 한다.
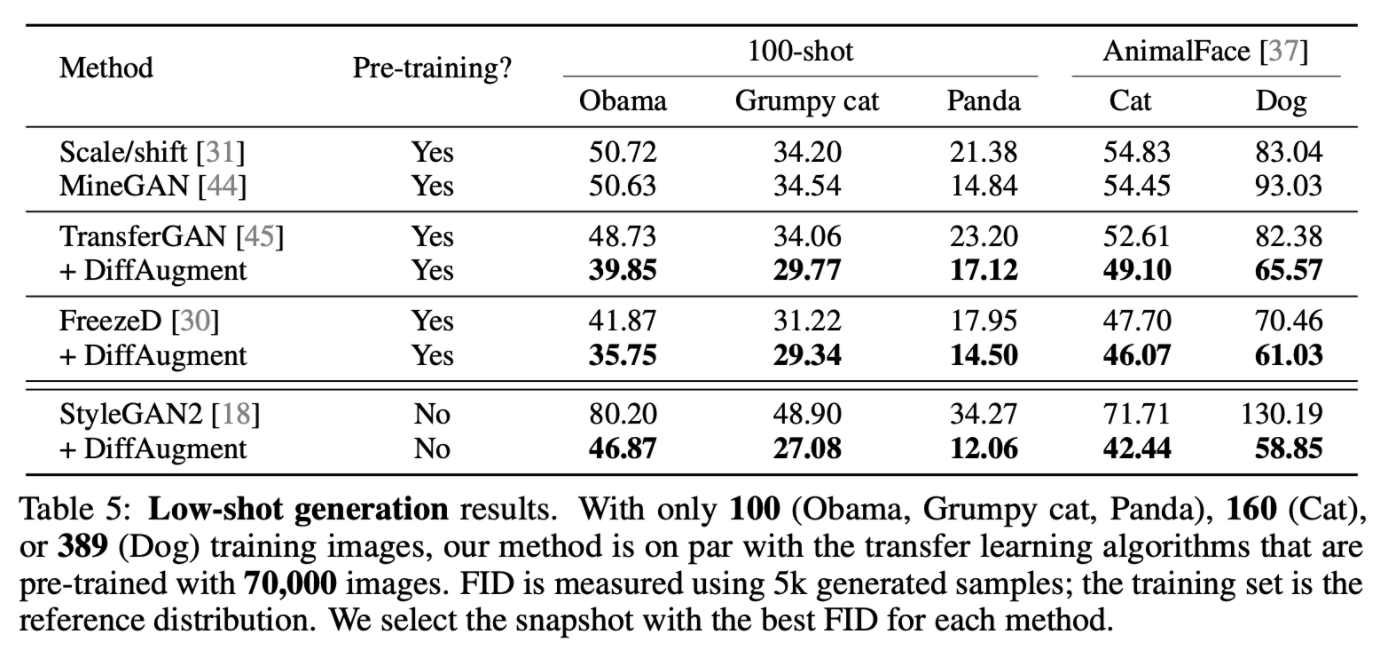
➡️ Without any pre-training, we achieve competitive performance with existing transfer learning algorithms that used to require tens of thousands of training images.
오 굳굳
2. Related work
- GAN
- Regularization for GANs:
- 다른 관점의 데이터 어그멘테이션을 제공하며, Discriminator가 다양한 유형의 어그멘테이션에서 잘 수행되도록 하는 방법 제안.
- Data Augmentation
- 많은 딥러닝 모델에서 오버피팅을 피하기 위해 label-preserving transformation을 취하고 있다. (ex. color jittering, region masking, flipping, rotation, ..., etc.)
- But GAN과 같은 생성 모델에 데이터 어그멘테이션을 적용시키는 것은 열려있는 문제이다.
- label이 입력의 변환에 불변하는 classifier 훈련과 달리 생성 모델의 목표는 데이터 분포 자체를 학습 하는 것이기 때문에.
- augmentation을 직접 적용하면 분포가 변경된다.
3. Method
GAN은 G와 D를 통해 타겟 데이터셋의 분포를 모델링하는 것을 목표로 한다.
Generator는 일반적으로 가우시안 분포에서가져온 input latent vector z를 아웃풋 G(z)에 mapping한다.
Discriminator는 생성된 샘플 G(z)를 실제 관측치인 x와 구별하는 방법을 학습한다.
번갈아가며 최적화.
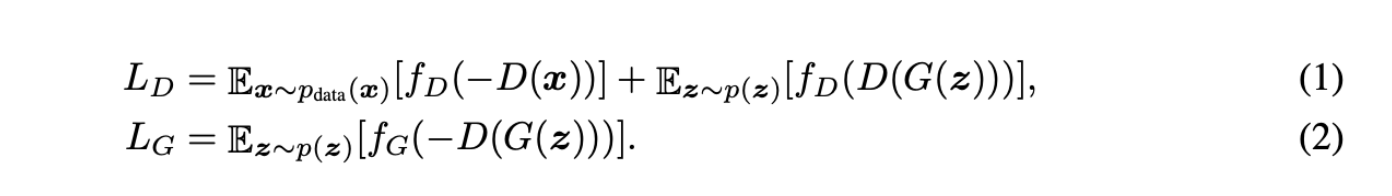
Overview of DiffAugment

T는 D와 G를 업데이트하며, DiffAugment는 실제 샘플 x와 생성된 출력 G(z) 모두에 T를 증가시킨다. G를 업데이트 할 때 기울기는 T를 통해 backprop되어야 하므로 입력과 미분 가능해야 함.
Discriminator는 학습이 진행됨에 따라 관측치를 기억하려는 경향이 있다.
과적합 된 discrimnator는 정확한 트레이닝 데이터 포인트 이외의 생성된 샘플에 패널티를 주고, poor generalizaion으로 인해 uninformative한 기울기 제공, 트레이닝 불안정 초래한다.
3.1. Revisiting Data Augmentation
지금까지 데이터 어그멘테이션을 GAN에 적용해도 baseline이 개선되지 않았다. 왜 효과적이지 않은 것인가?
🚩 Augment reals only
- GAN을 augmenting 하는 가장 간단한 방법은 augmentation T를 실제 관측치 x에 다이렉트하게 적용하는 것이다.
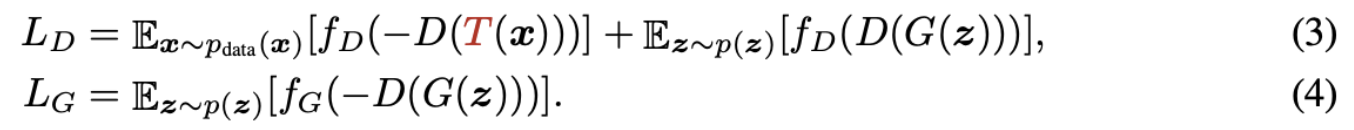
- Augment reals only는 모델이 x대신 T(x)의 다른 데이터 분포를 학습하게 되기 때문에 생성 모델의 원래 목적과 달라진다. 따라서 실제 이미지의 분포를 크게 변화시키는 어떤 aumgentaion을 적용할 수 없다..
- 위의 요구사항을 충족하는 선택은 특정 데이터셋에 따라 다르긴 하지만, 대부분의 경우 horizontal flips만 할 수 있다.
- 무작위 horizontal flips을 통해 성능이 적당히 향상되었으며, 모든 실험에서 이를 이용하여 baseline을 더 향상시키는 것을 확인하였다고 한다.
🚩Augment D only
- Augment reals only는 실제 샘플에 one-side augmentation을 적용하므로 생성된 distribution이 실제 distribution과 일치하는 경우에만 수렴이 가능하다. 그런데 Discrimnator의 관점에서, D를 업데이트 할 때 실제 샘플과 가짜 샘플을 둘 다 증가시키고 싶을 수 있다.
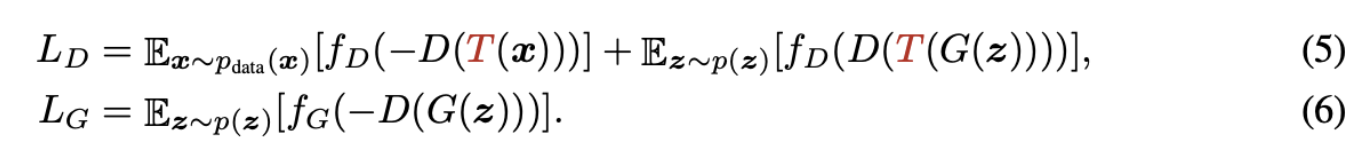
- 동일한 함수 T가 실제 샘플 x와 fake 샘플 G(z)에 적용된다. G가 x의 분포를 성공적으로 모델링하면 T(G(z)), T(x)는 G(z)와 x 뿐 아니라 G와도 구별 할 수 없다.
- D는 augmented generated 이미지와 잘 작동하지만, 생성된 원본 이미지를 인식하지 못한다.
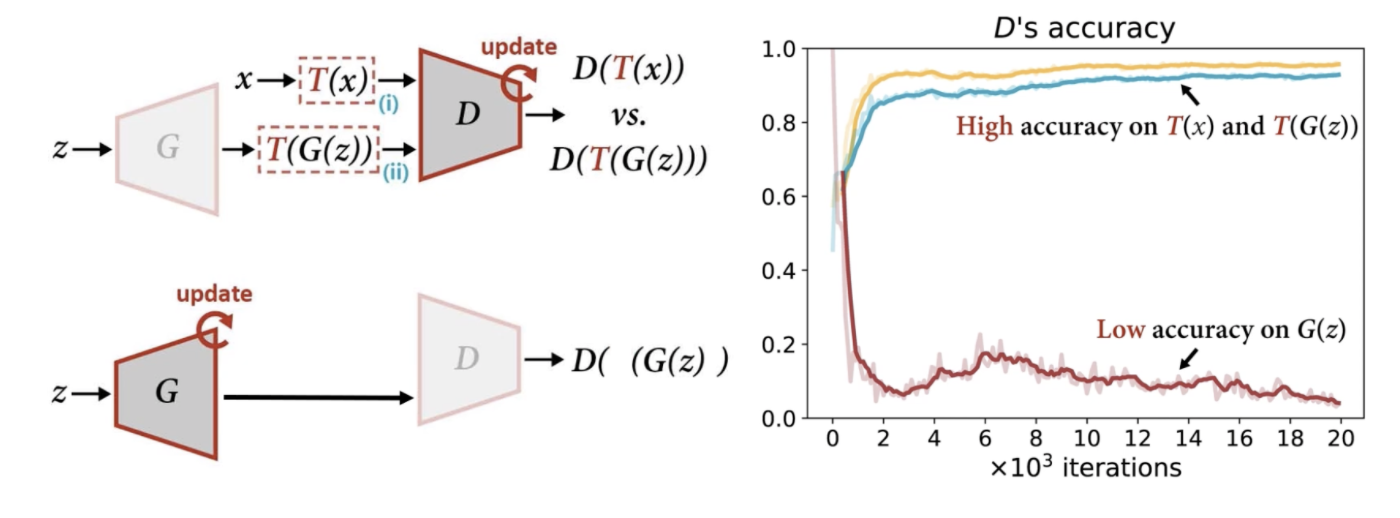
—> 최적화 될수록 나쁜 결과 초래
3.2. Differentiable Augmentation for GANs
- Augmenting both real and fake samples, and training generator and discriminator on them, leads to impressive results.
- augmented sample을 통해 G로 기울기를 전파하려면 augmenntation T를 아래 그림과 같이 미분 가능해야 한다.

T는 동일한 함수이여야 하지만, figure4에 나와있는 3개의 위치에서 반드시 동일한 random seed일 필요는 없다.
논문에서는 3가지 간단한 transformation과 composition을 사용하여 diffAugment의 효과를 보여준다.
4. Experiments
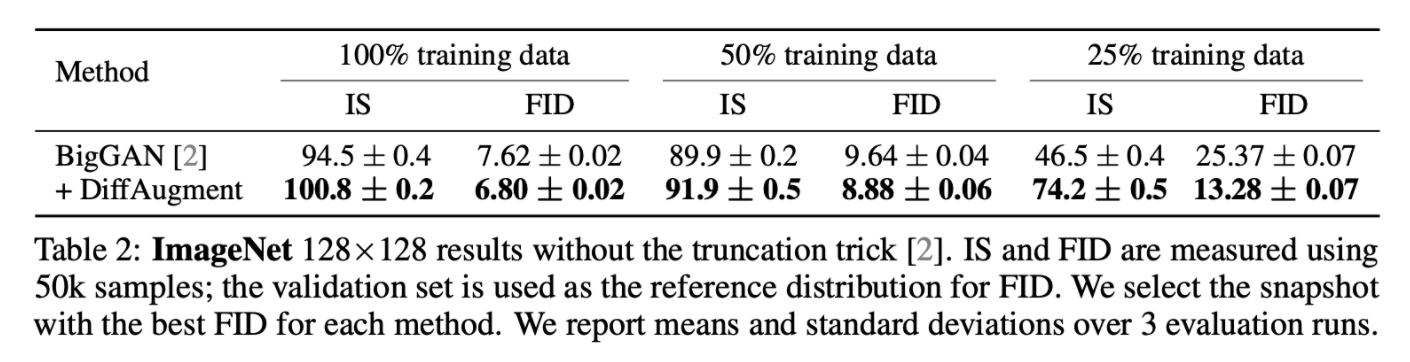
4.1. ImageNet
4.2. FFHQ and LSUN-cat
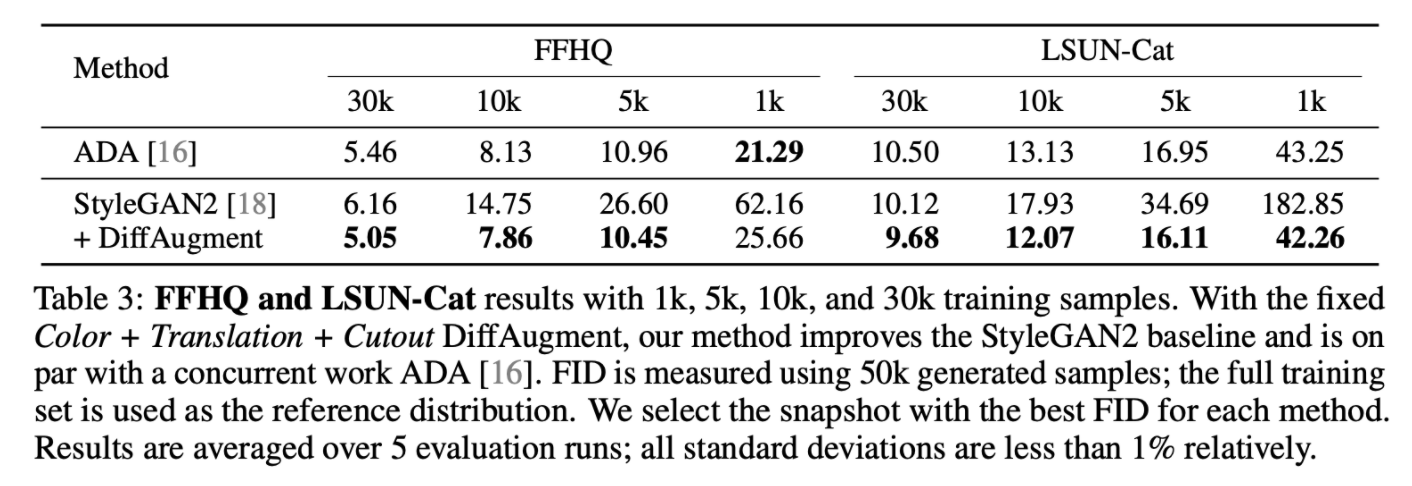
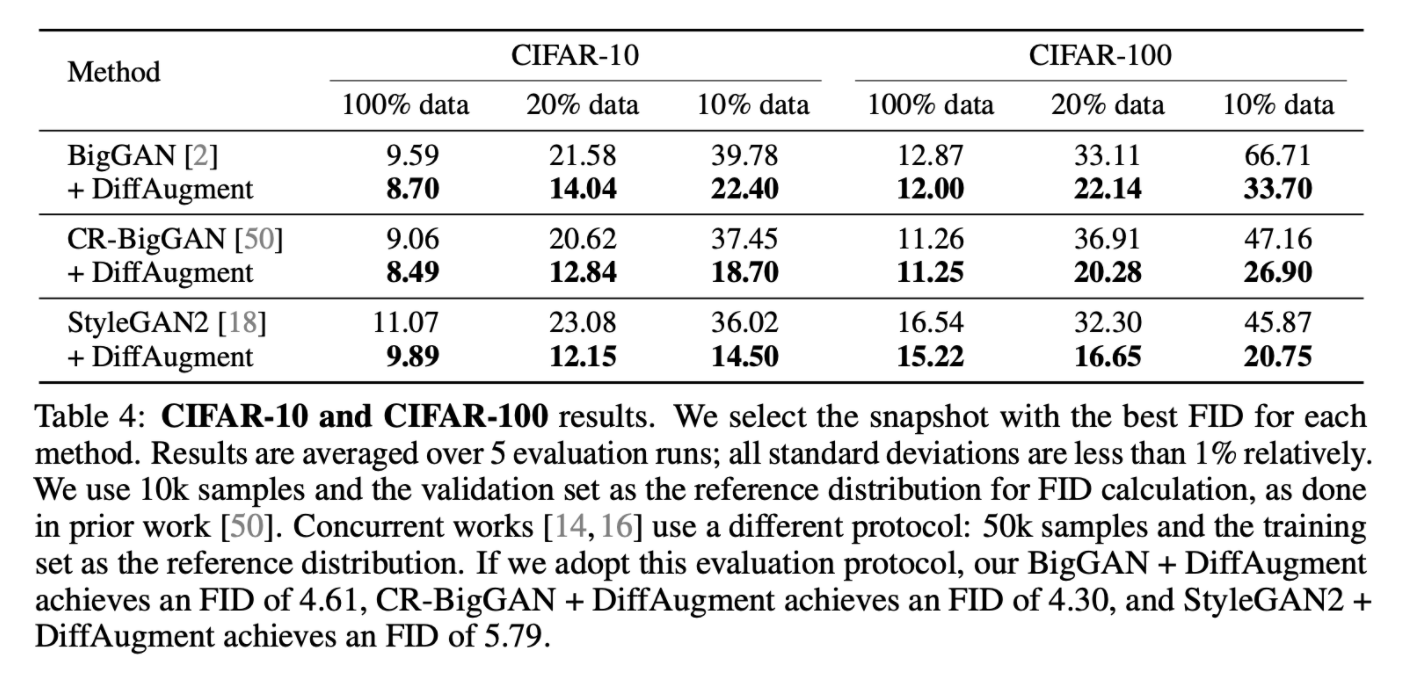
4.3. CIFAR-10 and CIFAR-100
4.4. Low-shot generation
5. Conclusion
- DiffAugment는 실제 샘플과 가짜 샘플을 모두 늘리면 Discriminator가 overfitting 되는 것을 효과적으로 방지하는 것을 보여준다.
- The augmentation must be differentiable to enable both generator and discriminator training.
블로그에 정리도 다시 열심히 해야지...
