논문 리뷰: MusicGen-Stem: Multi-stem music generation and edition through autoregressive modeling
I. Abs & Intro
최근 텍스트 조건 기반 음악 생성 모델(MusicGen 등)은 완성도 높은 곡을 만들 수 있게 되었지만, 실제 음악 제작에 필수적인 stem 단위(드럼, 베이스, 기타 등 악기별 트랙) 생성과 편집 기능은 부족하다.
이 논문에서는 MusicGen-Stem이라는 새로운 접근을 제안
- 세 개의 stem (베이스, 드럼, 기타/기타 악기)을 동시에 생성
- stem별 전용 compression model을 사용해 cross-talk(간섭) 최소화
- masking + autoregressive 전략으로 특정 stem만 수정·재생성 가능한 editing 지원
평가 결과, MusicGen-Stem은 기존 MusicGen 수준의 Text to Music 성능을 유지하면서도, unconditional generation과 editing에서 더 뛰어난 품질과 다양성을 보임
II. Relative Work
1. Music Generation Models
- Compression models: Neural audio codec을 이용해 오디오를 discrete tokens로 바꾼 뒤 autoregressive하게 모델링 (MusicLM, MusicGen).
- Diffusion models: Latent diffusion 기반으로 고품질 오디오 생성 (AudioLDM, MusicLDM, Stable Audio). 긴 길이(최대 95초)도 가능하지만 계산량 큼.
- Non-autoregressive 접근: 순차적 x (부분 마스크 등) -> 더 빠른 생성은 가능하지만, 음악적 일관성이 떨어지는 경우 많음.
2. Music Editing Models
- Zero-shot editing: Diffusion inversion(DPDM, DDIM)으로 기존 오디오 latent를 수정 → 유연하나 특정 stem만 편집 어려움.
- Test-time optimization: pseudoword를 학습시켜 특정 아티스트/스타일 반영 (특정 스타일을 pseudoword embedding에 입력되도록 학습) → 별도 훈련 없이 가능하지만 artifact 발생.
- Autoregressive 모델: discrete autoencoder 기반 → 곡 이어생성하기는 가능하나, stem-level inpainting은 불가(flexibility x)
- Instruction-tuned 모델: Instruct-MusicGen → 지시어로 추가/삭제/교체 가능, 하지만 길이 제한(5초), stem 독립성 부족.
3. Stem-based Music Generation
1. SingSong: 보컬 → 반주 생성. 보컬 중심이라 범용성 낮음.
2. StemGen: 하나의 stem을 입력으로 넣고 나머지 stem을 순차적으로 생성. 항상 조건 stem 필요, 비효율적.
3. Jen-1 Composer: Latent diffusion 기반 multi-track 생성.
4. MSDM: diffusion 기반 4-stem 동시 생성. 하지만 uncondition, 계산량 크고 다양성 부족.
Use-case of Model(3)
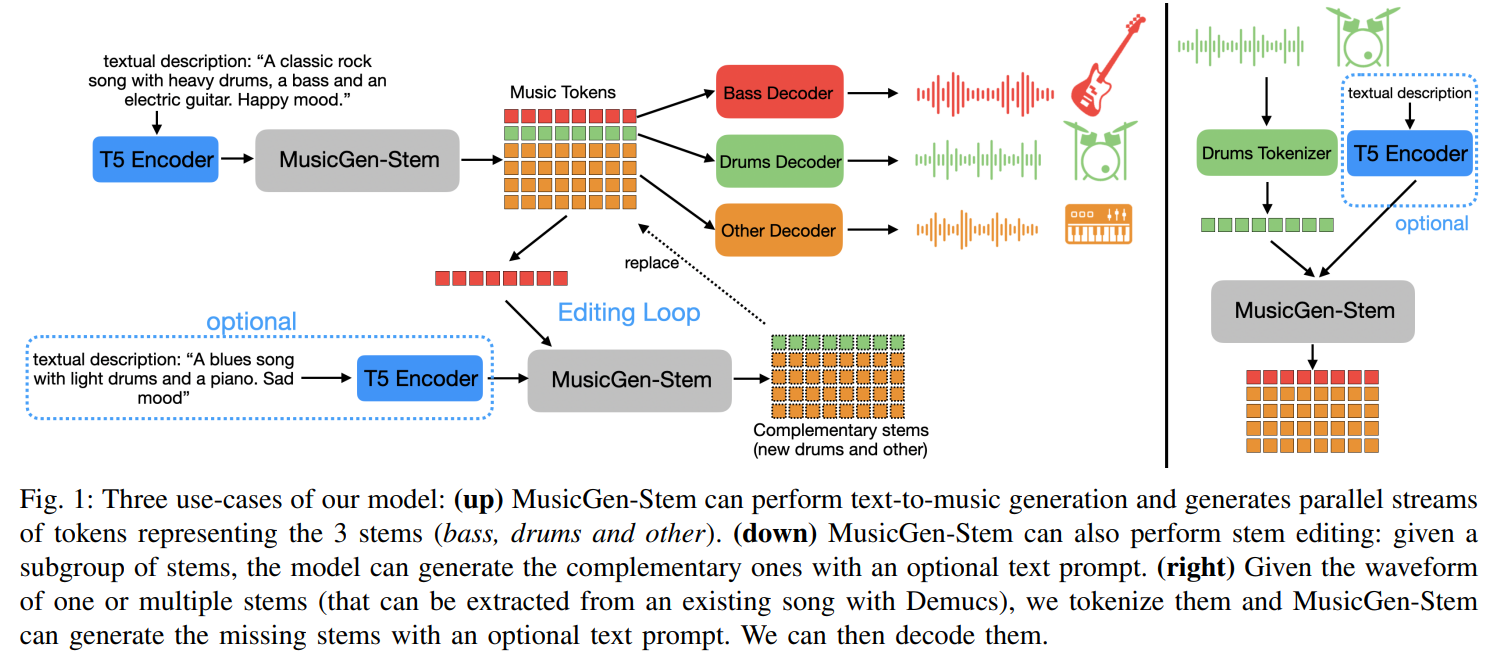
III. Method
1. 전체 구조
Training pipeline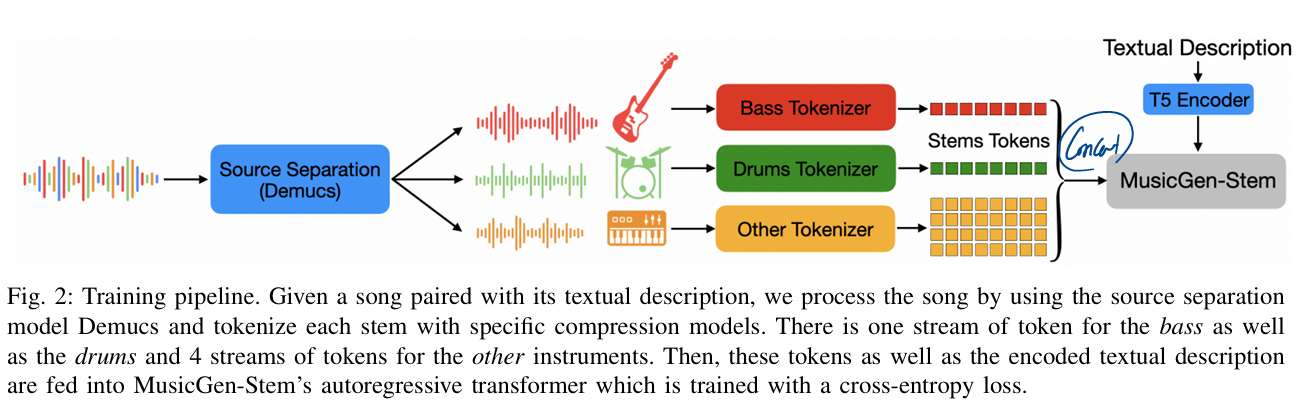
- 기반 모델: MusicGen(1.5B Transformer decoder) 아키텍처를 확장.
- 입력: 텍스트 프롬프트(옵션) + stem 토큰들.
- 출력: Bass, Drums, Other(4-stream RVQ) stem 토큰 시퀀스.
- 핵심 아이디어: stem별 전용 compression model을 두어 cross-talk(간섭)을 줄이고, coarse/residual 구조로 예측 순서를 설계.
2. Stem 전용 Compression Model
-
원본 오디오(30초, 32kHz)를 neural codec(EnCodec 계열)으로 압축(, 30초, 50Hz).
-
Bass/Drums: 단일 quantization (single codebook).
-
Other stem: 4-stream RVQ (Residual Vector Quantization).
-
첫 stream = coarse (구조 뼈대).
-
나머지 3개 stream = residual (세부 질감).
RVQ:
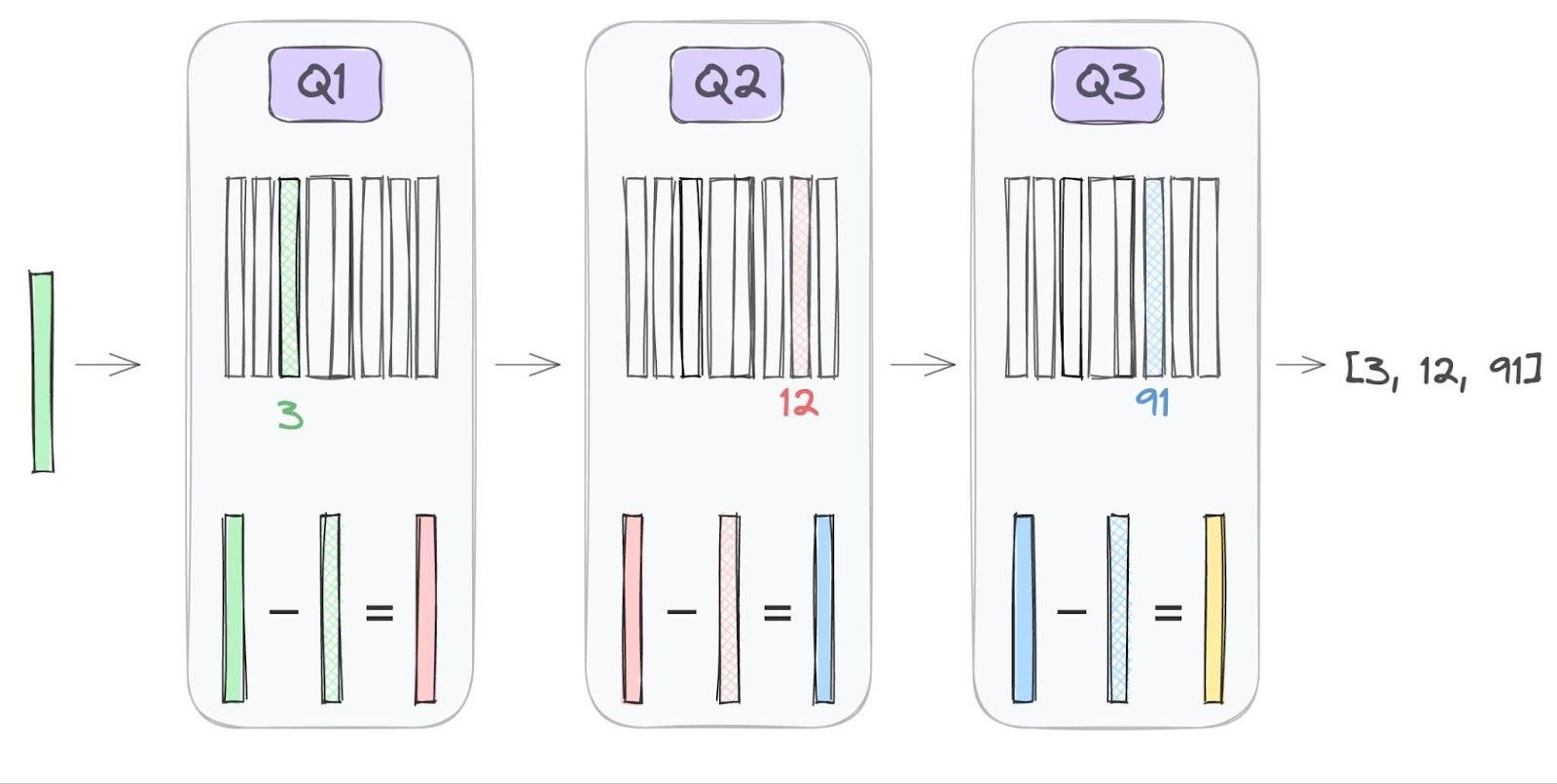 differences between the data vectors and their quantized representations을 다음 codebook에서 찾음 -> 반복 -> 더 세밀하게 표현
differences between the data vectors and their quantized representations을 다음 codebook에서 찾음 -> 반복 -> 더 세밀하게 표현
-
-
이렇게 stem별로 다른 압축 방식을 적용 → 독립성 보장 + 표현력 확보.
3. Autoregressive Modeling
-
모든 stem 토큰을 시간축에 따라 concat하여 Transformer 입력으로 사용.
-
Coarse tokens (Bass, Drums, Other-1): 이 셋은 동기화된 상태로 먼저 예측.
-
Residual tokens (Other-2,3,4): coarse 예측 후 delay를 두고 이어서 예측.
→ coarse가 전체 음악 구조를 먼저 잡고, residual이 디테일을 보강.Coarse tokens ->oth2 ->oth3 ->oth4 = coarse ->details
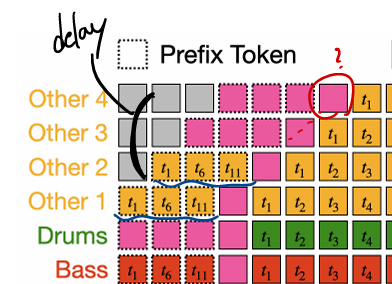
4. Editing with Masking
-
학습 시, 0.5 확률로 “text-to-music” 또는 “editing” 태스크 선택.
-
Editing:
-
prefix 생성 : 25 scondes(1,250 tokens를 down sampling(10Hz로) -> 250 tokens를 prefix로 사용
-
random(1or2개) stem 중 prefix에 해당하는 토큰을 mask 처리 (예: Drums 전체, Other residual).
- Other는 ({4},{4,3},{4,3,2},{4,3,2,1}) 중 선택
- first stream을 보고 details를 생성해내도록 만들기 위해
-
나머지 stem + prefix context를 조건으로 사용.
-
모델은 autoregressive하게 mask된 부분만 복원.
-
이 방식으로 모델은 특정 stem만 교체/보강하는 능력을 학습.
Traing the editing task

-
5. 데이터 준비
-
원 데이터: MusicGen에서 사용한 대규모 음악 데이터셋.
-
보컬 포함 곡 제거 (~15%).
-
최신 Demucs를 사용해 모든 곡을 Bass, Drums, Other 3 stem으로 분리.
-
최종적으로 stem-level 학습 데이터셋을 구축.
IV. Experiments
1. 실험 세팅
-
데이터셋: MusicGen에서 사용한 20만+ 곡 → 보컬 곡(15%) 제외, Demucs로 3 stem 분리.
-
모델 크기: MusicGen-Medium (약 1.5B 파라미터) 기반.
-
토큰화: 30초 오디오를 50Hz로 quantization → 약 1500 tokens/stem.
-
학습 전략:
-
매 step마다 50% 확률로 text-to-music / editing 태스크 선택.
-
Stem별 masking으로 editing 기능 학습.
-
2. 평가 방법
-
객관적 지표
- FAD (Fréchet Audio Distance)
- 의미: 모델이 만든 음악이 인간이 만든 음악과 얼마나 자연스럽고 다양한지.
- 무엇: 생성 음악과 실제 음악의 분포 유사도.
- 어떻게: VGGish 임베딩 분포의 평균·공분산을 비교해 Fréchet 거리 계산.
- CLAP Score
- 의미: 생성 음악이 주어진 텍스트 프롬프트와 잘 맞는지.
- 무엇: 텍스트-오디오 의미적 일치도.
- 어떻게: CLAP 모델의 텍스트/오디오 임베딩 코사인 유사도.
- KLD (KL Divergence)
- 의미: 생성 음악이 전체적으로 데이터 분포를 잘 따르는지(편향/다양성 여부).
- 무엇: 생성 분포와 참조 분포 간의 차이.
- 어떻게: MusicGen에서 정의한 분포 간 KL 발산 계산.
- FAD (Fréchet Audio Distance)
-
주관적 지표
- OVL (Overall Quality)
- 의미: 청취자가 느낀 음악의 전반적 품질(듣기 좋음/거슬림).
- 무엇: 전체적인 청취 경험.
- 어떻게: 사람이 MOS 방식으로 점수 매김.
- REL (Relevance)
- 의미: 음악이 텍스트 프롬프트와 얼마나 잘 맞는지에 대한 사람 판단.
- 무엇: 주관적 텍스트-오디오 관련성.
- 어떻게: 청취자가 프롬프트와 생성물의 적합도를 평가.
- OVL (Overall Quality)
-
Editing 전용 지표
- BEAT
- 의미: 편집된 스템이 원곡과 리듬적으로 얼마나 잘 맞는지.
- 무엇: 비트 정합성.
- 어떻게: madmom으로 비트 추출 → mir_eval로 F-measure 계산.
- HAR (Harmony)
- 의미: 편집된 베이스 라인이 원곡 코드와 화성적으로 잘 어울리는지.
- 무엇: 화음-베이스 일치율.
- 어떻게: Chordino로 코드 추출 + Pesto로 베이스 음 추정 → 코드톤 일치율 계산.
- BEAT
-
주요 결과
Music generation matrics
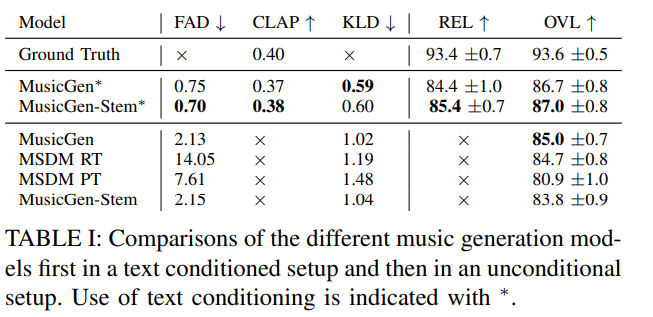
(1) Text-to-Music Generation
-
MusicGen-Stem은 기존 MusicGen과 거의 동일한 수준의 품질을 유지.
-
일부 지표에서는 약간 더 우수한 성능.
-
주관적 평가에서도 두 모델이 비슷하게 높음.
(2) Unconditional Generation
-
MusicGen-Stem은 MSDM보다 더 다양한 곡을 생성.
-
FAD/KLD 기준으로도 개선 → 다양성과 품질 동시 확보.
(3) Editing
Stem Editing Matrics
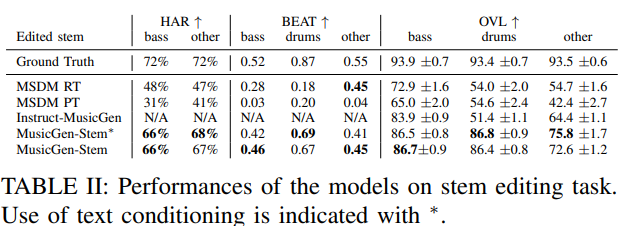
-
기존 Instruct-MusicGen보다 훨씬 안정적으로 특정 stem만 교체/편집 가능.
-
BEAT/HAR 지표 모두 우수 → 리듬·화음 일치 잘 유지.
-
주관적 평가에서도 “편집 후에도 곡이 자연스럽다”는 점수가 높음.
ME
- stem 종류를 더 늘리는 방법 고안
- text prompt로 stem을 무제한 선택가능 하도록("Zero-shot Musical Stem Retrieval with Joint-Embedding Predictive Architectures")
- 실시간 합주가능 모델로 발전 가능성
- ...
