EAT
: Self-Supervised Pre-Training with Efficient Audio Transformer
Abstract
- 문제점: 오디오 SSL에서 높은 계산 비용이 효율적 응용과 최적화를 방해.
- 제안 모델: Efficient Audio Transformer (EAT).
- 특징 1: 부트스트랩 학습 패러다임 적용.
- 특징 2: Utterance-Frame Objective (UFO) 설계로 글로벌 및 로컬 정보 동시 학습.
- 특징 3: 역 블록 마스크 전략 도입으로 마스킹 효율성을 극대화.
- 결과:
AudioSet, ESC-50, SPC-2 등의 오디오 태스크에서 SOTA 성능 달성.
기존 모델 대비 약 15배 빠른 사전 학습 속도 실현.
1. introduction
- 배경: 자기 지도 학습(SSL)의 중요성
- SSL의 성공적인 도입:
- NLP(BERT, GPT)와 CV(MAE, BYOL) 뿐 아니라, 오디오 도메인에서도 비라벨 오디오 데이터를 활용해 효과적인 학습을 위한 연구가 활발히 진행 중.
- 오디오 SSL의 주요 접근법:
- masked autoencoder 기반 모델
-> 제한된 마스킹된 컨텍스트에서 전체 데이터를 복원하며 표현을 학습.
예) SSAST, MAE-AST, Audio-MAE. - boostrap 기반 모델
-> 증강된 데이터를 사용하여 교사-학생 네트워크 구조로 학습.
예) BYOL-A, ATST, M2D.
- masked autoencoder 기반 모델
- SSL의 성공적인 도입:
- 기존 접근법의 한계
- 계산 효율성의 문제:
Audio-MAE는 높은 마스크 비율을 통해 계산량을 줄이려 하지만, 복잡한 디코더(SwinTransformer)를 필요로 해 학습 시간이 증가. - 정보 손실의 가능성:
BEATs는 목표 특징을 양자화(토크나이징)하여 학습 효율을 높이려 하지만, 이로 인해 정보 손실이 발생하며 더 많은 학습 반복이 필요.
- 계산 효율성의 문제:
- EAT(Efficient Audio Transformer)의 제안
- 효율적인 학습 구조
- 기존 방식과는 다르게 Utterance-Frame Objective (UFO)를 도입.
- 글로벌(Utterance 수준) 및 로컬(Frame 수준)의 정보를 동시에 학습.
- 핵심 아이디어
- 오디오 스펙트로그램의 글로벌 및 로컬 정보를 통합적으로 이해하여 더 나은 오디오 표현 학습 가능.
- 복잡한 디코더 대신 경량 CNN 디코더를 사용하여 계산 효율성 극대화.
- 효율적인 학습 구조
- 부트스트랩 프레임워크와 학습 전략
- 부트스트랩 학습 구조
- 학생 모델은 교사 모델의 출력을 예측하며, 교사 모델은 지수 이동 평균(EMA)으로 업데이트됨.
- 데이터2vec 2.0에서 영감을 받아 역 블록 마스킹(Inverse Block Masking) 기법 도입:
- 블록 단위로 마스킹되지 않은 데이터를 유지하여 학습 난이도를 증가.
- 높은 마스크 비율(80%)을 통해 데이터 효율성을 극대화.
- 비대칭 네트워크 설계
- 복잡한 Transformer 인코더와 경량 CNN 디코더를 결합.
- 프레임 수준과 발화 수준 정보를 모두 고려하여 더욱 정확한 표현 학습.
- 부트스트랩 학습 구조
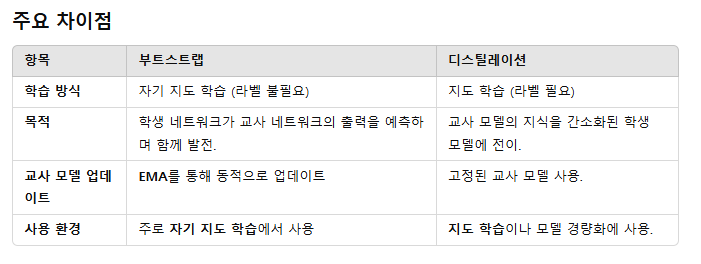
Boostrap vs Distilation
2. Related work
2.1 Boostrap Method
- 부트스트랩 방법의 기본 개념:
- 구성: 타겟 인코더 + 예측 네트워크.
- 타겟 인코더는 모멘텀 업데이트를 통해 점진적으로 업데이트.
- 예측 네트워크는 타겟 인코더 출력을 예측하도록 학습.
- 활용 사례:
- 초기 도입: BYOL.
- 발전된 비전 모델: DINO, SimSiam, MoCo v3.
- 부트스트랩 방법의 확장:
- 다양한 모달리티 적용:
1) Data2vec: 마스킹 기반 기법을 통해 성능 및 효율성 향상.
2) 오디오 도메인 적용:
BYOL-A, M2D는 오디오 학습에서 부트스트랩을 활용.
EAT는 부트스트랩 기반 설계로 학습 효율성을 대폭 향상.
- 다양한 모달리티 적용:
Boostrap 관련 포스팅
- SimCLR rivew https://kyujinpy.tistory.com/39
- moko review https://dhk1349.tistory.com/14
- BYOL review https://kyujinpy.tistory.com/44
2.2 Self-supervised Audio Pre-training
-
사전학습 데이터 두가지
- 음성 및 오디오 데이터를 결합한 공동 학습:
예: SS-AST [Gong et al., 2022], MAE-AST [Baade et al., 2022]. - 오디오 데이터만 사용하는 사전 학습(더 널리 사용됨):
예: MaskSpec [Chong et al., 2023], MSM-MAE [Niizumi et al., 2022], Audio-MAE [Huang et al., 2022], EAT.
- 음성 및 오디오 데이터를 결합한 공동 학습:
-
오디오 SSL 모델에서의 구성 요소:
-
입력 데이터:
1) Raw waveforms: wav2vec 2.0 [Baevski et al., 2020], data2vec.
2) Mel spectrograms: 대부분의 모델(EAT 포함)이 사용. -
사전 학습 목표(Pretext Tasks):
- 마스킹 기반 학습:
MAE-AST, Audio-MAE, EAT는 높은 마스킹 비율을 적용하여 스펙트로그램 복원. - 증강 기반 학습:
BYOL-A [Niizumi et al., 2021], ATST [Li and Li, 2022]는 mixup, random resize crop(RRC) 등의 증강 기법을 활용하여 학습.
- 마스킹 기반 학습:
-
사전 학습 목적(Objectives):
- 복원 기반:
Audio-MAE, MAE-AST는 원래의 스펙트로그램 패치를 복원. - 토크나이저 기반:
BEATs [Chen et al., 2022c]는 이산적인 의미적 특징을 예측. - 잠재 표현 기반:
data2vec, BYOL-A, M2D는 잠재적인 표현을 예측. - EAT의 목표:
Utterance-Frame Objective (UFO)를 도입해 글로벌 및 로컬 정보를 동시에 고려.
- 복원 기반:
-
3.Method
EAT의 설계 목표
- 효율적인 오디오 표현 학습:
data2vec 2.0과 Audio-MAE에서 영감을 받아 부트스트랩 및 마스킹 기반 학습 방식 결합.
전역(global) 및 로컬(local) 정보를 효과적으로 학습하는 구조. - 비대칭 네트워크 아키텍처:
Transformer 인코더: 가시적인 패치(마스킹되지 않은 영역)에서 전역 정보를 학습.
CNN 디코더: 전체 데이터(가시적 패치 + 마스크된 패치)를 처리하여 로컬 정보를 복원.
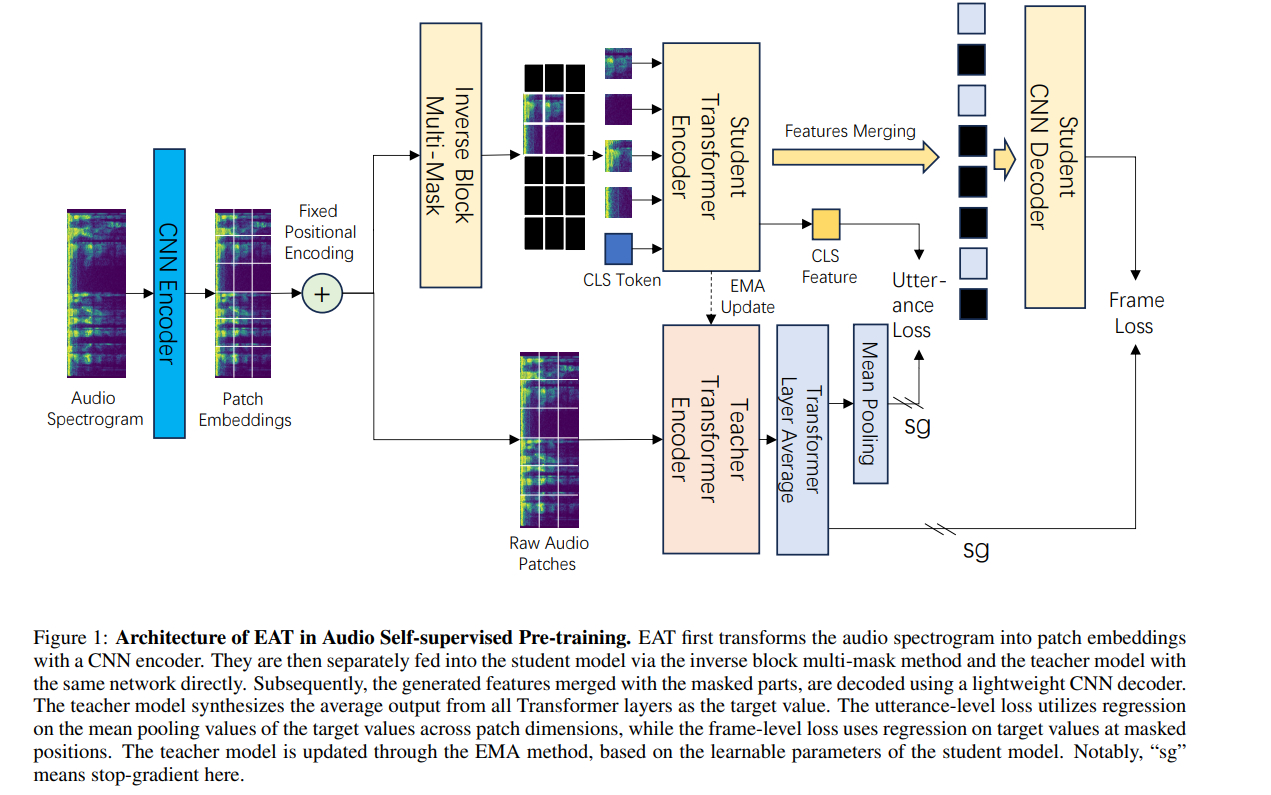
3.1 Model Architecture

1. 입력 데이터 처리: 패치 임베딩 (Patch Embedding)
처리과정
- padding 된 뒤 형태
- 예) 128x128
- 2D CNN을 사용하여 스펙트로그램을 패치 단위로 분할.
- CNN의 커널 크기와 스트라이드를 동일하게 설정해 패치 간의 독립성을 유지.
- 예) kernel size=16x16, stride=16
->8x8x768- Flatten 한 뒤 형태
- : 패치 개수 (스펙트로그램의 면적을 커널 크기로 나눔).
- : 임베딩 차원(패치당 특징 크기).
- transformer에서 사용하는 형식으로 맞춰주기 위해 Flatten
- 예) -> 64x768
- Fixed positional Encoding
- 패치에는 고유한 시간과 주파수 위치가 존재하므로, Transformer가 패치 간의 순서를 이해하도록 위치 정보를 제공.
- 1D 고정 위치 임베딩(Fixed Positional Encoding)을 사용하여 Xp에 위치 정보를 추가.
2. Utterance-Frame Objective(UFO)
EAT의 핵심 학습 전략은 발화 수준(utterance-level)과 프레임 수준(frame-level) 손실을 통합하여 학습하는 것.
->오디오 데이터의 전역(global) 및 로컬(local) 정보를 동시에 학습하는 것을 목표로 함
발화 수준(utterance-level) 손실
- 교사 모델(teacher model)의 타겟 생성 ()
- input: complete input patch embedddings
- 교사 모델(teacher model)의 Top-k(마지막 k개) Transformer 레이어 출력을 평균하여 생성된 맥락화된(contextualized) 표현 .
- 학생 모델(student model)의 출력 ()
- input은 가시적인 패치(마스크되지 않은 패치)
- cls token (초기화된 벡터)이 Transformer의 최종 레이어에서 CLS 토큰은 전체 입력 데이터의 전역 문맥을 학습한 상태로 출력
->
->는 학생 모델이 가시적인 패치를 처리한 결과 생성된 발화 수준의 전역 표현(utterance-level global representation)을 나타낸다.(by self-attention)- 발화 수준(utterance-level) 손실
- 생성
: 에서 패치 차원(P)에 대해 평균을 계산한 값으로, 발화 수준(utterance-level)의 전역 정보를 대표하는 하나의 임베딩 벡터- 와 사이 MSE loss계산
- 식:
로컬 프레임 수준(local Frame-level) 손실(MAE method 차용)
- student encoder output representations 가 원래 시퀀스에서 마스크 토큰과 결합(merged)
- lightweight CNN decoder를 사용해 마스킹된 위치에서 average features 를 예측
- masking 된 패치의 예측값 과 타겟값 사이 MSE loss
- 식
-> 최종 UPO loss
:
3. Masking Strategies in Pre-training
- 역 블록 마스킹(inverse block masking)을 채택
- 패치 임베딩의 80%를 마스킹.
- Transformer가 처리해야 할 데이터 양을 줄여 학습 속도 향상.
- 제한된 가시적 입력만으로 중요한 정보를 해석하고(U) 마스킹된 특징을 추론하도록(F) 모델을 학습시킴.
역 블록 마스킹(Inverse Block Masking)
기존 1D 랜덤 마스킹(->PxE) 대신, 시간-주파수 간의 상관성을 유지하는 2D 마스킹 방식(->TxFxE) 채택.
- 작동 원리:
- 처음에 모든 패치를 마스킹.
- 블록 단위로 일부 패치를 복원하여, 마스킹된 임베딩 수가 목표 마스킹 비율(80%)에 도달하도록 설정.
- 이때 블록은 패치 그룹의 크기를 말함
- ex) 2x2 -> 4개의 패치
- 1D 랜덤 마스킹과 비교:
- 2D 블록 단위로 패치를 복원하므로, 시간-주파수 영역에서의 상관성(correlation)이 유지
- given patch embedding 에 대해 1D random masking 과 달리, 로 reshape한 뒤 T,F두 차원에 대한 masking 적용
-> This maskmaintains correlation in both time and frequency dimensions, where T'= T /S and F'= F/S.
Multi-mask Approach
- 배경) 교사 모델과 학생 모델의 계산 부담 차이:
- 교사 모델:
전체 패치 임베딩을 처리해야 하므로 계산 자원이 더 많이 필요.
이는 학습 속도를 제한하는 요인이 될 수 있음.- 학생 모델:
가시적 패치(마스킹되지 않은 패치)만을 처리하므로 계산량이 상대적으로 적음.-> 결국 교사 모델이 1번 출력될 때, 학생모델은 여러 형태의 데이터를 입력받아 출력시켜서 선생 모델의 계산 반복 횟수를 줄이는 것! (다 대 일 구조)
- Multi-mask Approach의 작동 방식
- 동일한 스펙트로그램 패치에 대해 서로 다른 마스킹 변형을 생성.
예: 80%의 마스킹 비율을 유지하면서, 각 변형에서 마스킹된 블록의 위치가 다름.- 다중 클론 마스크 임베딩 생성: 동일한 입력 데이터(스펙트로그램)에서 생성된 다양한 마스킹 변형을 "클론(masked clones)" 형태로 생성.
예를 들어, 하나의 스펙트로그램 데이터에서 k개의 마스킹 변형을 생성.- 생성된 여러 마스킹 변형 데이터를 학생 모델에 동시에 입력.
이 데이터는 병렬 처리되어 한 번의 학습 반복에서 다양한 마스킹된 데이터를 동시에 학습 가능.
- Multi-mask Approach의 장점
- 학습 속도 향상:
병렬 처리를 통해 학습 반복(iteration) 당 처리되는 데이터 양 증가.
동일한 학습 시간 내에 더 많은 데이터를 처리하여 학습 속도 향상.- 데이터 활용도 증대:
동일한 입력 데이터를 다양한 마스킹 변형으로 활용하므로 데이터 다양성이 증가.
모델이 동일 데이터에 대해 다양한 맥락(context)을 학습하도록 유도.- 학습 효율성 극대화:
학생 모델의 계산 부담은 크게 증가하지 않으면서, 다양한 입력 패턴을 동시에 학습 가능.->결과적으로 모델이 더 강건하고 일반화된 표현을 학습할 수 있음.
3.2 Pre-training Details
- 모델 아키텍처:
- 학생 모델과 교사 모델 모두 12개의 Transformer 레이어(ViT-B)를 사용.
- CNN 인코더:
- (16,16) 커널과 16 스트라이드 사용
- CNN 디코더:
- 빠른 디코딩을 위해 (3,3) 커널로 구성된 6개의 레이어로 설계.
- 지수 이동 평균(EMA) 업데이트
- 학생 모델(파라미터 )은 UFO 손실 함수를 통해 업데이트
- 교사모델은 EMA를 통해 업데이트
τ 값을 선형적으로 증가시키는 전략을 채택.
- 초기 학습 단계에서는 더 높은 유연성과 랜덤성을 제공하고,
- 학습이 진행될수록 τ는 1에 가까워지며, 더 안정적인 학습이 가능해짐.
3.3 Fine-tuning Details
- 학생 Transformer 인코더만 사용, 잠재 표현(latent representation)을 생성
- 학생 CNN 디코더를 제거하고 오디오 카테고리 예측을 위한 선형 계층(linear layer)으로 대체
- 데이터 증강(data augmentation) 기술을 구현
미세 조정 시 적용되는 데이터 증강 기법:
- SpecAug [Park et al., 2019]: 스펙트로그램의 시간 및 주파수 영역에 마스킹 적용.
- mixup [Zhang et al., 2017]: 두 스펙트로그램 데이터를 혼합하여 학습.
- droppath [Huang et al., 2016]: 경로를 무작위로 제거하여 학습.
- audio rolling: 오디오 신호를 시간 축에서 회전.
- random noise: 스펙트로그램에 랜덤 노이즈 추가.
- CLS 토큰 기반 분류:
분류 작업에서는 CLS 토큰이 최종 예측에 사용, 평균 풀링(mean pooling) 방식보다 더 나은 성능을 보였다.
