ConvNeXt
ConvNeXt
intro
목적
: CNN의 최신화
배경
: vit(어텐션 기법을 적용한 비전 트랜스포머)에 비해 cnn모델들은 너무 old
=> ResNet을 swin transformer에 맞게 변형 (vit의 대표모델 = swin)
- vit와 유사한 조건으로 CNN을 학습 및 구성-> 성능향상
- 결국 CNN을 좀 더 최신화하는 것!
- 최근학습 및 모델 구조 변화에 대한 흐름 파악도 가능
1. trianing Techniques
Adam W
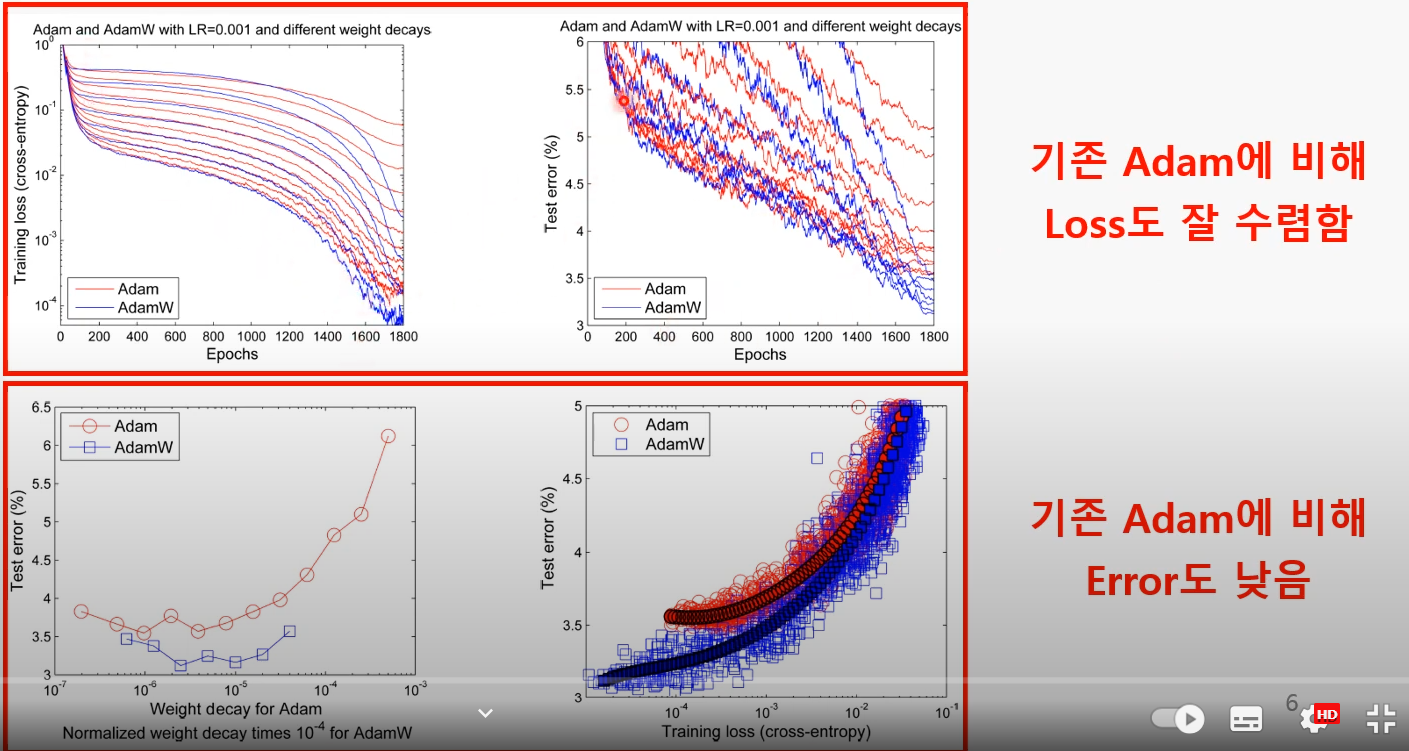
최근 연구에서 대부분 Adam W를 사용
why?
-> 1. Weight decay와 Learning Rate 간 관계가 독립적
eg) x값 하나로 고정해 두고 y값만 바꿔가며 실험 가능
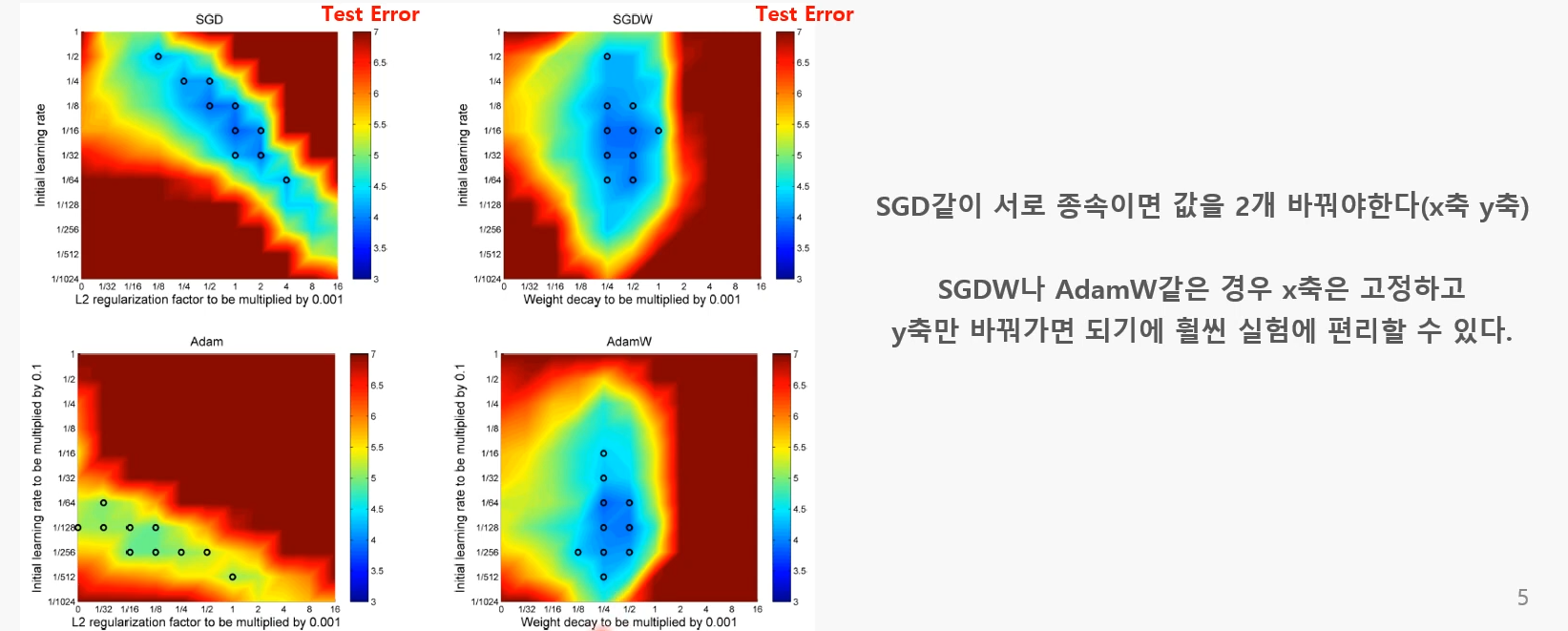
-> 2. 일반화 성능우수
2. 모델에서 변화 포인트
목적
: attention 없이 ResNet을 최신화!
- 사용된 기술들과 그에 따른 성능 변화
- 성능을 올린 기술을 모두 넣어 82까지 점수를 올림(최신기술들 때려 넣음)
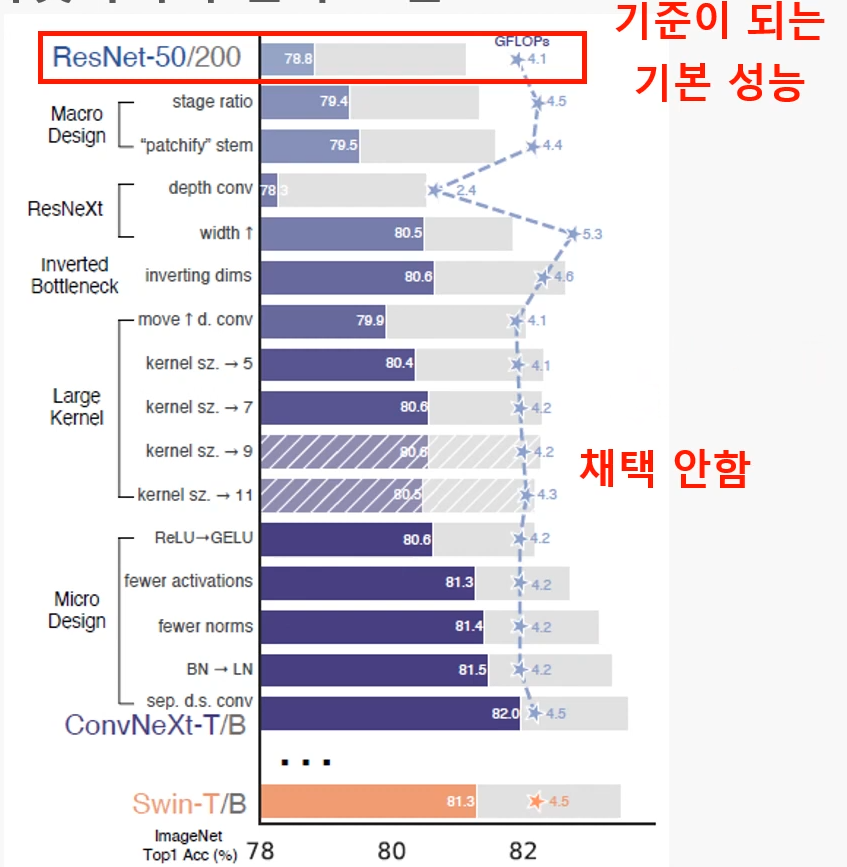
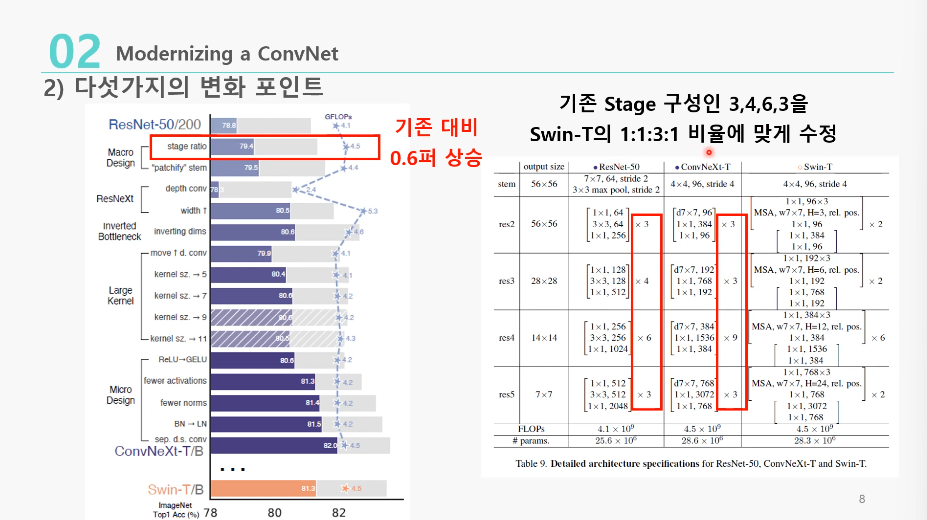
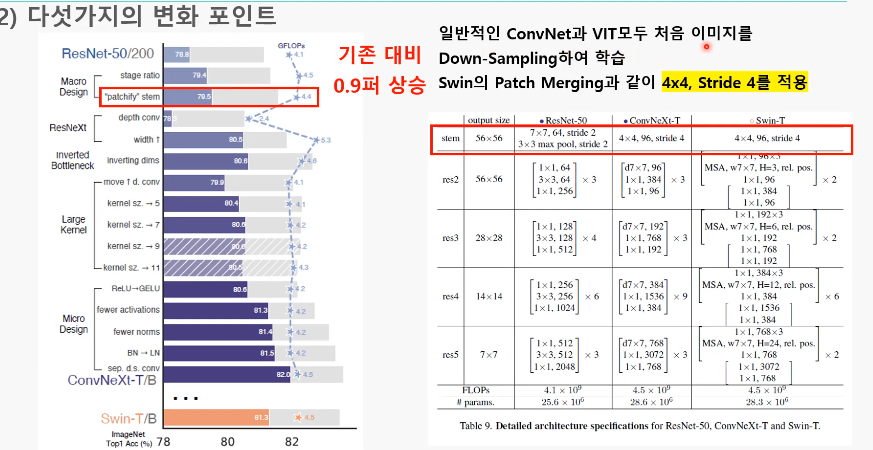
1. stage ratio( 78.8% -> 79.4% )
: stage 구성을 3:4:6:3(ResNet)에서 1:1:3:1(Swin-T)로 바꿈
2. “Patchify” stem( 79.4% -> 79.5% )
: 첫번째 입력이미지를 다루는 부분 stem 에서 (7x7,stride=2)->(4x4, stride=4)로 바꿈
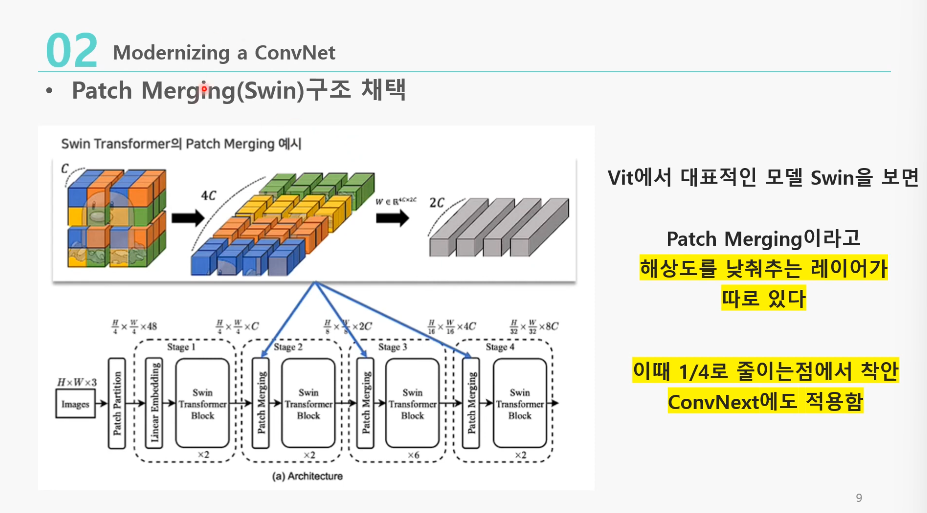
Swin Transformer에서 Patchify는 ResNet의 첫 Conv 레이어(Stem)과 비슷하다고 봤기 때문
- Swin-T의 Patch merging을 차용한 것
- Patch merging: swin transformer에서 해상도를 낮춰주는 레이어를 따로 둔 것
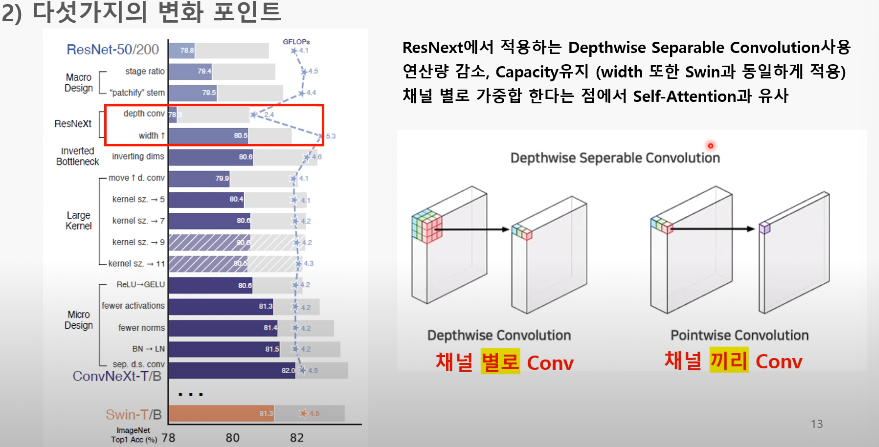
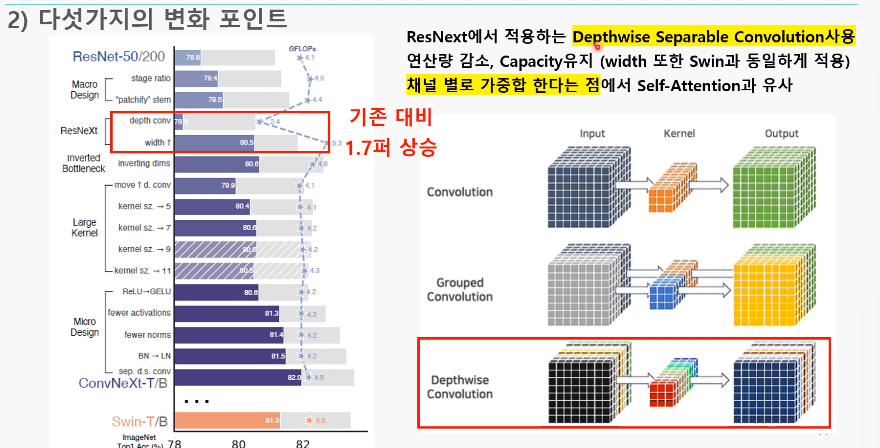
3. Depthwise separable Convolution 사용, Width up (79.5% -> 80.5%)
: REsNeXt의 그룹 컨볼루션 아이디어를 가지고, Depthwise separable Convolution을 사용
+) 적어진 연산량으로 Width를 넓힐 수 있었음
- Depthwise separable Convolution
: Depthwise conv+pointwise conv
- Point-wise convolution: 커널 크기가 1x1인 convolution layer(차원 변경 용, ConvNet에선 Linear로 구현됨)
- Depthwise Conv 이후 1×1 Conv가 DepthWise의 채널별 정보가 섞이도록 함
-> 파라미터가 줄어들면서도, Accuracy는 최대한 유지- Self-Attention 구조에서 가중합 연산과 비슷함(각 채널의 내에서만 정보를 처리한 뒤 채널끼리 혼합)
-
연산량의 감소로 채널의 너비를 증가시킴 ( 64 -> 96 )
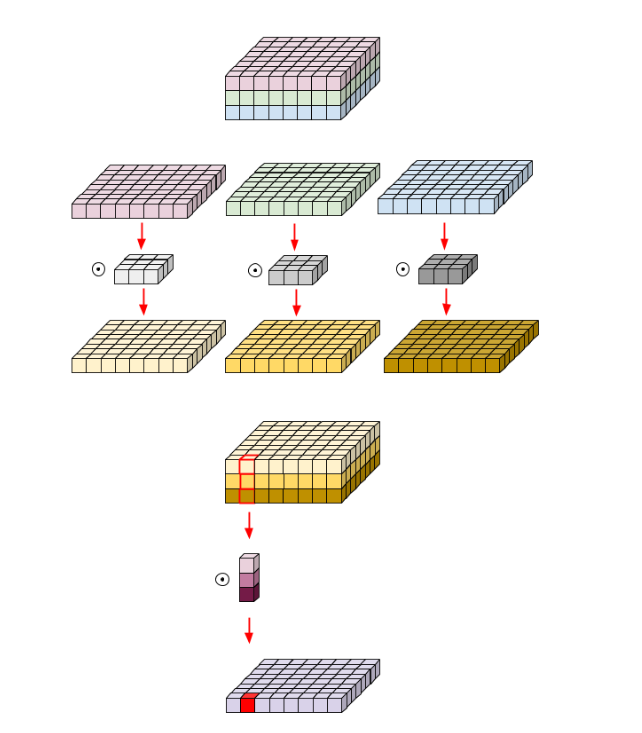
+) Depthwise conv
 : 그룹 수를 채널 수로 두고 그룹 컨볼루션을 실행하는 거랑 동일
: 그룹 수를 채널 수로 두고 그룹 컨볼루션을 실행하는 거랑 동일
+) 그룹 컨볼루션의 output 채널은 그룹 수 x 커널 갯수임- Depthwise conv 예시
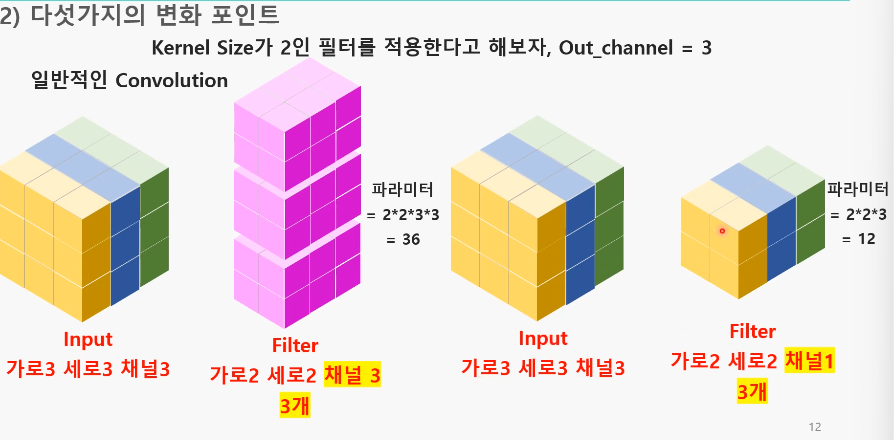
- Depthwise conv 예시
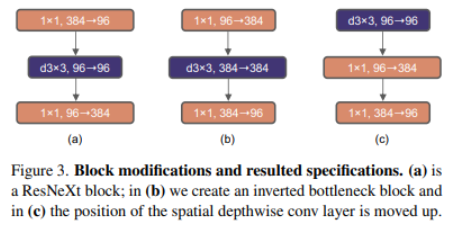
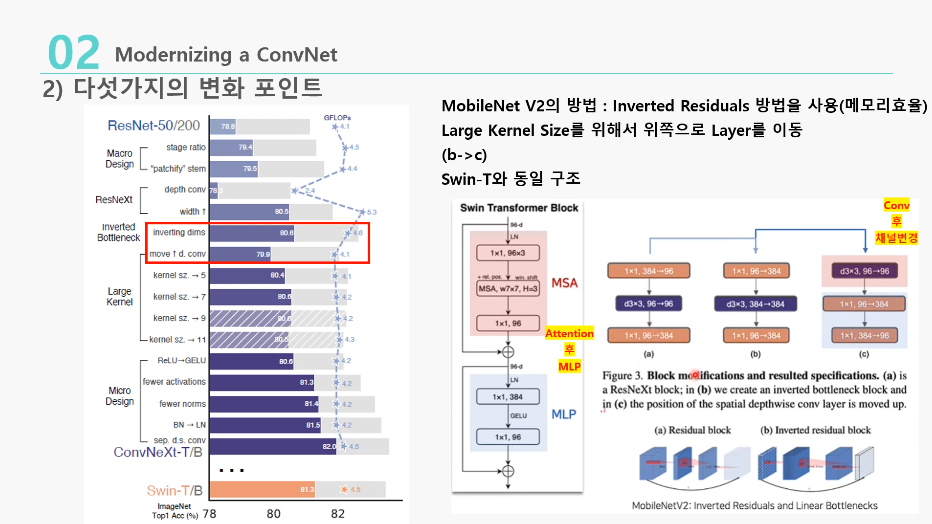
4. Moving up depthwise conv layer( 80.6% -> 79.9% )
: Transformer의 Self Attention은 각 블록 앞에 위치함
Self-Attention과 비슷한 특징을 가지는 ConvNeXt의 Depthwise Conv을 각 블록 앞에 위치하도록 변경
- 기존: 1x1(채널 축소)->conv->1x1(채널 복구)(a)(b와 c는 inverted bottleneck이라고 부름)
- 변경: conv->1x1(채널 확장)->1x1(채널 복구)(c)(결국 depthwise 이후, pointwise 과정을 나타내는 것!)
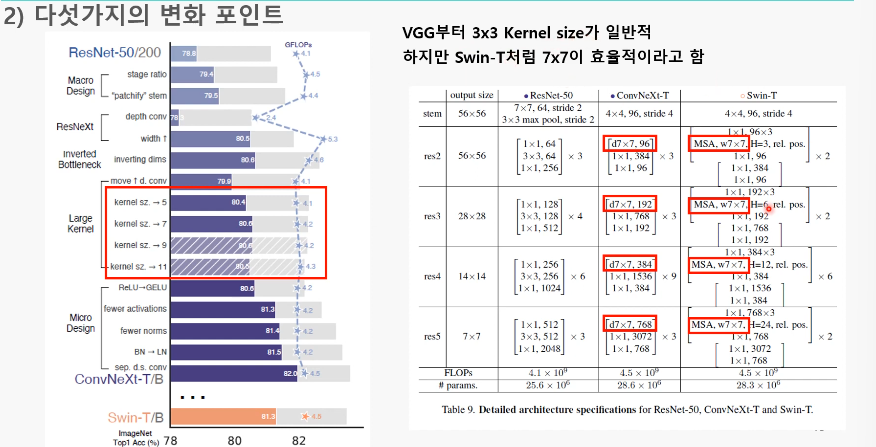
5. Increasing the kernel size ( 79.9% -> 80.6% )
: 7x7 conv layer를 사용
- Swin Transformer의 Window 크기는 7×7임
- 3×3 크기의 Kernel을 7×7 크기로 변경
6. GELU로 교체
:ReLU 대신 GELU를 사용
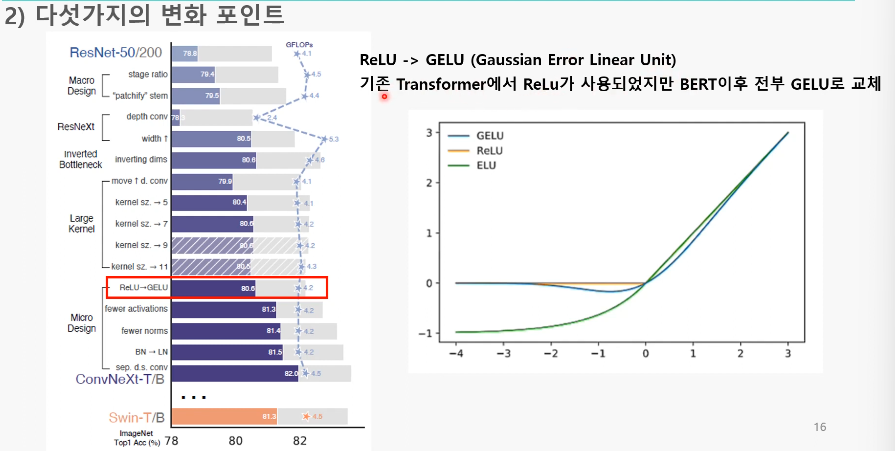
-
ReLu의 문제
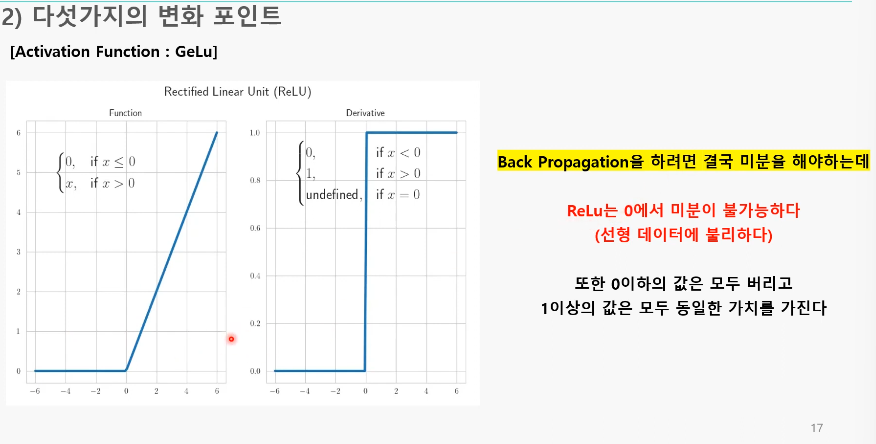
1. 0에서 미분 불가로 선형데이터에 불리
2. 1이상의 값에 대해 모두 동일한 가치 -
GELU의 장점
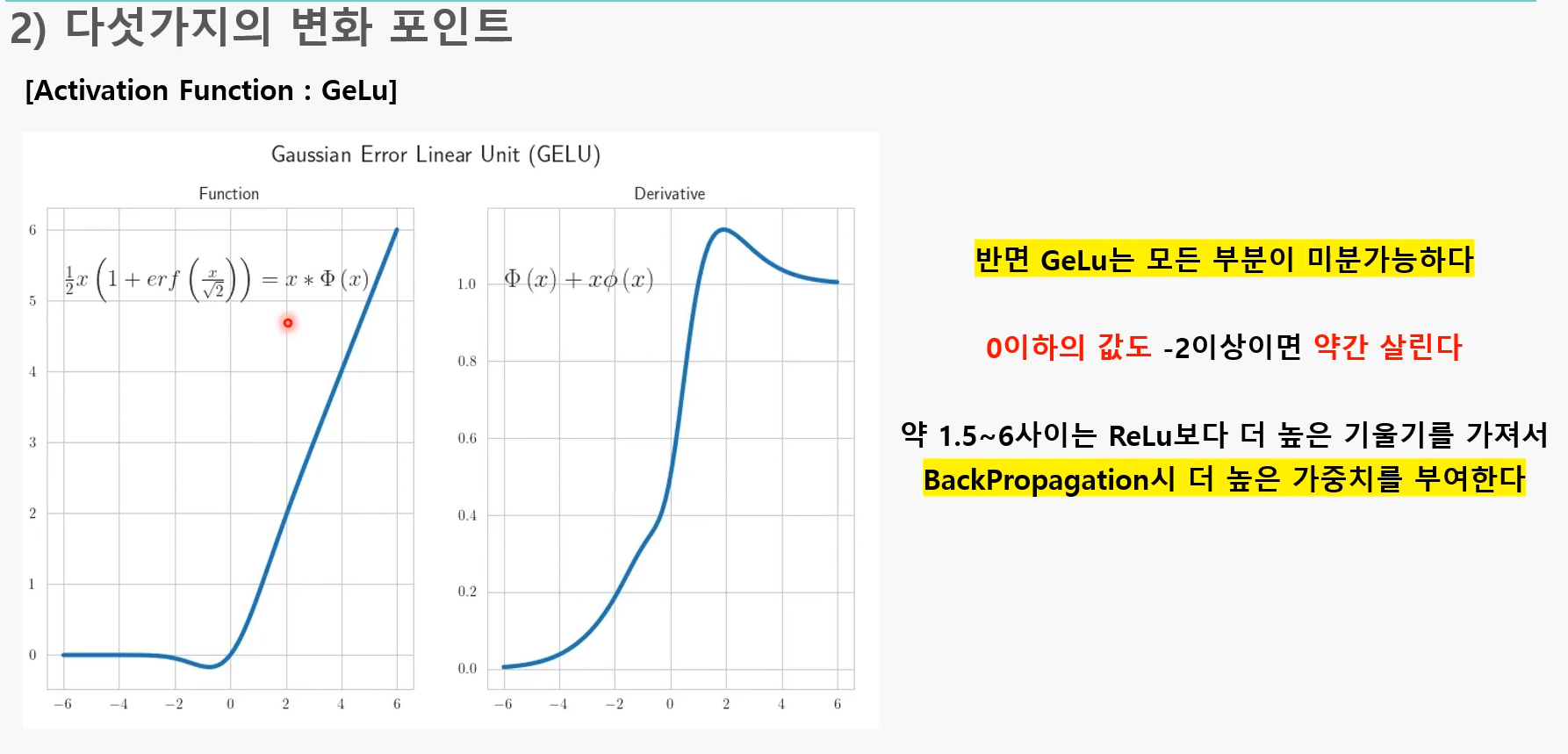 1. 0이하도 약간 살림
1. 0이하도 약간 살림
2. 일정 부분 더 높은 기울기-> 역전파시 더 높은 가중치
-> 결과적으론 GELU를 사용하면 인풋들이 정규분포를 띄게 되어서 좋았음
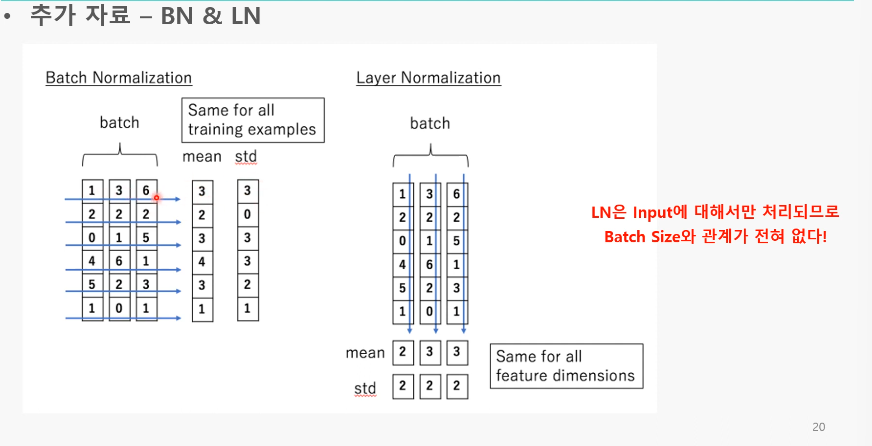
7. activation/Normalization을 한번만 적용, Batch Normalization->layer Normalization
- Layer Normalization
BN->첫번째 이미지와 두번째이미지가 관련없는 이미지라면?->문제가 됨
LN->이미지마다 정규화-> 이미지 하나하나의 데이터도 더 잘 파악 가능- 그림과 달리 이미지 마다(면) 단위로 정규화됨
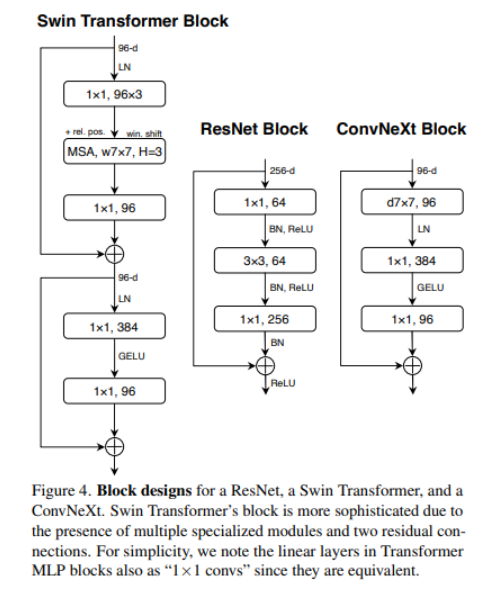
8. Separate downsampling layers( 81.4% -> 82.0% )
: stage마다 Down sampling 레이어를 따로 둠
- ResNet: 박스 첫번째 레이어에서 stride=2로 두고 해상도를 낮춤
- Swin Transformer: 다음 계층으로 갈 때 인접한 윈도우를 하나로 뭉침
-> 이를 CNN에서는 Downsampling 레이어라고 판단- ConvNeXt의 Downsampling 레이어를 따로 두고, 3×3 Conv를 2×2로 변경
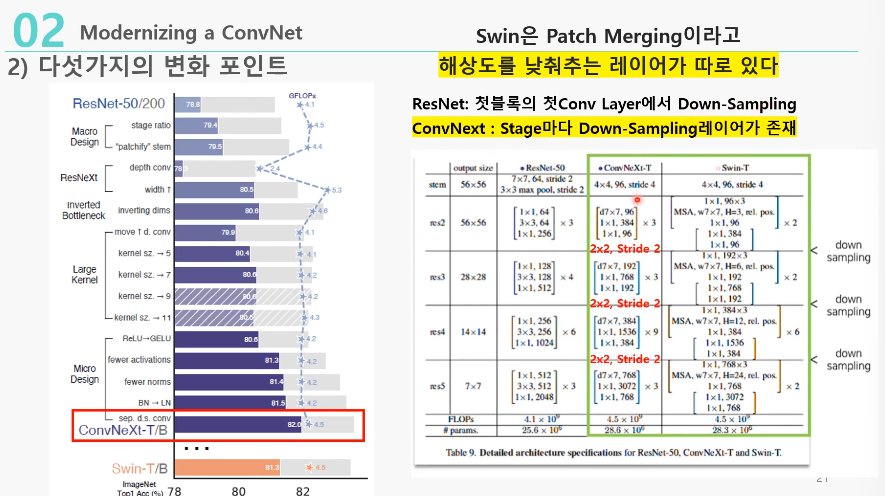
V stride 그대로??, 원래는 stride 한다음 바로 downsampling으로 차원 맞춰줌
정리
1. stage 구성을 1:1:3:1로 바꿈
2. “Patchify” stem
3. Depthwise separable Convolution 사용
4. Moving up depthwise conv layer
5. 7x7 conv layer를 사용
6. GELU로 교체
7. activation/Normalization을 한번만 적용
Batch Normalization->layer Normalization
8. Separate downsampling layers
모델 전체 구조
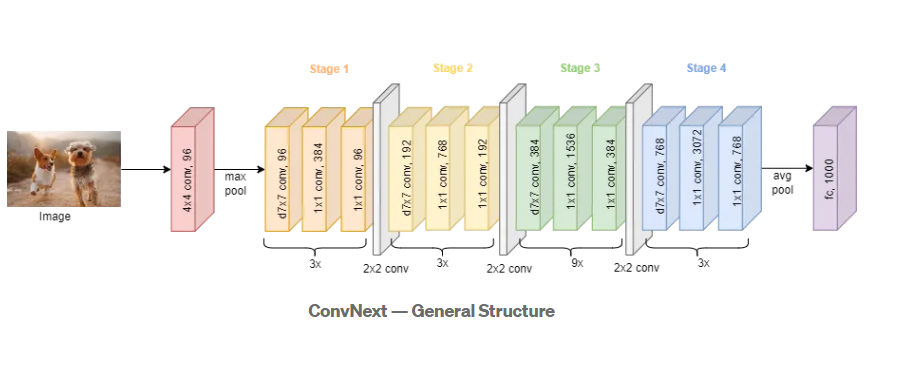
블록 한개 구조
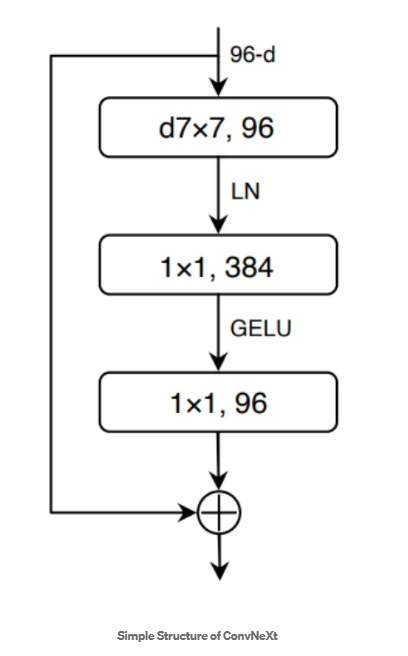
결과
- 높은 성능 달성
- CNN 기법으로 만들어진 기존 기법에 적용이 가능(vit에 비해)
code로 더 자세히
Block 설정
1. 기본 구조
1. 입력 이미지
입력 이미지 텐서 의 차원:
2. Conv2D 레이어 적용(Depthwise)
Conv2D 레이어를 통해 공간적 특징을 추출한 후의 출력 텐서 :
3. Permute
채널 차원을 마지막으로 이동하여 텐서를 재배열한 후의 출력 텐서 :
- [N,C,H,W]->[N,H,W,C]
- Normalization
정규화를 적용한 후의 출력 텐서 :
- 첫 번째 Linear Layer(Point-wise)
각 픽셀 위치 에서의 입력 벡터 를 선형 변환한 후의 출력 텐서 :
- GELU
GELU 활성화 함수를 적용한 후의 출력 텐서 :
- 두 번째 Linear Layer(Point-wise)
각 픽셀 위치 에서의 입력 벡터 를 선형 변환한 후의 출력 텐서 :
- Permute
출력 텐서를 원래 차원 순서로 되돌린 후의 최종 출력 텐서 :
- Linear Layer
: 차원을 줄이고 늘리는 방법 중 하나
- Conv2D와 차이
: Conv2D의 사용은 이미지의 공간적 특징을 추출하기 위함이었음
Linear Layer는 입력의 모든 요소 간의 관계를 고려하여 계산 함으로써 전역적인 정보를 얻을 수 있음.
-> 오히려 클래스 예측이나 회귀 문제에선 더 유용,
+) 가중치 행렬하나로 계산 -> 단순함,계산 적음- 예시)
입력 차원:
(각 픽셀 위치 에서 차원의 벡터가 존재)
가중치 행렬 의 크기:
=>출력 벡터 의 크기:
의문)
왜 차원을 늘렸다 줄였다 하지?
->Linear Layer를 통해 차원을 늘리고 활성화 함수 (예: ReLU, GELU 등)를 적용하면, 네트워크는 더 복잡한 비선형 변환을 학습할 수 있습니다. 이는 모델의 표현력을 크게 향상시킵니다.
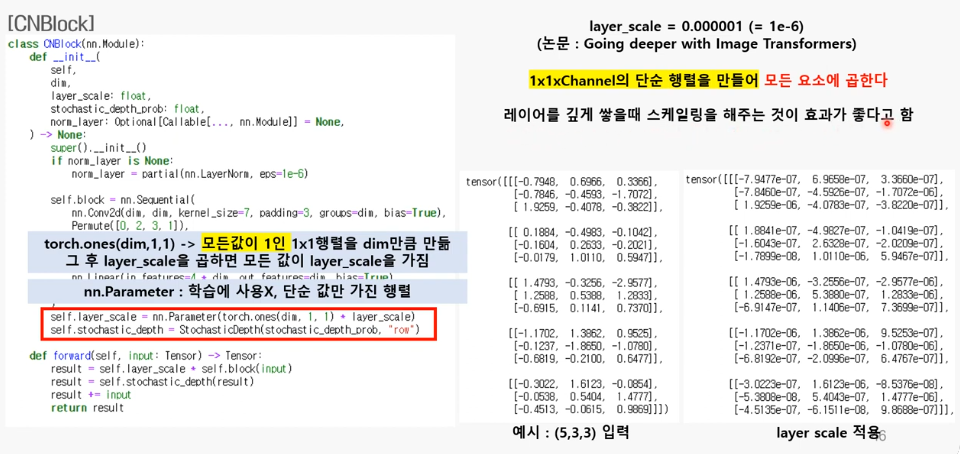
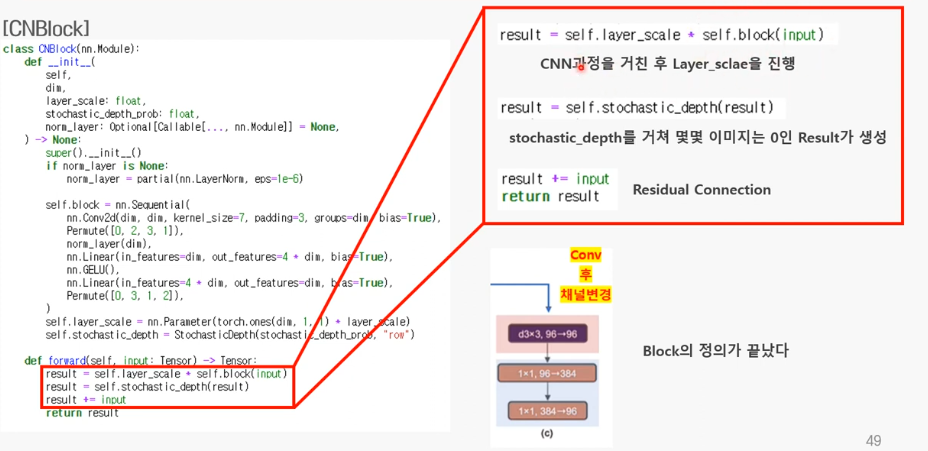
2. 레이어 스케일과 Stochastic Depth
레이어 스케일
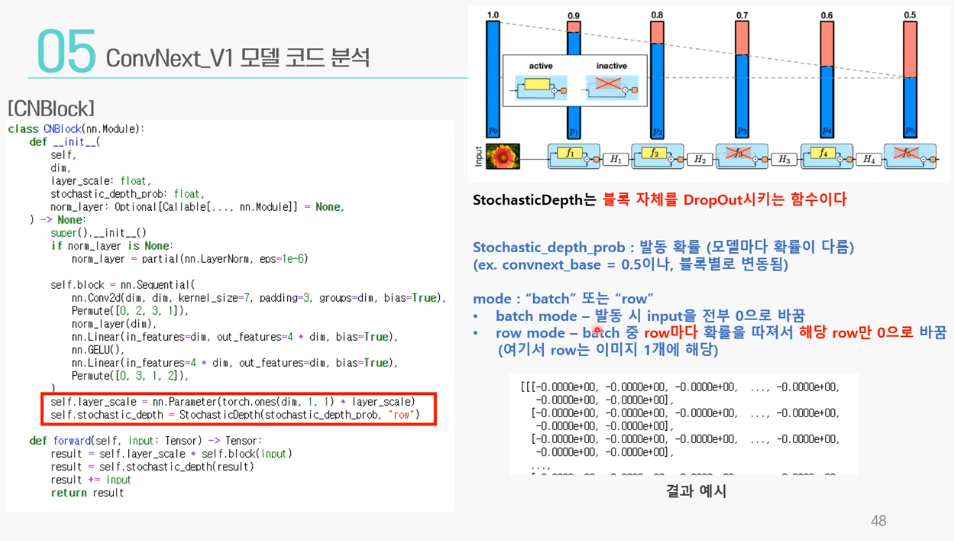
Stochastic Depth3.forward
ConvNext
기본 함수들

1. stem

- List[nn.modle] = []으로 클래스들을 리스트에 쌓을 수 있게됨
2. block 쌓기
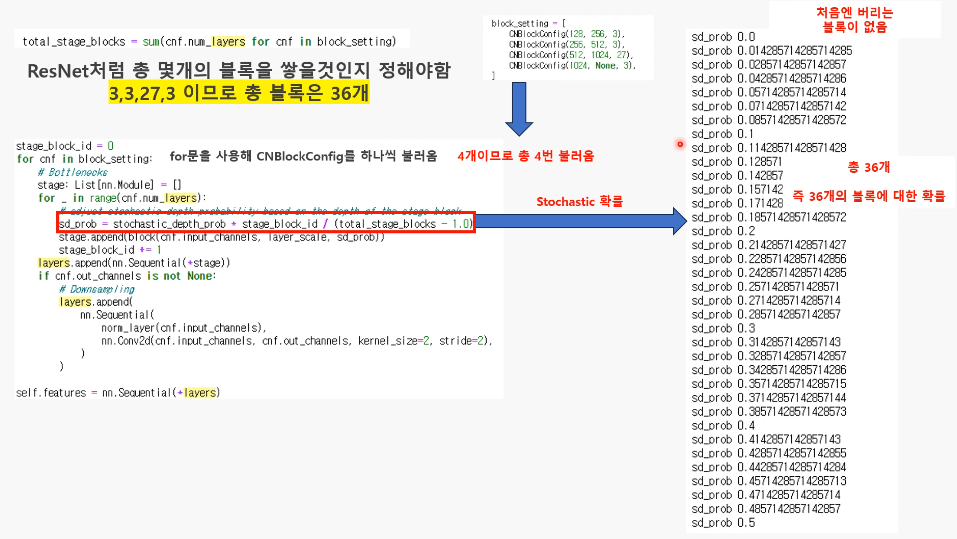
Stochastic 계산
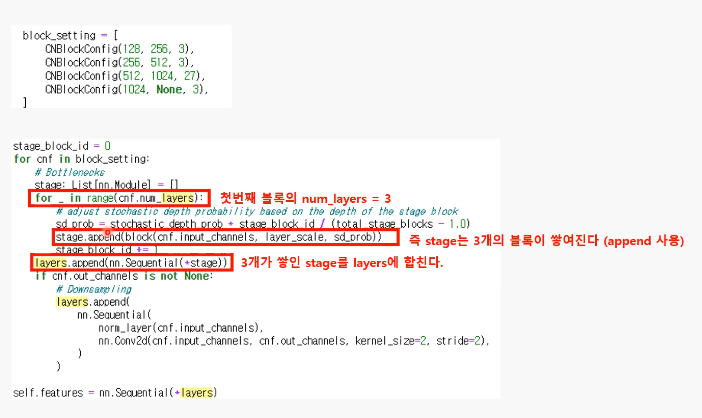
블록 3개 쌓기
Block 이후에 (Conv2D로) 해상도 낮추는 레이어 추가
- output 채널 수도 여기서 다음 블록에 들어갈 값으로 바뀜
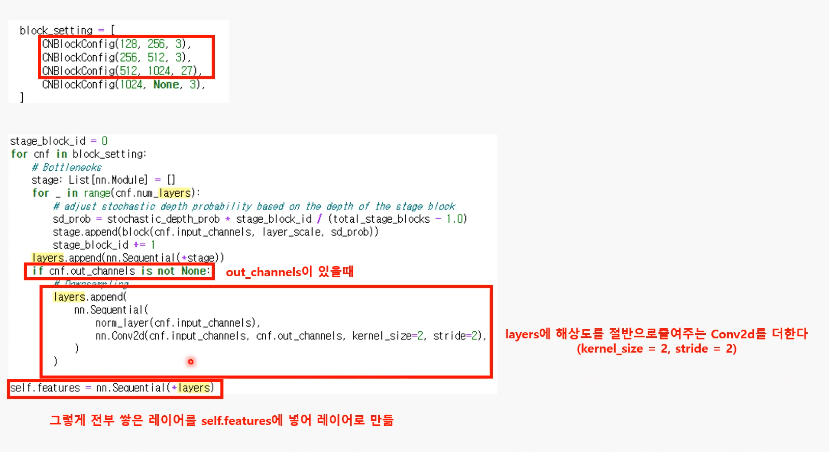
->마지막에 self.features에 저장
지금까지 구조
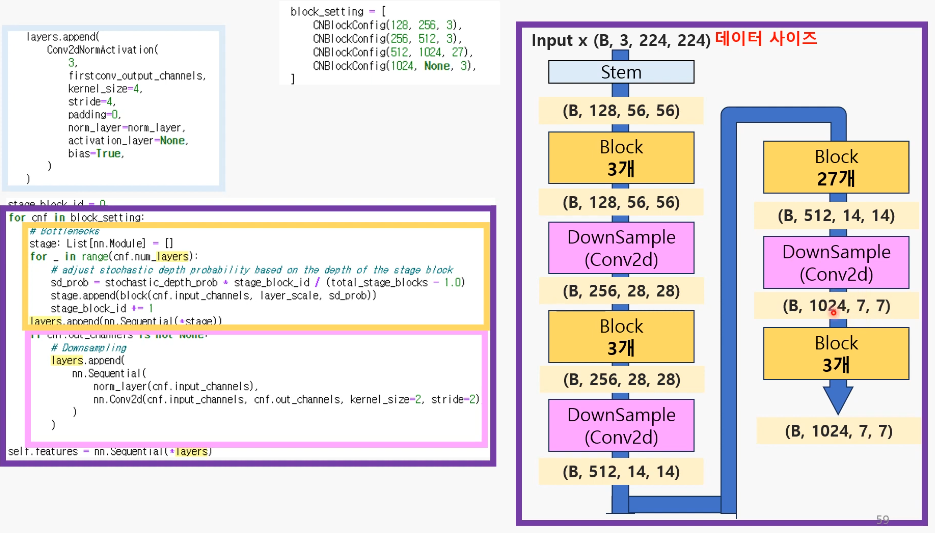
Q. 블록을 지나도 input, output 채널 수 가 같아야 하는데 왜 block_stting에선 다르게 설정되어 있지?
-> 각 블록의 입력과 출력 채널 설정은 해당 블록 내의 DownSample 레이어까지 고려하여 결정
출력
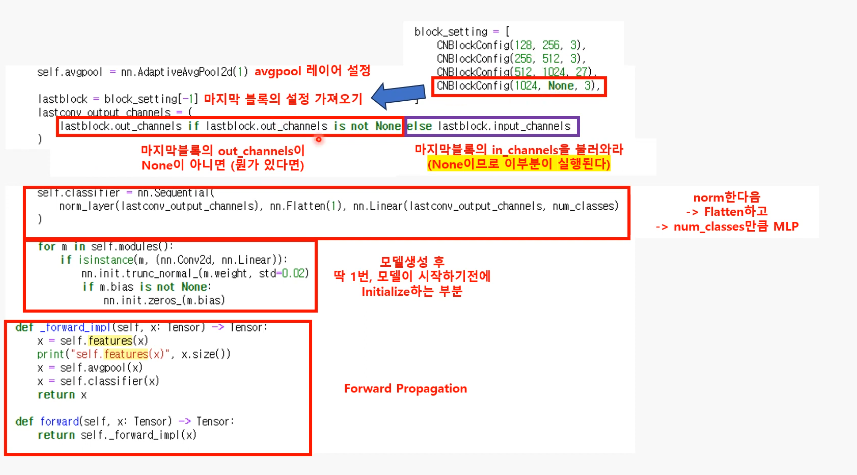
-
output채널은 None으로 설정돼 input 채널 수(3)과 같아짐
-
self.classifier 부분을 통과한 후 출력 텐서는 다음과 같이 변환:
Normalization: 입력 형태 유지 -> (B, 1024, 7, 7)
Flatten: (B, 1024x7x7) -> (B, 50176)
Linear: (B, 50176) -> (B, num_classes)
->class 분류에 사용!
-
forward_impl 함수:
입력 텐서 x를 받아서 네트워크를 통과시킨 후 출력을 반환하는 실제 연산을 정의
def _forward_impl(self, x: Tensor) -> Tensor:
x = self.features(x)
print('self.features(x)', x.size())
x = self.avgpool(x)
x = self.classifier(x)
return x
- 특징 추출
x = self.features(x)
- 특징 맵의 크기 출력:
print('self.features(x)', x.size())
- 평균 풀링 적용 ,분류 (B, num_classes) 적용, 결과 반환:
x = self.avgpool(x) x = self.classifier(x) return x
