SLAM-AAC
SLAM-AAC: Enhancing Audio Captioning with Paraphrasing Augmentation and CLAP-Refine through LLMs
I. intro
- AAC의 목표: 오디오 데이터를 이해하고, 이를 자연스러운 텍스트로 설명하는 작업.
- 기존 방법 한계: PANNs와 같은 감독 학습 모델은 데이터 부족과 유연성 문제로 한계가 있음.
- SLAM-AAC 제안:
- 오디오 인코딩: EAT를 활용한 세밀한 오디오 특징 추출.
- 텍스트 디코딩: Vicuna를 사용하여 자연스러운 설명 생성.
- 효율적 학습: LoRA를 활용한 경량화된 파인튜닝.
- 데이터 증강: Clotho 데이터셋을 역번역으로 확장해 텍스트 다양성 증대.
- CLAP-Refine: 추론 단계에서 입력 오디오와 가장 유사한 텍스트 선택.
II. SLAM-AAC
A. Network Architecture
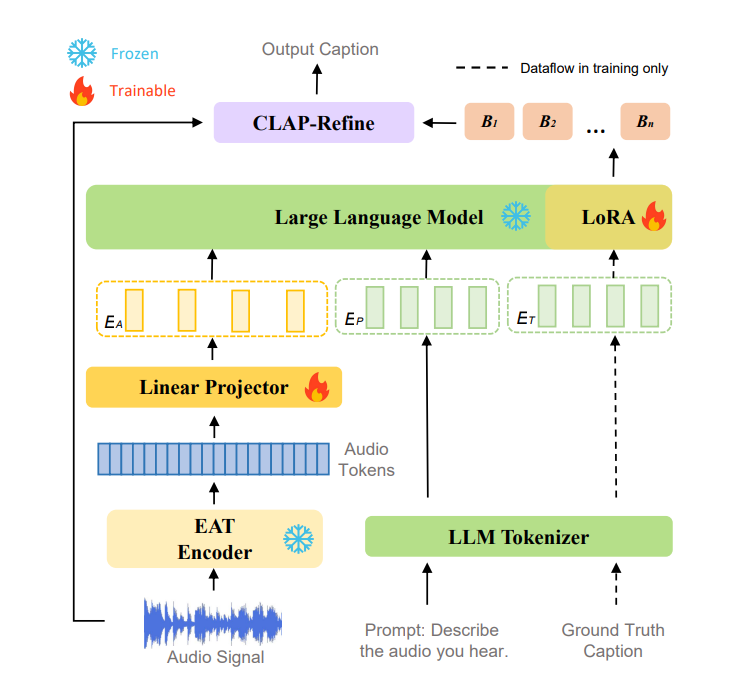 1. 오디오 인코딩:
1. 오디오 인코딩:
- EAT 모델을 고정(frozen) 상태로 사용하여 오디오에서 세밀한 표현(feature)을 추출.
- 선형 프로젝터를 통해 오디오 표현을 다운샘플링하고 텍스트 임베딩과 정렬.
2. 텍스트 디코딩:
- 대규모 언어 모델(LLM)이 결합된 오디오-텍스트 표현을 기반으로 텍스트 캡션 생성.
LoRA를 통해 효율적인 파인튜닝 수행.
3. 추론 단계:
-
빔 서치를 통해 다양한 후보 캡션 생성.
-
CLAP-Refine 전략을 활용해 입력 오디오와 가장 잘 맞는 후보를 최종 캡션으로 선택.
오디오 인코딩
- EAT는 입력 오디오 신호를 16kHz로 샘플링하고, 25ms의 Hanning 윈도우와 10ms의 이동 간격으로 128차원 멜 주파수 대역으로 변환, 이 멜 스펙트로그램은 CNN 인코더와 ViT-B(12개 레이어) 모델을 통해 2D 패치 임베딩으로 변환
->결과적으로 약 50Hz의 오디오 표현이 생성
->lightweight 2-layer linear projections을 통해 5배 다운샘플링하여, 10Hz로 변환
텍스트 디코딩
- SLAM-AAC는 "Describe the audio you hear"와 같은 텍스트 프롬프트와 정답 캡션을 Vicuna의 토크나이저(32,000 어휘)로 처리해 해당 텍스트 임베딩
-> 와 를 생성 - 는 학습 과정에서 교사 강제(teacher-forcing)를 사용
- 오디오 임베딩 프롬프트 임베딩, 정답 임베딩을 보두 concat해서 LLM에 넣어줌
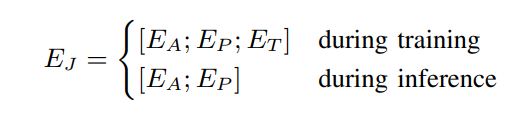
- cross-entropy를 사용해 loss 계산
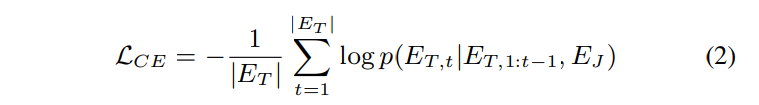
- 교차 엔트로피의 역할:
- )는 모델이 t-번째 토큰을 정확히 예측했을 때의 확률 값에 대한 로그입니다.
이를 음수로 바꾸는 이유는, 로그 확률은 값이 높을수록 (정확도가 높을수록) 작은 음수가 되므로, 최적화 시 손실을 최소화하려는 방향과 부합합니다.
- )는 모델이 t-번째 토큰을 정확히 예측했을 때의 확률 값에 대한 로그입니다.
- 평균 손실 계산:
- 는의 전체 토큰 수로 나누는 부분입니다.
이로써 각 토큰의 손실을 평균 내어 전체 문장 길이에 관계없이 균일하게 손실을 계산합니다.
- 는의 전체 토큰 수로 나누는 부분입니다.
- 조건부 확률의 중요성:
- 는 오토리그레시브(Autoregressive) 방식으로, 이전 토큰 과 입력 임베딩 를 기반으로 현재 t번째 토큰을 예측하는 확률입니다.
이는 모델이 순차적으로 텍스트를 생성하는 방식과 일치합니다.
- 는 오토리그레시브(Autoregressive) 방식으로, 이전 토큰 과 입력 임베딩 를 기반으로 현재 t번째 토큰을 예측하는 확률입니다.
- EAT는 입력 오디오 신호를 16kHz로 샘플링하고, 25ms의 Hanning 윈도우와 10ms의 이동 간격으로 128차원 멜 주파수 대역으로 변환, 이 멜 스펙트로그램은 CNN 인코더와 ViT-B(12개 레이어) 모델을 통해 2D 패치 임베딩으로 변환
B. Paraphrasing Augmentation in AAC
역번역을 활용한 증강 방법
- 각 영어 캡션을 Google Translate API를 사용해 중국어로 번역한 뒤, 다시 영어로 역번역하여 5개의 추가 주석을 생성합니다.
- 예시:
- 원래 주석 (영어): "A person is very carefully wrapping a gift for someone else."
- 번역 (중국어): "一个人正在非常小心地为别人包装礼物。"
- 역번역 (영어): "Someone is wrapping a present for someone else with great care."
효과
- Clotho 데이터셋의 어휘 크기가 7,454개에서 10,453개로 증가했습니다.
- 이 기법은 단어 수준의 텍스트 증강(예: WordNet 기반 유의어 대체)보다 더 광범위한 문장 재구조화를 가능하게 하며, 원래 의미를 유지하면서도 데이터 다양성을 향상시켰습니다.
C. CLAP-Refine for Text Decoding
기존의 AAC 시스템에서는 주로 빔 서치(beam search)나 누클리어스 샘플링(nucleus sampling)을 텍스트 디코딩에 활용합니다. 그러나 이러한 방법들은 다음과 같은 한계를 가집니다:
- 빔 서치는 디코더의 점수(score)를 최대화하는 데 집중하며, 생성된 텍스트와 오디오 임베딩 간의 정렬(alignment)을 간과할 수 있습니다.
빔 서치의 문제
입력 오디오 임베딩과 생성된 텍스트 간의 의미적 일관성을 유지하려면, 모델이 입력 임베딩에서 충분한 정보를 활용해야 합니다. 하지만 빔 서치는 이러한 입력-출력 정렬을 보장하기보다 언어적 구조(확률 점수)를 우선시합니다. 그 결과, 생성된 텍스트가 오디오의 실제 의미를 정확히 반영하지 못할 수 있습니다. - 누클리어스 샘플링은 출력이 불안정하며, 최적의 결과를 얻기 위해 다수의 디코딩 시도와 추가적인 후처리가 필요합니다.
누클리어스 샘플링의 문제
샘플링 기반 디코딩이므로 동일한 입력에 대해 매번 다른 결과를 생성할 가능성이 높습니다. 특히, 확률 분포의 상위 p-확률 질량에 포함된 여러 토큰 중 무작위로 선택되기 때문에, 생성 결과의 품질이 일정하지 않을 수 있습니다. 따라서 가장 적절한 결과를 선택하는 과정(예: BLEU, CIDEr 등의 기준)을 거쳐야 합니다.
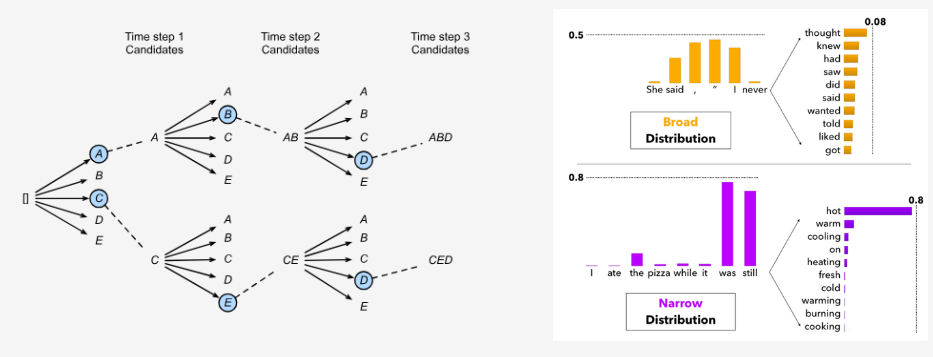
CLAP-Refine 전략
- CLAP 모델은 대조 학습(contrastive learning)을 통해 암묵적인 오디오-텍스트 멀티모달 표현 공간을 구축합니다.
- CLAP은 듀얼 인코더(dual encoder)를 사용해 텍스트와 오디오 데이터를 독립적으로 처리하고, 결과적으로 텍스트-오디오 쌍의 정렬도를 평가하는 유사성 점수(similarity score)를 제공합니다:
작동 방식
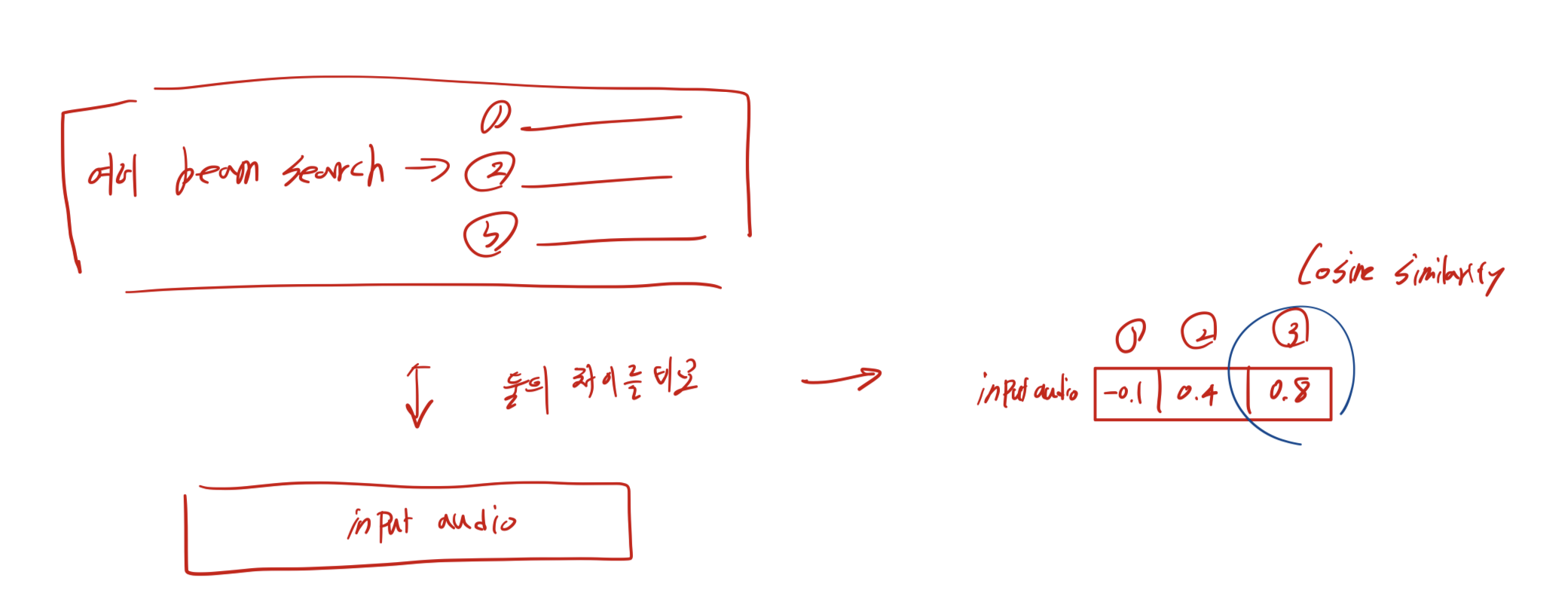
- 빔 서치 생성:
- SLAM-AAC는 입력 오디오에 대해 다양한 빔 크기(예:n=2,3,...)로 여러 후보 캡션을 생성.
- 후보 캡션 평가:
- CLAP 모델을 사용해 각 후보 캡션과 입력 오디오 간의 유사성을 계산.
- 재정렬 및 최종 선택:
- 유사성이 가장 높은 후보 캡션을 최종 출력으로 선택.
- 빔 서치 생성:
III. EXPERIMENTAL SETUP
A.데이터셋
Clotho, AudioCaps, WavCaps, MACS
- 훈련 과정에서는 Clotho, AudioCaps, MACS 훈련 세트와 전체 WavCaps 데이터셋을 사용.
- 이때, Clotho 훈련 세트는 패러프레이징 증강(paraphrasing augmentation)을 통해 확장
B. 평가 지표
METEOR [33]:
유니그램 정밀도, 재현율, 동의어, 어간 추출을 고려.
CIDEr [34]:
TF-IDF 가중치를 사용해 생성 텍스트와 참조 텍스트 간의 합의(consensus)를 측정.
SPICE [35]:
생성 텍스트와 참조 텍스트의 의미적 그래프를 비교.
SPIDEr [36]:
CIDEr와 SPICE를 선형적으로 결합해 문법적 및 의미적 평가를 균형 있게 수행.
SPIDEr-FL [37]:
유창성 오류 감지(fluency error detection)를 포함한 SPIDEr 확장판.
FENSE [37]:
문장 BERT(Sentence-BERT)의 의미적 유사성과 유창성 오류 감지를 결합한 지표.
C. 학습 및 추론 세부 사항
- 사전 학습:
위 데이터셋으로 사전 학습을 진행.
- 배치 크기: 16
- 학습률: 1e-4
- 학습 횟수: 100,000 업데이트.
- 학습률은 선형 감소 스케줄을 따르며, 1,000회 반복 동안 점진적으로 증가(warmup).
- 학습은 NVIDIA A800 GPU에서 약 26시간 소요.
- 미세 조정(Fine-Tuning):
Clotho와 AudioCaps 데이터셋에서 각각 10에포크 동안 수행.
- 배치 크기: 4
- 학습률: 8e-6
- LoRA 어댑터를 Transformer 블록의 및 투영 레이어에 통합.
- CLAP 모델 학습:
AudioCaps, Clotho, WavCaps 데이터셋에서 학습.
- 배치 크기: 128
- 학습률: 5e-5
- 학습 횟수: 15 에포크.
- 최적의 검증 손실에서 모델을 저장.
- 추론:
SLAM-AAC는 다양한 빔 크기(2~8)로 빔 서치를 수행하여 후보 캡션을 생성.
최종 캡션은 CLAP-Refine를 통해 가장 높은 유사성 점수를 가진 후보를 선택.
IV. EXPERIMENTAL RESULTS
Main Result
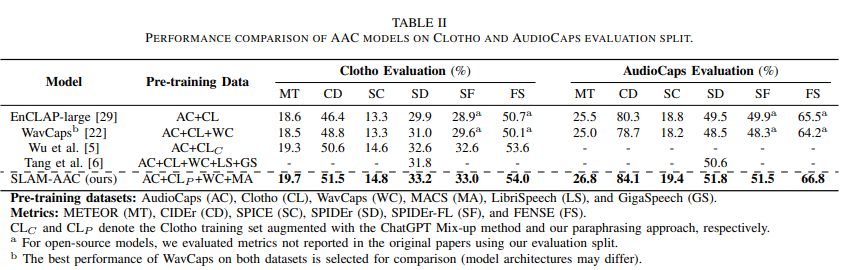
- SLAM-AAC는 Clotho와 AudioCaps에서 거의 모든 지표에서 최고 성능을 기록.
- 특히 AudioCaps에서는 기존 모델 대비 CIDEr와 SPIDEr 점수에서 1% 이상의 개선.
Ablation Study
- 사용된 방법이 모두 유의미함
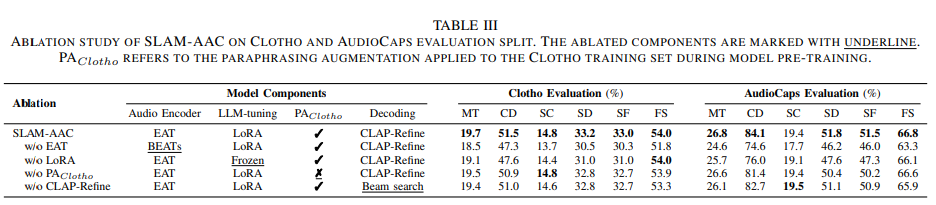
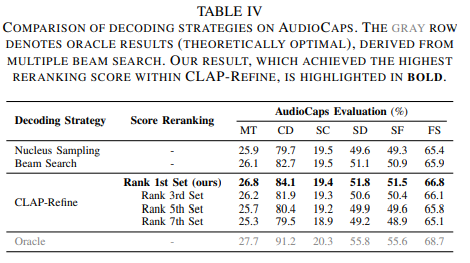
decoding 기법 비교
- CLAP-Refine는 기존 빔 서치 대비 약 1.4% 성능 향상.
- 이론적으로 최적의 결과(Oracle)와 비교하면 개선 여지가 남아 있음.
V. Conclusion and Future Work
향후 연구 방향 (Future Work)
-
새로운 패러프레이징 기법 탐구
- LLM을 활용한 텍스트 재구성(rephrasing) 방법 도입.
- 기존 역번역 방식보다 문맥적으로 더 정교한 텍스트 증강 가능성 탐구.
-
CLAP 모델 개선
- 다양한 CLAP 모델 변형을 실험하여 CLAP-Refine 전략의 성능 최적화.
- Oracle-level 디코딩 성능에 근접하거나 이를 달성하기 위한 후처리 전략 연구.
-
오디오-텍스트 정렬 개선
- 오디오와 텍스트 간 정렬을 더 정교하게 처리할 수 있는 새로운 모델 구조 또는 학습 방법 연구.
-
대규모 데이터셋 확장
- WavCaps나 MACS 같은 더 큰 데이터셋을 활용해 학습 및 평가 성능을 강화.
VI. idea
- EAT 대신 아예 retrieval로 학습된 인코더를 projection layer 까지 가져와서 text와 더 잘 aligned 될 수 있도록 만들자.
- BACK-TRANSLATION에 더해 LLM을 활용한 rephrasing 방법 도입
- decoding 기법에 대해 Oracle달성할 수 있는 방법 생각
- BACK-TRANSLATION은 영어와 거리가 먼 언어일 수록 더 바뀌는 정도가 클 것 같은데, 이를 활용할 수 있을까?
