LASS
1. intro
Task
: 소리를 분리
Input: 사용자의 설명과 mixed된 오디오 데이터
Output: 사용자가 자연어로 설명한 대로 오디오 혼합물에서 특정 소리를 분리
기본 아이디어
"고정된 소리 카테고리 대신 자연어를 통해 오디오 소스를 분리"
- 자연어를 사용하면 소리의 공간적 및 시간적 관계를 포함할 수 있어, 소리의 특성을 더욱 세밀하게 설명 가능
- 고정된 소리 카테고리:
개 짖는 소리, 박수 소리, 피아노 연주, 새소리 등 - 자연어 설명:
“배경에서 개가 짖는다” 또는 “사람들이 박수치고 나서 여자가 말한다”
LASS의 주요 과제:
-
자연어 표현의 복잡성: 오디오를 설명하는 언어는 다양한 구문으로 이루어져 있으며, 동일한 소리도 여러 방식으로 표현될 수 있습니다. 이로 인해, 시스템은 다양한 언어적 표현을 이해하고 이를 소리와 연결해야 합니다.
-
정확한 소리 분리: 언어적 설명에 기반하여 오디오 혼합물에서 특정 소리 원천을 정확하게 분리하는 것이 필요합니다. 이는 단순히 소리의 종류를 지정하는 것보다 더 복잡한 작업입니다.
=> 결국, LASS는
언어적 표현을 이해->소리와 연결->사용자가 자연어로 묘사한 대로 원하는 소리를 오디오 혼합물에서 정확히 분리
하는 과정
모델:
- Transformer based query model: 언어 표현을 쿼리 임베딩으로 바꿈
- ResUNet-based sparation network : 쿼리 임베딩을 가지고 mixed 오디오로부터 타겟 소스를 분리함
2 관련 Task들
2.1 Universal sound separation(USS)
- 소리를 모든 class에 따라 분리
- LASS는 real-world sounds 분리를 수행하기 위한 모델 중 하나다. 근데 이제 자연어를 곁들인
2.2 target source extraction(TSE)
- USS와 달리 TSE는 특정 소리에 대한 쿼리 정보를 제공 받아 관심 있는 target source만 추출
- LASS는 TSE를 수행하기 위한 모델 중 하나다. 근데 이제 자연어 쿼리를 곁들인
2.3 Automated Audio captioning (AAC)
- 오디오를 듣고 그에 대한 자연어 설명을 자동으로 생성
- LASS의 데이터셋 구축에 사용, 이때 만든 설명을 활용하여 소리를 분리
3. Proposed Approach
3.1 LASS-Net 모델 구성
LAS-Net: 자연어 쿼리를 가지고 오디오 소스를 분리!
두가지 구성요소를 가짐
1) QueryNet:
input: a language query
output: a query embedding
2) SeparationNet
input: mixture and query embedding
output: prediction of the target source
"These two modules are trained jointly"
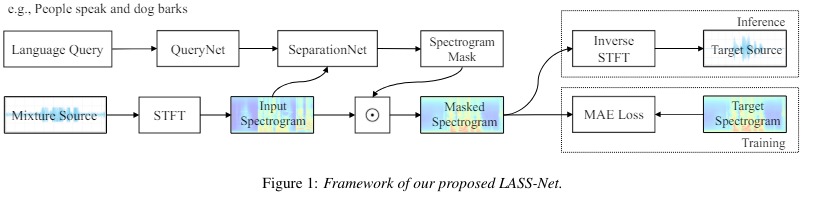
1. QueryNet
the language query
a query embedding
2. SeparationNet
: 크기 스펙트로그램
와 같은 크기의 잠재 특징
전체 과정
목표:
- 주어진 크기 스펙트로그램 에서 target source의 크기 스펙트로그램 로 regression 모델을 학습하는 것이 목표
- 여기서 는 분리된 target source
-
STFT 변환:
The audio mixture 는 단기 푸리에 변환 (STFT)을 통해 스펙트로그램 로 변환- 이때 =
- : 크기 스펙트로그램
- : 위상
- 는 시간과 주파수의 이차원 표현으로,
- 는 시간 프레임 수,
- 는 스펙트럼 특징의 차원
AND
-
SeparationNet() →
- 와 같은 크기의 잠재 특징
- 잠재 특징: 오디오와 쿼리의 관계를 나타냄, (target 소스를 정확하게 분리하기 위한 기반)
-
- obtain a spectrogram mask
- 를 시그모이드 함수에 통과
- 스펙트로그램 마스크 을 구함:
범위로, 각 요소가 혼합된 스펙트로그램에서 특정 소리 성분을 분리하는 데 사용
-
=
- The magnitude spectrogram (target source의 크기 스펙트로그램)
- ⊙는 Hadamard product (요소별 곱셈)를 의미
- 각 요소별로 의 값을 의 값으로 곱하여 target source의 크기 스펙트로그램을 추출
->학습
-
- MAE (Mean Absolute Error):
와 실제 목표 소스의 크기 스펙트로그램 간의 오차를 최소화하는 것 - 여기서 1은 노름으로, 요소별 절대값의 합
- MAE (Mean Absolute Error):
OR
-> inference
- 위상 재사용 =
- 역 STFT를 적용해 분리된 오디오 소스 를 얻음
사용되는 모델들
3.2. Query network
BERT
"LASS-Net에서 언어 쿼리를 임베딩하기 위해 BERT 모델을 활용"
- BERT는 4개의 Transformer 인코더 블록으로 구성되어 있으며, 각 블록은 4개의 헤드와 256개의 차원을 가짐
과정:
- 언어 쿼리는 BERT에 입력되어 256차원의 단어 수준 임베딩을 생성
- 언어 쿼리: "사람이 웃는 소리와 박수 소리"
-> BERT -> 각 단어들이 256 차원의 임베딩된 벡터가 됨
- 언어 쿼리: "사람이 웃는 소리와 박수 소리"
- 이 중 첫번째 단어의 임베딩 벡터 을 완전연결층에 넣음
- 은 [CLS] 토큰으로 전체 문장을 대표하는 데 최적화
- 이때 엔 모든 단어들 간의 관계가 들어있음
- 애초에 BERT의 목적이 문맥파악이라 을 주로 사용함(나머지는 보조적)
- 최종 쿼리 임베딩 생성
- 하나의 벡터임
- 완전 연결층의 역할
- 특정 차원으로 조정
- 비선형 변환: ReLU 활성화를 통해 복잡한 관계를 더 잘 학습
3.3. Separation network
ResUNet
"LASS-Net에서 Mixed audio를 separation 하기 위해 ResUNet을 활용"
:기존 UNet에서 Encoder 및 Decoder 부분의 block마다 residual unit with identity mapping을 적용
ResUNet 구조:
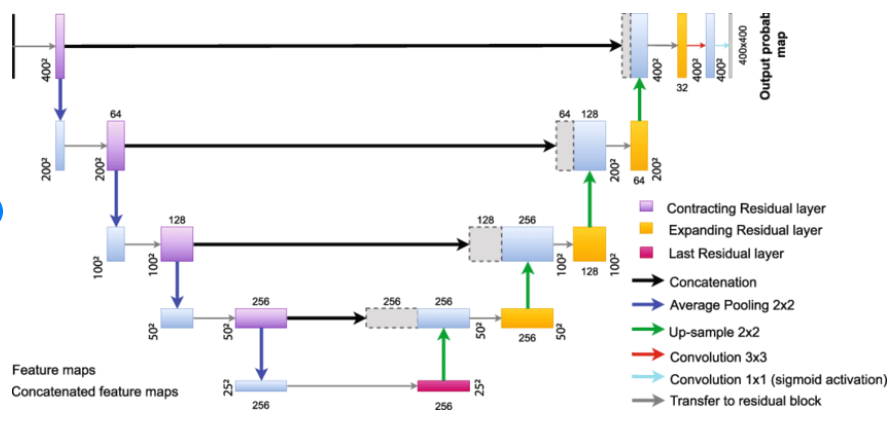
- 인코더 블록 여섯 개와 디코더 블록 여섯 개로 구성되며, 같은 층위는 스킵 연결로 연결
- 각 인코더와 디코더 블록은 두 개의 ConvBlock으로 구성된 동일한 구조를 공유
- 각 ConvBlock은 배치 정규화, leakyReLU 활성화, 4×4 커널 크기의 합성곱 계층을 포함
- 인코더 블록에서는 다운샘플링을 위해 평균 풀링을 적용
- 디코더 블록에서는 업샘플링을 위해 Transposed Convolution을 적용
- 각 인코더 블록의 특징 맵 수는 각각 32, 64, 128, 256, 384, 384
- 디코더 블록의 특징 맵 수는 각각 384, 384, 256, 128, 64, 32
- 마지막 디코더 블록 이후, 32채널 ConvBlock과 1×1 합성곱 계층이 배치
=>입력 스펙트로그램과 동일한 형태의 스펙트로그램 마스크를 추정
+) FiLM 사용
Query network와 separation network를 연결하기 위해, separation network에 배치된 각 ConvBlock 이후에 Feature-wise Linearly modulated (FiLM) 계층을 사용
: ConvBlock 의 출력 feature map (은 필터수)
각 특징 맵 에 대해 FiLM 계층을 통해 다음과 같이 적용
FiLM() =
이때, and 은 를 통해 구한 조절 매개 변수
참고
